Мультиарендный LLM-шлюз: как разделить доступ между продуктами
Мультиарендный LLM-шлюз помогает обслуживать несколько продуктов через один API: отдельно считать бюджеты, хранить логи и задавать роли без лишних копий.
Где появляется проблема
Проблемы начинаются не в момент выбора модели. Они начинаются позже, когда у компании появляется несколько продуктов с разными сценариями: клиентский чат, внутренний помощник для сотрудников, генерация описаний, проверка обращений в поддержке. Пока трафик небольшой, многие команды живут с одним токеном и одним общим доступом к LLM API. Сначала это кажется удобным. Потом учет разваливается.
Финансы видят один счет вместо понятной картины по продуктам. Если расходы резко выросли, команде приходится вручную разбирать запросы и гадать, что случилось: неудачный релиз, слишком длинный промпт, сломанный fallback или сервис, который ушел в бесконечные ретраи.
С логами происходит то же самое. Когда все продукты пишут в одно место без разделения, поиск причины сбоя превращается в долгий разбор чужого шума. Инцидент в поддержке смешивается с тестами другой команды и с фоновыми задачами третьей. Вроде журнал есть, но он не помогает быстро ответить на простой вопрос: кто именно отправил запрос, к какой модели и за чей счет.
Общий доступ к моделям тоже быстро становится проблемой. Продукт, которому нужен быстрый и дешевый ответ, внезапно получает тот же набор моделей, что и исследовательская команда. В итоге простой сервис случайно ходит в дорогую модель, а внутренний инструмент получает доступ туда, куда ему лучше не ходить. Если у компании есть требования по аудиту и персональным данным, это уже не мелочь.
Отсюда и появляется идея сделать отдельный шлюз на каждый продукт. Но такой путь быстро раздувает расходы. Приходится дублировать настройки, мониторинг, правила доступа, биллинг и процедуры разбора инцидентов. Мультиарендный LLM-шлюз нужен ровно в тот момент, когда общий вход уже мешает, а отдельная инфраструктура для каждого продукта еще слишком дорога.
Что нужно изолировать между продуктами
Если несколько продуктов работают через один шлюз, границы нужно задавать явно. Иначе один сервис начинает тратить чужой бюджет, тестовая среда шумит в продовых логах, а подрядчик видит больше, чем должен.
Ограничиться разными ключами мало. В проде обычно приходится разделять сразу несколько вещей.
- Токены. У каждого продукта должен быть свой токен. У каждой среды тоже свой: prod, stage и dev отдельно.
- Лимиты. Их лучше задавать по деньгам, по числу токенов и по количеству запросов. Эти ограничения решают разные задачи.
- Метки в логах. Без
tenant_id,product_id,ownerиenvironmentвы видите только общий поток событий. - Роли. Команда продукта, сервисный аккаунт и внешний подрядчик не должны иметь одинаковые права.
- Список моделей. Продукту с поддержкой клиентов обычно нужен один набор моделей, внутреннему помощнику - другой.
Если провести эти границы заранее, можно сохранить одну инфраструктуру и не потерять контроль. У каждого продукта будет свой бюджет, свой след в логах и свой набор разрешений.
В OpenAI-совместимом шлюзе вроде RU LLM такие правила удобно держать в одном месте. Команда меняет base_url на api.rullm.com, продолжает использовать те же SDK и код, а сам шлюз применяет лимиты, маскирует PII в логах и оставляет аудит-трейл по каждому запросу.
Как устроить базовую схему шлюза
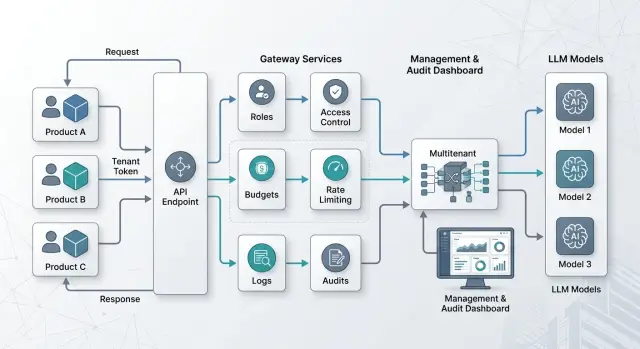
Рабочая схема обычно строится вокруг одного внешнего endpoint. Это упрощает интеграцию: мобильное приложение, внутренний ассистент и партнерский API ходят по одному адресу и не тащат в свой код логику выбора модели, лимитов и ролей.
