Нормализация русских имён, дат и адресов после LLM
Нормализация русских имён, дат и адресов после LLM: где хватит ответа модели, а где нужны правила, словари и строгая проверка формата.
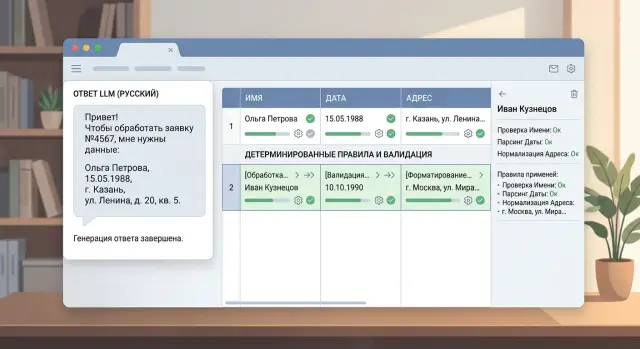
Где проблема начинается после ответа модели
Проблема редко выглядит как явная ошибка. Чаще модель отвечает "почти правильно": фамилия записана без "ё", дата приходит как "03.04.24" вместо "2024-04-03", а адрес склеен в одну строку без корпуса и строения. Человек это поймет. База данных - не всегда.
Именно такие мелочи ломают поиск, дедупликацию и отчеты. "Алексей Семёнов" и "Алексей Семенов" легко расходятся по разным карточкам. "1 апреля 2024" и "01.04.2024" попадают в разные форматы. Адреса вроде "Москва, Ленина 7" и "г. Москва, ул. Ленина, д. 7" кажутся одинаковыми только на глаз.
В ФИО сбои обычно повторяются. Модель путает порядок полей, оставляет лишние пробелы, то сокращает отчество до инициалов, то раскрывает его полностью. Иногда она нормализует слишком смело: превращает "Наталию" в "Наталью", хотя это уже другой вариант имени, а не исправление опечатки.
С датами картина та же. Один и тот же промпт может вернуть:
- "07.09.1988"
- "7 сентября 1988"
- "1988-09-07"
- "07/09/88"
По смыслу это одно и то же. Для фильтров, сортировки и сверки - четыре разных значения. Если в потоке смешаны даты рождения, даты договоров и сроки доставки, ошибка быстро уходит дальше по цепочке.
С адресами сложнее всего. Модель часто делает ответ читаемым, а не пригодным для системы. Она убирает индекс, меняет части местами, пишет "Санкт-Петербург" как "СПб", а "проспект" сокращает до "пр-т". Для человека это мелочь. Для валидации адресов, геокодинга и дедупликации - уже разные записи.
Даже при одном промпте форма ответа плавает. Одна модель любит сокращения, другая пишет все полностью. Если команда меняет модели под цену, скорость или тип задачи, разброс форматов становится заметнее. Смысл ответа может оставаться верным, а структура полей уже нет.
Сначала такие случаи правят вручную. Это терпимо, пока у вас 50 записей в день. Когда их 5 тысяч, ручная правка съедает часы, добавляет новые ошибки и делает результат непредсказуемым. Поэтому "почти правильно" после LLM - не косметическая мелочь, а обычная причина дублей в CRM, сломанных отчетов и лишней работы в бэк-офисе.
Где модель уже дает чистый результат
Модель часто справляется сама, если исходный текст уже почти нормальный. Когда задача сводится к тому, чтобы убрать мусор, выровнять регистр и привести запись к аккуратному виду, результат нередко можно брать почти без правок.
Так бывает с ФИО из анкет, писем и заявок, где человек ввел данные в свободной форме, но без сильных ошибок. Из строки вроде " иВАНОВ иВАН иВАНОВИЧ " модель обычно делает "Иванов Иван Иванович". Для интерфейса, отчета или ручной проверки этого уже достаточно.
То же самое работает там, где не нужно ничего угадывать. Если в имени есть все части, порядок понятен, нет инициалов и редких сокращений, жесткие правила можно не включать сразу. С датами еще проще. Если дата указана явно, модель редко портит ее при нормальном промпте. Записи вроде "12.03.2024", "2024-03-12" или "12 марта 2024" она обычно приводит к одному виду без сюрпризов.
