Холодный старт моделей с открытыми весами: прогрев или пул
Холодный старт моделей с открытыми весами не всегда лечится прогревом. Покажем, когда прогрев нужен, а когда выгоднее держать горячий пул.
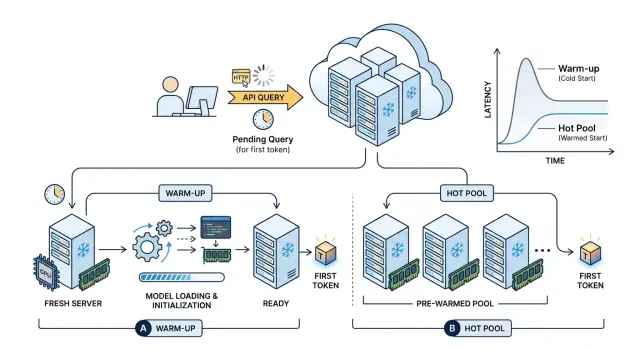
Почему тянется первый ответ
Пользователь замечает не "медленную модель", а паузу перед первым токеном. Именно она сильнее всего портит ощущение скорости: запрос уже ушел, а интерфейс молчит. Эту задержку обычно измеряют через TTFT - время до первого токена.
При холодном старте модели с открытыми весами серверу мало просто принять запрос. Ему нужно поднять процесс инференса, проверить свободную GPU-память и подготовить модель к работе. Если инстанс давно простаивал или его выгрузили ради экономии, запрос попадает не в готовую среду, а в процесс запуска.
Самая дорогая часть паузы - загрузка весов. Модель может занимать десятки гигабайт, и эти данные нужно прочитать и разложить в память GPU. Даже если сеть и API быстрые, чтение весов, инициализация рантайма и служебные шаги нередко занимают больше времени, чем сама генерация первого фрагмента ответа.
Дальше накладываются более мелкие задержки. Запрос может встать в очередь, если GPU занята. Токенизатор сначала разбирает длинный промпт и системные инструкции. Лимиты параллелизма могут удержать запрос до освобождения слота. Часть времени уходит на маршрутизацию, логирование и служебные проверки.
Из-за этого два одинаковых запроса часто ведут себя по-разному. Днем модель уже лежит в памяти, очередь короткая, и первый токен приходит быстро. Ночью или после долгого простоя тот же запрос ждет заметно дольше.
Хороший пример - внутренний помощник банка. В рабочие часы сотрудники пользуются им постоянно, а ночью почти не обращаются. Утром первый запрос может ждать не потому, что модель "думает", а потому что инфраструктура заново поднимает процесс и загружает веса в GPU.
Поэтому смотреть стоит не только на среднюю задержку ответа, а отдельно на TTFT и на долю запросов, которые попали в холодный запуск. Иначе причина паузы просто теряется внутри общей цифры.
Что измерить до выбора схемы
Прежде чем решать, нужен ли прогрев или постоянный горячий пул, разложите задержку по частям. Общая длительность ответа почти всегда скрывает реальную причину.
Сначала измерьте TTFT отдельно от полного времени ответа. Если первый токен приходит через 8 секунд, а дальше текст печатается быстро, проблема одна. Если первый токен появляется за секунду, а весь ответ тянется 20 секунд, искать причину нужно уже в длине вывода, скорости генерации или параметрах запроса.
Среднее значение почти бесполезно. Смотрите хотя бы на p50, p95 и p99. p50 покажет обычное поведение, p95 - то, что уже раздражает пользователей, а p99 - редкие, но самые неприятные провалы. Для холодного старта это особенно важно: средняя цифра может выглядеть терпимо, пока хвост задержек ломает опыт заметной части запросов.
Полезно прогнать один и тот же сценарий в трех режимах:
- Полностью холодный запрос после простоя.
- Теплый запрос сразу после прогрева.
- Повторный запрос в серии, когда модель уже занята.
