Внутренний маркетплейс моделей: владелец, доступ, вывод
Внутренний маркетплейс моделей помогает команде вводить новые модели без путаницы: назначать владельца, давать доступ и вовремя убирать их из каталога.
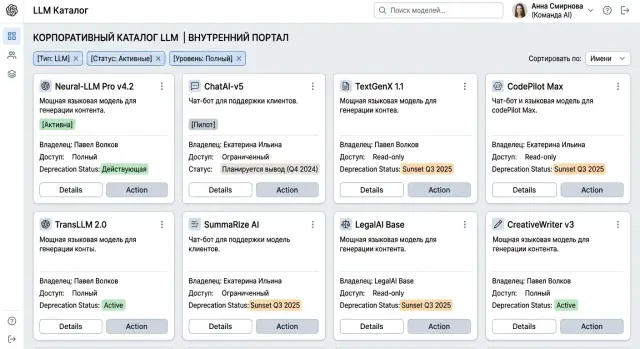
Почему каталог быстро превращается в хаос
Каталог ломается не тогда, когда моделей становится много. Он ломается тогда, когда одна и та же модель появляется под разными именами. Одна команда пишет "gpt-4.1", другая - "openai/gpt-4.1", третья заводит тот же вариант через другого провайдера и называет его по-своему. На экране будто три модели, хотя по факту это один и тот же инструмент.
Во внутреннем маркетплейсе моделей такая путаница быстро бьет по деньгам и по поддержке. Люди не понимают, что брать в работу, где смотреть лимиты и почему цена отличается. Если у компании есть единый шлюз к нескольким провайдерам, дублей обычно становится еще больше.
Следом появляется другая проблема: у модели нет владельца. Никто не следит за лимитами, стоимостью, сроком жизни тестового доступа и причиной, по которой модель вообще попала в каталог. Пока все спокойно, этого не видно. Когда провайдер меняет тариф или команда внезапно упирается в квоту, искать ответственного уже поздно.
Еще один источник беспорядка - доступ через личные чаты. Кто-то попросил открыть модель аналитикам, кто-то согласовал это в мессенджере, и правило как будто появилось. Но оно нигде не записано, не проверяется и не имеет срока. Новый сотрудник не понимает, почему ему доступ закрыт, а старый часто сохраняет его дольше, чем нужно.
Самый неприятный случай - старая модель продолжает работать после замены. Новый стандарт уже объявили, но часть сервисов все еще шлет запросы в старую версию. В итоге качество нельзя честно сравнить, бюджет расходится с планом, а разбор инцидентов тянется дольше обычного.
Обычно каталог ломается без громкой ошибки. Никто специально ничего не портит. Просто названия, владельцы, правила доступа и вывод модели из каталога живут отдельно друг от друга.
Какие роли нужны с первого дня
Если роли не назначены сразу, каталог быстро начинает расползаться. Одна команда считает модель общей, другая отправляет в нее чувствительные данные, а на вопрос о цене, лимитах или качестве никто не отвечает.
Для старта обычно хватает четырех ролей:
- Владелец модели решает, где и для каких задач ее можно использовать. Он отвечает за описание сценариев, версию по умолчанию, ограничения и решение о выводе из каталога.
- Администратор каталога проверяет карточку перед публикацией. Он смотрит на статус модели, теги, название, описание ограничений и проверяет, не дублирует ли запись уже существующую.
- ИБ задает рамки по данным и средам. Эта роль определяет, можно ли отправлять в модель персональные данные, где допустим запуск и какие команды вообще могут получить доступ.
- Платформенная команда следит за квотами, логами и техническим поведением модели. Она настраивает лимиты, смотрит ошибки и задержку, помогает не перегрузить общий контур.
Эти роли не обязаны быть разными людьми. В небольшой команде один человек может быть и владельцем, и администратором каталога. Но сами зоны ответственности лучше не смешивать. Если владелец сам себе одобряет карточку, а потом сам решает спор по доступу, ошибки почти неизбежны.
На практике роль стоит закреплять по имени, а не по отделу. Формулировка вроде "ML-команда" не отвечает ни за что, пока не указан конкретный человек.