С адресами ситуация обманчивее. Модель умеет убрать лишние пробелы и сделать строку понятной человеку: "г москва ул тверская д 7" превращается в "г. Москва, ул. Тверская, д. 7". Для карточки клиента или оператора этого нередко хватает.
Но именно адреса чаще всего создают ложное чувство порядка. Строка может выглядеть аккуратно, хотя для базы она все еще опасна. "Москва, Ленина, 10" читается нормально, но в городе может быть несколько таких объектов. Могут отсутствовать тип улицы, корпус, строение или индекс. "Санкт-Петербург, Невский, 15" тоже легко читать, но это не значит, что запись можно однозначно сопоставить со справочником.
Простое правило такое: чем меньше в задаче скрытых допущений, тем чаще ответ модели можно принять как есть. Если модель не восстанавливает пропущенные части и не выбирает между несколькими вариантами, результат обычно чистый. Для ФИО и простых дат этого часто хватает. Для адресов красивый внешний вид почти ничего не гарантирует.
Где без детерминированных правил не обойтись
Даже сильная модель не держит формат так строго, как этого ждет база, CRM или обмен с внешней системой. Она понимает смысл записи, но не обязана каждый раз оформлять поле одинаково. Поэтому после LLM почти всегда нужен слой правил.
Самый частый пример - буква "Ё". Для человека "Елена" и "Ёлкина" читаются без труда, а для поиска и сверки это разные строки. Модель может вернуть "Фёдор" в одном ответе и "Федор" в другом, хотя источник один и тот же. Тут нужен явный выбор: либо вы храните каноническую форму с "Ё", либо везде приводите к "Е". Иначе одинаковые люди начнут расходиться по записям.
С датами проблем не меньше. Модель понимает, что "03.04.24" - это дата, но ей неоткуда знать, какой век имел в виду источник, если правило не задано заранее. То же самое с фразами вроде "в прошлый вторник", "5 мая вечером" или "до конца квартала". Для заметки это нормально. Для системы, где нужен ISO-формат, придется жестко решать, что считать допустимой датой, как достраивать год и что делать с часовым поясом.
Адреса почти всегда ломаются на сокращениях и деталях. Один ответ даст "ул. Тверская, д. 7, корп. 2", другой напишет "Тверская улица, дом 7 корпус 2", третий добавит "стр. 1" или "лит. А". Все варианты понятны человеку, но для индексации и сверки нужен один шаблон.
Обычно правила нужны как минимум для четырех вещей:
- приводить сокращения к одному виду
- разбирать корпус, строение и литеру по отдельным полям
- проверять, что дата попадает в допустимый формат
- фиксировать единую запись ФИО для всех документов
Если вы пропускаете извлечение через единый LLM API, это не отменяет постобработку. Модель может аккуратно достать адрес из письма банка или анкеты, но только детерминированный слой решит, что попадет в address_line, что уйдет в building_block, а что надо отправить на ручную проверку. В продакшене это обычная санитария данных.
Почему извлечение и нормализацию лучше разделять
Если смешать обе задачи в одном промпте, модель часто начинает не извлекать, а редактировать. Она видит "иванова м.с., 3 фев 91, ленинский пр-т" и сразу делает красивый ответ. После этого уже трудно понять, что было в исходнике, а что модель дорисовала сама.
Надежнее разделить конвейер на два шага. Сначала модель достает сущности из текста. Потом код приводит каждое поле к одному формату и проверяет его по правилам.
На шаге извлечения лучше просить у модели только факты из документа: ФИО, дату, индекс, город, улицу, дом, квартиру. Не просите ее угадывать канонический вид записи и не смешивайте это с бизнес-валидацией. Если команда работает через RU LLM, удобно требовать структурированный JSON через единый OpenAI-совместимый эндпоинт, а логику нормализации держать отдельно в приложении. Тогда смена модели не ломает весь пайплайн.
После извлечения каждое поле обрабатывают своим правилом. Имена приводят к нужному регистру, убирают двойные пробелы, решают, как работать с "е" и "ё". Даты переводят в один внутренний формат, например YYYY-MM-DD, и сразу проверяют календарные ошибки. Адреса разбирают на части и отправляют на валидацию по справочнику или по вашему набору допустимых значений.
Полезно хранить сразу несколько версий значения:
- сырое значение из текста
- значение из ответа модели
- нормализованное значение
- статус проверки и причину ошибки
Такой разрез быстро показывает, где именно сломались данные. Модель неверно прочитала поле, нормализатор слишком агрессивно исправил запись или справочник не нашел адрес.
