Единый API-эндпоинт для LLM: переход без переписки кода
Единый API-эндпоинт для LLM помогает сменить провайдера без переписывания кода. Разберем base_url, проверку SDK, smoke-тесты и быстрый откат.
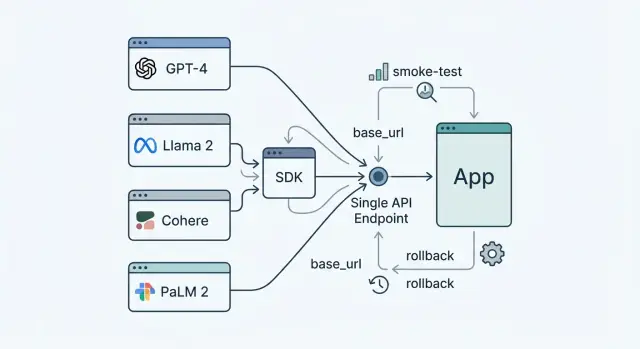
Почему команды переходят на один endpoint
Когда у команды несколько LLM-провайдеров, даже простая смена модели превращается в отдельную задачу. Нужно менять адреса, проверять формат ответов, вспоминать, где заданы таймауты и какие флаги работают только у одного провайдера. Из-за этого полезные изменения часто откладывают просто потому, что на них нет времени.
Единый endpoint убирает эту рутину. Команда один раз собирает интеграцию вокруг общего входа, а потом меняет поставщика или модель без правок по всему коду. Это не вопрос удобства. Это экономия часов, меньше скрытых зависимостей и меньше шансов сломать рабочий сценарий вечером перед релизом.
Проблема обычно шире, чем кажется. base_url редко живет в одном месте. Он встречается в инициализации SDK, переменных окружения, CI/CD, Helm values, прокси-конфигах и внутренних обертках над OpenAI-клиентом. Иногда старый адрес остается в тестах или в сервисе, который давно не трогали. Поэтому переход на один endpoint наводит порядок не только в коде, но и в настройках.
Ручное переключение между провайдерами обходится дорого. Команда держит несколько наборов конфигов, путается в лимитах, логах и биллинге и снова и снова делает одни и те же проверки. Если инцидент случается ночью, инженер сначала выясняет, какой endpoint сейчас работает в проде, и только потом разбирается с ошибкой. Так быть не должно.
Обычно срочный переход нужен в четырех случаях:
- провайдер часто меняет доступность или квоты
- нужно быстро тестировать новые модели без релизов
- появились требования по хранению данных в РФ
- ручная поддержка интеграции уже заметно съедает время
Если у команды нет тестового контура, запросы сильно завязаны на нестандартные поля провайдера или интеграция сама по себе меняется каждую неделю, лучше сначала разобрать конфиги и точки вызова. В OpenAI-совместимых шлюзах вроде RU LLM переход часто и правда сводится к смене base_url, но хаос в настройках такая совместимость не исправит.
Что проверить до изменений
Сначала соберите полную карту вызовов LLM API. Обычно они разбросаны по нескольким местам: основной бэкенд, фоновые воркеры, чат-сервис, ETL-задачи, внутренние утилиты. Частая ошибка простая: команда меняет base_url в одном сервисе, а старый endpoint продолжает жить в двух других.
Проверьте не только прямые вызовы SDK, но и свои обертки. Во многих командах есть общий клиент, helper-функции, прокси-класс или слой логирования, где один раз задаются base_url, заголовки, таймауты и ретраи. Именно эти места обычно решают, пройдет миграция спокойно или превратится в цепочку мелких сбоев.
SDK тоже лучше сверить заранее. Посмотрите на точные версии библиотек, различия между сервисами и старые форки. Один сервис может использовать новый OpenAI SDK, другой - старый клиент, а третий вообще ходит raw HTTP. Формально все это работает, но на streaming, tools, JSON-ответах и обработке ошибок поведение часто разное.