Если команда работает через RU LLM, разделение ролей видно особенно хорошо. ИБ смотрит на требования по ПДн, хранение логов и бэкапов в РФ, маскирование PII и audit trail. Платформенная команда ведет квоты и наблюдение за запросами. Владелец модели решает, выводить ли ее в общий каталог или оставить только для одной группы.
Простой тест: если имя владельца нельзя найти за 30 секунд, модель еще рано публиковать.
Что собрать перед добавлением модели
Карточку модели лучше собрать до публикации, а не после первых жалоб. Если в каталоге лежит просто "Qwen" или "Llama" без версии, команды быстро путаются, сравнивают разное и спорят о цене на пустом месте.
В карточке должен быть минимум: точное название и версия, источник модели, понятные сценарии использования, лимиты и цена, правила работы с данными и журналами.
Название нужно фиксировать полностью. Не "Gemma" и не "DeepSeek", а конкретную запись, по которой инженер, закупка и платформа поймут, что речь об одной и той же модели. Если версия меняется, это уже новая запись или хотя бы новый релиз в каталоге. Иначе команда думает, что тестирует старую модель, а в проде получает другой ответ и другую цену.
Источник тоже влияет на решение. Одно дело, когда модель идет через внешнего провайдера. Другое - когда вы держите ее внутри компании. Если каталог строится поверх RU LLM, в карточке полезно сразу отмечать, идет ли модель через OpenAI-совместимый шлюз к внешнему провайдеру или используется вариант, размещенный на собственной GPU-инфраструктуре в российских ЦОДах. Это меняет ожидания по задержке, доступности и требованиям к данным.
Сценарии лучше описывать простыми словами. "Чат для сотрудников", "классификация обращений", "суммаризация звонков", "черновик ответа юристу" звучит намного полезнее, чем расплывчатое "подходит для текста". Если модель плохо держит длинный контекст или не любит строгий JSON, это тоже стоит написать прямо.
Цена без лимитов почти бесполезна. Нужны хотя бы базовые рамки: сколько стоит токен, есть ли rate limit, сколько одновременных запросов вы ждете и что будет в пике. Часто модель выглядит дешевой на демо, но на массовой суммаризации документов счет растет очень быстро.
С данными и журналами не стоит надеяться на договоренности на словах. Сразу зафиксируйте, можно ли отправлять персональные данные, что маскируется, как долго хранятся логи, кто видит audit trail и какие метки нужны для регуляторных проверок. Если на эти вопросы нет ответа, модель пока не готова к публикации.
Как добавить модель по шагам
Новая модель не должна попадать в каталог за один клик. Если пропустить пару простых шагов, команда быстро получает привычный набор проблем: у модели нет описания, за инциденты никто не отвечает, доступ открыли всем раньше времени.
- Сначала заведите карточку модели. Укажите понятное имя, версию, источник, статус, лимиты и пример сценария, где модель уместна. Если доступ идет через единый OpenAI-совместимый шлюз, сразу добавьте технический алиас, чтобы команда не гадала, что вызывать в коде.
- Потом опишите вход и выход. Нужны не общие слова, а практичные детали: какой контекст модель принимает, какой размер запроса допустим, нужен ли system prompt, в каком виде приходит ответ, как она ведет себя с JSON и где ломается чаще всего. Один короткий пример запроса экономит много времени.
- Назначьте владельца модели и резервный контакт. Владелец следит за качеством, ценой, лимитами и обновлениями. Резервный контакт нужен на случай отпуска, увольнения или ночного инцидента.
- Откройте тестовый доступ только одной команде. Лучше выбрать живой сценарий, а не песочницу без нагрузки. За несколько дней станет ясно, хватает ли качества, нет ли сюрпризов по стоимости и как модель работает с вашими правилами логирования и маскирования PII.
- Переводите модель в общий каталог только после короткой приемки. Обычно хватает трех подтверждений: тестовая команда проверила сценарий, владелец принял метрики, платформа зафиксировала правила доступа и статус поддержки.
Если хотя бы один шаг пропущен, модель лучше не публиковать. Пара лишних дней на оформление почти всегда дешевле, чем спешный откат после жалоб от нескольких команд.
