Трассировка LLM-запроса через шлюз, очередь и инструменты
Трассировка LLM-запроса помогает связать шлюз, очередь, вызовы инструментов и ответ модели, чтобы быстрее находить сбои и чинить прод.
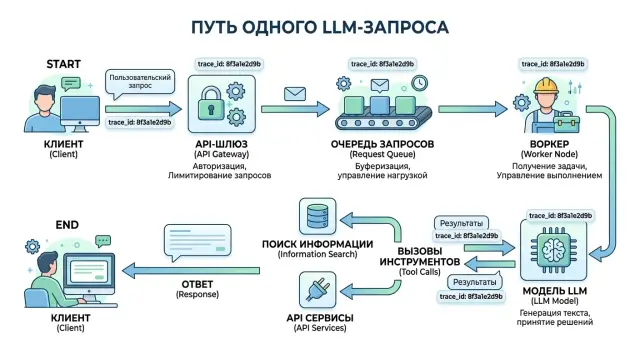
Почему без общего trace id все расползается
Проблема кажется скучной ровно до первого сбоя. Один запрос проходит через API-шлюз, попадает в очередь, вызывает инструмент, возвращается в модель и уходит клиенту. А в логах у каждого узла свой id. В итоге один и тот же запрос распадается на несколько отдельных историй.
Тогда инженер почти всегда начинает с плохого сценария: ищет по времени. Он открывает логи шлюза, потом очередь, потом сервис инструмента и вручную сверяет секунды, payload и user id. На один инцидент легко уходит 30-40 минут, хотя сама ошибка длилась две секунды.
Сильнее всего это бьет по ретраям. Первый вызов инструмента мог упасть по таймауту, второй сработал, а клиент увидел только длинный ответ. Без общего trace id исходная ошибка живет в одном месте, повторная попытка в другом, а очередь добавляет свой job id. Цепочка рвется ровно там, где нужен ясный ответ: что сломалось первым.
Даже один медленный шаг легко прячется. Шлюз может показать нормальное время ответа модели, но не показать, что tool call ждал в очереди 18 секунд. Лог инструмента при этом покажет только 300 мс работы функции. Формально все сервисы работают нормально. По факту запрос завис где-то между ними.
Где trace id теряется по пути
Обычно проблема начинается не в модели, а раньше. Один пользовательский запрос проходит через пять разных узлов, и каждый живет по своим правилам логирования. В шлюзе есть один идентификатор, в очереди уже другой, у воркера третий, а в логах инструмента может не быть ни одного.
На входе в шлюз все обычно выглядит аккуратно. HTTP-запрос получает trace id, и первые записи легко найти. Но дальше многие команды сохраняют только внутренний request id шлюза и не передают исходный trace id в очередь, метаданные задачи или заголовки внутренних вызовов.
Очередь почти всегда добавляет свой id, и это нормально. Проблема начинается, когда команда ищет запрос уже по id очереди, а связь с исходным trace id никто не записал. Через час разбора видно, что задача обработалась, но непонятно, к какому клиентскому запросу она относилась.
Дальше контекст часто теряет воркер. Он берет job из очереди, пишет "start processing", вызывает модель и логирует только локальный job id. Если вызов ушел к внешнему провайдеру или на внутреннюю модель, запись о запросе к модели уже не связана с исходным trace id. На этом месте трассировка LLM-запроса рвется чаще всего.
С инструментами еще сложнее. Поиск, RAG-слой, проверка прав доступа, SQL-запрос или CRM нередко пишут свои логи отдельно. Они знают user id, имя метода и время ответа, но не знают trace id. Потом видно, что инструмент тормозил 18 секунд, а привязать это к конкретному ответу модели трудно.
Добивает картину стриминг. Начало запроса логируется в access log шлюза, а чанки ответа, отмена стрима и финальный статус живут в другом процессе или формате событий. Если клиент закрыл соединение на 73-м токене, это событие уже не связано с началом запроса.
Чаще всего trace id пропадает в пяти местах:
- при переходе из HTTP-запроса в сообщение очереди
- при создании нового job id без ссылки на исходный id
- в воркере перед вызовом модели или ретраем
- в логах инструментов и внешних зависимостей
- в событиях стриминга, отмены и завершения ответа
После этого один инцидент распадается на набор несвязанных кусков. Логи есть, а единого пути запроса уже нет.
