Планировщик шагов для агента или один вызов: что выбрать
Планировщик шагов для агента не всегда нужен. Разберём, где один вызов быстрее и дешевле, а где цепочка шагов даёт меньше ошибок.
Почему этот выбор вообще возникает
Один и тот же агент может решать совсем разные задачи. Иногда ему нужно просто ответить на вопрос по уже известному контексту. Иногда - сходить в базу, проверить статус в CRM, вызвать поиск и только потом собрать ответ без ошибок.
Поэтому команда довольно быстро упирается в выбор: оставить один вызов LLM или добавить планировщик шагов. Оба подхода работают, но ломаются по-разному и стоят по-разному.
Для простого запроса лишняя логика часто только мешает. Если сотрудник просит короткое резюме документа или переформулировать письмо, цепочка из нескольких шагов добавляет токены, задержку и новые точки сбоя. Модель могла бы ответить сразу, но вместо этого сначала строит план, потом проверяет его, а потом еще раз формирует ответ.
С длинными задачами все иначе. Когда агенту нужно собрать данные из нескольких источников, применить правила компании и лишь потом что-то отправить наружу, один ответ нередко теряет ход работы. Модель пропускает проверку, меняет порядок действий или уверенно пишет то, что должна была сначала сверить.
В корпоративной среде этого уже достаточно, чтобы выбор перестал быть теоретическим. Здесь смотрят не только на качество текста. Важны еще три вещи: сколько ошибок схема дает на реальных запросах, сколько секунд ждет пользователь или внутренний сервис и сколько денег уходит на токены, инструменты и повторные прогоны.
Разница становится заметной быстро. Один вызов LLM обычно дешевле и быстрее. Планировщик чаще дает более аккуратное поведение в сложных сценариях, но за это приходится платить лишними шагами, более длинными логами и большим числом мест, где процесс может застрять.
Особенно хорошо это видно в продакшене, где запросы идут тысячами. Если команда работает через единый шлюз вроде RU LLM, сравнивать такие схемы проще: можно оставить тот же SDK, тот же код и те же промпты, а затем измерить цену, задержку и долю ошибок на одном наборе задач.
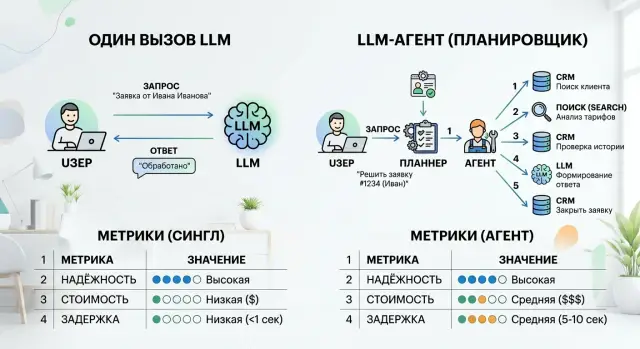
Чем отличаются один вызов и планировщик шагов
Один вызов LLM - это самый прямой вариант. Вы даете модели один промпт, и она сразу возвращает ответ. Вся логика сидит внутри этого запроса: инструкция, контекст, формат вывода и ограничения.
Такой подход хорош, когда задача короткая и цель ясна. Например, классифицировать обращение, переписать текст в нужном тоне, сделать краткое резюме документа или достать несколько полей из письма.
Планировщик шагов работает иначе. Сначала система определяет, из каких шагов состоит задача. Потом она ведет процесс по этим шагам: вызывает модель несколько раз, проверяет промежуточный результат и решает, что делать дальше.
Обычно между шагами агент подключает инструменты. Он может запросить данные из CRM, найти договор в базе, сверить поля, что-то посчитать кодом и только потом собрать финальный ответ. Это уже не один большой запрос, а цепочка небольших решений.
Главная разница - в том, где находится контроль. В одном вызове вы надеетесь, что модель сама аккуратно пройдет весь путь внутри одного ответа. В планировщике маршрут задан явно, и систему проще остановить до того, как ошибка уйдет дальше.
У планировщика есть понятный плюс: процесс легче наблюдать. Видно, на каком шаге агент ошибся, какой инструмент вызвал и что вернула проверка. Для продакшена это часто важнее, чем красивый ответ на демо.
Но контроль не бывает бесплатным. Каждый шаг добавляет задержку, тратит токены, усложняет логику и дает еще одну точку сбоя. Поэтому один вызов чаще выбирают там, где ошибка не ломает бизнес-процесс и ответ легко перепроверить человеку. Планировщик нужен там, где задача состоит из нескольких зависимых действий и пропуск одного шага уже дорого стоит.
