Метрики дашборда LLM-платформы: 12 сигналов для CTO
Метрики дашборда LLM-платформы помогают CTO видеть качество, цену, сбои и риски 152-ФЗ без перегруза графиками и лишними показателями.
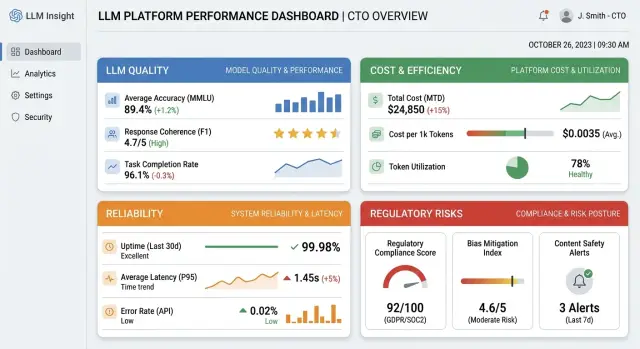
Почему дашборд быстро превращается в шум
У CTO редко бывает нехватка графиков. Проблема в другом: графиков много, а ответа на простой вопрос нет. Где сегодня риск для бизнеса: в качестве ответов, в счете от провайдеров, в сбоях или в требованиях 152-ФЗ?
Шум начинается тогда, когда команда меряет то, что легко снять, а не то, что помогает принять решение. Токены в минуту, средняя задержка, число запросов, загрузка очереди - все это полезно, но только как фон. Если рядом нет доли успешных ответов по важным сценариям, цены за полезный результат и частоты отказов по провайдерам, дашборд успокаивает, а не помогает управлять.
Часто метрики еще и разбросаны по разным системам. Качество смотрят в eval-системе. Расходы лежат в биллинге. Сбои уезжают в мониторинг. Регуляторные события прячутся в отдельной панели у безопасников. В итоге CTO открывает четыре экрана и сам собирает картину в голове. Обычно это значит одно: сигнал о риске приходит поздно.
Особенно быстро шум растет в мультипровайдерной схеме. Один провайдер дешевле, другой точнее, третий чаще спасает ночью при сбое. Если дашборд не связывает эти данные в одном месте, команда видит только отдельные куски: ответ стал дешевле, но ручных проверок стало больше; средняя задержка снизилась, но p95 вырос; инцидентов стало меньше, но доля запросов с PII-флагами пошла вверх; fallback сработал, но запрос ушел в контур, который не подходит по политике хранения.
Для LLM-платформы это заметно уже через несколько дней. Система вроде бы работает, запросы идут, пользователи не жалуются. Но финансы уже видят перерасход, продукт замечает падение качества в одном сценарии, а юристы находят логи не там, где ожидали. Хороший дашборд должен отвечать не на вопрос "что у нас происходит", а на вопрос "что нужно исправить сегодня".
Как выбрать 12 метрик
Хороший дашборд LLM-платформы нужен не для отчетности. Он должен быстро отвечать на четыре вопроса: модель дает нужный результат, сколько это стоит, можно ли на нее опереться каждый день и не создает ли она регуляторный риск.
Поэтому дашборд лучше сразу делить на четыре блока: качество, цена, надежность и регуляторика. В каждом блоке - только три метрики. Такой лимит дисциплинирует. Когда метрик становится 20 или 25, команда смотрит на графики, но не понимает, что делать утром после алерта.
Важно и то, чтобы блоки были равны по весу. CTO легко увести панель в сторону цены и latency, а потом пропустить рост отказов в одном сценарии или проблему с персональными данными. Баланс 3 на 3 на 3 на 3 помогает держать общую картину без споров о том, что важнее.
У каждой метрики должен быть владелец. Не абстрактная "платформа", а конкретная роль: ML lead, SRE, FinOps, security или продуктовая команда. Рядом нужен порог тревоги и понятное действие. Если средняя стоимость за 1000 запросов выросла на 18%, кто проверяет маршрутизацию? Если доля ответов с PII без маскирования ушла выше нуля, кто останавливает релиз? Метрика без владельца почти всегда становится фоном.