После этого зафиксируйте, какие модели и параметры реально используются в проде. Нужен короткий и честный список: модель, режим вызова, streaming, temperature, max_tokens, system prompts, tools, response_format, embeddings, batch-задачи. Без этого легко перевести endpoint и случайно сломать редкий, но важный сценарий.
Боевой и тестовый трафик лучше разделить до начала работ. Не отправляйте первые проверки через те же очереди, лимиты и алерты, что и прод. Проще завести отдельный ключ, отдельный набор переменных окружения и явный флаг переключения.
Еще один полезный шаг - сохранить текущую базовую конфигурацию. Запишите таймауты, число ретраев, rate limits, размеры батчей и правила fallback. Если после смены endpoint задержка вырастет на 800 мс, спорить по памяти уже поздно. Нужна точка сравнения.
Как подготовить переход без спешки
Спокойный переход почти всегда начинается с одной вещи: вынесите base_url из кода в переменную окружения или конфиг. Тогда адрес меняют один раз, а не ищут по репозиторию и соседним сервисам.
Если вы уходите с OpenAI или OpenRouter на другой совместимый шлюз, сначала проверьте, что приложение действительно берет адрес из настроек при старте. Рядом лучше держать токены, имя модели и служебные заголовки. Чем меньше значений зашито в коде, тем проще переключение и откат.
Не тестируйте это сразу на боевом проекте. Поднимите отдельный стенд или хотя бы тестовый проект с теми же SDK, теми же промптами и похожими лимитами. Так вы увидите реальные проблемы совместимости и не заденете рабочий трафик.
Текущую конфигурацию сохраните как точку возврата. Обычно хватает одного файла или записи в секрет-хранилище, где лежат старый base_url, модель, таймауты, ретраи и служебные заголовки. Если что-то пойдет не так, команда вернется к прошлым настройкам за несколько минут.
Перед переключением договоритесь об окне работ и распределите роли. Один человек отвечает за код, один - за инфраструктуру, еще один - за проверку результата. Без этого даже мелкая проблема тянется дольше самой смены адреса.
Первыми отправляйте в тест самые понятные запросы: короткий chat completion без инструментов, запрос со строгим JSON-ответом, длинный промпт, близкий к боевому, потоковый ответ, если вы используете streaming, и запрос с вашими обычными системными инструкциями. Такой порядок быстро показывает, где все в порядке, а где уже нужны настройки или правки обвязки.
Как сменить base_url по шагам
Если интеграция уже работает через OpenAI-совместимый SDK, переход часто сводится к одной правке в конфигурации. Лучше менять base_url не внутри каждого запроса, а в одном месте: через переменную окружения, общий модуль инициализации клиента или файл настроек.
- Найдите точку, где создается клиент. Старый адрес не стоит держать в нескольких модулях, иначе потом сложно понять, какой сервис еще ходит по старому маршруту.
- Подставьте новый
base_url. Если вы уже используете OpenAI-совместимый API, SDK, формат запроса и промпты чаще всего менять не придется. - Сразу проверьте авторизацию. Ошибка нередко прячется в заголовке
Authorization, префиксеBearerили в том, как приложение читает ключ из переменной окружения. - Посмотрите на имя модели в поле
model. Сам API может быть совместимым, а имя модели - другим, с алиасом или своим префиксом. - Отправьте минимальный запрос на
chat completionс коротким сообщением и маленькимmax_tokens. Такой smoke-тест быстро показывает, жив ли маршрут целиком.
После первого ответа не останавливайтесь на статусе 200. Сравните структуру JSON, наличие choices, поле usage, время ответа и поведение клиента при сетевой ошибке. Если ваш код читает choices[0].message.content, проверьте именно этот путь, а не только общий статус.