Простое правило такое: если модель должна просто ответить, часто хватает одного вызова. Если ей нужно сначала понять, потом проверить, потом что-то запросить и только после этого решить задачу, без явных шагов быстро начинаются сбои.
Где одного вызова обычно хватает
Один вызов хорошо работает там, где задача укладывается в понятный вход и один понятный выход. Если модели не нужно искать данные по разным системам, выбирать следующий шаг или перепроверять себя через инструменты, лишняя агентность только добавит сбои и задержку.
Самый частый пример - простая классификация. Короткий текст обращения вроде "не проходит оплата" или "не могу войти в личный кабинет" обычно можно сразу отнести к нужной категории, приоритету или очереди. Для таких задач модель отвечает быстро, а результат легко проверить на выборке из реальных обращений.
То же касается извлечения полей из типового письма или документа. Если формат более-менее стабилен, один вызов с жестким JSON-ответом часто решает задачу без планировщика. Например, из письма можно достать номер договора, дату, сумму и тему запроса. Здесь лучше работает не "умный агент", а аккуратный промпт и четкая схема полей.
Короткие резюме тоже почти всегда укладываются в один запрос. Чат с клиентом, запись звонка после расшифровки или длинную заявку модель может сжать до нескольких строк, выделить проблему и предложить следующий шаг. Для поддержки и продаж этого обычно достаточно, особенно если оператору нужен черновик, а не окончательное решение без человека.
Перевод, переформулирование и подготовка ответа - еще один класс задач, где один вызов обычно выигрывает. Модель переводит текст, делает тон спокойнее, убирает канцелярит или пишет вежливый черновик письма. Если не нужно ходить в CRM, базу знаний и биллинг, цепочка из нескольких шагов здесь редко окупается.
Обычно одного вызова хватает, если вход короткий или средней длины, формат результата заранее известен, внешние данные не нужны, а ошибку можно перехватить на ручной проверке. На практике это дает три плюса сразу: ниже стоимость, меньше задержка и меньше точек отказа.
Где без планировщика трудно
Планировщик нужен там, где ответ нельзя честно собрать из одного куска текста. Если агенту надо сходить в поиск, потом в CRM, потом в базу знаний и сверить, что данные не спорят друг с другом, один вызов LLM часто срежет угол. Он выдаст гладкий ответ, но пропустит проверку.
Проблема обычно не в самой модели, а в порядке действий. Для многих корпоративных задач шаги нельзя менять местами: сначала найти клиента, потом проверить статус договора, потом ограничения по продукту, и только после этого готовить ответ. Если агент пропустил один этап, ошибка уходит дальше по цепочке.
Без планировщика трудно, когда данные лежат в нескольких системах, ответ зависит от серии проверок, результат нужно сравнить с CRM или внутренним регламентом, а цена ошибки выше, чем лишние 2-3 секунды ожидания.
Хороший пример - письмо клиента о возврате денег. Агенту мало понять смысл письма. Он должен проверить номер заказа, историю обращений, статус оплаты, срок возврата по правилам и возможные исключения. Один вызов может сразу написать вежливый текст. Планировщик заставит систему пройти по шагам и остановиться, если где-то не хватает данных.
Такой подход особенно полезен там, где команде нужен разбор решения. Руководителю поддержки, комплаенсу или владельцу продукта важно видеть не только итог, но и путь: какой источник агент открыл, что нашел и почему остановился именно на таком ответе.
В банке, телекоме или госсервисе это часто обязательное условие. Если агент советует действие по клиентскому договору, команда должна понимать, что он не придумал ответ из памяти модели. Если запросы идут через RU LLM, разбор упрощают встроенные аудит-трейлы: по ним легче понять, на каком этапе цепочка свернула не туда.
Планировщик не делает систему умнее сам по себе. Он делает ее дисциплинированнее. Для задач с несколькими источниками, строгим порядком проверок и дорогой ошибкой этого обычно достаточно.
Как меняются надежность, стоимость и задержка
Один вызов почти всегда быстрее. У вас один запрос, один ответ и меньше мест, где цепочка может зависнуть. Для коротких задач вроде классификации письма, извлечения полей из документа или черновика ответа это обычно лучший вариант.
Планировщик почти всегда медленнее. Каждый шаг добавляет токены, сетевой вызов и время ожидания. Если агент сначала строит план, потом ищет данные, потом проверяет ответ и только после этого пишет итог, задержка растет на каждом этапе.