Такой тест быстро показывает, дает ли прогрев реальный выигрыш. Если разница между холодным и теплым состоянием составляет 5-10 секунд, прогрев часто оправдан. Если выигрыш меньше секунды, отдельная механика прогрева обычно только усложняет систему.
Еще один важный замер - сколько минут модель живет без трафика, прежде чем снова уходит в холодное состояние. У одних команд запросы идут каждые 20-30 секунд, и модель почти не остывает. У других бывают паузы по 15 минут, и каждый новый пользователь снова платит временем за загрузку.
Полезная стартовая таблица очень простая: режим запроса, TTFT, полная длительность, p50, p95, p99 и время простоя перед тестом. Этого уже достаточно, чтобы выбрать схему без догадок.
Когда прогрев помогает
Прогрев нужен там, где задержка первого ответа появляется после деплоя, рестарта или долгого простоя. Пока веса уже лежат в памяти GPU, модель отвечает быстро. После паузы TTFT резко растет. Пользователь видит не медленную генерацию, а долгую подготовку перед первым токеном.
В такой ситуации короткий служебный запрос часто дает заметный эффект. Он поднимает процесс, загружает веса, заполняет нужные кэши и убирает самую неприятную паузу. Для чата, внутреннего поиска или классификации этого нередко достаточно, если трафик потом идет серией.
Лучше всего прогрев работает при предсказуемой нагрузке. Если пик приходит по расписанию, модель не нужно держать горячей весь день. Проще отправить 1-2 технических запроса за несколько минут до начала смены, утреннего потока или пакетной обработки. В корпоративных сценариях это обычная история: люди начинают работать примерно в одно и то же время.
Короткий прогрев почти всегда выгоднее постоянного пула, если простой длинный, а всплески короткие. Вы платите за пару подготовительных запросов, а не за GPU, которая ждет пользователей часами.
Прогрев подходит, если у вас совпадают четыре условия:
- после простоя первый запрос заметно медленнее остальных;
- дальше трафик идет серией, а не одним запросом в час;
- пики можно предсказать по времени;
- цена прогревочных вызовов ниже, чем цена постоянно горячей реплики.
Если разница между холодным и теплым TTFT падает, например, с 20-40 секунд до 2-4, эффект уже трудно игнорировать.
Когда прогрев не решает проблему
Прогрев помогает только в узком случае: модель в целом умеет отвечать быстро, но ей нужен короткий старт перед первым запросом. Если задержка живет в другом месте, прогрев становится дорогой привычкой. GPU занята, а пользователи все равно ждут.
Так бывает, когда между запросами проходят десятки минут. Да, можно отправлять фоновый запрос каждые 5-10 минут, но тогда вы почти платите за постоянную готовность. Для редкого трафика это обычно плохая сделка.
Еще хуже, когда модель и так работает на пределе памяти. Она может загружаться с оффлоадом, упираться в VRAM, дергать диск или соседнюю карту. В такой схеме прогрев не убирает главную паузу, потому что веса и KV-cache все равно двигаются слишком долго. Первый токен приходит поздно не из-за "сна", а из-за нехватки ресурсов.
Есть и другая ловушка: пользователи приходят волнами. Полчаса тишины, потом двадцать запросов за минуту. Один прогретый инстанс примет первый запрос быстро, а остальные встанут в очередь или будут ждать запуска новых реплик. В таком режиме прогрев одной копии почти ничего не меняет.
Обычно вы греете не то место, если видите такую картину:
- TTFT после старта нормальный, но полный ответ все равно слишком долгий;
- задержка растет вместе с длиной вывода, а не только на первом запросе;
- в пик очередь растет быстрее, чем поднимаются инстансы;
- после прогрева память GPU почти заполнена, и система начинает выгружать части модели.
Отдельный случай - медленная генерация. Если модель начинает отвечать быстро, но печатает 8-12 токенов в секунду, прогрев не спасет. Здесь уже нужно смотреть на размер модели, квантизацию, длину контекста, batch size и ограничения по GPU. Иногда лучше сократить ответ, взять другую модель для черновика или держать постоянный горячий пул.