Как это выглядит на одной записи
В тексте есть строка: "Петрова Анна, 07/08/24, СПб, Большой пр. П.С., д. 14". Модель должна вернуть части записи как они есть, без догадок про полный адрес. Дальше код решает, что "СПб" нужно привести к принятому виду, дату интерпретировать по правилу вашего процесса, а адрес проверить по справочнику.
И еще один принцип, который сильно экономит время: не затирайте исходник. Храните рядом raw и normalized. Когда оператор или разработчик разбирает спорный случай, он видит не только итог, но и путь, которым система к нему пришла.
Рабочая схема постобработки
Проблема обычно не в том, что модель не поняла запись. Она часто верно вытаскивает смысл, но оставляет мелкий хаос: двойные пробелы, разные форматы дат, "ул" без точки, ФИО в случайном регистре. Для потока данных этого уже достаточно, чтобы поиск и сверка начали ошибаться.
Рабочая схема держит модель и правила на разных ролях. Модель извлекает поля. Код приводит их к одному виду и решает, можно ли доверять результату.
- Сначала просите у модели только структуру. Пусть она возвращает отдельные поля, а не свободный абзац.
- Затем делайте механическую очистку: убирайте лишние пробелы, финальные запятые и точки, приводите разделители к одному виду.
- После этого включайте правила по типу поля. Дату переводите в один формат. В ФИО приводите части к обычному написанию, но не додумывайте пропущенное отчество. В адресе сводите "ул.", "улица" и "ул" к одному варианту, так же с "д.", "корп.", "кв.".
- Дальше идет проверка. Дата должна существовать в календаре. В имени не должно быть цифр и случайных символов. Адрес стоит сверять по маскам, словарям сокращений и разумной длине поля.
- Все сомнительные случаи отправляйте в отдельную очередь. "01.02.03" без контекста, "Саша" вместо полного имени, "Ленина, 10" без города - плохой материал для автонормализации.
Короткий пример: модель вернула " ПЕТРОВ ПЕТР ", "1/2/24" и "г Москва, ленинский проспект д 5 ". После постобработки вы получите "Петров Петр", дату в одном выбранном формате и адрес с едиными сокращениями. Если дата двусмысленна, запись не надо чинить догадкой. Ее лучше пометить и отдать на разбор.
Для команд, которые меняют модели через единый API-шлюз, такой порядок особенно удобен. Модель можно заменить, а слой нормализации и проверки продолжит работать одинаково.
Пример на одной записи
Запись из формы часто приходит одной строкой: "иванов и.и., 3 мая 24 г., москва, ленинский 10к2". Для человека тут все понятно. Для системы это уже смесь трех сущностей: ФИО, дата и адрес.
LLM обычно хорошо справляется с первым шагом. Она поднимает регистр, видит границы полей и раскладывает строку по частям: "Иванов И.И.", "3 мая 24 г.", "Москва, Ленинский 10к2". Этого достаточно, чтобы не писать хрупкие регулярные выражения под каждый вариант ввода.
Но дальше должны включаться правила. Если в источнике есть только "И.И.", нельзя без проверки превращать инициалы в "Иван Иванович". Такое раскрытие допустимо только тогда, когда детерминированное правило находит совпадение в доверенном справочнике или в уже подтвержденной карточке.
С датой правила нужны почти всегда. Строка "3 мая 24 г." выглядит простой, но системе нужен один формат хранения. Парсер переводит ее в "2024-05-03", проверяет допустимый диапазон и отдельно помечает короткий год, если в ваших данных есть риск спутать 1924 и 2024.
С адресом логика та же. Модель может понять, что "10к2" означает дом 10, корпус 2, но тип улицы она не должна придумывать. Поэтому нормализация идет по шагам: привести регистр к обычному виду, отделить дом и корпус, найти совпадение в адресном справочнике, записать адрес в принятом формате и поставить флаг проверки, если не хватает типа улицы или найдено несколько совпадений.
Если справочник подтверждает запись, адрес можно сохранить как "г. Москва, Ленинский пр-т, д. 10, к. 2". Если подтверждения нет, лучше оставить "Ленинский" как есть и отметить поле как сомнительное.