На практике все выглядит довольно просто. Команда меняет base_url и ключ в конфиге, оставляет тот же SDK, отправляет короткий запрос вроде "Ответь одним словом: ok" и сравнивает результат со старым endpoint. Если статус, схема ответа и задержка в норме, можно переходить к более полным тестам.
Как проверить совместимость SDK
Проблемы чаще начинаются не в модели, а в клиентской обвязке. Команда меняет base_url, получает 200, а потом выясняет, что embeddings не работают, streaming рвется, а логгер режет куски ответа.
Сначала проверьте, не зашит ли старый endpoint внутри SDK, внутреннего клиента или helper-слоя. Часто base_url берут не из одной переменной, а из нескольких мест: отдельно для chat, embeddings и фоновых задач. Поэтому ищите не только прямые вызовы SDK, но и фабрики клиентов, middleware и тестовые заглушки.
Потом сверьте реальные сценарии, которые использует продукт. Если приложение работает в основном с chat completions, этого все равно мало. Нужно отдельно проверить обычный chat-запрос, embeddings, streaming с частичной выдачей токенов, вызовы с tools и ответы с response_format.
Тихие ошибки обычно прячутся в параметрах. Один SDK передает temperature как число с плавающей точкой, другой округляет его или молча игнорирует. То же бывает с tools: клиент отправляет старую схему, а команда замечает это только на function calling в проде.
Ошибки стоит смотреть руками. Сделайте два простых теста: намеренно отправьте плохой запрос, чтобы получить 4xx, и смоделируйте сбой провайдера, чтобы увидеть 5xx. Клиент должен не просто поймать код, но и сохранить текст ошибки, request id и тело ответа. Иначе потом тяжело разбирать инциденты.
Отдельно проверьте логирование. Некоторые обертки сериализуют ответ по своей схеме и ломают streaming или JSON в response_format. Мелочь, но времени на ней обычно теряют много.
Если вы переходите на RU LLM, основной риск обычно не в самом SDK, а в том, как приложение обрабатывает нестандартные поля, таймауты и ошибки. Сам шлюз остается OpenAI-совместимым, поэтому слабое место чаще находится в вашей обвязке.
Какие smoke-тесты сделать сразу
После смены base_url не нужен большой регресс. Достаточно короткой серии проверок, которая занимает 10-15 минут и быстро показывает, где сломалась совместимость.
Сначала отправьте самый простой текстовый запрос. Один короткий промпт на 1-2 предложения помогает быстро проверить авторизацию, формат ответа, имя модели, лимиты токенов и неожиданные 4xx или 5xx.
Потом смотрите не на качество текста, а на форму и поведение API. Обычно хватает пяти проверок:
- обычный
chat completionс коротким промптом - streaming на том же промпте
- embeddings на знакомом наборе из 5-10 строк
- запрос с коротким таймаутом и повторной отправкой
- сравнение полей
usage,idи кодов ошибок
Для streaming хватит запроса вроде "ответь одним абзацем". Смотрите, как приходят чанки, не зависает ли соединение и корректно ли клиент закрывает поток. Частая проблема простая: ответ есть, но парсер ждет другой формат событий.
С embeddings лучше не брать случайные тексты. Возьмите строки, которые уже использовались в поиске, кластеризации или антидубле. Так быстрее видно, если изменился размер вектора, тип данных или схема ответа.
Таймауты и ретраи проверяйте отдельно. Задайте слишком короткий timeout, убедитесь, что клиент падает предсказуемо, а потом повторите запрос с retry. Если у вас есть идемпотентность на стороне приложения, проверьте, не создает ли повтор лишние записи в логике продукта.
Если после перехода API отвечает нормально, но ломаются логи, метрики или алерты, проблема уже не в маршруте, а в обвязке. Это частый сценарий. Поэтому сравнивайте не только сам ответ модели, но и то, как приложение читает usage, id и тексты ошибок.
Если все базовые проверки прошли, можно двигаться дальше. Если нет, не пытайтесь исправить все сразу. Зафиксируйте первый сбой, верните старый base_url и разбирайте несовместимости по одной.
