Блог
Практические материалы об архитектуре LLM-приложений, маршрутизации моделей, оптимизации затрат и продакшен-эксплуатации AI-систем.
Свежие материалы

17 мая 2025 г.·10 мин чтения
Датасет для дообучения без мусора: отбор и разметка
Датасет для дообучения часто портят дубли, шум и разная логика разметки. Разберем, что удалять сразу и как проверить согласованность.
датасет для дообученияпроверка консистентности разметки
13 мая 2025 г.·11 мин чтения
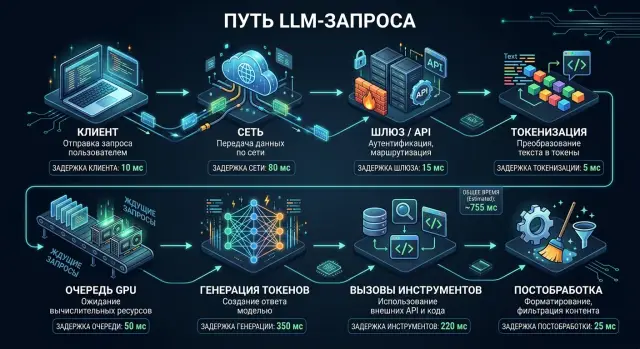
Задержка в LLM-запросе: куда уходит время по шагам
Задержка в LLM-запросе складывается не только из времени модели. Разберем сеть, токенизацию, очередь, вызовы инструментов и постобработку.
задержка в LLM-запросебюджет задержки LLM
08 мая 2025 г.·9 мин чтения
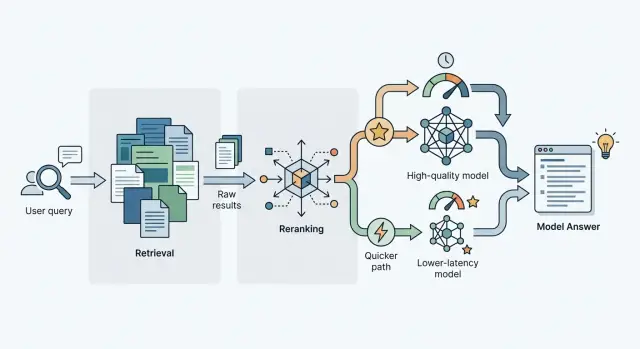
Реранжирование в RAG: когда оно окупается на практике
Реранжирование в RAG помогает не всегда: разберем, для каких коллекций и запросов reranker улучшает ответ, а где только добавляет задержку.
реранжирование в RAGreranker для поиска
07 мая 2025 г.·8 мин чтения
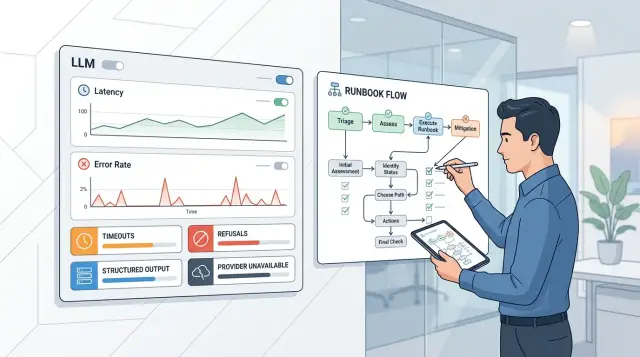
Runbook для LLM-инцидентов: таймауты, refusals и сбои
Runbook для LLM-инцидентов помогает команде быстро гасить таймауты, всплеск refusals, сбои structured output и недоступность провайдера.
runbook для LLM-инцидентовтаймауты LLM

07 мая 2025 г.·11 мин чтения
LLM над сканами и PDF: где ломаются OCR и чанкинг
LLM над сканами и PDF часто сбоит на OCR, таблицах, чанкинге и проверке полей. Разберем типовые поломки и порядок проверки пайплайна.
LLM над сканами и PDFOCR для документов
27 апр. 2025 г.·10 мин чтения
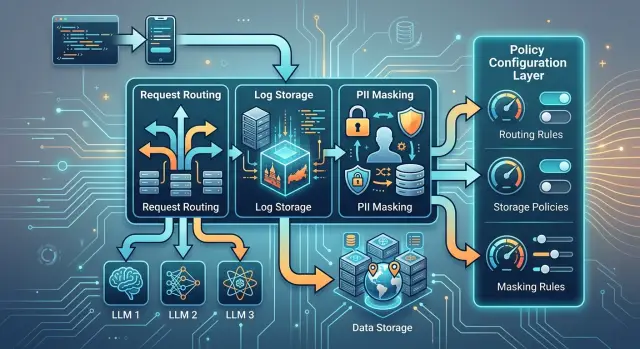
Смена требований комплаенса в LLM без остановки фичи
Смена требований комплаенса не должна останавливать LLM-фичу. Покажем, как вынести маршрутизацию, хранение и маскирование в конфиг и менять правила без правок кода.
смена требований комплаенсаполитики маршрутизации LLM