С ценой картина похожая. Один вызов обычно дешевле, потому что вы платите за один контекст и один ответ. В цепочке из нескольких шагов модель несколько раз читает инструкции, хранит промежуточные результаты и иногда вызывает не одну модель, а несколько.
С надежностью все не так однозначно. Для простой задачи лишние шаги часто только вредят: больше запросов, больше шансов на таймаут, пустой ответ или сбой интеграции. Но в составной задаче планировщик может дать более стабильный результат, если после каждого шага есть проверка. Модель ошиблась при поиске договора - система заметила это сразу, перезапросила данные и не пустила ошибку в финальный ответ.
Поэтому полезно смотреть хотя бы на четыре числа: среднюю задержку, p95 или p99, среднюю цену одного успешного ответа и цену ошибки, если промах ушел в продакшен. Последний пункт часто и решает спор.
Если ошибка стоит условные 5 рублей, нет смысла строить длинную цепочку ради лишних 2% точности. Если ошибка ведет к неверному тарифу, отказу клиенту или нарушению внутреннего правила, промежуточные проверки окупаются.
В продакшене длинные хвосты часто бьют больнее среднего времени. Один медленный шаг тормозит весь сценарий. Если вы маршрутизируете запросы через нескольких провайдеров, например через единый OpenAI-совместимый шлюз RU LLM, это видно особенно ясно: среднее время может выглядеть нормально, а p95 внезапно выходит за пределы SLA из-за одного этапа в цепочке.
Как выбрать подход для новой задачи
Начинайте не с архитектуры, а с результата. Сформулируйте его одной фразой так, будто это уже готовый выход системы: "определить тип обращения и вернуть черновик ответа" или "найти нужный пункт договора и объяснить его простыми словами". Если формулировка расплывчатая, команда почти всегда переусложняет решение.
Потом разберите задачу на части. Обычно здесь быстро видно, где хватит одного запроса к модели, а где нужен планировщик.
Если модели нужно только понять текст и сделать вывод, начинайте с одного вызова LLM. Если ей нужны данные из базы, документа или API, если надо сходить во внешние сервисы и потом проверить формат, полноту или бизнес-правила, скорее всего, потребуется более явная оркестрация.
Дальше соберите базовый вариант и прогоните его на реальных примерах, а не на пяти удобных тестах из головы. Возьмите обычные случаи, спорные, редкие и откровенно плохие входы. Часто выясняется неприятная, но полезная вещь: проблема не в том, что модели не хватает шагов, а в том, что промпт просит слишком много сразу или не задает четкий формат ответа.
Планировщик стоит добавлять только после этого. Причина должна быть конкретной: модель регулярно пропускает обязательный поиск, забывает проверить ограничение, путает порядок действий или не понимает, когда нужен вызов внешнего сервиса. Если сбои лечатся уточнением инструкции, схемой ответа или парой дополнительных примеров, отдельный слой оркестрации пока не нужен.
Есть и простой практический тест. Если человек решает задачу за один короткий взгляд на входные данные, часто сработает один вызов. Если человеку пришлось бы сначала открыть CRM, потом сверить правило, затем проверить исключения и только после этого писать ответ, агенту тоже нужен явный порядок шагов.
Сразу задайте пределы: максимум шагов, лимит токенов и предельное время ответа. Иначе даже полезный сценарий быстро превращается в медленный и дорогой процесс. Например, для поддержки можно ограничить цепочку тремя шагами и общим временем ответа в 8 секунд. Если задача не укладывается в рамки, система должна вернуть частичный результат или передать случай человеку.
Пример: письмо клиента в поддержку
В поддержке разница между одним вызовом и агентом с шагами видна очень быстро. Одни письма можно закрыть за пару секунд, другие ломаются, если модель пытается ответить без проверки данных.
Когда хватает одного вызова
Простое письмо вроде "Как поменять адрес доставки?" или "Где скачать чек?" обычно не требует цепочки действий. Один вызов LLM может сразу определить тему, оценить срочность и написать черновик ответа в нужном тоне.
Такой вариант дешевле и быстрее. Если модель получает само письмо, краткие правила ответа и формат вывода, она может вернуть структуру вроде "тема обращения", "приоритет", "черновик" и "нужна ли передача человеку". Для первой линии поддержки этого обычно достаточно.
На практике один вызов хорошо работает там, где ответ не зависит от внешних систем. Модель не проверяет заказ, не ищет историю клиента и не принимает решение о деньгах. Она просто разбирает текст и снимает с оператора рутину.
Когда нужен планировщик шагов
Сложнее письмо вроде "Заказ не пришел, деньги списались, можно ли отменить и вернуть часть покупки?" Здесь уже опасно отдавать все одному ответу модели. Ей нужны факты, а не догадка.