Как организовать быстрый откат
Откат работает только тогда, когда вы готовите его заранее. Если команда переводит LLM-запросы на новый endpoint, старый base_url должен лежать рядом в конфиге, в отдельной резервной переменной. Не в тикете и не в переписке, а там, откуда прод реально читает настройки.
Лучше всего работает простой флаг переключения. Один флаг отправляет трафик на новый адрес, второй возвращает его назад без правок в коде и без нового деплоя. Если вы временно переводите интеграцию на новый шлюз, старый маршрут должен оставаться доступным хотя бы на период наблюдения.
Откат нельзя запускать по ощущениям. Заранее задайте понятные условия: рост 5xx выше обычного уровня, заметное увеличение таймаута, пустые ответы, сбой авторизации или падение доли успешных запросов ниже согласованного порога. Решение принимает один человек, остальные исполняют его без обсуждений в момент инцидента.
Перед релизом проверьте четыре вещи:
- кто меняет конфиг в проде и у кого есть доступ
- где хранится текущее значение
base_urlи как быстро его вернуть - нужен ли рестарт сервиса после смены параметра
- кто следит за метриками в первые 15-30 минут
На практике часто ломается не сам откат, а действия после него. Команда вернула старый маршрут, ошибка исчезла, и все разошлись. Так делать не стоит.
После возврата зафиксируйте время переключения, сохраните логи проблемных запросов, отметьте долю затронутого трафика и временно заморозьте новые изменения. Иначе через день никто не вспомнит, что именно сломалось: новый base_url, заголовки, лимиты провайдера или поведение SDK.
Хороший откат занимает минуты. Если он требует созвона, ручной правки кода и поиска старых переменных, это уже второй релиз под давлением.
Пример миграции без переписывания кода
Представим сервис поддержки, который готовит черновики ответов операторам и ищет похожие обращения. Он уже работает через OpenAI-совместимый SDK, а все вызовы LLM идут через один клиент. Адрес API и ключ хранятся в переменных окружения, поэтому новый endpoint можно подключить без правок в бизнес-логике.
Для пилота команда не трогает прод. Сначала она поднимает staging, меняет только base_url на новый совместимый адрес и оставляет те же SDK, промпты и схему ответов. Если клиентский код не зашивал старый хост вручную, изменений на этом этапе немного: новый env-файл, новый секрет и короткая проверка запуска.
Дальше маршрут простой: прогнать staging на наборе реальных обращений, проверить обычные ответы, streaming, таймауты и ошибки авторизации, затем перевести небольшой процент боевого трафика через флаг в конфиге и посмотреть на логи, задержку и формат ответа в интерфейсе операторов.
Если staging и первые 5% трафика дают тот же JSON, не ломают UI и держат приемлемую задержку, команда постепенно переводит остальной поток. Клиент при этом не переписывают. Меняется только точка входа.
Откат готовят заранее. Старый base_url не удаляют, а оставляют как запасной вариант. Если после переключения растет число 5xx, ломается streaming или ответы перестают проходить валидацию, дежурный возвращает прежний адрес и уводит сервис назад за пару минут.
В этом и смысл такого перехода: код почти не меняется, меняется маршрут. Если сервис изначально собран вокруг одного клиента и env-переменных, миграция больше похожа на аккуратную смену конфигурации, чем на новый проект.
Где чаще всего ошибаются
Самая частая ошибка выглядит безобидно: команда меняет только основной endpoint для chat-запросов и считает работу законченной. Потом внезапно падают embeddings, streaming или фоновые сценарии, потому что их оставили на старом адресе или вообще не проверили.
Вторая ловушка - старые таймауты. У разных провайдеров разная задержка на первый токен, потоковую выдачу и длинные ответы. Таймаут, который раньше был нормальным, после переключения может обрывать рабочие запросы на 20-30 секунде. Особенно часто это всплывает на streaming.