25 апр. 2025 г.·9 мин чтения
Ошибки LLM-пилота: 7 причин, почему команда буксует
Ошибки LLM-пилота часто прячутся не в модели, а в процессе: без eval, трассировки, лимитов и учета затрат команда теряет месяцы.
ошибки LLM-пилотаeval-контуры
23 апр. 2025 г.·6 мин чтения
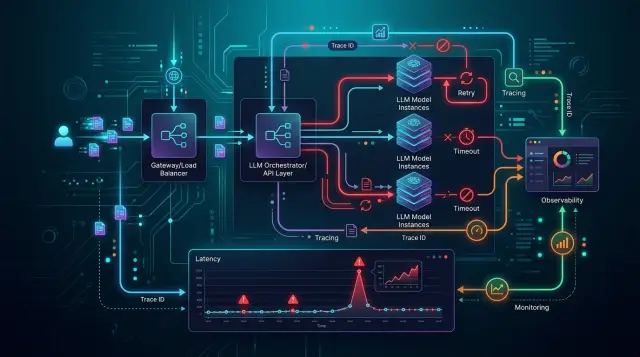
Ошибки в продакшене LLM: 7 сбоев, которые ломают стек
Разбираем ошибки в продакшене LLM: таймауты, дрейф формата, токены, ретраи и трассировку. Что проверить в первую очередь.
ошибки в продакшене LLMтаймауты LLM API
20 апр. 2025 г.·7 мин чтения
Почему модель выбирает не тот инструмент: имена и схемы
Разбираем, почему модель выбирает не тот инструмент: как имена функций, порядок описаний и громоздкие схемы ломают вызов инструментов и как это исправить.
почему модель выбирает не тот инструментвызов инструментов в LLM
20 апр. 2025 г.·7 мин чтения
Почему один и тот же промпт ведет себя по-разному у провайдеров
Почему один и тот же промпт ведет себя по-разному у провайдеров: разберем токенизацию, скрытые системные инструкции, JSON-режим и дефолтные параметры.
почему один и тот же промпт ведет себя по-разному у провайдеровразличия LLM провайдеров
19 апр. 2025 г.·10 мин чтения
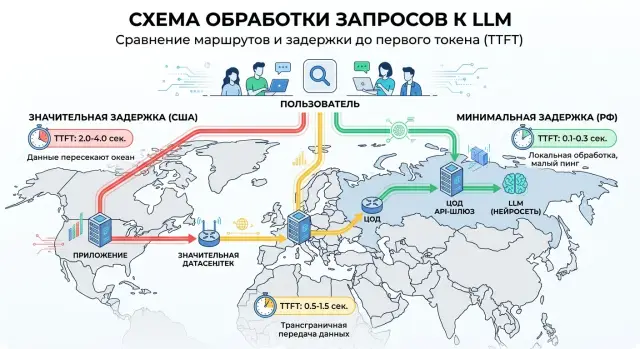
Задержка до первого токена: как близость ЦОДа меняет UX
Задержка до первого токена влияет на UX чата: в статье покажем схему маршрута, роль географии ЦОДов и простой способ замерить эффект в РФ.
задержка до первого токенагеография серверов
10 апр. 2025 г.·7 мин чтения
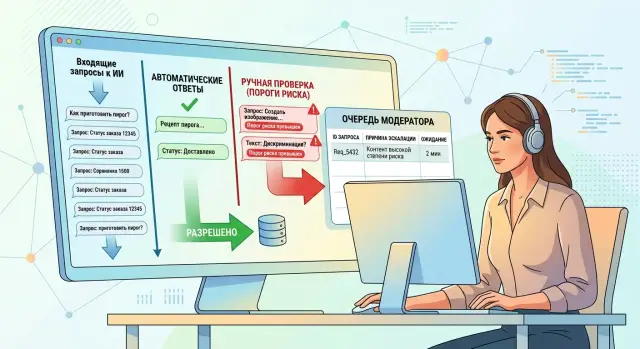
Ручная проверка ответов ИИ: где нужна и как эскалировать
Разберём, когда ручная проверка ответов ИИ снижает риск, как задать пороги эскалации и не превратить проверку в бесконечную очередь.
ручная проверка ответов ИИэскалация запросов ИИ
09 апр. 2025 г.·10 мин чтения
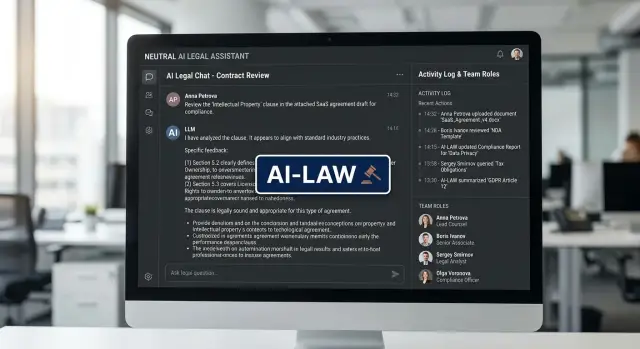
Метки AI-Law в продукте с LLM: где ставить и кто отвечает
Метки AI-Law в продукте с LLM: где их показывать, кто пишет правила, как проверять спорные случаи и не делать маркировку пустой.
метки AI-Lawмаркировка ответов LLM
04 апр. 2025 г.·9 мин чтения
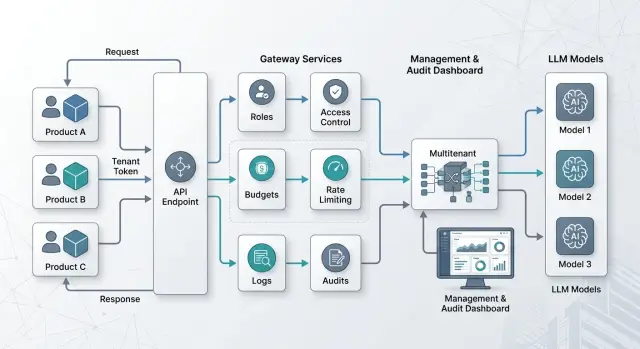
Мультиарендный LLM-шлюз: как разделить доступ между продуктами
Мультиарендный LLM-шлюз помогает обслуживать несколько продуктов через один API: отдельно считать бюджеты, хранить логи и задавать роли без лишних копий.
мультиарендный LLM-шлюзразделение токенов по продуктам
31 мар. 2025 г.·7 мин чтения
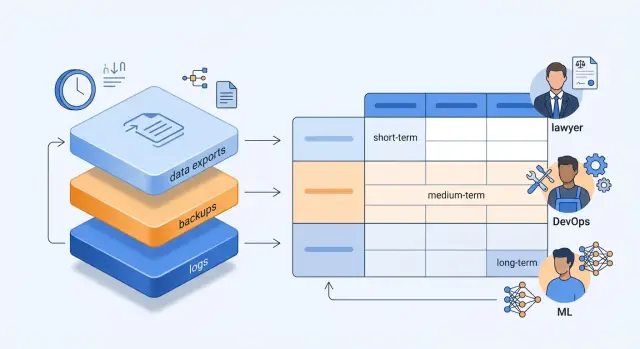
Сроки хранения логов LLM по 152-ФЗ: схема для команд
Сроки хранения логов LLM по 152-ФЗ: как разделить логи, бэкапы и выгрузки, назначить сроки и дать юристам, DevOps и ML общие правила.
сроки хранения логов LLM152-ФЗ для LLM
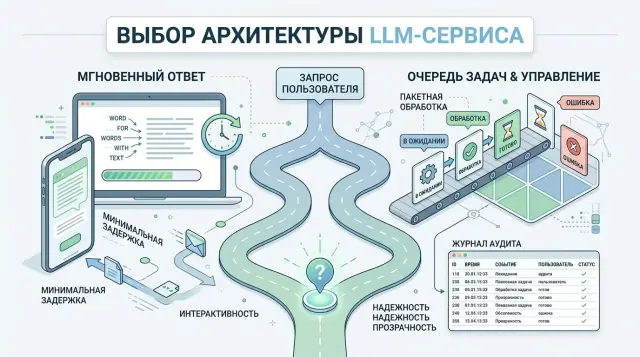
30 мар. 2025 г.·9 мин чтения
Синхронный вызов или очередь для LLM: как выбрать режим
Разберём, когда нужен синхронный вызов или очередь для LLM: по терпению пользователя, риску повторов, таймаутам и требованиям аудита.
синхронный вызов или очередь для LLMархитектура LLM-функции
27 мар. 2025 г.·8 мин чтения
Автоскейлинг open-weight моделей без дёрганья кластера
Автоскейлинг open-weight моделей требует разных сигналов на рост и спад. Разберём очередь, пороги, окна и защиту от ложных всплесков.
автоскейлинг open-weight моделейдлина очереди
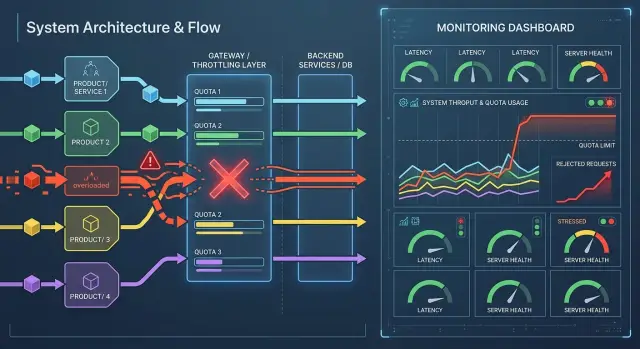
24 мар. 2025 г.·7 мин чтения
Лимиты запросов по командам и сервисам без перегрузки
Лимиты запросов по командам и сервисам помогают разделить квоты между продуктами, сдержать шумный трафик и сохранить стабильность общего контура.
лимиты запросов по командам и сервисамквоты для API

24 мар. 2025 г.·11 мин чтения
Отраслевые evals для банка и телекома: как собрать набор
Отраслевые evals для банка и телекома: где брать реальные сценарии, как обезличивать данные, кто утверждает эталоны и как не сломать процесс.
отраслевые evals для банка и телекомареальные сценарии для LLM
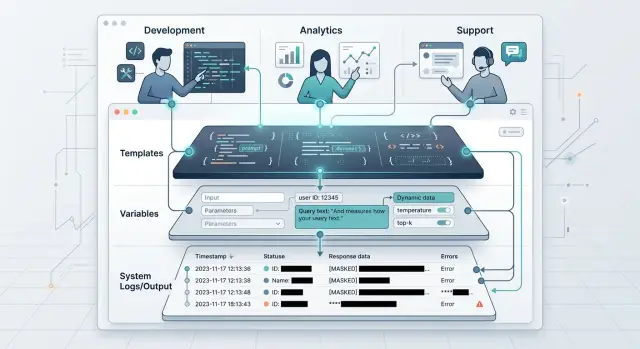
21 мар. 2025 г.·8 мин чтения
Разграничение доступа к промптам с чувствительными данными
Разграничение доступа к промптам помогает отделить шаблоны, переменные и логи по ролям и снизить риск утечек в разработке, аналитике и саппорте.
разграничение доступа к промптамчувствительные данные в LLM

18 мар. 2025 г.·6 мин чтения
A/B-тесты для LLM: почему CTR не показывает качество
A/B-тесты для LLM часто ломаются на CTR и времени в окне. Разберём сигналы, которые ближе к качеству ответа и итогу задачи.
A/B-тесты для LLMоценка качества ответов LLM
13 мар. 2025 г.·6 мин чтения
Noisy neighbor в мультиарендном LLM: квоты и параллелизм
Noisy neighbor в мультиарендном LLM возникает, когда один продукт съедает общие лимиты. Разберем квоты, параллелизм и пулы моделей без лишней теории.
noisy neighbor в мультиарендном LLMизоляция по квотам

12 мар. 2025 г.·9 мин чтения
Полезность большого контекстного окна: как проверить на деле
Разбираем, как оценить полезность большого контекстного окна на своих задачах: простые тесты, метрики, частые ошибки и короткий чек-лист.
полезность большого контекстного окнатесты контекстного окна