В таком случае задача раскладывается на проверяемые действия: разобрать суть письма и вытащить номер заказа, проверить статус в CRM или OMS, посмотреть историю клиента, найти правило возврата для нужной категории товара и только потом собрать черновик ответа для сотрудника.
Такой маршрут дольше и дороже, зато надежнее. Если система не нашла заказ, увидела конфликт в данных или уперлась в спорное правило возврата, она не должна отправлять ответ сама.
Для спорных случаев лучше оставить ручное подтверждение перед отправкой. Это особенно важно там, где есть возврат денег, скидка, блокировка аккаунта или риск ошибиться в сроках. Хороший черновик уже экономит время, а человек ставит финальную точку.
Ошибки при внедрении
Самая частая промашка проста: команда строит агента с планировщиком, памятью и набором инструментов для задачи, где хватает одного запроса к модели. Так бывает с разбором писем, кратким резюме звонка или извлечением полей из документа. Сложность сразу растет: больше отказов, выше задержка, труднее понять, где именно система ошиблась.
Есть и другая ошибка, более опасная. Агент получает плохой ответ от инструмента, но не останавливается. Он додумывает недостающие данные, пишет уверенный текст и передает его дальше по цепочке. Для поддержки, комплаенса или финансовых операций это хуже явного сбоя, потому что оператор видит аккуратный результат и верит ему.
Ограничения на число шагов часто вспоминают слишком поздно. Без жесткого лимита агент легко уходит в лишние циклы: повторно вызывает поиск, заново переписывает план, еще раз спрашивает тот же сервис. Каждая такая итерация тратит токены, время и квоты внешних систем.
Хорошее демо тоже обманывает. На отобранных примерах агент почти всегда выглядит умнее, чем на живом потоке. Реальная проверка начинается на логах продакшена: с опечатками, пустыми полями, длинными переписками, старыми форматами и редкими, но дорогими случаями.
Тревожные сигналы обычно видны рано. Агент делает 6-8 шагов там, где человек принимает решение за один экран. В трассировке нет явного статуса ошибки инструмента. Команда меряет качество на 20 "красивых" примерах вместо сотен реальных задач. Бюджет считают только по токенам модели, хотя заметную часть расходов часто дают поиск, OCR, антифрод-проверки, CRM API и повторные запросы при таймаутах.
Нормальный старт обычно скромнее. Сначала команда проверяет, можно ли решить задачу одним вызовом с жестким форматом ответа и понятной валидацией. Если этого мало, она добавляет один инструмент и лимит шагов. Полноценный планировщик стоит включать только после этого. Такой порядок выглядит скучнее демо, но в продакшене он обычно спасает и деньги, и нервы.
Что проверить перед запуском
Перед запуском нельзя смотреть только на то, насколько гладко модель пишет текст. Команда должна заранее договориться, какой результат нужен бизнесу: меньше ручной работы, быстрее ответ клиенту, ниже процент ошибок в маршрутизации заявок. Если такой метрики нет, выбор между одним вызовом и многошаговым агентом быстро превращается в спор о вкусах.
Сразу задайте пределы. Сколько шагов агент может сделать, сколько токенов он может потратить и сколько секунд запрос может жить в системе. Без этого даже хороший сценарий начинает обходиться слишком дорого.
Перед релизом обычно достаточно пяти проверок:
- Метрика успеха связана с деньгами, временем или риском, а не только с общей оценкой ответа.
- У задачи есть лимит по шагам, токенам и времени, после которого система останавливается.
- Каждый инструмент отдает короткие структурированные поля, а не длинный абзац текста.
- Логи сохраняют не только финальный ответ, но и промежуточные решения.
- У системы есть запасной путь: одиночный вызов, передача оператору или честный отказ без догадок модели.
На практике это экономит много времени. Если агент в поддержке не смог достать номер договора за два шага или не уложился в 8 секунд, лучше сразу отдать кейс человеку. Так сервис остается предсказуемым.
Отдельно проверьте разбор сбоев. Когда команда видит промежуточные вызовы и причины остановки, она чинит систему намного быстрее. Если инфраструктура уже работает через RU LLM, для такого разбора удобно использовать аудит-трейлы и логи запросов: по ним проще понять, какой инструмент вернул плохие данные и почему агент выбрал неверный следующий шаг.
Что делать дальше
Не спорьте о подходе на уровне вкуса. Возьмите 2-3 живых сценария, где ошибка и задержка уже влияют на работу команды. Лучше всего подходят задачи с понятным результатом: разбор письма клиента, извлечение полей из документа, ответ по базе знаний или черновик ответа оператору.