Как закрепить владельца и его задачи
У каждой модели в каталоге должен быть один владелец по имени, а не "платформа" или "ML-отдел". Если отвечают все, не отвечает никто. На практике это быстро бьет по качеству, доступам и расходам.
Лучше назначать владельцем того, кто понимает, зачем модель вообще попала в каталог. Это может быть ML-инженер, продуктовый техлид или менеджер платформы. Должность тут вторична. Нужны право принимать решения и обязанность отвечать на вопросы.
В карточке модели стоит сразу зафиксировать, кто владелец и кто его замещает, куда писать по вопросам, когда пересматривать статус модели и по каким причинам ее можно отправить в архив.
Дальше начинается регулярная работа. Владелец следит за версией модели и датой последнего обновления. Если провайдер меняет цену, лимиты или саму модель, это должно появиться в каталоге в тот же день, а не через месяц, когда команда уже получила другой результат в проде.
Он же одобряет новые группы доступа. Не стоит открывать модель всем по умолчанию, если у нее высокая цена, слабая предсказуемость или ограничения по данным. Владелец смотрит, кому она нужна, для каких задач и не дублирует ли она уже доступный вариант.
Еще одна задача - вывод из каталога. Если модель стала дороже, отвечает хуже, редко используется или создает лишние риски, владелец не ждет общего собрания. Он переводит запись в статус на вывод, назначает срок и предлагает замену.
Наконец, владелец разбирает вопросы по качеству и цене. Пользователи часто жалуются не на саму модель, а на плохой промпт, неверный режим или слишком длинный контекст. Владелец собирает такие сигналы, сверяет их с метриками и решает, что делать дальше: оставить модель, изменить правила доступа или убрать ее из каталога.
Если команда работает через единый шлюз вроде RU LLM, эта роль становится еще полезнее. Для разработчика снаружи почти ничего не меняется: тот же SDK, тот же код, меняется только base_url. Но внутри кто-то должен понимать, какая модель и какой провайдер стоят за записью в каталоге, сколько это стоит и когда выбор пора пересмотреть.
Как задать правила доступа
Правила доступа лучше строить не вокруг самой модели, а вокруг риска. Одна и та же модель может быть уместна в песочнице и запрещена в проде. Поэтому сначала разделите доступ по командам и средам: dev, test, stage, prod.
Новые модели в прод лучше не пускать по умолчанию. Сначала команда прогоняет тестовый набор, смотрит на качество, цену и сбои, а потом владелец просит допуск в боевую среду. Такой порядок снимает частую проблему: кто-то нашел интересную модель, подключил ее в сервис, а через неделю выяснилось, что ответы плавают, а счет вырос вдвое.
Отдельное правило нужно для чувствительных данных. Если в запросах бывают персональные данные, платежная информация или внутренние документы, разрешайте только те модели и маршруты, которые согласованы с безопасностью и юристами. Для российского контура это обычно значит отдельный список провайдеров, хранение логов в РФ и маскирование PII. В таком сценарии команды часто используют единый шлюз вроде RU LLM, чтобы не собирать эти требования заново для каждого сервиса.
Набор правил обычно довольно простой:
- каждая команда видит только свой список моделей для dev и test;
- новая модель закрыта для prod, пока не пройдены тесты и не назначен владелец;
- чувствительные данные идут только по отдельному правилу и через одобренные модели;
- для каждой команды есть месячная квота по токенам и лимит по бюджету;
- у исключений есть согласующий, срок действия и причина.
Квоты нужны даже там, где команда "и так все понимает". Мягкий лимит предупреждает о перерасходе, жесткий лимит останавливает трафик до выяснения причин. Часто этого хватает, чтобы не потерять бюджет на одном неудачном эксперименте.
Исключения лучше оформлять коротко и явно. Кто согласует доступ в prod, кто разрешает работу с чувствительными данными, кто продлевает временный доступ - все это должно быть записано в каталоге, а не жить в переписке.
Пример для двух команд
Один и тот же каталог редко подходит всем одинаково. Если не разделить доступ по задачам, дорогая модель уйдет на черновики, а слабая - в важные отчеты.