Какой id за что отвечает
Если у всей цепочки есть один общий идентификатор, разбор сбоя идет заметно быстрее. Один пользовательский запрос получает один trace id, и этот id проходит через шлюз, очередь, модель и вызовы инструментов до самого ответа.
trace_id нужен для всей истории запроса. Он не меняется, даже если система делает retry, ставит задачу в очередь или вызывает несколько инструментов подряд. Когда команда ищет проблемный ответ, она ищет именно по этому полю.
span_id решает другую задачу. Он описывает отдельный шаг внутри общей цепочки: прием на шлюзе, запись в очередь, работу воркера, запрос к модели, каждый tool call. Так видно не только общее время, но и место, где система потеряла 8 из 10 секунд.
request_id лучше оставить как локальный id сервиса. Шлюз может выдать свой request_id, воркер свой, адаптер модели свой. Это нормально. Проблемы начинаются, когда request_id пытаются использовать как единый идентификатор всей цепочки. На стыке сервисов он часто меняется или пропадает.
tenant_id, session_id и user_id не стоит прятать внутри trace_id. Держите их в отдельных полях. Тогда поиск проще, фильтры не ломаются, а аудит остается читаемым. Для систем с требованиями по 152-ФЗ это особенно удобно: можно отдельно искать запросы клиента, сессии или пользователя и не смешивать это с технической трассировкой.
Практичный минимум выглядит так:
trace_id- один на весь пользовательский запросspan_id- один на каждый шаг обработкиparent_span_id- связь между шагамиrequest_id- локальный id конкретного сервисаtenant_id,session_id,user_id- бизнес-контекст в отдельных полях
Персональные данные не кодируйте в самих id. Не вставляйте email, телефон, логин или имя клиента в trace_id и request_id. Идентификатор должен быть случайным или сгенерированным по понятному правилу, а чувствительные данные нужно хранить отдельно и маскировать.
Как пронести trace id через весь путь
Создавайте trace_id в самой первой точке входа. Это может быть API-шлюз, edge-функция или backend, который принимает запрос от клиента. Не ждите очереди, воркера или SDK провайдера. Если id появился слишком поздно, часть пути уже потеряна.
Для LLM-потока это особенно заметно: один запрос проходит через шлюз, маршрутизацию к модели, очередь задач, вызов инструмента и callback с результатом. Если на каждом шаге рождается новый id, разбор инцидента снова превращается в ручной поиск по логам.
Рабочее правило простое. trace_id создают один раз на входе, а дальше только передают.
- На входе создайте один
trace_idи сразу положите его в контекст запроса. Если клиент прислал свой id, сохраните его отдельно какclient_request_id. - При любом внутреннем переходе передавайте
trace_idдвумя путями: в header и в теле сообщения. Header удобен для HTTP и gRPC, поле в payload помогает при очередях, ретраях и dead letter queue. - В воркере копируйте
trace_idв локальный контекст до первого сетевого вызова. Тогда все логи, метрики и ошибки воркера будут привязаны к одному запросу. - В каждый вызов инструмента передавайте тот же
trace_idбез изменений. Если инструмент создает свойrequest_id, просто логируйте оба значения рядом. - Возвращайте
trace_idклиенту и в обычном ответе, и в streaming-событиях, и в ошибке. Тогда саппорт, разработчик и пользователь говорят об одном запросе, а не пересказывают текст промпта.
Если команда работает через RU LLM, начальную точку удобно фиксировать прямо на едином OpenAI-совместимом endpoint, а затем тянуть тот же trace_id через очередь и инструменты. Это особенно полезно там, где важны аудит-трейлы и хранение данных внутри РФ.
Что писать в лог на каждом узле
Наличие trace_id само по себе не спасает, если в логах не хватает контекста. Разбор работает быстро только тогда, когда по одной записи можно понять, чей это запрос, на каком шаге он находится и что произошло до сбоя.
На каждом узле полезно писать один и тот же набор полей. Не сокращайте лог в "простых" местах вроде очереди или worker-пула. Именно там связность теряется чаще всего.