11 мар. 2025 г.·11 мин чтения
Выбор LLM-модели по ограничениям: матрица вместо бенчмарка
Выбор LLM-модели по ограничениям помогает сравнить задержку, резидентность, бюджет, контекст и JSON-схему до запуска в прод.
выбор LLM-модели по ограничениямматрица выбора модели
07 мар. 2025 г.·8 мин чтения
Утечки персональных данных в логах, админке и кабинете
Утечки персональных данных в логах часто начинаются не в модели, а в личном кабинете, админке и служебных журналах. Разберем слабые места и проверки.
утечки персональных данных в логахличный кабинет и ПДн

07 мар. 2025 г.·11 мин чтения
Матрица целей обработки для LLM: как собрать без пробелов
Матрица целей обработки для LLM помогает связать сценарии продукта, категории данных, сроки хранения и меры контроля без лишней теории.
матрица целей обработки для LLMцели обработки данных

04 мар. 2025 г.·11 мин чтения
Лимиты по бизнес-сценарию вместо API-ключа: где и зачем
Разбираем, почему лимиты по бизнес-сценарию лучше, чем общий предел на API-ключ, для чата продаж, кабинета оператора и фоновых задач.
лимиты по бизнес-сценариюлимиты LLM API

01 мар. 2025 г.·8 мин чтения
Чек-лист 152-ФЗ для LLM-сервиса перед первым запуском
Чек-лист 152-ФЗ для LLM-сервиса: проверьте хранение логов в РФ, маскирование PII, аудит-трейлы и роли доступа до боевого запуска.
чек-лист 152-ФЗ для LLM-сервисахранение логов в РФ
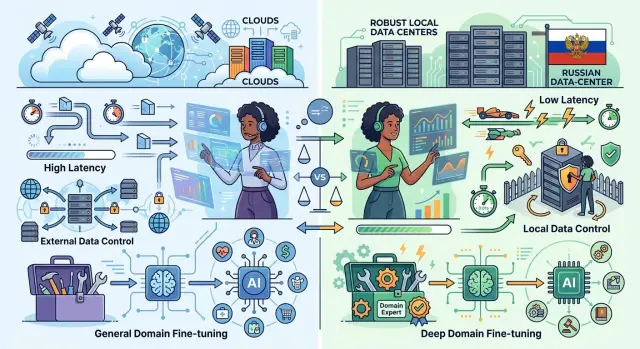
01 мар. 2025 г.·9 мин чтения
Frontier-модели или open-weight: что выбрать в РФ
Frontier-модели или open-weight: сравниваем задержку, контроль данных, настройку под домен и типовые сценарии для команд в российском контуре.
frontier-модели или open-weightвыбор LLM для российского контура
19 февр. 2025 г.·7 мин чтения
Kill switch для LLM: как отключать риск без релиза
Kill switch для LLM помогает быстро отключить рискованный промпт, инструмент или маршрут без аварийного релиза. Разберем схему, проверки и ошибки.
kill switch для LLMаварийное отключение промпта
14 февр. 2025 г.·8 мин чтения
Дубликаты документов в векторной базе: как убрать лишнее
Дубликаты документов в векторной базе портят поиск и ответы LLM. Разберем checksum, смысловое сходство и приоритет источника без лишней теории.
дубликаты документов в векторной базедедупликация по checksum
10 февр. 2025 г.·8 мин чтения
Прогноз исчерпания квот по моделям: ранние сигналы
Прогноз исчерпания квот по моделям помогает заранее увидеть пики спроса по сезонности, запускам и росту трафика и не ловить сбои в проде.
прогноз исчерпания квот по моделямсезонность трафика LLM
07 февр. 2025 г.·9 мин чтения
Очередь на ручную проверку LLM: пороги без завала команды
Очередь на ручную проверку LLM легко перегрузить, если ставить пороги наугад. Покажем, как считать нагрузку, приоритеты и правила эскалации.
очередь на ручную проверку LLMпороги сомнительных ответов
06 февр. 2025 г.·9 мин чтения
Единый OpenAI-совместимый эндпоинт: когда он упрощает работу
Разберем, когда единый OpenAI-совместимый эндпоинт снижает трение при смене провайдера, биллинге и работе с логами, а когда мешает.
единый OpenAI-совместимый эндпоинтсмена LLM-провайдера
06 февр. 2025 г.·8 мин чтения
Каскад маленькой и большой модели: где он оправдан
Каскад маленькой и большой модели помогает не всегда: разберём, когда первая ступень снижает расходы, а когда приносит лишнюю задержку и логику.
каскад маленькой и большой моделимаршрутизация запросов LLM
03 февр. 2025 г.·8 мин чтения
Тестовые и боевые данные в LLM-проекте: как разделить
Разбираем, как разделить тестовые и боевые данные в LLM-проекте: правила для песочницы, QA и демо, доступов, логов и ежедневных проверок.
тестовые и боевые данные в LLM-проектепесочница для LLM
26 янв. 2025 г.·10 мин чтения
Разделение квот офлайн и онлайн без пустого лимита днем
Разберем, как настроить разделение квот офлайн и онлайн, чтобы ночные батчи не съедали бюджет, а дневные запросы не упирались в лимит к обеду.
разделение квот офлайн и онлайнночной батч и дневной лимит
26 янв. 2025 г.·7 мин чтения
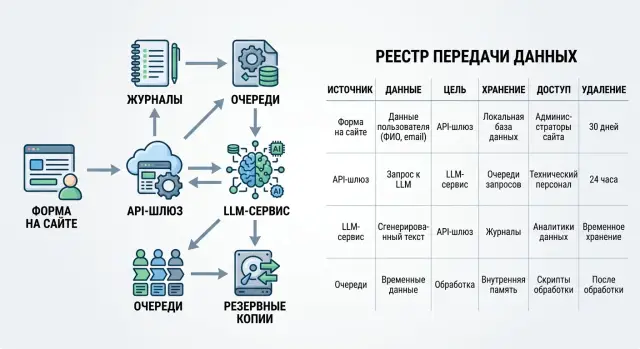
Реестр потоков персональных данных для LLM-функций
реестр потоков персональных данных помогает связать формы, API, логи и бэкапы для LLM-функций в одном документе, понятном ИБ, юристам и разработке.
реестр потоков персональных данныхLLM-функции и персональные данные
22 янв. 2025 г.·9 мин чтения
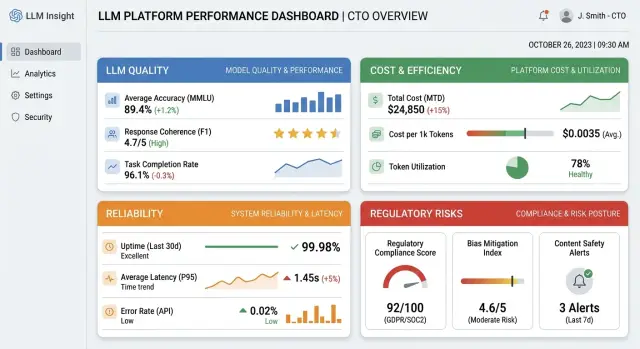
Метрики дашборда LLM-платформы: 12 сигналов для CTO
Метрики дашборда LLM-платформы помогают CTO видеть качество, цену, сбои и риски 152-ФЗ без перегруза графиками и лишними показателями.
метрики дашборда LLM-платформыдашборд LLM для CTO

20 янв. 2025 г.·11 мин чтения
Централизация доступа к LLM API: когда она уже нужна
Централизация доступа к LLM API нужна раньше, чем кажется: разберем признаки потери контроля, рост расходов, риски по логам и шаги без остановки команд.
централизация доступа к LLM APIединый шлюз для моделей

19 янв. 2025 г.·6 мин чтения
Доступ к LLM-логам: как пройти проверку без сырых данных
Доступ к LLM-логам требует ясного процесса: кто запрашивает данные, что маскируют, кто согласует выгрузку и как фиксируют каждое действие.
доступ к LLM-логаммаскирование PII

15 янв. 2025 г.·8 мин чтения
Проверка LLM на 10 миллионах диалогов в телекоме
Проверка LLM на 10 миллионах диалогов: как собрать выборку, прогнать архив пакетно и разметить ошибки по правилам, не читая весь массив вручную.
проверка LLM на 10 миллионах диалоговвыборка диалогов для оценки модели
13 янв. 2025 г.·7 мин чтения
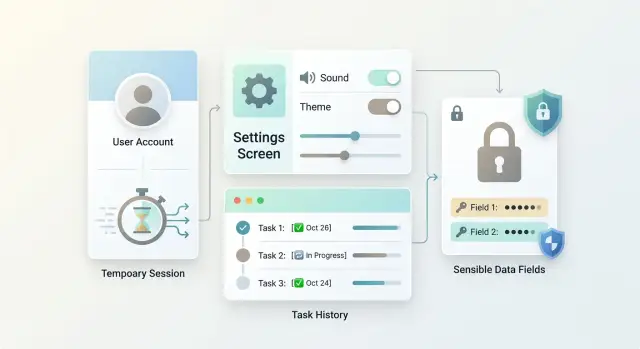
Что хранить в сессии и аккаунте: простые правила
Разбираем, что хранить в сессии и аккаунте: личные настройки, историю задач, токены и чувствительные данные без лишнего риска и путаницы.
что хранить в сессии и аккаунтеличные настройки аккаунта