Сразу задайте и срезы. Общая средняя цифра почти всегда врет. Смотрите данные как минимум по модели, провайдеру, сценарию и продукту. Иначе можно увидеть "нормальную" стоимость в целом, но не заметить, что один продукт с длинными промптами сжигает бюджет, а один провайдер дает всплеск ошибок только на задаче извлечения данных.
Если сомневаетесь, оставляйте метрику только после простого теста: может ли команда принять по ней конкретное решение за 10 минут. Если нет, ей не место на первом экране.
Три метрики качества
Сводить качество к одному числу опасно. Одна и та же модель может хорошо писать короткие ответы, но срываться на извлечении полей из договора или путать факты в ответах для поддержки. Поэтому качество лучше держать в трех метриках.
Доля успешных ответов по бизнес-сценарию
Считать ее нужно не по абстрактной шкале "хорошо или плохо", а по тому, выполнил ли ответ полезное действие. Для поддержки это может быть ответ без правок оператора. Для KYC или документооборота - все нужные поля заполнены, формат соблюден, запрос не ушел на ручной разбор.
Формула простая: успешные ответы / все ответы в этом сценарии.
Оценка на контрольной выборке
Берите набор типовых запросов и проверяйте его по одной шкале каждую неделю или после смены модели. Если сценарии быстро меняются, полезна ручная проверка случайной выборки из продакшена. Достаточно короткого рубрикатора: точность, полнота, соблюдение формата.
Эта метрика нужна не для красоты. Она помогает заметить деградацию до того, как на нее массово пожалуется продукт.
Доля фактических ошибок в критичных запросах
Именно эта метрика чаще всего прячется за хорошим средним баллом. Если модель перепутала ставку, срок договора, лимит, ФИО или обязательное условие, такой ответ нельзя считать "почти хорошим". Это ошибка.
Обычно достаточно смотреть отдельно несколько типов критичных запросов: ответы с цифрами и датами, пересказ договоров и регламентов, ответы клиенту с риском неверного обещания и извлечение данных из документов.
Эти три метрики стоит смотреть отдельно по модели и по типу задачи. Общий срез по системе почти всегда скрывает проблему. Модель может давать 95% успеха в суммаризации и только 76% в извлечении реквизитов. Для CTO это уже не "качество в среднем", а ясное решение: где менять модель, где чинить промпт, а где добавлять обязательный review.
Три метрики цены
Смотреть только на цену токена почти бесполезно. Дешевая модель часто дает больше повторов, длиннее контекст и больше незавершенных попыток. В итоге бюджет уходит быстрее, чем кажется по прайсу.
Для дашборда полезнее три метрики, которые связаны с реальной работой продукта.
Стоимость одного полезного ответа
Эта метрика отвечает на простой вопрос: сколько вы платите за ответ, который пользователь действительно может использовать.
Считайте так: все затраты на запросы делите на число полезных ответов. Что такое "полезный", команда должна определить заранее. Для поддержки это может быть диалог без эскалации на оператора. Для внутреннего помощника - ответ, после которого сотрудник не переписывает запрос заново.
Здесь быстро видно неприятную правду: модель может быть дешевле по токенам, но дороже по делу. Если она чаще ошибается, просит повторный запрос или тянет лишний контекст, цена полезного ответа растет.
Цена 1000 успешно решенных задач
Эта метрика ближе к бизнесу. Она показывает, сколько стоит не сам ответ, а законченная задача: классификация обращения, заполнение карточки, черновик письма, проверка документа.
Формула простая: общие затраты / число успешно решенных задач x 1000.
Такое число удобно сравнивать между командами, продуктами и месяцами. Часто оказывается, что модель на 15% дешевле по токенам, но завершает задачу только в 72% случаев. Другая дороже, зато закрывает 89%. Во втором случае цена 1000 решенных задач нередко выходит ниже.
Доля расходов на потери
Эта метрика показывает, сколько денег сгорает впустую. Обычно в нее входят три источника потерь: повторы, таймауты и слишком длинный контекст.