Минимальный набор полей такой:
trace_id,span_id,parent_span_idtenant_id,request_id,user_idили его безопасный суррогатmodel,provider,routequeue_message_id,job_idstatus,error_code,duration_ms
Для очереди этого уже недостаточно, если вы хотите быстро видеть задержки. Логируйте не только факт постановки, но и время ожидания до старта, время выполнения job и, если возможно, длину очереди в момент записи. Эти цифры быстро показывают, где копится задержка: в перегруженном воркере, в медленном провайдере или в слишком длинной очереди.
Отдельно отмечайте события, которые ломают обычный поток: retry, timeout, cancel, ручной stop. Не прячьте их в общий status. Лучше явно писать причину и номер попытки, например retry_count=2. Тогда при разборе сразу видно, система один раз попробовала заново или гоняла запрос по кругу.
Если запрос уходит во внешние инструменты, сохраняйте id вызова инструмента, имя инструмента и связь с текущим span_id. Иначе потом трудно понять, какой именно tool call дал ошибку, вернул пустой ответ или затянул весь пайплайн на 40 секунд.
Еще одна частая ошибка - писать в лог сырые промпты, email, телефон или номер договора. Даже во внутренних системах так делать не стоит. Маскируйте PII до записи в лог, а для поиска оставляйте безопасные маркеры, хеши или короткие признаки. В этом месте требования 152-ФЗ совпадают с обычной инженерной гигиеной.
Как собрать один таймлайн запроса
Один LLM-запрос редко живет в одном месте. Он входит в шлюз, ждет воркер в очереди, уходит в модель, вызывает инструмент и потом еще несколько секунд стримится клиенту. Если каждый узел пишет лог сам по себе, команда видит набор разрозненных записей и тратит лишние 20-30 минут на один разбор.
Практичнее собирать не "логи по сервисам", а одну цепочку событий под одним trace_id. Создайте id на входе в шлюз и передавайте его дальше без изменений: в сообщение очереди, в контекст воркера, в вызовы инструментов и в события стрима. Если у вас OpenAI-совместимый шлюз, trace_id лучше ставить еще до маршрутизации, чтобы он пережил смену провайдера или модели.
Минимум событий для одного таймлайна обычно такой:
- запрос принят шлюзом
- задача поставлена в очередь и взята в работу
- модель начала генерацию и отдала первый токен
- инструмент стартовал, ответил или упал
- стрим завершился или оборвался с причиной
Этого хватает, чтобы разделить задержку по слоям. Вы сразу видите, где ушло время: 1800 мс в очереди, 400 мс до первого токена, 2200 мс на вызов CRM, 900 мс на сам стрим. Без такой разбивки люди часто винят модель, хотя проблема сидит в очереди или во внешнем инструменте.
Ошибки и таймауты тоже пишите в тот же таймлайн, а не в отдельную таблицу. У каждого сбоя должен быть тип и короткая причина: tool_timeout, provider_5xx, client_cancelled, stream_broken, max_tokens_reached. Полезно хранить и место обрыва: до первого токена, после 63 токенов, во время второго вызова инструмента.
Финального duration_ms в конце запроса мало. Он говорит, что было медленно, но не объясняет почему. Один полный таймлайн по trace_id сразу показывает, где запрос ждал, где работал, где сломался и кто именно оборвал ответ.
Пример инцидента на одном запросе
Один и тот же trace_id часто снимает спор между тремя командами за пять минут. Без него каждый смотрит в свои логи и почти всегда первым делом винит модель, хотя задержка сидит совсем в другом месте.
Представьте запрос пользователя: "Покажи 10 клиентов с самой большой просрочкой за последние 30 дней". Ответ из памяти модели тут не подойдет. Нужен вызов SQL tool, значит запрос пройдет через шлюз, очередь, воркер, модель и потом базу.
Таймлайн может выглядеть так:
- 10:14:03 - шлюз принимает запрос, присваивает
trace_id=trc_7f3a, ставит общий таймаут 25 секунд и кладет задачу в очередь - 10:14:15 - воркер забирает задачу, значит в очереди она ждала 12 секунд
- 10:14:17 - модель отвечает за 1.8 секунды и просит вызвать
sql_tool - 10:14:17 - сервис инструмента получает тот же
trace_idи отправляет SQL в базу - 10:14:28 - база все еще не вернула результат, и общий таймаут запроса срабатывает раньше ответа инструмента
Если trace_id прошел через весь путь, картина собирается сразу. На стороне шлюза видно, что запрос пришел вовремя и не упал на маршрутизации. В очереди видно 12 секунд ожидания. На стороне модели видна нормальная задержка. В сервисе инструмента видно, что вызов стартовал, но завис на SQL. В базе или логах query service видно, какой именно запрос тормозил.