Внутри шлюза нужен простой слой маршрутизации. Он получает запрос, проверяет токен и tenant_id, а затем отвечает на три вопроса: кто отправил запрос, к каким моделям у этого продукта есть доступ и как считать расход. Если токен и tenant не совпадают, шлюз должен сразу отклонить запрос, а не пытаться подобрать настройки по умолчанию.
Обычно такой схеме хватает пяти частей:
- единая точка входа;
- маршрутизатор с правилами по tenant и продукту;
- биллинг, который считает токены и стоимость отдельно;
- хранилище логов с метками, маскированием и сроками хранения;
- панель управления для лимитов и политик без нового деплоя.
Запрос проходит довольно просто. Сервис отправляет токен и служебные метки. Шлюз проверяет права, выбирает маршрут к нужной модели, записывает событие в лог и после ответа относит расход не на компанию целиком, а на конкретный продукт или команду.
В этом и есть смысл мультиарендного подхода. Инфраструктура общая, а правила изоляции живут в конфигурации, а не размазываются по коду каждого продукта.
Как выдать токены и роли
Если у вас три продукта и один общий шлюз, не давайте им общий API-токен. Это почти всегда заканчивается одинаково: смешиваются расходы, права доступа и журналы, а любой инцидент превращается в ручное расследование.
Изоляцию лучше строить не на договоренностях, а на понятных сущностях. Базовая схема обычно такая:
- Для каждого продукта создается отдельный tenant.
- Для каждого tenant выпускаются разные токены для prod, stage и dev.
- Каждый токен привязывается к владельцу: человеку или сервису.
- Права делятся по задачам: просмотр логов, выпуск токенов, смена лимитов, доступ к моделям.
Эта схема звучит скучно, но работает. У вас есть мобильное приложение, внутренний copilot и чат поддержки - значит, у вас уже три tenant. Внутри каждого по три токена: для продакшена, стейджинга и разработки. У поддержки можно оставить только безопасные модели и чтение логов, а право менять лимиты отдать владельцу продукта.
Полезно сразу сохранять в метаданных tenant, owner, environment и cost_center. Тогда любой спор по расходам, ошибкам или правам доступа решается не по памяти и переписке, а по записям в системе.
И еще одна простая проверка: токен продукта A не должен видеть логи, бюджеты и аудит продукта B, даже если запросы идут в тот же endpoint. Это стоит проверить руками до запуска, а не после первого инцидента.
Как настроить бюджеты, квоты и лимиты
У каждого продукта должен быть свой месячный потолок расходов. Без него мультиарендный шлюз быстро превращается в общую кассу: одна команда проводит дорогой эксперимент, а счет получает весь бизнес.
Но месячного бюджета мало. Он не спасает от ночного всплеска, неудачного релиза или сервиса, который внезапно начал повторять один и тот же запрос сотни раз. Поэтому рядом нужен дневной лимит. Он ловит перерасход раньше, чем проблема успеет сжечь бюджет за месяц.
Тестовые среды обычно тратят больше, чем кажется. Разработчики прогоняют один и тот же сценарий много раз, сравнивают ответы и не всегда замечают лишний трафик. Для dev и stage лучше сразу закрыть самые дорогие модели и оставить более дешевые варианты. Продакшену можно дать отдельные правила.
Жесткая блокировка без предупреждения тоже неудобна. Команда видит отказ, пользователи жалуются, а причину ищут уже после сбоя. Практичнее сначала отправить сигнал на 70-80% лимита. У владельца продукта появляется время убрать лишние вызовы, сократить контекст или временно переключить модель.