Когда нужен горячий пул
Горячий пул нужен там, где пользователи обращаются к модели весь рабочий день и ждут ровный TTFT, а не поведение "как повезет". Если сервис то отвечает за 0,8 секунды, то за 8 секунд после паузы, люди воспринимают это как сбой, даже если средняя задержка на графике выглядит нормально.
В этой схеме первый запрос не будит модель с нуля. Он сразу попадает на уже загруженную копию: веса в памяти, рантайм поднят, GPU не тратит время на инициализацию. Это особенно полезно там, где запросы идут волнами - утром, после обеда, после массовой рассылки или в начале смены операторов.
Пул помогает и тогда, когда одна копия быстро упирается в очередь. Один длинный запрос с большим контекстом может занять сервер гораздо дольше обычного. Если у вас всего один живой инстанс, следующий пользователь увидит рост TTFT, хотя модель уже прогрета. Несколько копий сглаживают такие скачки.
Обычно пул делят по профилю нагрузки: отдельные копии оставляют под короткие диалоги, отдельные - под длинный контекст, еще одну - в резерве на перезапуск или сбой. Это простая мера, но она часто дает более ровный отклик, чем бесконечная настройка прогрева.
Горячий пул стоит денег. Вы платите за предсказуемость, а не за максимальную утилизацию железа. Но для внутреннего помощника, чат-поддержки, операторского интерфейса или API с SLA это часто разумный обмен. Стабильный отклик там важнее, чем экономия нескольких часов GPU ночью.
Как выбрать режим
Решение лучше принимать по цифрам, а не по ощущениям. Для холодного старта важны две вещи: как часто модель простаивает и какой TTFT вы готовы терпеть в реальном продукте.
Средняя задержка почти всегда уводит в сторону. Смотрите на p95 и на первый токен отдельно.
- Возьмите трафик хотя бы за неделю и разбейте его по часам и сценариям: чат, суммаризация, классификация.
- Для каждого сценария задайте допустимый TTFT. Для внутреннего поиска 2-3 секунды могут быть приемлемы, для живого чата обычно ждут меньшую цифру.
- Замерьте холодный подъем каждой модели отдельно: загрузку весов, инициализацию рантайма и первый успешный ответ. У одной модели это 8 секунд, у другой - 40.
- Прогоните одинаковый набор запросов в трех режимах: без прогрева, с прогревом по расписанию и с горячим пулом.
- Сравните не только среднее время, но и p95, p99, частоту холодных запусков и загрузку GPU.
- Оставьте самый простой режим, который укладывает p95 в целевое значение без лишних копий.
Обычно картина получается довольно приземленной. Редкий ночной трафик и длинные паузы между запросами - хватит прогрева. Плотный дневной поток, где люди ждут ответ сразу, - чаще нужен горячий пул хотя бы для одной-двух моделей.
После выбора не считайте задачу закрытой. Повторите замеры после смены модели, квантизации, размера контекста или GPU. Один такой апдейт легко ломает расчеты, которые месяц назад казались нормальными.
Пример с внутренним помощником банка
Представьте внутреннего помощника банка, который отвечает сотрудникам на вопросы по регламентам, продуктам и процедурам. Ночью им почти не пользуются, а в 9:00 в систему сразу приходят десятки запросов. Кто-то открывает смену, кто-то ищет правило, кто-то проверяет шаблон ответа клиенту.
Если модель простаивала всю ночь, утренний всплеск почти всегда бьет по одному месту: TTFT резко растет. Модель грузит веса в память, поднимает окружение, прогревает кэш. Для сотрудника это выглядит просто: помощник слишком долго молчит.
Здесь прогрев по расписанию работает хорошо. Если запускать короткий warm-up за 10 минут до начала смены, первый живой запрос уже не тратит время на холодный старт. Утром разница заметна сразу.