Самое полезное здесь не сам факт таймаута, а расклад по времени. Из 25 секунд почти половина ушла на очередь, около 2 секунд на модель, и остаток съела медленная база. После такого разбора уже трудно говорить, что проблема в LLM. Модель отработала нормально. Инцидент сидит в двух местах: перегруженный воркер и долгий SQL.
Если у вас единый шлюз вроде RU LLM, полезно донести один и тот же trace_id не только до вызова модели, но и в очередь, инструмент и, по возможности, в комментарий к SQL. Тогда разбор идет по одному номеру, а не по догадкам.
Частые ошибки
Самая частая поломка выглядит скучно: команда меняет trace_id там, где не надо. После ретрая сервис создает новый id, очередь добавляет еще один, инструмент пишет третий. В итоге один пользовательский запрос превращается в несколько несвязанных историй.
Для ретрая лучше сохранять исходный trace_id и добавлять отдельный признак попытки: attempt, retry_number или новый span_id. Тогда видно, что запрос один и тот же, а шагов у него было несколько.
Не меньше проблем создает несогласованность в именах полей. Один сервис пишет traceId, другой trace_id, третий кладет id в metadata.request.trace. Поиск по логам сразу дает дыры, а часть событий просто не находится. На бумаге это мелочь. В ночном разборе инцидента это лишние полчаса.
Отдельная боль начинается при fan-out. Модель вызвала три инструмента, каждый пошел в свой воркер, а дальше один из них потерял исходный trace_id и оставил только локальный job_id. После этого таймлайн рвется. Видно успешный ответ модели и отдельно ошибку в одном tool call, но быстро доказать, что это части одного запроса, уже трудно.
Еще одна типичная ошибка - искать сбой только по времени. Для LLM этого почти всегда мало. В одну и ту же секунду у вас могут идти запросы от разных tenants, на разных моделях и через разные маршруты. Если в фильтре нет хотя бы tenant_id, model и trace_id, велика вероятность, что вы смотрите не на тот запрос.
Плохо и когда клиенту возвращают один id, а в логах живет другой. Пользователь присылает request_id из ответа, а поддержка не находит его в Kibana, ClickHouse или APM. Потом выясняется, что снаружи это request_id, а внутри еще есть trace_id, который нигде не показали. Если вы отдаете id клиенту, команда должна либо находить по нему весь путь запроса, либо мгновенно переходить к связанному trace_id.
Короткая проверка
Если поиск одного сбоя у вас до сих пор начинается с пяти разных логов, трассировка еще не доведена до рабочего состояния. Вся схема должна держаться на одном trace_id, который живет от входа в шлюз до ответа инструмента и финального статуса у клиента.
Проверьте несколько простых вещей:
- шлюз создает
trace_idдля каждого входящего запроса, если клиент не прислал свой - очередь переносит этот id и в headers, и в payload
- воркер пишет
trace_idдо вызова модели и сразу после ответа - инструменты добавляют тот же id в обычный лог, в ошибку и в запись о таймауте
- дашборд, поиск и алерты используют одно имя поля во всех сервисах
Есть хороший тест. Отправьте один синтетический запрос с редким текстом, дождитесь ответа и попробуйте найти весь путь только по одному id. Если за пару минут вы не видите вход в шлюз, постановку в очередь, старт воркера, вызов модели и работу инструмента, значит в схеме еще есть дыры.
Если вы используете RU LLM, проверьте не только входящий OpenAI-совместимый запрос, но и все внутренние шаги после него. Чаще всего id теряется не на первом хопе, а между очередью и воркером или в логах инструментов.
Что сделать в проде
Начните с дисциплины в мелочах. Если в одном сервисе поле называется trace_id, а в другом traceId или x-trace-id, разбор инцидента снова станет ручной работой. Выберите одно имя поля для логов, сообщений очереди, HTTP-заголовков и событий инструментов. Формат тоже лучше зафиксировать один, например UUIDv7 или 32 символа hex.