Считать можно так: расходы на неудачные или лишние запросы / общие расходы.
Если показатель ушел выше нормы, проблема обычно не в самой модели, а в маршрутизации, лимитах, промптах или логике повторов. Полезно отдельно видеть, что именно создает потери: повторы после неудачного ответа, таймауты и обрывы, лишние токены из-за раздутого контекста.
Все три метрики цены режьте как минимум по провайдеру, модели и продукту. Иначе дешевый сценарий маскирует дорогой, а сильная модель скрывает слабую. Если в панели есть только "стоимость за 1M токенов", она почти ничего не объясняет. Если есть цена полезного ответа, цена 1000 решенных задач и доля потерь, разговор о бюджете сразу становится предметным.
Три метрики надежности
Надежность LLM видно не по среднему времени ответа и не по общей цифре ошибок. Здесь важны сигналы, которые сразу показывают, где именно система ломается и насколько часто это замечают пользователи.
P95 latency по каждому сценарию
Считать задержку нужно по сценариям. Короткий чат, извлечение полей из документа и длинная генерация живут в разном темпе. Если свести их в одну линию, дашборд станет красивее, но потеряет смысл.
Среднее время ответа почти всегда успокаивает зря. Если девять запросов из десяти приходят за 2 секунды, а каждый двадцатый висит 18 секунд, пользователь запомнит именно задержку. Поэтому полезнее смотреть P95 отдельно для поиска по базе знаний, tool calling, суммаризации и других рабочих путей.
Доля ошибок провайдера и rate limit отдельно от ошибок клиента
Не смешивайте сетевые сбои, ошибки модели и ошибки клиента в одну корзину. Таймаут соединения, ответ провайдера 5xx, upstream 429 и неверный JSON от вашего приложения говорят о разных проблемах и требуют разных действий.
Правило простое: если команда продукта прислала битую схему, это не сбой провайдера. Если провайдер уперся в rate limit, это не ошибка клиента. Если сеть между вашим сервисом и шлюзом рвется, модель тут ни при чем.
Частота переключения на резервную модель
Эта метрика показывает скрытую нестабильность. Если шлюз часто уводит трафик на запасной маршрут, SLA может выглядеть нормально, но качество ответа, цена и задержка уже поплыли.
Для систем с маршрутизацией между несколькими моделями это особенно важный сигнал. Он быстро показывает, какой провайдер проседает и как часто прод держится на fallback.
Нормальный блок надежности отвечает на три вопроса: где тормозит, кто ошибается и как часто система включает запасной план. Обычно этого хватает, чтобы не чинить не ту часть цепочки.
Три метрики регуляторного риска
Регуляторный риск в LLM-системе редко приходит как один большой инцидент. Чаще он копится тихо: где-то в запрос ушли персональные данные без маскирования, где-то сервис не проставил AI-Law-метку, а где-то трафик ушел в контур, который команда не согласовывала.
Поэтому в дашборде CTO нужны не общие слова про compliance, а три понятные метрики.
Доля запросов с PII до маскирования
Эта метрика показывает, сколько чувствительных данных вообще пытается попасть в модель. Это ранний сигнал. Если доля растет, проблема обычно не в модели, а в продуктовой логике, шаблонах промптов или в новом сервисе, который начал отправлять лишние поля.
Для банка, ритейла или телеком-продукта даже небольшой скачок уже повод открыть примеры запросов и проверить источник.
Доля запросов без AI-Law-меток и audit trail
Если запрос нельзя связать с владельцем сервиса, сценарием использования и историей обработки, вы теряете управляемость. Во время аудита среднее число по платформе мало что дает. Нужен ответ на простой вопрос: какие команды отправляют трафик, который потом нельзя нормально разобрать.
Доля трафика вне разрешенного контура хранения
Для российского рынка это одна из самых практичных метрик. Она отвечает не на абстрактный вопрос про безопасность, а на конкретный: где реально оказались данные, логи и бэкапы.