Еще одна типичная проблема связана с именами моделей. После смены base_url разработчик оставляет прежний model id, а новый шлюз ждет другое имя или алиас. Снаружи все выглядит почти правильно, но запрос получает 400, 404 или уходит не в ту модель.
Путаница с ключами тоже встречается постоянно. Тестовый ключ попадает в прод, боевой уезжает на стенд, а команда потом ищет причину странных ошибок доступа и лимитов. Секреты по окружениям лучше разнести и подписать так, чтобы их было сложно перепутать.
И самая дорогая ошибка - смотреть только на код 200. Нужны проверки на неверный ключ, несуществующую модель, пустой streaming-чанк, 429, 5xx и обрыв соединения. Именно эти случаи показывают, выдержит ли интеграция реальный трафик.
Короткий чек-лист перед релизом
Перед выкладкой полезно пройтись по нескольким вещам, которые чаще всего ломают переход не в коде, а в мелочах вокруг него.
- Все сервисы читают
base_urlиз конфига или переменных окружения. Если хотя бы один воркер, cron или background job хранит адрес в коде, релиз уже нельзя считать безопасным. - Версии SDK зафиксированы. Даже при OpenAI-совместимости внезапный апдейт клиента перед релизом легко смешает две причины сбоя в одну.
- Список моделей и реальные параметры запросов сверены. Чаще всего проблемы всплывают на
response_format, streaming, tool calling и ограничениях поmax_tokens. - Smoke-тесты на staging идут через тот endpoint, который пойдет в прод.
- План отката лежит там, где его увидит дежурная команда без поисков в чате. В нем должны быть точные шаги: что переключить обратно, кто это делает и как проверить возврат трафика.
Есть еще одно простое правило: не совмещайте смену base_url с ротацией моделей в том же релизе. Когда меняется одна переменная, команда быстро понимает, где ошибка. Когда меняется все сразу, даже хороший лог не всегда помогает.
Если этот список закрыт, релиз обычно проходит спокойно. Если нет хотя бы одного пункта, лучше потратить еще полчаса до выкладки, чем потом разбирать ночной инцидент.
Что делать после первого успешного перехода
Первый удачный релиз не значит, что работа закончена. Дальше нужно решить, какая схема останется надолго: только proxy-слой с единым endpoint или еще и размещение самих моделей в РФ.
Если пилот на внешних провайдерах прошел без сбоев, это еще не отвечает на вопросы про данные. Для продакшена проверьте, где хранятся логи, попадают ли в них персональные данные, как маскируется PII и кто отвечает за резервные копии. На этом этапе многие понимают, что сменить base_url было легко, а требования к хранению и аудиту куда важнее.
Стоит отдельно оценить, нужен ли один OpenAI-совместимый endpoint сразу для нескольких провайдеров. Это удобно, когда один маршрут идет на дешевые запросы, другой - на более точные, а третий остается запасным на случай лимитов или деградации. Тогда переход перестает быть временным обходным решением и становится нормальной рабочей схемой.
Если для вас важны data residency, хранение логов в РФ и расчеты в рублях, такие условия лучше проверить отдельно. Например, RU LLM дает единый OpenAI-совместимый endpoint и маршрутизацию через разных провайдеров, а логи и бэкапы хранятся в РФ. Для части команд этого достаточно. Другим нужен еще и хостинг open-weight моделей на российской инфраструктуре, чтобы сильнее контролировать маршрут, задержку и требования по данным.
После выбора зафиксируйте решение во внутренней документации. Достаточно короткого документа: какой base_url считается основным, когда команда включает резервный маршрут, кто принимает решение об откате, какие smoke-тесты запускают после переключения и где лежат правила по логам, PII и срокам хранения.
Если этого документа нет, через месяц следующий дежурный снова будет искать ответы в чатах и старых тикетах. Если он есть, переход и откат занимают минуты, а не полдня.