Не смешивайте роли идентификаторов. trace_id связывает весь путь запроса, request_id живет внутри одного узла, а span_id описывает отдельный шаг. Когда эта граница понятна всей команде, таймлайн собирается за минуты, а не по кускам из пяти систем.
Полезно закрепить это в коротком внутреннем стандарте:
- одно имя поля во всех сервисах
- один формат id без исключений
- обязательная передача id через очередь и вызовы инструментов
- запись
trace_idв каждый лог, где есть ошибка или внешний вызов
После этого устройте учебный инцидент. Возьмите реальный сценарий: запрос пришел в шлюз, ушел в очередь, агент вызвал инструмент и вернул пустой ответ. Пусть дежурный инженер найдет всю цепочку только по trace_id. Засеките время разбора до правила и после. Если разница не измеряется десятками минут, схема у вас все еще слишком сложная.
Рабочие инструкции тоже лучше поправить сразу. В шаблоне разбора инцидента достаточно трех полей: trace_id, время начала и список узлов, через которые прошел запрос. Этого обычно хватает, чтобы новый инженер не гадал, с чего начинать поиск.
Старайтесь держать схему простой. Новый инженер должен понять ее за 10 минут: где id рождается, где передается, где ищется в логах и кто отвечает за потерю контекста. Если для этого нужна длинная схема на двадцать блоков, проблема уже не в трассировке, а в устройстве системы.
Финальный критерий тоже простой: откройте инцидент по одному trace_id и соберите весь путь запроса без чатов, созвонов и ручного сопоставления строк. Если это получается стабильно, схема работает.
Часто задаваемые вопросы
Зачем вообще нужен один trace_id на весь LLM-запрос?
Чтобы собрать весь путь запроса по одному полю. Если шлюз, очередь, воркер и инструмент пишут разные id, инженер ищет сбой по времени и руками склеивает куски логов. С общим trace_id сразу видно, где запрос ждал, где упал и был ли ретрай.
Где лучше создавать trace_id?
Создавайте trace_id в первой точке входа, обычно в API-шлюзе. Не ждите очередь, воркер или SDK провайдера, иначе вы потеряете начало цепочки и потом не восстановите полный таймлайн.
Чем trace_id отличается от request_id и span_id?
Нет, это разные роли. trace_id связывает весь путь одного пользовательского запроса, request_id живет внутри одного сервиса, а span_id показывает отдельный шаг вроде постановки в очередь или вызова инструмента.
Как не потерять trace_id в очереди и воркере?
Передавайте один и тот же trace_id и в headers, и в payload сообщения. Тогда воркер увидит его даже после ретрая, а вы не потеряете связь между job в очереди и исходным запросом клиента.
Что делать с trace_id при ретраях?
При ретрае оставляйте исходный trace_id без изменений. Для новой попытки добавьте retry_number или новый span_id, чтобы видеть и общую историю запроса, и каждую попытку отдельно.
Что писать в логах, кроме trace_id?
Логируйте не только trace_id, но и span_id, parent_span_id, request_id, статус, код ошибки и duration_ms. Для LLM-пайплайна еще полезно писать модель, провайдера, job_id, имя инструмента и причину timeout, cancel или retry.
Можно ли зашивать user_id или email в trace_id?
Да, особенно если у вас есть 152-ФЗ и обычные требования к безопасности. Не вставляйте email, телефон, логин или номер договора в trace_id и request_id; храните их в отдельных полях и маскируйте до записи в лог.
Как быстро понять, где именно тормозит запрос?
Полезнее строить один таймлайн по trace_id, а не смотреть логи по сервисам по очереди. В хорошем таймлайне вы видите вход в шлюз, ожидание в очереди, старт модели, вызовы инструментов, первый токен и причину завершения стрима.
Нужно ли отдавать trace_id клиенту?
Возвращайте клиенту тот же trace_id в обычном ответе, в streaming-событиях и в ошибках. Тогда саппорт, разработчик и сам пользователь обсуждают один и тот же запрос, а не пересказывают текст промпта и примерное время сбоя.
Как проверить, что трассировка уже работает в проде?
Пошлите один синтетический запрос с редким текстом и попробуйте найти весь путь только по одному id. Если за пару минут вы не видите шлюз, очередь, воркер, модель и инструмент, значит схема еще дырявая и где-то контекст теряется.