Обычно хорошо работает такой набор правил:
- отдельный месячный бюджет на каждый продукт;
- отдельный дневной лимит для защиты от всплесков;
- более строгие ограничения для dev и stage;
- предупреждение до блокировки;
- заранее назначенный человек, который может временно поднять лимит.
Последний пункт часто забывают. А потом в пятницу вечером никто не понимает, кто может согласовать перерасход и на какой срок. Лучше определить это заранее и ограничить временное повышение, например сутками.
Логи, метки и аудит
Если один шлюз обслуживает несколько продуктов, журнал должен отвечать на несколько простых вопросов: кто отправил запрос, к какой модели, сколько это стоило, что решила политика доступа и чем все закончилось.
Для большинства случаев хватает набора полей tenant_id, product_id, environment, model, cost, status, request_id и времени запроса. Этого уже достаточно, чтобы разнести расходы по командам, заметить всплеск трафика и собрать отчет для финансов, безопасности и разработки.
Персональные данные лучше маскировать до записи в лог. Если пользователь вставил в промпт телефон, почту или номер договора, журнал не должен хранить это в исходном виде. Иначе лог сам становится источником утечки.
Доступ к журналам тоже нужно разделять. Разработчику полезны подробные записи для отладки конкретного запроса. Руководителю продукта чаще нужен другой вид: расходы, число вызовов, доля ошибок, средняя задержка. Один интерфейс и одна роль для этих задач только мешают.
Отдельно стоит хранить административный аудит. Выдача нового токена, изменение лимита, открытие доступа к модели и экспорт логов - это один класс событий. Пользовательские промпты и ответы модели - другой. Когда все лежит вперемешку, разбор инцидента идет заметно дольше.
Если у вас есть требования 152-ФЗ, проверьте не только основное хранилище, но и бэкапы, очереди, временные файлы и внешние системы мониторинга. У RU LLM логи и бэкапы хранятся на серверах в РФ, а маскирование PII, метки AI-Law и аудит-трейлы встроены в каждый запрос. Для команд с российским контуром это сокращает объем ручных проверок.
Как ограничить доступ к моделям
Одна и та же модель редко подходит всем сразу. Если открыть весь каталог всем продуктам, быстро появятся лишние траты, путаница в логах и ненужные риски.
Правила доступа к моделям лучше задавать не по принципу кому что понравилось, а по понятным рамкам для каждого продукта. Поддержке клиентов может хватить двух-трех моделей для чата. Внутреннему помощнику нужен длинный контекст. Пакетной обработке важнее стабильная цена и ночное окно запуска.
Обычно правила делят по четырем направлениям:
- какие модели продукт вообще видит;
- какие типы запросов ему разрешены: чат, embeddings, пакетные задачи;
- к каким провайдерам и регионам он может обращаться;
- какие дообученные модели доступны только своей команде.
Дообученные модели лучше считать внутренним активом команды, а не общим ресурсом. Если одна продуктовая группа дообучила модель под свой сценарий, соседние команды не должны видеть ее по умолчанию.
Отдельное правило нужно для провайдеров и регионов. Продукт с персональными данными может работать только через маршруты с хранением и обработкой внутри РФ, а R&D-песочница - через более широкий набор поставщиков. Это особенно полезно, когда один шлюз обслуживает и строгие контуры, и экспериментальные задачи.
Такие изменения не стоит вносить по устной договоренности. Любое изменение должно оставлять след: кто открыл доступ, когда именно и что поменялось. Иначе разбор причин инцидента сводится к догадкам.
Пример для трех продуктовых команд
Один мультиарендный шлюз особенно удобен там, где у компании несколько продуктов с разной ценой ошибки и разной нагрузкой. Инфраструктура одна, а правила разные.
Представим три команды.
Поддержка клиентов отвечает на частые вопросы, делает краткие выжимки диалогов и готовит шаблонные ответы. Ей подходят недорогие модели, жесткий дневной лимит и небольшой месячный бюджет.