13 янв. 2025 г.·6 мин чтения
LLM в контакт-центре: как помочь оператору, а не мешать
LLM в контакт-центре помогает оператору только при жёстком контроле времени ответа. Разберём подсказки, суммаризацию и следующее действие.
LLM в контакт-центреподсказки оператору

08 янв. 2025 г.·9 мин чтения
Подготовка GPU-кластера к утреннему пику по Москве
Подготовка GPU-кластера к утреннему пику по Москве: как заранее прогреть пулы, сдвинуть batch-окна и встретить рост нагрузки без очередей.
подготовка GPU-кластера к утреннему пикупрогрев GPU-пулов
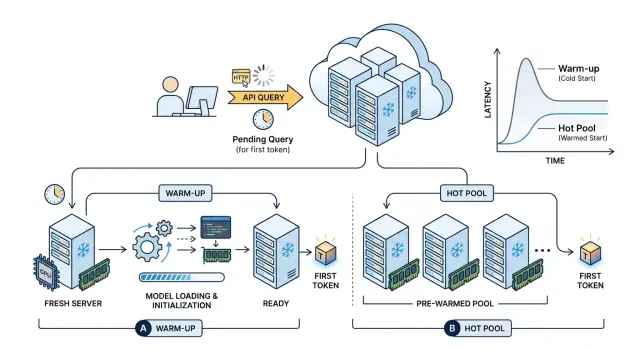
08 янв. 2025 г.·7 мин чтения
Холодный старт моделей с открытыми весами: прогрев или пул
Холодный старт моделей с открытыми весами не всегда лечится прогревом. Покажем, когда прогрев нужен, а когда выгоднее держать горячий пул.
холодный старт моделей с открытыми весамипрогрев модели

06 янв. 2025 г.·10 мин чтения
Evals на русском: как ловить регрессии без ручных проверок
Evals на русском помогают заметить поломки до релиза: разберем golden set, метрики, judge-модель и проверки в CI без ручной рутины.
Evals на русскомgolden set для LLM

04 янв. 2025 г.·11 мин чтения
Высокая доля refusals: когда это не баг в работе LLM
Высокая доля refusals не всегда говорит о сбое. Разберем, как отделить строгую политику модели от ошибки в промпте, данных и маршрутизации.
высокая доля refusalsошибки промпта

02 янв. 2025 г.·10 мин чтения
Контентный долг базы знаний: когда нужен редактор
Контентный долг базы знаний часто путают с «нужна новая модель». Разберём дубли, мёртвые ссылки, слабые заголовки и страницы без владельца.
контентный долг базы знанийредактура базы знаний
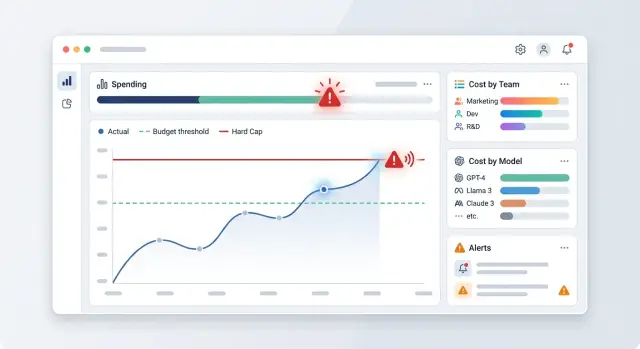
28 дек. 2024 г.·8 мин чтения
Контроль расходов LLM: алерты, hard cap и лимиты команд
Контроль расходов LLM помогает поставить алерты, hard cap и отчёты по командам так, чтобы счёт не удивил CFO в конце месяца.
контроль расходов LLMалерты бюджета LLM
27 дек. 2024 г.·10 мин чтения
Какие логи хранить для аудита без лишнего шума и затрат
Разбираем, какие логи хранить для аудита: какие поля ускоряют разбор инцидента, что писать выборочно и как не раздувать хранение.
какие логи хранить для аудитаполя логов для инцидента
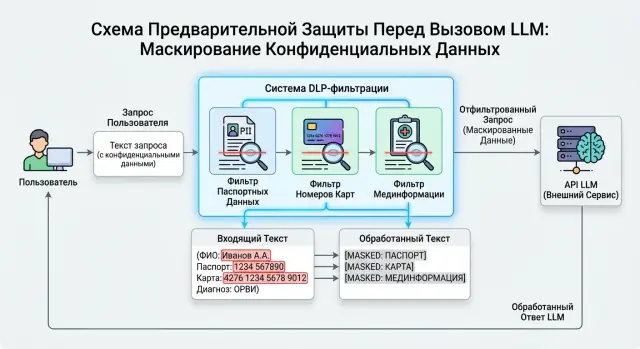
26 дек. 2024 г.·6 мин чтения
DLP перед вызовом модели: как отрезать чувствительные данные
DLP перед вызовом модели помогает убрать паспортные данные, номера карт и мединформацию до отправки в LLM. Разберем схему фильтров и проверки.
DLP перед вызовом моделифильтрация ПДн перед LLM
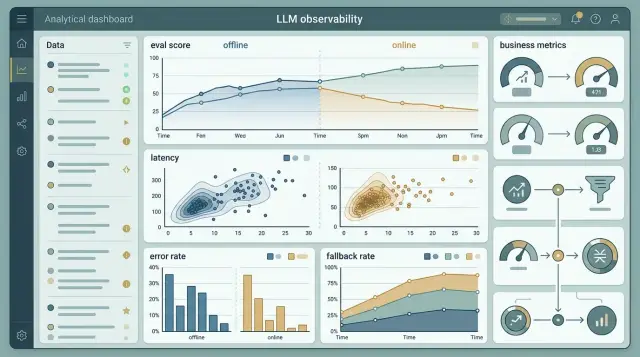
22 дек. 2024 г.·7 мин чтения
Оффлайн и онлайн метрики LLM: как свести их в дашборд
Оффлайн и онлайн метрики LLM не всегда совпадают. План статьи о том, как собрать дашборд, где рядом видны eval score, сбои и бизнес-эффект.
оффлайн и онлайн метрики LLMeval score и бизнес-метрики

20 дек. 2024 г.·9 мин чтения
Карточка модели для внутреннего каталога: нужные поля
Карточка модели для внутреннего каталога помогает команде быстро сравнить язык, ограничения, цену, задержку, логирование и статус допуска.
карточка модели для внутреннего каталогаполя карточки модели
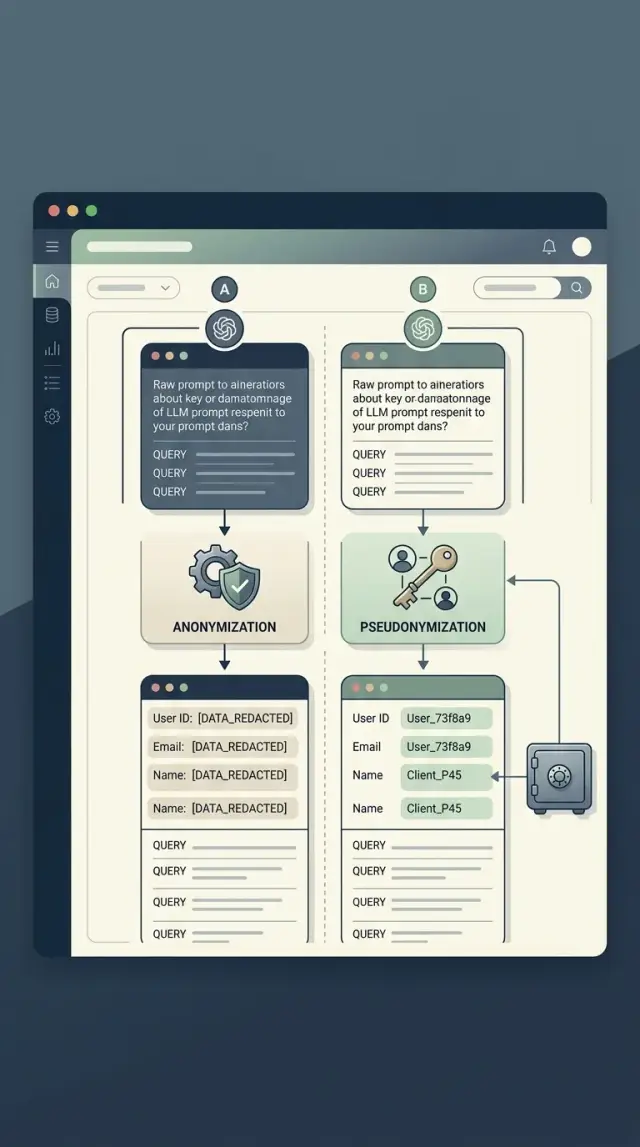
19 дек. 2024 г.·7 мин чтения
Анонимизация или псевдонимизация LLM-журналов по 152-ФЗ
Сравниваем анонимизацию или псевдонимизацию LLM-журналов: что выбрать для аналитики, аудита и расследования инцидентов по 152-ФЗ.
анонимизация или псевдонимизация LLM-журналов152-ФЗ и журналы LLM
11 дек. 2024 г.·7 мин чтения
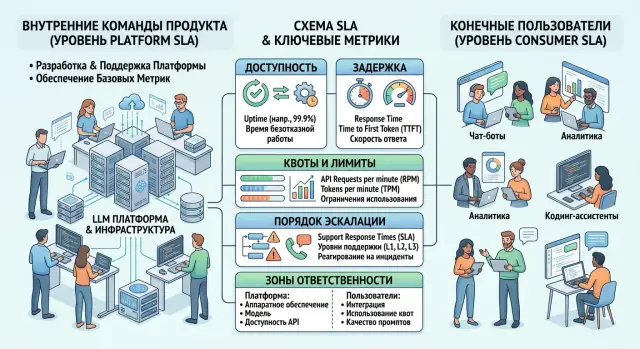
SLA для внутренних клиентов LLM-платформы без путаницы
SLA для внутренних клиентов LLM-платформы нужен отдельно от внешнего SLA: разберем границы, метрики, ошибки и простой порядок согласования.
SLA для внутренних клиентов LLM-платформывнешний SLA LLM-сервиса