Если у вас есть требования по хранению в РФ и по 152-ФЗ, любое отклонение должно сразу попадать в красную зону.
Среднее значение по всей компании почти всегда скрывает проблему. Один внутренний бот может держать риск на нуле, а соседний сервис поддержки клиентов - тянуть весь показатель вверх. Поэтому режьте эти три метрики по командам, продуктам, провайдерам и типам данных.
Как это выглядит на реальном сценарии
Представим банк, который запускает помощника для операторов контакт-центра. Он подсказывает ответы по тарифам, статусам заявок, условиям карт и пунктам договора. На старте все выглядит спокойно: средняя цена запроса приемлемая, задержка нормальная, операторы довольны. Проблемы становятся видны только тогда, когда дашборд режет картину по типам запросов, а не смешивает все в одну цифру.
Через неделю команда меняет основную модель на более дешевую. На общих вопросах разницы почти нет. Но в диалогах про договоры, комиссии и спорные списания модель начинает ошибаться чаще. Средняя метрика качества по всем обращениям почти не меняется, и в этом главная ловушка.
Картина в дашборде может выглядеть так:
- цена 1000 токенов падает на 28%
- точность на договорных запросах падает с 92% до 84%
- доля резервной модели растет с 8% до 27%
- сессии с PII доходят до 14%, а в теме перевыпуска карт - до 38%
Эти цифры уже говорят достаточно. Экономия есть, но она держится на модели, которая чаще путает условия договора. Операторы начинают перепроверять ответы вручную, и выигрыш по цене быстро исчезает.
Чтобы не срывать SLA, команда включает резервную модель для сложных интентов и пиковых часов. Она отвечает ровнее и лучше держит вечернюю нагрузку. Но у нее выше цена, длиннее контекст и больше расход токенов на один диалог. В итоге CTO видит не просто рост затрат на API, а рост стоимости одной смены операторов, например с 480 до 610 рублей на человека. Это уже число, с которым можно работать на уровне бизнеса.
Отдельно дашборд показывает долю запросов с персональными данными. Именно эта метрика быстрее всего обнаруживает, где нужен другой маршрут. Если оператор открывает кейс с паспортом, телефоном, номером счета или текстом заявления, такой диалог лучше сразу отправлять в отдельный поток с маскированием PII, аудит-трейлом и правилами хранения внутри РФ. Для банка это обычная гигиена под 152-ФЗ, а не перестраховка.
Где команды ошибаются чаще всего
Ошибки обычно начинаются не с модели, а с того, как команда смотрит на цифры. Если метрики собраны без контекста, CTO видит аккуратную картинку и пропускает реальную проблему: ответ стал дороже, медленнее или рискованнее для продакшена.
Самая частая ловушка - считать токены вместо стоимости полезного ответа. Два запроса могут стоить одинаково по токенам, но один закрывает задачу с первого раза, а второй уходит в ретраи, ручную проверку или повторный вызов другой модели. Для бизнеса это огромная разница.
Не меньше путаницы дает смешение тестового и боевого трафика. Когда в один график попадают A/B-прогоны, ручные пробы команды и реальные запросы клиентов, средние значения становятся бесполезными. Вчера инженеры прогнали тысячу длинных тестов, и кажется, что прод внезапно подорожал на 30%. На деле вырос только стенд.
Есть и другие типовые ошибки:
- команда смотрит на среднюю задержку и не видит p95 или p99
- все ошибки складывают в одну строку failed requests
- регуляторные метрики живут в отдельном отчете, который почти никто не открывает
- стоимость считают по токенам, а не по успешному результату
- тесты и прод идут в одном потоке
Средняя задержка особенно часто обманывает. Если 90% запросов идут за 2 секунды, а 10% висят по 25 секунд, среднее может выглядеть терпимо. Пользовательский опыт при этом уже сломан.
С ошибками та же история. Rate limit, таймаут провайдера, пустой ответ модели, блокировка по policy и сбой парсинга JSON - это разные поломки с разными действиями. Когда их склеивают в одну категорию, команда не понимает, что чинить первым.