Представим две команды. Поддержка клиентов каждый день отвечает на типовые вопросы, правит тон и собирает черновики писем. Им не нужна самая точная модель. Для такого сценария владелец открывает недорогую и быструю модель только для задач "черновик ответа", "краткое резюме диалога" и "классификация обращения". Расходы заметно снижаются, а качество остается приемлемым.
Аналитики работают иначе. Они готовят отчеты для руководителей, сводят данные из нескольких источников и проверяют формулировки. Здесь ошибка стоит дороже, чем лишние рубли за запрос. Поэтому им дают доступ к более точной модели, но только для сценариев "подготовка отчета", "сравнение версий текста" и "пояснение выводов". Поддержка эту модель даже не видит, чтобы не выбирать ее по привычке.
У владельца модели в такой схеме простая задача: не открыть модель всем сразу, а привязать ее к понятным случаям использования. Обычно достаточно четырех настроек: кто может вызывать модель, для каких задач, с каким лимитом и кто отвечает за качество ответа. Этого уже хватает, чтобы каталог не расползался.
Когда команда решает заменить старую модель новой, спешить не стоит. Старую запись оставляют в каталоге еще на неделю, но помечают как запасную для отката. Новые запросы постепенно переводят на новую версию, а старую держат для спорных кейсов и быстрых проверок. Если качество падает, владелец за один день возвращает прежний маршрут без аврала.
Как вывести модель из каталога без сбоев
Удаление модели из каталога редко ломается из-за самой модели. Обычно проблема в другом: ее отключают раньше, чем находят все сервисы, шаблоны промптов и ручные сценарии, которые на нее завязаны.
Сначала зафиксируйте дату замены и объявите ее заранее. Командам нужен не расплывчатый статус, а понятный план: какая модель уходит, какая приходит на замену, кто отвечает за переход и до какого дня можно откатиться. Для рабочей модели в проде часто хватает 2-4 недель, но для критичных процессов срок лучше увеличить.
Потом соберите реальные зависимости. Смотрите не только на код и SDK-вызовы. Проверьте батч-задачи, внутренних ботов, сохраненные промпты, пайплайны оценки и инструкции, по которым сотрудники работают вручную. Если запросы идут через шлюз с audit trail, как у RU LLM, найти активные вызовы и команды-владельцы заметно проще.
Полезный порядок такой:
- пометить модель статусом "снимается с поддержки";
- назначить замену и срок перехода;
- найти сервисы и промпты, которые еще используют старую модель;
- перевести запись в режим только для чтения;
- закрыть доступ после периода отката.
Режим "только для чтения" снижает риск новых зависимостей. Карточка модели остается в каталоге, описание и история настроек видны, но новые проекты уже не могут выбрать ее по умолчанию. Так команды не теряют контекст и не продолжают строить новые сценарии на том, что скоро исчезнет.
Небольшой пример. У команды поддержки есть бот на старой модели, а у аналитиков - три сохраненных промпта для разметки обращений. Если отключить модель в один день, остановятся оба процесса. Если сначала дать замену, неделю на проверку и короткое окно отката, переход пройдет спокойно.
Когда срок отката закончится, доступ лучше закрыть полностью, а карточку убрать из активного каталога. В архиве достаточно оставить владельца, дату вывода и причину. Через месяц это сэкономит много лишних вопросов.
Где команды ошибаются чаще всего
Самая дорогая ошибка выглядит скучно: модель добавили, а владельца не назначили. Пока все работает, это почти незаметно. Проблемы начинаются позже, когда нужно обновить версию, ответить на инцидент, поднять лимиты или объяснить счет. Если у модели нет конкретного владельца, вопросы зависают между ML, платформой и бизнесом.
Не меньше путаницы создает общий доступ для теста и для продакшена. Команде удобно открыть одну и ту же модель всем сразу, но потом тестовые сценарии смешиваются с боевыми. Один разработчик гоняет эксперименты на реальных лимитах, а другая команда случайно отправляет в пилот то, что должно идти только через проверенный маршрут. Тестовый доступ лучше разделять сразу: по среде, лимитам, журналам и типам данных.