08 дек. 2024 г.·9 мин чтения
ROI внутренней LLM-платформы: как считать без иллюзий
ROI внутренней LLM-платформы считают через время команд, закупки, простои и риск. Разберем формулу, входные данные и пример для пилота.
ROI внутренней LLM-платформыэкономика LLM-платформы
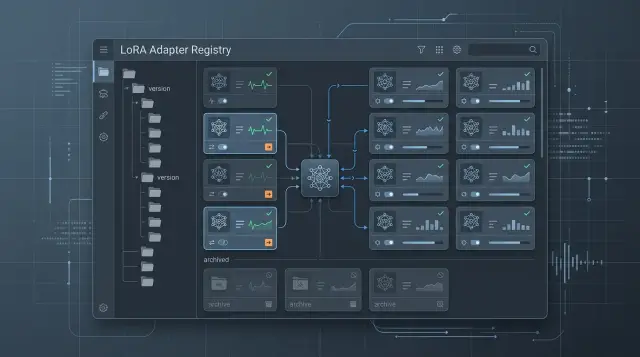
05 дек. 2024 г.·8 мин чтения
Хранение LoRA-адаптеров: имена, откат и архивирование
Хранение LoRA-адаптеров требует простых правил: как называть версии, проверять совместимость с базовой моделью, откатывать и убирать в архив.
хранение LoRA-адаптеровжизненный цикл LoRA
03 дек. 2024 г.·11 мин чтения
Внутренний маркетплейс моделей: владелец, доступ, вывод
Внутренний маркетплейс моделей помогает команде вводить новые модели без путаницы: назначать владельца, давать доступ и вовремя убирать их из каталога.
внутренний маркетплейс моделейправила доступа к моделям

30 нояб. 2024 г.·9 мин чтения
Продление контракта на LLM-сервис: что проверить до подписи
Продление контракта на LLM-сервис требует проверки SLA, истории инцидентов, условий по данным, цен и плана выхода без сбоев и лишних трат.
продление контракта на LLM-сервиспроверка SLA LLM
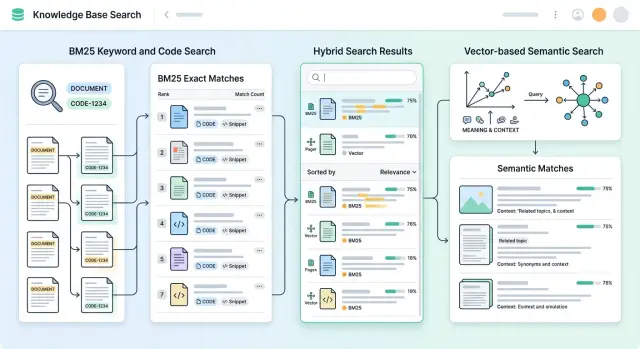
29 нояб. 2024 г.·8 мин чтения
Гибридный поиск для базы знаний: как совместить BM25 и векторы
Гибридный поиск для базы знаний помогает находить и точные фразы, и смысловые совпадения. Разберем BM25, векторы, смешивание рангов и проверки.
гибридный поиск для базы знанийBM25

28 нояб. 2024 г.·7 мин чтения
Суммаризация звонков: как считать пользу по CRM и follow-up
Суммаризация звонков стоит оценивать не по вау-эффекту, а по заполнению CRM, качеству follow-up и скорости работы команды после разговора.
суммаризация звонковоценка пользы ИИ
28 нояб. 2024 г.·9 мин чтения
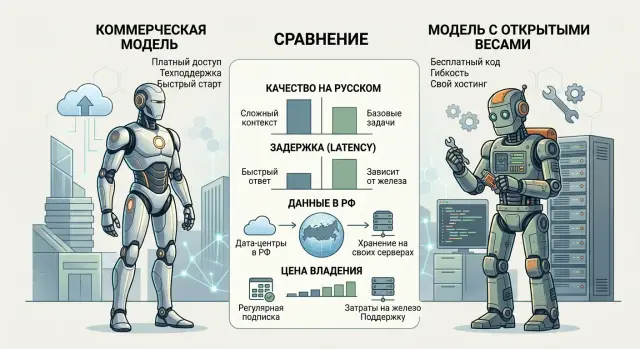
Коммерческая модель или модель с открытыми весами: как выбрать
Коммерческая модель или модель с открытыми весами: сравниваем качество на русском, задержку, данные в РФ и цену владения без общих слов.
коммерческая модель или модель с открытыми весамикачество LLM на русском
27 нояб. 2024 г.·8 мин чтения
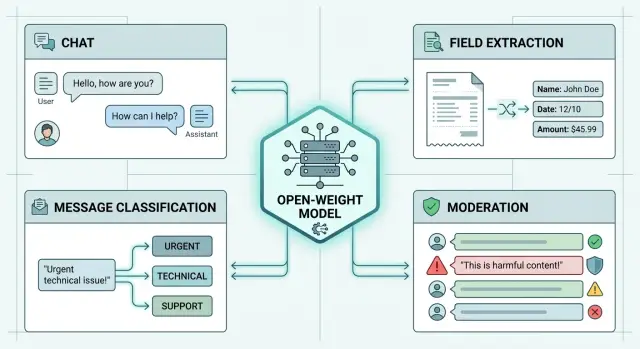
Одна open-weight модель для всего стека: где она тянет
Разбираем, когда одна open-weight модель закрывает чат, извлечение, классификацию и модерацию, а когда стек лучше разделить по задачам.
одна open-weight модельopen-weight модели
26 нояб. 2024 г.·8 мин чтения
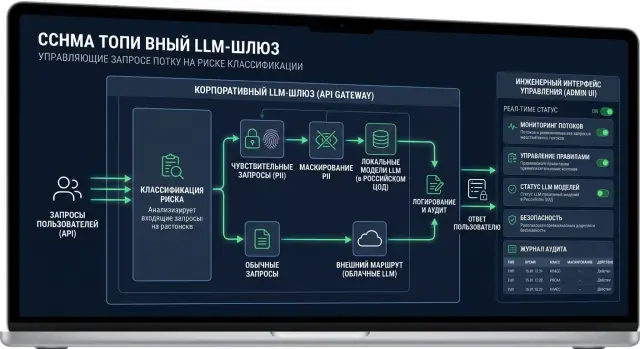
Контур для чувствительных запросов: как разделить трафик LLM
Контур для чувствительных запросов помогает отправлять PII и внутренние данные в локальные модели, а остальной LLM-трафик вести через обычный маршрут.
контур для чувствительных запросовмаршрутизация LLM по классам риска
25 нояб. 2024 г.·6 мин чтения
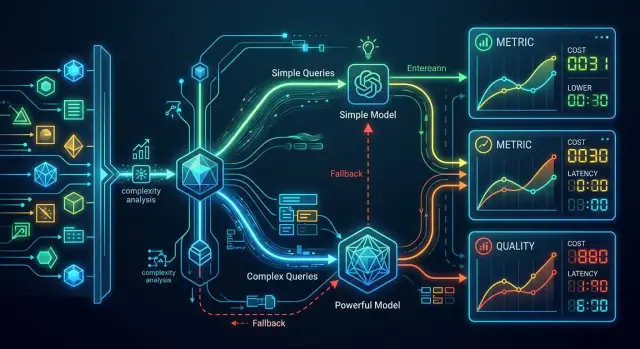
Маршрутизация моделей без лишних расходов в продакшене
Маршрутизация моделей помогает снизить затраты: разделите запросы по сложности, настройте fallback и отдавайте дорогим моделям только сложные случаи.
маршрутизация моделейfallback для LLM