Регуляторные сигналы нельзя прятать отдельно от продовых. Если запросы с персональными данными внезапно пошли без маскирования PII или без audit trail, это не отчет "на потом", а инцидент текущего дня. Удобный дашборд сводит цену, качество, надежность и регуляторный риск на один рабочий экран.
Быстрая проверка перед запуском
Перед запуском не нужен еще один красивый экран. Нужен один рабочий экран, где сразу видны все 12 метрик: качество, цена, надежность и регуляторные сигналы. У каждой метрики должен быть порог и понятный статус. Если показатель вышел за лимит, команда сразу понимает, что делать.
Плохой дашборд показывает число, но не подсказывает следующий шаг. Тогда метрика быстро превращается в фон. Если latency растет, кто меняет маршрут? Если цена за успешный ответ вышла за лимит, кто снижает модель или включает кэш? Если запросы с персональными данными проходят без нужной маскировки, кто останавливает релиз?
Перед запуском стоит проверить пять вещей:
- на одном экране есть все 12 метрик, без переходов между вкладками
- у каждой метрики есть порог, владелец и действие при выходе за лимит
- данные приходят автоматически из API-шлюза, логов, трассировки и прикладной аналитики
- любой график можно разрезать по модели, провайдеру и сценарию
- юристы, SRE и продукт смотрят на один и тот же набор чисел
Ручные выгрузки почти всегда ломают такую схему. CSV из одной системы, скриншот из другой и таблица из третьей создают спор не о проблеме, а об источнике данных. Автоматический сбор лучше просто потому, что ему больше доверяют. Если цифра меняется, все видят это одновременно.
Для LLM-платформы это особенно важно. Один и тот же сценарий может вести себя по-разному на разных моделях и у разных провайдерах. Без срезов вы увидите только среднюю температуру. Со срезами понятно, что именно просело: конкретная модель, один внешний провайдер или отдельный продуктовый сценарий.
Что сделать после первой версии
Первая версия нужна не для красоты, а чтобы поймать рабочий ритм. Не пытайтесь сразу покрыть весь стек и все команды. Возьмите один сценарий, где LLM уже влияет на деньги или риск. Например, внутренний чат для поддержки или разбор клиентских обращений.
Так вы быстрее увидите, какие метрики действительно помогают принимать решения, а какие просто занимают место. Если в одном сценарии цена растет на 18%, а качество не меняется, команда заметит это за день. На общей панели по всей платформе такой сигнал легко потерять.
Через две недели устройте жесткую чистку. Спросите у владельца продукта, инженера и человека, который отвечает за комплаенс: "По какой метрике вы приняли хотя бы одно решение?" Если ответа нет, убирайте ее. Дашборд спокойно переживет минус пять графиков. Люди тоже.
Обычно после первой версии полезно сделать четыре шага:
- оставить только метрики, по которым команда меняет лимиты, маршруты или алерты
- разделить сигналы по сценариям, если один поток дорогой, а другой чувствителен к качеству
- добавить сравнение моделей в одинаковых условиях, если цена и качество расходятся
- проверить, есть ли у каждого инцидента понятный след: запрос, модель, маршрут, причина fallback
Маршрутизация между моделями часто появляется именно на этом этапе. Пока объем небольшой, можно жить на одной модели. Но как только один сценарий требует точности, а другой терпит небольшое падение качества ради экономии, одна модель начинает мешать.
Если вы уже строите такую панель в российском контуре, полезно, когда маршрутизация, биллинг и аудит видны в одном месте. Например, RU LLM на rullm.com дает единый OpenAI-совместимый эндпоинт, хранение логов и бэкапов в РФ, встроенные AI-Law-метки и аудит-трейлы на уровне запроса. Это удобно не для презентации, а для повседневной работы, когда нужно сравнивать модели, держать 152-ФЗ под контролем и не переписывать интеграцию при смене провайдера.
Хорошая вторая версия почти всегда меньше первой. Это нормальный признак. Значит, панель наконец начали использовать по делу.