Но после обеда картина меняется. Трафик идет не ровно, а волнами. После планерки, рассылки или смены статуса в очереди в помощника снова приходят группы пользователей. В этот момент одной прогретой копии уже мало. Она быстро примет первый запрос, но дальше очередь начнет расти.
В такой схеме обычно лучше работает гибридный режим: утром один инстанс прогревают заранее, в активные часы держат 2-3 горячие копии, а ночью пул снова уменьшают до минимума. Это дает не самый красивый средний показатель на бумаге, зато предсказуемое время ответа в течение дня. Для внутреннего сервиса это важнее.
Ошибки, которые дорого обходятся
Частая ошибка - греть модель по таймеру, не глядя на реальный трафик. Команда отправляет тестовый запрос каждые 5 минут, потому что так спокойнее. Если пики приходят утром и после обеда, а ночью запросов почти нет, такой прогрев просто сжигает GPU-часы и не убирает задержку там, где она действительно мешает.
Другая дорогая ошибка - держать редкую модель горячей весь день. Если ее вызывают раз в час или реже, вы платите за готовность, которой почти никто не пользуется. В таких сценариях часто разумнее принять редкий холодный старт или включать прогрев только в ожидаемые окна нагрузки.
Еще один промах - сводить TTFT и полную задержку в одну цифру. Пользователь ощущает именно первый ответ. Когда экран молчит 8 секунд, это раздражает сильнее, чем долгая генерация после первого токена. А в дашборде при этом может висеть нейтральное "среднее 12 секунд", которое ничего не объясняет.
Размер контекста тоже часто недооценивают. Модель может стартовать быстро на коротком запросе и резко проседать на длинных диалогах, потому что растет память под KV-cache. Из-за этого схема, которая выглядела дешевой на тестах, разваливается в проде.
И еще одна ловушка - смотреть только на average latency. Среднее почти всегда рисует слишком приятную картину. Для эксплуатации полезнее держать перед глазами TTFT отдельно, p50, p95, p99, частоту вызовов по часам и загрузку памяти на один инстанс.
Короткий чек-лист перед запуском
Перед запуском достаточно ответить на несколько простых вопросов.
- Какой TTFT допустим для вашего живого сценария?
- Сколько стоит минута GPU для каждой модели, которую вы реально рассматриваете?
- Как выглядит график нагрузки по часам, а не среднее за сутки?
- Проверяли ли вы схему на реальных промптах и реальной длине ответов?
- По какому правилу пул будет расти и сжиматься?
Если этих цифр нет, команда почти наверняка лечит не ту проблему и платит либо временем пользователя, либо пустым простоем GPU.
Что делать дальше
Не пытайтесь сразу подобрать один режим для всех сценариев. Возьмите один сервис с понятной нагрузкой и одну модель, у которой холодный старт уже мешает пользователям. Например, внутренний чат для сотрудников или разбор обращений в поддержку.
Дальше нужен короткий пилот на одинаковых запросах. Прогоните один и тот же набор промптов в двух режимах: с прогревом по расписанию и с горячим пулом на фиксированном числе инстансов. Смотрите не только на TTFT, но и на долю запросов с долгим стартом, загрузку GPU по часам и стоимость недели работы.
Если нужен пилот в российском контуре без переделки текущей интеграции, можно проверить RU LLM на rullm.com. У сервиса есть OpenAI-совместимый эндпоинт, а для hosted open-weight моделей используются российские ЦОДы, так что сравнить прогрев и пул можно на тех же SDK, коде и промптах.
Хорошее рабочее правило тоже простое: заранее зафиксируйте порог, после которого вы переходите с прогрева на горячий пул. Например, если TTFT в рабочие часы три дня подряд выше целевого значения или если простои начинают стоить дороже, чем ожидалось. Тогда выбор перестает быть спором и становится обычным эксплуатационным решением.