Внутренний copilot помогает сотрудникам искать по базе знаний и писать черновики писем и документов. Ему нужен длинный контекст, более высокий лимит на один запрос и доступ только для внутренних пользователей.
Команда аналитики запускает пакетные задачи: классифицирует отзывы, извлекает поля из документов, размечает массивы текста. Для нее разумно выделить отдельное окно расходов и ночной маршрут, чтобы эти задания не мешали онлайн-нагрузке.
Во всех трех случаях токены не должны быть общими. Если поддержка и аналитика используют один и тот же ключ, ошибка в пакетной задаче быстро съест общий бюджет. Намного безопаснее выдать каждой команде свой токен и привязать его к product_id. Тогда шлюз считает расход отдельно, даже если все запросы идут в одну и ту же модель.
Логи тоже стоит делить по продуктам. В записи запроса обычно достаточно имени модели, числа токенов, стоимости, сервиса-инициатора и результата политики доступа. Финансы видят три независимых потока расходов, а не одну большую сумму за месяц.
На практике это сильно упрощает жизнь. Поддержка не платит за эксперименты аналитики, а copilot не теряет доступ к длинному контексту из-за чужих ограничений.
Ошибки, которые дорого обходятся
Самая частая ошибка - один сервисный аккаунт на всю компанию. Так проще стартовать, но потом любой сбой становится общим. Один продукт уходит в цикл ретраев, второй тестирует новую функцию, третий получает задержки и общий перерасход.
Вторая ошибка - общий бюджет без дневного порога. Месячный лимит почти бесполезен, если команда может сжечь его за ночь после релиза или массового eval-прогона.
Третья ошибка - логи без tenant_id и владельца. Пока все спокойно, это кажется мелочью. Но как только нужно понять, кто отправил дорогой запрос или где в промпт попали персональные данные, такой лог почти ничего не дает.
Четвертая ошибка - широкие админские права у разработчиков и подрядчиков. Временный доступ почти всегда живет дольше, чем планировали. Через пару недель уже трудно понять, кто может менять лимиты, маршруты и правила логирования.
Пятая ошибка - ручные исключения без срока пересмотра. Сначала кто-то временно отключает квоту, потом открывает все модели еще одной команде, а через месяц никто не помнит, зачем это сделали. У любого исключения должен быть владелец, причина и дата проверки.
Что проверить перед запуском
Перед боевым стартом полезно проверить не только маршрут до модели, но и сами границы между продуктами. Мультиарендный шлюз чаще ломается не в коде, а в разделении доступа.
Короткий список перед запуском:
- выпустить отдельный токен для каждого продукта и каждой среды;
- назначить владельца для каждого токена;
- включить дневные и месячные лимиты;
- добавить в логи
product_id,environment,model,request_idи стоимость; - проверить, что каждая команда видит только свои модели, токены и отчеты;
- заранее протестировать аварийное отключение токена или дорогой модели.
Полезный тест очень простой. Отправьте несколько запросов от каждого продукта, упритесь в лимит на тестовом tenant, найдите один запрос по логам и отключите доступ для одной команды так, чтобы остальные продолжили работать. Если этот сценарий проходит без ручной магии, схема собрана нормально.
Что делать после пилота
Не пытайтесь сразу развести весь каталог продуктов, ролей и моделей. Лучше начать с двух продуктов с разной нагрузкой и одной понятной схемой именования. Так быстрее видно, где права слишком широкие, где лимиты не срабатывают и какие поля в логах никто не заполняет.
Хорошая схема имен обычно простая: product.environment.role. Токен вида billing.prod.backend читается без отдельного документа и помогает быстрее находить источник расходов или спорный запрос.
До пилота полезно собрать короткую таблицу и держать ее в актуальном состоянии. Обычно хватает четырех колонок: токен, владелец, лимит и набор моделей. Если таблица уже не помещается на один экран, система, скорее всего, стала сложнее, чем нужно.
Потом дайте схеме прожить хотя бы месяц. Раз в неделю сверяйте логи запросов с расходами по каждому продукту. Смотрите не только на итоговую сумму, но и на детали: ночные всплески, вызовы не тех моделей, рост ретраев, пустые теги, неожиданные скачки стоимости одного и того же сценария.