21 нояб. 2024 г.·9 мин чтения
Проверка ответов модели: правила, LLM и regex для PII
Проверка ответов модели помогает поймать PII, рискованные советы и спорные формулировки. Разберем, где хватает regex, а где нужен второй LLM.
проверка ответов моделиPII в LLM
21 нояб. 2024 г.·8 мин чтения
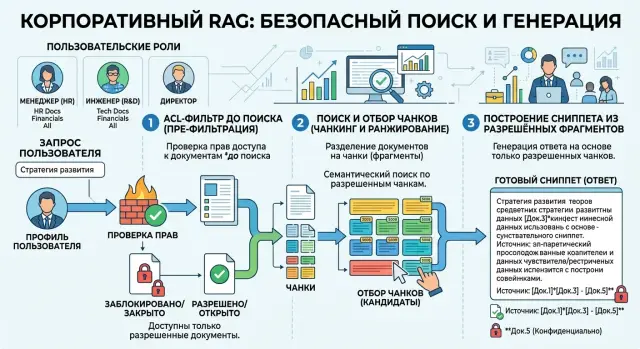
Права доступа в RAG: как не показать закрытый документ
Права доступа в RAG требуют фильтров до поиска, после ранжирования и перед выдачей. Разберём схему ACL, чтобы сниппеты не раскрывали закрытые данные.
Права доступа в RAGACL-фильтры в поиске
20 нояб. 2024 г.·7 мин чтения
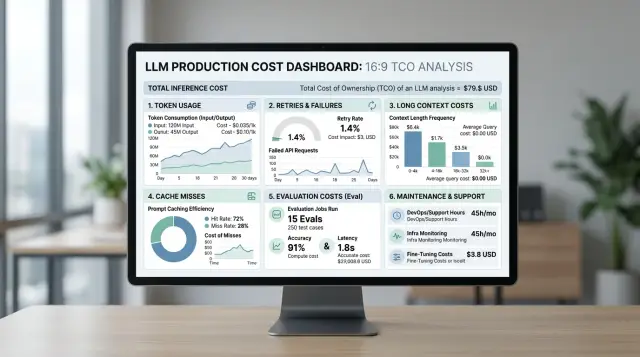
Стоимость LLM в продакшене: как считать без сюрпризов
Стоимость LLM в продакшене складывается не только из токенов. Покажем, как учесть ретраи, длинный контекст, eval, кэш и поддержку.
стоимость LLM в продакшенерасчет затрат на LLM
16 нояб. 2024 г.·7 мин чтения
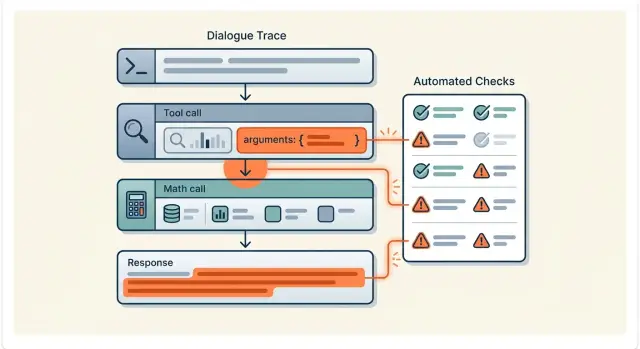
Оценка tool use: автоматические проверки без ручного разбора
Оценка tool use без ручного просмотра: как собрать автопроверки аргументов, порядка вызовов и финального ответа для LLM.
оценка tool useавтопроверки для LLM

16 нояб. 2024 г.·8 мин чтения
Внутренняя политика использования LLM для всех команд
Внутренняя политика использования LLM помогает закрепить единые правила для разработки, поддержки и бизнеса без разночтений в чатах.
внутренняя политика использования LLMправила работы с LLM
08 нояб. 2024 г.·7 мин чтения
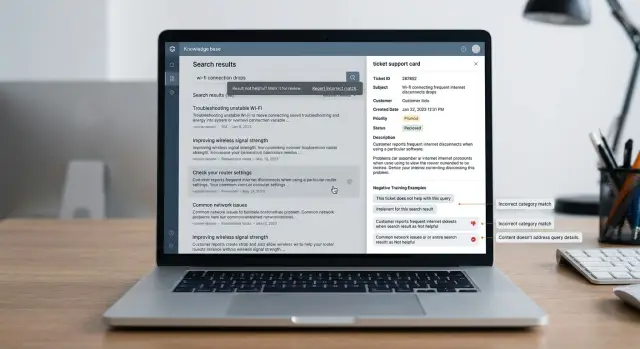
Отрицательные примеры для поиска по базе знаний: как собрать
Разберем, как собирать отрицательные примеры для поиска по базе знаний из плохих кликов, жалоб саппорта и пустых выдач, чтобы точнее настроить поиск.
отрицательные примеры для поиска по базе знанийнастройка ретривера

06 нояб. 2024 г.·11 мин чтения
Пакетная обработка LLM-задач ночью без лишней нагрузки
Пакетная обработка LLM-задач помогает вынести классификацию, суммаризацию и разметку из онлайн-контура и снизить дневную нагрузку.
пакетная обработка LLM-задачночная обработка запросов
05 нояб. 2024 г.·9 мин чтения
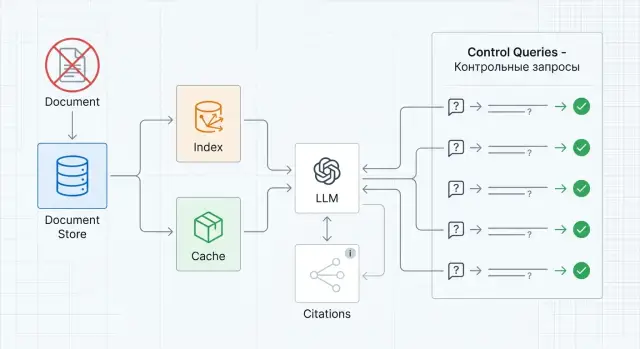
Удаление документа из RAG без следов в ответах на практике
Покажем, как провести удаление документа из RAG: очистить индекс, кэш и цитаты, а затем проверить систему контрольными запросами.
удаление документа из RAGочистка индекса RAG

31 окт. 2024 г.·9 мин чтения
Пики нагрузки после релиза LLM-функции: запуск по сегментам
Пики нагрузки после релиза LLM-функции часто ломают общий контур в день анонса. Разберем сегменты, лимиты, очереди и порядок выката.
пики нагрузки после релиза LLM-функциираскатка LLM по сегментам
30 окт. 2024 г.·10 мин чтения
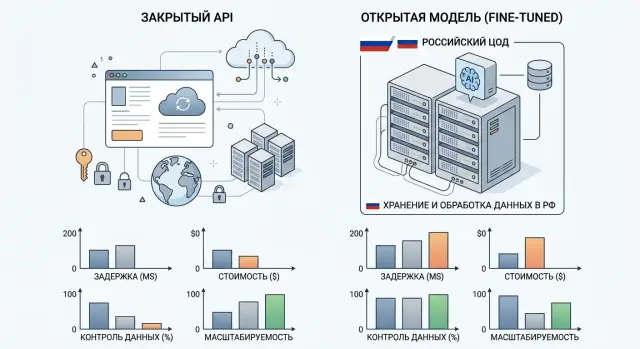
Fine-tuned open-weight модель: когда она выгоднее API
Fine-tuned open-weight модель окупается не всегда: разбираем, где она даёт ниже задержку, больше контроля над данными и понятную экономику.
Fine-tuned open-weight модельзакрытый API
26 окт. 2024 г.·6 мин чтения
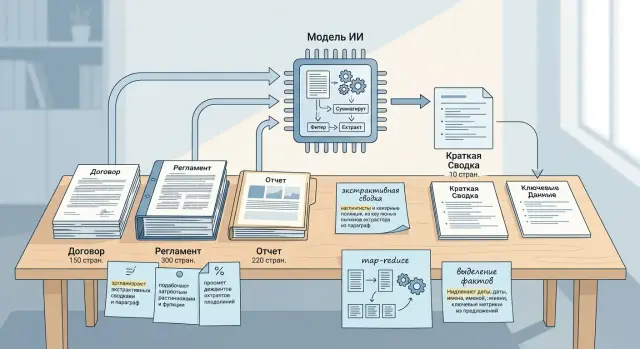
Сжатие контекста перед запросом: сводка, map-reduce, факты
Сжатие контекста перед запросом помогает уместить длинные регламенты, договоры и отчеты в один промпт. Сравним три подхода и их слабые места.
сжатие контекста перед запросомэкстрактивная сводка