В итоге чистая запись выглядит примерно так: фамилия "Иванов", инициалы "И.И.", дата "2024-05-03", адрес в нормализованном виде и флаги вроде initials_not_expanded и address_needs_review, если они нужны. Модель делает грязную работу по разбору текста, а правила не дают ей гадать там, где цена ошибки выше пары лишних секунд на ревью.
Ошибки, которые чаще всего ломают данные
Больше всего проблем дают не грубые сбои, а аккуратные ответы, которые выглядят правдоподобно. Модель пишет имя без лишних пробелов, дату в одном стиле, адрес в красивой строке, и кажется, что поле уже можно класть в базу. Обычно именно в этот момент данные и начинают портиться.
Первая частая ошибка - пытаться чинить все одним промптом. Для косметики это работает: убрать мусор, поправить регистр, разнести строку по полям. Но промпт плохо держит жесткие правила. Сегодня модель сохранит "ул. Ленина, д. 5", завтра превратит это в "улица Ленина 5", а послезавтра решит, что "корп. 2" можно опустить как несущественную деталь. Для адреса это уже другая запись.
Вторая ошибка - смешивать нормализацию и бизнес-логику в одном шаге. Нормализация отвечает на вопрос "что написано в данных". Бизнес-логика отвечает на вопрос "что мы с этим делаем". Если модель сразу решает, можно ли принимать клиента, совпадает ли адрес с форматом анкеты или проходит ли дата под правила договора, вы теряете контроль над системой.
Третья ошибка встречается почти в каждой первой интеграции: исходное значение затирают. Было "Сергеев-Ценский", стало "Сергеев Ценский". Было "08.04.25", стало "2025-04-08". Потом всплывает спорный случай, а проверять уже нечего. Храните рядом хотя бы три версии: сырой ввод, ответ модели и результат правил.
Особенно часто ломаются такие случаи:
- редкие и двойные фамилии
- буквы "Е" и "Ё" в именах
- адреса с "стр.", "к.", "лит.", "вл."
- даты вроде "01.02.03", где формат неочевиден
- локальные сокращения, понятные человеку, но не правилу
Еще одна частая ошибка - считать красивый текст валидными данными. "Москва, ул. Тверская, 7" выглядит хорошо, но без проверки вы не знаете, существует ли такой дом в нужном контексте, не потерялся ли корпус и не склеились ли два поля в одно. С именами ровно та же история: "Наталья" может быть написано чисто, но это не значит, что падеж, отчество и пол определены верно.
Если поток идет через единый LLM-шлюз, соблазн сделать все на стороне модели еще выше: один вызов, один ответ, одна схема. На практике дешевле и надежнее разделить роли. Модель извлекает и чистит текст там, где хватает вероятностного ответа. Правила проверяют формат, справочники и спорные случаи. Иначе тихие ошибки накопятся быстрее, чем это заметит команда.
Короткий чек-лист перед запуском
Перед запуском полезно проверять не качество модели вообще, а судьбу каждого поля после ответа. Ошибки тут обычно простые: дата хранится в трех форматах, адреса "ул. Ленина, 7" и "улица Ленина, дом 7" считаются разными, а "Наталья" и "Наталия" кто-то случайно склеивает в одно значение.
Если нормализация таких полей входит в продовый поток, этот список лучше пройти до первой интеграции:
- для каждого поля должен быть один формат хранения
- нужно сохранять и исходное значение, и нормализованное
- подозрительные записи надо помечать, а не молча принимать
- тесты должны включать редкие, но реальные случаи
- команда должна одинаково понимать границу между ответом модели и правилом
Один практический признак здоровой схемы такой: вы можете показать любую запись и ответить на два вопроса без ручных раскопок. Что пришло от модели? Что изменили правила после нее? Если на это нельзя ответить за минуту, пайплайн еще сырой.
Для команд, которые гонят такие поля через единый LLM API, это особенно важно. Смена модели не должна менять формат хранения. В этом смысле подход RU LLM удобен для экспериментов: можно переключать модели через тот же OpenAI-совместимый эндпоинт и смотреть, что меняется именно в извлечении, не трогая слой нормализации и проверки.
Что делать дальше
Начните не с новых промптов, а с набора живых данных. Возьмите 100-200 реальных записей из того потока, где ответ модели уже влияет на CRM, анкету, договор или доставку. На таком объеме быстро видно, где LLM ошибается редко, а где формат поля ломается каждый день.