Если нужен OpenAI-совместимый шлюз внутри РФ, RU LLM позволяет быстро проверить такую схему без переписывания SDK, кода и промптов: достаточно сменить base_url. Для команд, которым важны data residency, биллинг и поддержка внутри России, это упрощает пилот.
Хороший результат здесь довольно приземленный. У каждого токена есть владелец, у каждого продукта свой лимит, а любой спор по расходам решается по логам за несколько минут.
Часто задаваемые вопросы
Зачем вообще делить доступ по продуктам, если endpoint один?
Потому что общий endpoint сам по себе не дает порядок. Если все продукты ходят под одним токеном, вы теряете связь между запросом, расходом и владельцем. Один вход работает нормально только тогда, когда шлюз жестко разделяет tenant, токены, лимиты и логи.
С чего начать настройку мультиарендного шлюза?
Начните с самого простого: создайте отдельный tenant на каждый продукт и выпустите отдельные токены для prod, stage и dev. Сразу привяжите каждый токен к владельцу и задайте список разрешенных моделей. Этого уже хватает, чтобы расходы и инциденты не смешивались.
Нужен ли отдельный токен для dev, stage и prod?
Да, иначе тестовый трафик быстро смешается с боевым. Разработчики часто гоняют один сценарий много раз, и без отдельного токена вы не поймете, кто съел лимит. Разделение по средам еще и упрощает быстрое отключение одной среды без вреда для остальных.
Какие лимиты лучше включить в первую очередь?
Ставьте месячный бюджет и дневной лимит одновременно. Месячный потолок держит общий расход под контролем, а дневной ловит ночные всплески, ретраи и неудачные релизы. Предупреждение на 70–80% лимита тоже полезно: команда успеет убрать лишние вызовы до блокировки.
Что обязательно писать в логи, чтобы потом не разбирать все вручную?
Обычно хватает полей tenant_id, product_id, environment, model, cost, status, request_id и времени запроса. Этот набор помогает быстро найти дорогой вызов, увидеть всплеск трафика и собрать отчет по продукту. Если работаете с персональными данными, маскируйте PII до записи в лог.
Как ограничить доступ к моделям для разных команд?
Не открывайте весь каталог всем подряд. Для каждого продукта заранее задайте свой список моделей, типы запросов и допустимые маршруты по провайдерам и регионам. Поддержке обычно хватает недорогих моделей, а внутреннему помощнику можно дать длинный контекст и закрытый доступ для сотрудников.
Как понять, что бюджеты и квоты настроены плохо?
Плохая настройка быстро видна по симптомам: один продукт внезапно платит за чужие эксперименты, dev ходит в дорогие модели, а команда узнает о блокировке уже после жалоб пользователей. Если вы не можете за пару минут ответить, кто потратил деньги и на какой сценарий, схема учета уже дала сбой.
Что делать с подрядчиками и временным доступом?
Подрядчику давайте отдельный токен и только те права, которые нужны на задачу. Не давайте ему доступ к чужим логам, бюджетам и смене лимитов, если он только тестирует интеграцию. Сразу ставьте срок действия и сохраняйте, кто выдал доступ и зачем.
Как проверить схему перед запуском?
Прогоните простой сценарий руками. Отправьте запросы от нескольких продуктов, упритесь в лимит на тестовом tenant, найдите запрос по request_id и отключите один токен так, чтобы остальные сервисы продолжили работу. Если на этом этапе начинается ручная магия, в прод лучше не идти.
Когда имеет смысл использовать шлюз внутри РФ, например RU LLM?
Такой вариант имеет смысл, когда вам нужны хранение логов и бэкапов в РФ, внятный аудит и обычная интеграция без переписывания SDK. В RU LLM можно просто сменить base_url, сохранить текущий код и вынести лимиты, маскирование PII и учет по продуктам в сам шлюз. Это удобно для команд, которым нужен российский контур и раздельный биллинг.