Для каждого сценария соберите одну и ту же выборку. Не берите только удобные примеры. Добавьте короткие запросы, шумные данные, редкие случаи и несколько явно сложных задач. Иначе один вызов LLM покажется лучше, чем есть, а планировщик - умнее, чем ведет себя под нагрузкой.
Смотрите не на общее впечатление, а на цифры: долю верных ответов на всей выборке, медианную задержку и отдельно p95 или p99, полную цену задачи, долю случаев, где нужен человек для исправления, и вред от ошибки в деньгах, времени или риске.
Один вызов часто выигрывает там, где ответ должен прийти быстро, а задача не требует поиска, проверки и нескольких решений подряд. Планировщик стоит держать только там, где он дает заметную прибавку именно в бизнес-метрике. Если точность выросла на 2%, а задержка стала в 4 раза выше и очередь поддержки встала, такой выигрыш мало что дает.
Хороший тест не делается за один вечер. Дайте обоим режимам одинаковую нагрузку, прогоните их в разное время суток и посмотрите на длинные хвосты. Среднее значение почти всегда выглядит прилично. Пользователи запоминают не среднее, а те ответы, которые пришли через 18 секунд или ушли в неверную ветку.
Если вы сравниваете много моделей и при этом держите контур в РФ, RU LLM может упростить такую проверку. Сервис дает единый OpenAI-совместимый эндпоинт, так что можно тестировать разные маршруты без переписывания SDK и вести логи и биллинг внутри России. Это удобно, когда нужно честно сравнить один вызов и агентный сценарий на одной и той же задаче.
После такого прогона решение обычно видно без лишних споров. Где хватает одного вызова, оставляйте простую схему. Где планировщик стабильно окупает свою цену и задержку, там он действительно нужен.
Часто задаваемые вопросы
Когда одного вызова LLM обычно достаточно?
Берите один вызов, если модель читает текст и сразу выдает понятный результат: классификацию, краткое резюме, извлечение полей или черновик ответа. Оператор потом быстро проверит итог, а системе не придется тратить время на лишние шаги.
В каких задачах без планировщика шагов сложно обойтись?
Планировщик нужен там, где агент сначала ищет данные, потом сверяет правила и только после этого отвечает. Если задача зависит от CRM, базы знаний, статуса заказа или других проверок, явный порядок шагов снижает риск ошибки.
Планировщик всегда дает более точный результат?
Нет, не всегда. На простой задаче он часто только замедляет систему и добавляет новые сбои, а на составной задаче он помогает держать порядок и не пропускать проверки.
Что обычно дешевле: один вызов или многошаговый агент?
Почти всегда один вызов. Вы платите за один контекст и один ответ, а планировщик тратит токены на каждый этап и может несколько раз дергать модель и инструменты.
Что быстрее для пользователя?
Если смотреть на обычные короткие запросы, быстрее работает один вызов. Планировщик прибавляет задержку на каждом этапе, поэтому его стоит держать только там, где проверка реально спасает от дорогих промахов.
Как выбрать подход для новой задачи?
Сначала опишите готовый результат одной фразой и проверьте, нужны ли внешние данные. Если модель может решить задачу по входному тексту, начните с одного вызова; если ей нужно идти в систему, проверять ограничения и собирать ответ по частям, берите планировщик.
Что выбрать для поддержки клиентов?
Для простых писем вроде вопроса о чеке или адресе доставки обычно хватает одного вызова. Для возвратов, отмен, скидок и спорных случаев лучше строить цепочку с проверкой заказа, правил и истории клиента, а финальную отправку оставить сотруднику.
Какие метрики важнее всего при сравнении двух схем?
Смотрите не только на качество текста. Команде полезно мерить долю верных ответов, медианную задержку, p95 или p99, полную цену успешного ответа и цену ошибки, если она дошла до клиента или внутренней системы.
Какие ошибки при внедрении встречаются чаще всего?
Часто команда сразу строит сложного агента там, где хватило бы строгого промпта и JSON-формата. Еще одна частая промашка — агент продолжает работу после плохого ответа инструмента и начинает додумывать данные вместо честной остановки.
Как безопасно проверить решение перед запуском в продакшен?
Начните с малого: задайте лимит шагов, токенов и времени, а потом прогоните систему на живых примерах, а не на удобных тестах. Если вы сравниваете варианты через единый шлюз вроде RU LLM, держите один и тот же SDK и один набор задач, чтобы честно увидеть разницу в цене, задержке и сбоях.