25 окт. 2024 г.·7 мин чтения
Eval-контур для русскоязычных LLM-задач без регрессий
Покажем, как собрать eval-контур для русскоязычных LLM-задач: выбрать кейсы, ввести офлайн и онлайн проверки и ловить регрессии до релиза.
eval-контур для русскоязычных LLM-задачофлайн проверка LLM

23 окт. 2024 г.·10 мин чтения
Политика удаления промптов и ответов по типам задач
Политика удаления промптов и ответов зависит от задачи: поддержка, аналитика и документы требуют разных сроков хранения.
политика удаления промптов и ответовсроки хранения данных LLM

22 окт. 2024 г.·11 мин чтения
Договор с LLM-провайдером: что проверить до запуска
Договор с LLM-провайдером стоит проверить до запуска: где хранятся данные, кто из субподрядчиков их видит и как провайдер сообщает об инцидентах.
договор с LLM-провайдеромхранение данных LLM
12 окт. 2024 г.·7 мин чтения
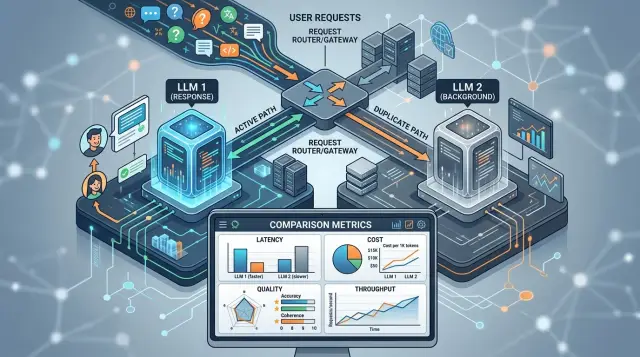
Теневой трафик для проверки модели перед выпуском
Разберем, как запустить теневой трафик для проверки модели, собрать честные метрики и сравнить новую LLM с текущей без риска для пользователей.
теневой трафик для проверки моделисравнение моделей LLM

11 окт. 2024 г.·9 мин чтения
Порог доверия для автодействий: черновик, подсказка, автоотправка
Порог доверия для автодействий помогает решить, где оставить черновик, где дать подсказку, а где включить автоотправку без лишнего риска.
порог доверия для автодействийавтоотправка без человека

08 окт. 2024 г.·6 мин чтения
Ошибочный tool call: dry-run, квоты и откат на практике
Ошибочный tool call не должен списывать деньги, удалять данные и менять статусы. Разберем dry-run, квоты действий и откат для рискованных операций.
Ошибочный tool calldry-run для инструментов LLM
02 окт. 2024 г.·6 мин чтения
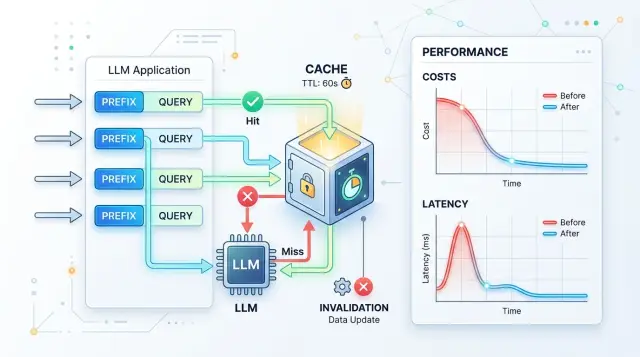
Prompt caching в продакшене: где он экономит, а где ломает
Разберём, когда prompt caching в продакшене снижает расходы, как выбрать TTL, настроить инвалидацию и смотреть метрики после запуска.
prompt caching в продакшенеttl кэша для llm
01 окт. 2024 г.·10 мин чтения
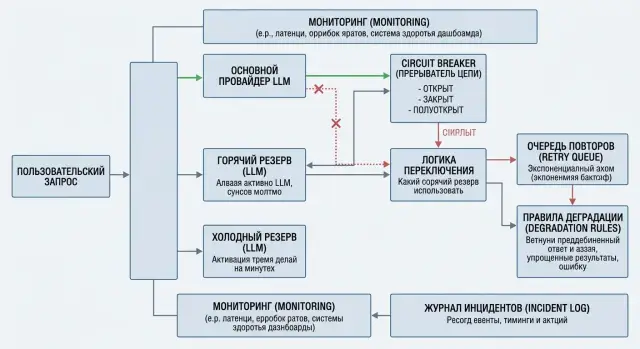
Аварийное переключение LLM: схема для критичных сценариев
Аварийное переключение LLM помогает пережить сбой провайдера: разберем запасные модели, circuit breaker, правила деградации и порядок внедрения.
аварийное переключение LLMcircuit breaker для LLM
28 сент. 2024 г.·8 мин чтения
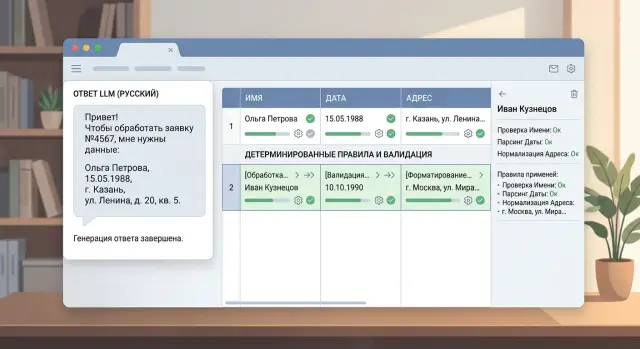
Нормализация русских имён, дат и адресов после LLM
Нормализация русских имён, дат и адресов после LLM: где хватит ответа модели, а где нужны правила, словари и строгая проверка формата.
нормализация русских имён, дат и адресовпостобработка LLM

27 сент. 2024 г.·8 мин чтения
Учёт экспериментов с моделями без Excel-хаоса в команде
Учёт экспериментов с моделями помогает не терять промпты, версии датасетов и evals. Разберём простую схему хранения, поиска и сверки.
учёт экспериментов с моделямиверсии промптов
26 сент. 2024 г.·10 мин чтения
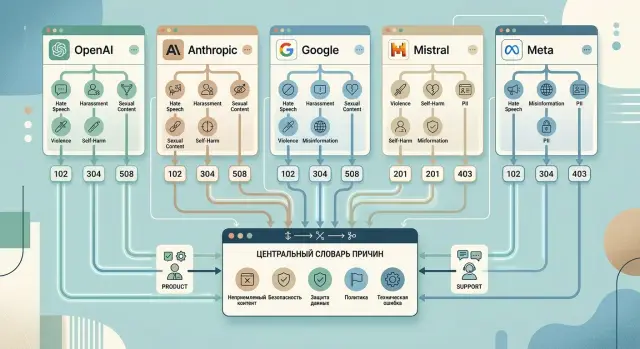
Единая политика блокировок LLM для мультипровайдерного стека
Единая политика блокировок LLM помогает свести разные safety-отказы к общему словарю причин, чтобы продукт и саппорт отвечали одинаково.
единая политика блокировок LLMкатегории модерации у провайдеров

24 сент. 2024 г.·9 мин чтения
LoRA или полный fine-tune для русской предметной области
LoRA или полный fine-tune: как выбрать подход для русской предметной области, не сломать формат ответа и не переплатить за обучение.
LoRA или полный fine-tuneдообучение LLM на русском
21 сент. 2024 г.·10 мин чтения
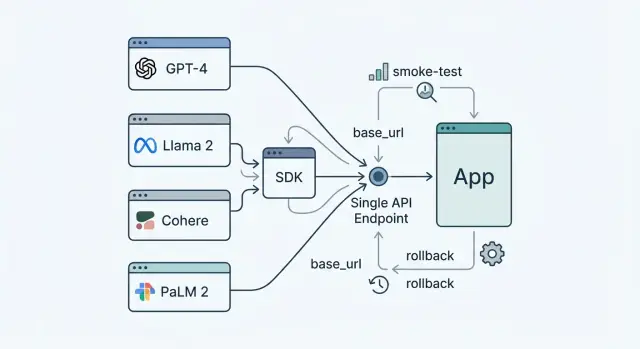
Единый API-эндпоинт для LLM: переход без переписки кода
Единый API-эндпоинт для LLM помогает сменить провайдера без переписывания кода. Разберем base_url, проверку SDK, smoke-тесты и быстрый откат.
единый API-эндпоинт для LLMсмена base_url