Многие каталоги ломаются и на правилах данных. Команды пишут, что модель подходит для внутренних задач, но не фиксируют прямым текстом, что в нее нельзя отправлять. Нужен короткий запретный список: паспортные данные, платежная информация, медицинские сведения, сырые клиентские диалоги без маскировки. Даже если шлюз маскирует PII и сохраняет audit trail, это не отменяет простого правила: запреты нужно задать до первого запроса, а не после ошибки.
Еще одна частая история - старые версии копятся в каталоге без срока жизни. Через пару месяцев никто не помнит, какая версия рекомендована, какая нужна только для совместимости, а какую давно пора убрать. Разработчики берут знакомое имя и случайно остаются на устаревшей модели. Помогает простая дисциплина: дата публикации, дата пересмотра и дата вывода.
И наконец, команды часто смотрят только на качество ответов. Для внутреннего маркетплейса этого мало. Если модель отвечает чуть лучше, но стоит в четыре раза дороже, итог для бизнеса может оказаться хуже. Сравнивать стоит не абстрактный "ум", а цену одной полезной операции: классификации обращения, проверки документа, генерации черновика ответа.
Быстрый чек-лист перед публикацией
Перед публикацией карточки проверьте пять простых вещей. Такой проход занимает несколько минут, но потом убирает долгие переписки, лишние заявки и споры о том, кто отвечает за модель.
- Сверьте название и версию с уже существующими карточками.
- Назначьте владельца и запасной контакт.
- Проверьте, что правила доступа понятны без созвона.
- Запишите лимиты, квоты и бюджетный потолок прямо в карточке.
- Поставьте дату следующего пересмотра.
Для внутреннего маркетплейса моделей это базовая гигиена. Если пропустить хотя бы один пункт, карточка выглядит готовой, но пользоваться ей нормально нельзя.
Хороший тест очень простой: откройте карточку как человек из соседней команды. Если за 30 секунд понятно, что это за модель, кому писать, сколько можно тратить и когда запись пересмотрят, карточку можно публиковать.
Если каталог работает поверх RU LLM, добавьте в карточку еще и техническое имя маршрута или алиас. Тогда команды не перепутают бизнесовое название модели с тем, что реально вызывают через API.
Что сделать после запуска
Запуск каталога не завершает работу. Через пару недель станет видно, какие модели команды правда используют, где растут счета и какие позиции висят мертвым грузом.
Раз в месяц полезно смотреть на каталог как на рабочий продукт, а не как на список моделей. Сравнивайте спрос, стоимость и результат на реальных задачах. Иногда модель с меньшей ценой дает тот же итог. Иногда дорогая версия, наоборот, экономит часы ручной проверки.
Достаточно короткого ежемесячного цикла:
- проверить трафик по моделям и командам;
- сравнить расходы с прошлым месяцем;
- отметить модели с жалобами, сбоями или долгим ответом;
- найти позиции без владельца;
- решить, что оставить, ограничить или отправить в архив.
Обратную связь лучше собирать не общими вопросами, а по конкретным сценариям. Не "нравится ли вам модель", а "пишет ли она нормальные ответы для поддержки", "ломает ли JSON", "стала ли команда чаще перепроверять результат". Такие ответы быстро показывают, где каталог помогает, а где только создает лишний выбор.
Хорошо работает и простой порог для архивации. Если у модели нет владельца и по ней нет трафика 60-90 дней, держать ее в общем каталоге обычно нет смысла. Сначала переведите ее в статус "архив", уберите из выдачи по умолчанию и оставьте короткую заметку с причиной. Если кто-то все еще зависит от этой модели, это всплывет быстро и без аварии.
Больше всего пользы обычно дает связка цифр и живых отзывов. Например, команда аналитики может сказать, что модель стала дешевле, но начала чаще путать поля в таблицах. По графику расходов все выглядит хорошо, а по факту команда теряет по 20 минут на каждую проверку.
Если каталог строится поверх RU LLM, поддерживать такую схему проще: команды работают через единый OpenAI-совместимый endpoint и не переписывают SDK, код и промпты при смене base_url, а платформа держит маршрутизацию, биллинг и аудит в одном месте. Для компаний с требованиями по 152-ФЗ это особенно удобно, потому что логи и бэкапы остаются на серверах в РФ, а маскирование PII и AI-Law метки можно сразу учесть в общей модели контроля.