Часто задаваемые вопросы
Правда ли, что для перехода часто хватает одной смены `base_url`?
Да, если у вас уже OpenAI-совместимый клиент и адрес API берется из конфига. В таком случае вы обычно меняете base_url, ключ и при необходимости имя модели, а код вызова и промпты оставляете как есть.
Но сначала проверьте, что старый адрес не зашит в воркерах, тестах, Helm values или внутренних обертках.
Где обычно прячется старый endpoint?
Ищите не только в инициализации SDK. Старый адрес часто лежит в .env, CI/CD, секретах, прокси-конфигах, фоновых задачах и helper-функциях.
Если у вас есть отдельные клиенты для chat, embeddings или streaming, проверьте каждый. Иначе часть трафика уйдет по новому маршруту, а часть останется на старом.
Что проверить до первого переключения?
Сначала соберите карту всех вызовов LLM: какие сервисы ходят в API, какие модели они используют и какие параметры реально идут в прод. Отдельно запишите streaming, tools, response_format, temperature, max_tokens, таймауты и ретраи.
Потом разделите тестовый и боевой трафик. Так вы проверите совместимость без риска для прода.
Какой smoke-тест сделать первым?
Начните с короткого chat completion на маленьком max_tokens. Такой запрос быстро покажет, работает ли авторизация, жив ли маршрут и совпадает ли схема ответа.
После ответа смотрите не только на 200, но и на choices, usage, время ответа и то, как ваш код читает choices[0].message.content.
Что может сломаться, даже если API вернул `200`?
Часто ломается не сам запрос, а обвязка вокруг него. Клиент может получить ответ, но парсер streaming ждать другой формат чанков, логгер может резать JSON, а код может падать на пустом usage или другом model id.
Поэтому после первого успешного ответа проверьте еще ошибки 4xx, 5xx, 429 и обрыв соединения.
Как быстро проверить `streaming`, `embeddings` и `tools`?
Проверьте их по отдельности на реальных сценариях. Для streaming достаточно одного запроса на абзац текста, а для embeddings лучше взять знакомые строки из поиска или антидубля, чтобы сразу увидеть смену размера вектора или формата ответа.
С tools и response_format смотрите на точную схему полей. Здесь мелкие отличия всплывают чаще всего.
Как подготовить откат, чтобы он занял минуты?
Держите старый base_url рядом с новым в конфиге и заведите простой флаг переключения. Тогда дежурный вернет прошлый маршрут без правок в коде и без спешки по репозиторию.
Заранее договоритесь, кто принимает решение об откате и при каких сигналах вы его делаете: рост 5xx, пустые ответы, сбой авторизации или заметная задержка.
Нужно ли менять SDK или промпты при миграции?
Не всегда. Если вы уже используете OpenAI-совместимый SDK, старый клиент часто продолжает работать после смены адреса.
Менять библиотеку стоит только тогда, когда у вас старый форк, raw HTTP с самописной схемой или разные сервисы используют несовместимые версии и ведут себя по-разному на streaming и ошибках.
Как провести миграцию и не задеть прод?
Не гоните первый тест через продовые очереди и лимиты. Поднимите staging или хотя бы отдельный проект с теми же SDK, теми же промптами и похожими настройками.
После этого переведите малую долю трафика через флаг и смотрите на задержку, ошибки и формат ответа в интерфейсе, а не только в логах.
Когда одной смены endpoint уже мало и нужно смотреть на хранение данных в РФ?
Если вам нужен не только единый endpoint, но и хранение логов и бэкапов в РФ, это уже отдельная часть решения. Тут мало просто сменить адрес API: нужно проверить PII, аудит, сроки хранения и расчеты.
В случае RU LLM команды обычно используют OpenAI-совместимый endpoint, а затем отдельно решают, хватает ли им прокси-слоя или нужен еще хостинг open-weight моделей на российской инфраструктуре.