Дальше разберите ошибки по типам. Обычно их немного: ФИО в разных падежах, дата в свободной форме, адрес с сокращениями, лишние пробелы, переносы строк, смешение "д. 5" и "дом 5", пропуск корпуса или квартиры. Если свалить все в одну корзину "модель иногда путается", вы ничего не почините.
Модели оставьте то, что она делает хорошо: извлечение из грязного текста и мягкую очистку. Она может убрать шум, собрать имя из нескольких фрагментов, отделить дату от комментария, вернуть адрес одной строкой без явного мусора. Это нормальная роль для постобработки LLM в проде: сначала вытащить смысл, потом передать строгий формат правилам.
Строгую нормализацию дат и адресов лучше держать вне модели. Дата должна попадать в один формат, а не в "как получилось". Адрес стоит прогонять через словари сокращений, правила по корпусам и строениям, проверки индекса, региона и города. Имена обычно живут посередине: модель извлекает, а правила приводят "Екатерина Сергеевна" к нужному виду поля.
Рабочая схема простая:
- Храните исходный фрагмент отдельно от нормализованного значения.
- Для каждого поля заведите свои правила и причины отказа.
- Все неоднозначное отправляйте в ручную проверку, а не додумывайте автоматически.
- Считайте качество по типам ошибок, а не по одной средней цифре.
Когда этот слой уже собран, спорить о "нужна ли еще одна модель" становится проще. Ответ виден не по общему впечатлению, а по конкретным полям и конкретным ошибкам. И это куда полезнее, чем еще один красивый ответ, который почти правильный.
Часто задаваемые вопросы
Что лучше просить у модели на шаге извлечения?
Просите у модели только структуру и факты из исходного текста. Пусть она вернет отдельные поля вроде ФИО, даты, города, улицы, дома и квартиры, а канонический вид, проверки и бизнес-решения оставьте коду.
Когда ответ модели можно брать почти без правок?
Обычно да, если исходник уже почти чистый и модели не нужно ничего угадывать. Для простых ФИО и явно записанных дат она часто дает аккуратный результат, но адреса даже в красивом виде все равно стоит проверять отдельно.
Почему лучше разделять извлечение и нормализацию?
Если смешать это в одном промпте, модель начнет не только читать текст, но и дорисовывать недостающее. Когда вы делите конвейер на два шага, проще понять, что пришло из документа, а что изменили ваши правила.
Как правильно работать с Е и Ё в именах?
С буквой Е и Ё нужно принять одно правило на весь поток и держаться его везде. Либо вы храните каноническую форму с Ё, либо всегда приводите к Е, иначе поиск и дедупликация быстро начнут расходиться.
Какой формат даты лучше хранить в базе?
Храните одну внутреннюю форму, обычно YYYY-MM-DD. Такой формат проще сортировать, фильтровать и сравнивать между системами, а человекочитаемый вид можно строить уже в интерфейсе.
Что делать с датами вроде 01.02.03?
Не исправляйте такую дату догадкой. Пометьте запись как неоднозначную и отправьте в ручную проверку или разберите ее по жесткому правилу процесса, если контекст всегда один и тот же.
Можно ли доверить нормализацию адресов только LLM?
Полностью полагаться на модель не стоит. Она может сделать адрес понятным человеку, но для базы часто теряет тип улицы, корпус, строение или пишет сокращения в разном виде, поэтому адрес лучше разбирать и сверять правилами и справочником.
Что нужно сохранять кроме нормализованного значения?
Сохраняйте хотя бы три версии: сырой фрагмент, ответ модели и нормализованное значение. Рядом держите статус проверки и причину ошибки, чтобы быстро разбирать спорные случаи.
Какие записи лучше сразу отправлять на ручную проверку?
Отправляйте туда все, что можно понять двояко или нельзя подтвердить. Инициалы без расшифровки, короткие годы, адрес без города, редкие сокращения и строки с пропущенными частями лучше не чинить автоматически.
Что проверить перед запуском такой схемы в прод?
Проверьте, что у каждого поля есть один формат хранения, что вы не затираете исходник и что тесты покрывают редкие реальные случаи. Если вы меняете модели через единый API, например через OpenAI-совместимый шлюз, формат данных после нормализации не должен меняться.