18 сент. 2024 г.·10 мин чтения
Роли и доступы в LLM-платформе: минимальный набор прав
Роли и доступы в LLM-платформе: как выдать разработчикам, аналитикам, службе безопасности и закупкам только нужные права без лишнего риска.
роли и доступы в LLM-платформематрица прав LLM

17 сент. 2024 г.·9 мин чтения
Чанкинг на русском для RAG: как резать регламенты и договоры
Чанкинг на русском для RAG требует другого подхода: абзацы, разделы и смысловые блоки ведут себя по-разному на регламентах и договорах.
чанкинг на русском для RAGразбиение документов для RAG
16 сент. 2024 г.·10 мин чтения
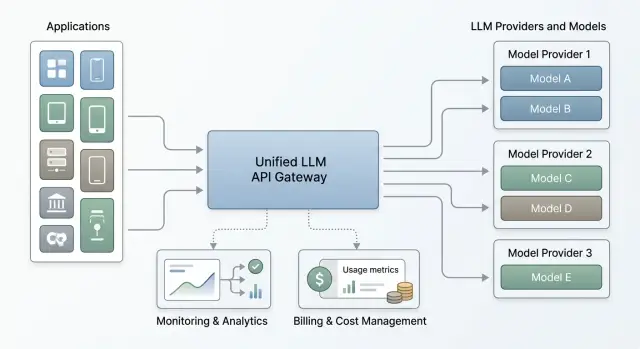
Зависимость от одного провайдера LLM: как убрать без переделок
Зависимость от одного провайдера LLM мешает быстро менять модели. Покажем слой совместимости, единый мониторинг и общий учет расходов.
Зависимость от одного провайдера LLMмаршрутизация моделей
12 сент. 2024 г.·10 мин чтения
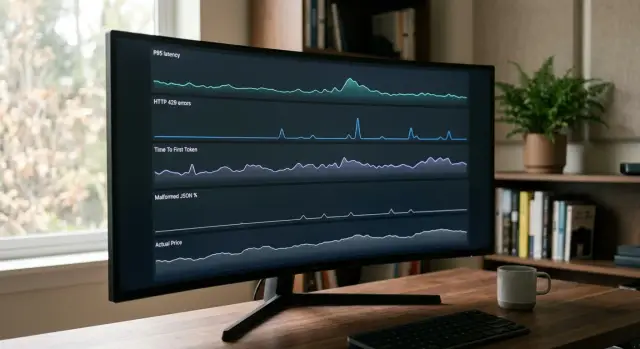
Сравнение провайдеров LLM по стабильности за неделю
Сравнение провайдеров LLM по стабильности: как за 7 дней собрать p95, 429, TTFT, долю битых JSON и фактическую цену для честного выбора.
сравнение провайдеров LLM по стабильностиp95 и TTFT для LLM

11 сент. 2024 г.·11 мин чтения
Длинные system prompt и задержка: что вынести из текста
Длинные system prompt часто добавляют лишние токены и скрытую задержку. Разберем, что стоит перенести в шаблоны, таблицы правил и логику сервиса.
длинные system promptзадержка LLM

09 сент. 2024 г.·11 мин чтения
Описание модели в каталоге: какие поля нужны команде
Описание модели в каталоге помогает выбрать модель без споров: какие поля добавить про задержку, класс данных, контекст, JSON и примеры задач.
описание модели в каталогекарточка модели LLM
27 авг. 2024 г.·11 мин чтения
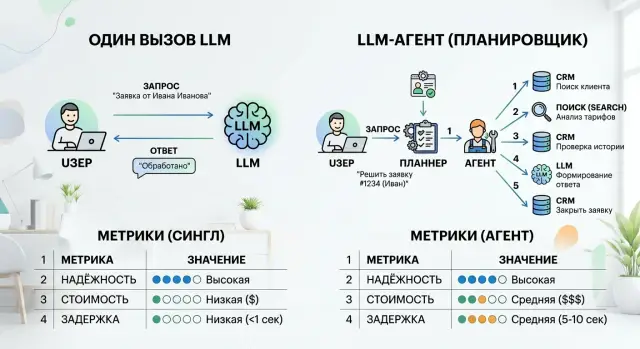
Планировщик шагов для агента или один вызов: что выбрать
Планировщик шагов для агента не всегда нужен. Разберём, где один вызов быстрее и дешевле, а где цепочка шагов даёт меньше ошибок.
планировщик шагов для агентаодин вызов LLM

26 авг. 2024 г.·10 мин чтения
Эмбеддинги для русскоязычного поиска: сравнение на своих данных
Пошаговая методика, как выбрать эмбеддинги для русскоязычного поиска на своих данных: набор запросов, разметка, метрики, ошибки и быстрый чек.
эмбеддинги для русскоязычного поискасравнение эмбеддингов
26 авг. 2024 г.·11 мин чтения
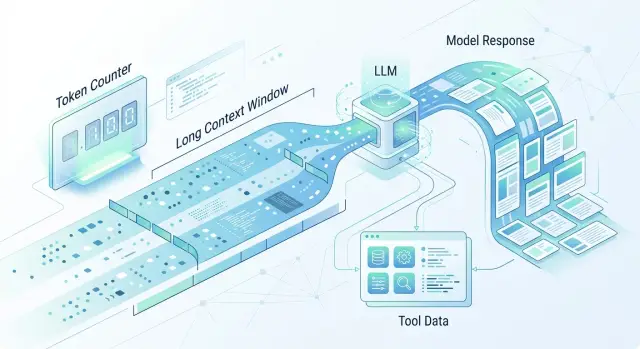
Лимит по токенам: когда он важнее лимита запросов
Лимит по токенам часто упирается раньше, чем лимит запросов. Разберём длинный контекст, большие ответы и вызовы инструментов с объёмными данными.
лимит по токенамдлинный контекст
19 авг. 2024 г.·6 мин чтения
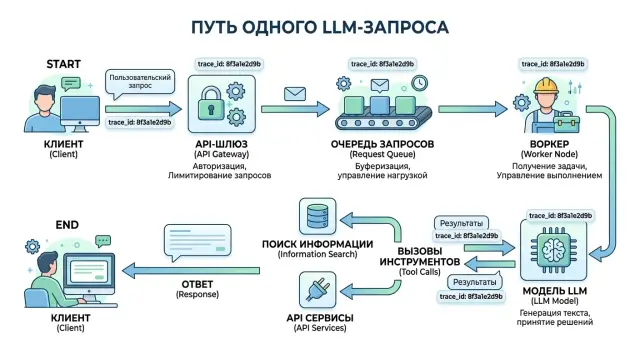
Трассировка LLM-запроса через шлюз, очередь и инструменты
Трассировка LLM-запроса помогает связать шлюз, очередь, вызовы инструментов и ответ модели, чтобы быстрее находить сбои и чинить прод.
трассировка LLM-запросаtrace id

18 авг. 2024 г.·7 мин чтения
LLM-пилот не готов к масштабу: как объяснить руководству
LLM-пилот не готов к масштабу, если команда не считает ошибки, цену запроса и ручную работу. Покажем, как обсудить это с руководством спокойно.
LLM-пилот не готов к масштабуриски LLM для бизнеса
17 авг. 2024 г.·8 мин чтения
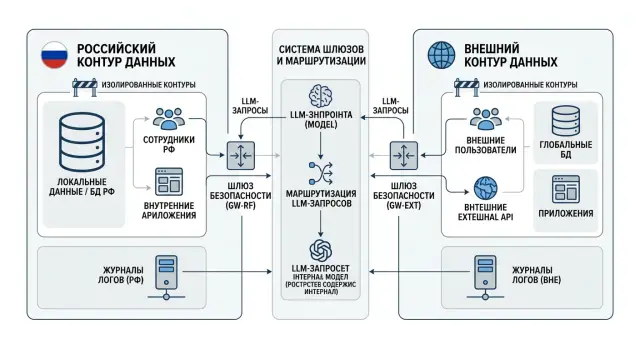
Российский и внешний контур данных: рабочий шаблон
Российский и внешний контур данных: как развести доступ, логи, интеграции и LLM-запросы, чтобы команды работали без смешения и лишнего риска.
российский и внешний контур данныхразделение контуров данных