Ошибки в продакшене LLM: 7 сбоев, которые ломают стек
Разбираем ошибки в продакшене LLM: таймауты, дрейф формата, токены, ретраи и трассировку. Что проверить в первую очередь.
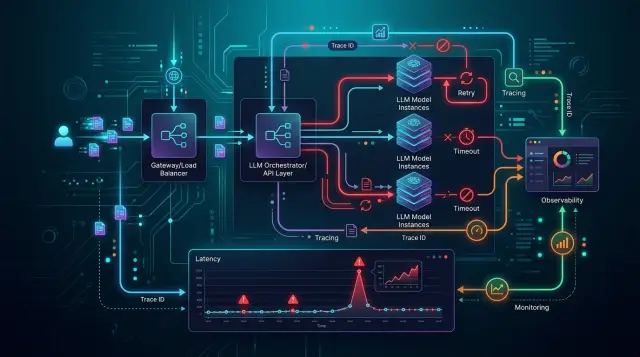
Почему стек LLM ломается в продакшене
Сбои в LLM почти никогда не начинаются с одной большой поломки. Обычно это цепочка мелких проблем. Пользователь отправляет запрос, сервис собирает промпт, шлюз выбирает провайдера, модель отвечает, парсер проверяет JSON, бизнес-логика формирует итог. Если ломается один шаг, разваливается весь ответ.
Проблема в том, что приложение часто показывает один и тот же симптом для разных причин. Пользователь видит пустой ответ, 500, обрыв стрима или "не удалось обработать запрос". За этим могут стоять таймаут, усеченный вывод, дрейф формата ответа, ошибка в подсчете токенов или лишний ретрай, который забил очередь.
Код тоже не всегда помогает. Он может выглядеть аккуратно: запрос ушел, статус пришел, исключение перехватили. Но сбой уже произошел раньше или позже - в маршрутизации, лимитах провайдера, схеме ответа, постобработке или логике фолбэка. В итоге команда чинит не причину, а самый заметный эффект.
LLM-стек ведет себя не как обычный REST API. Один и тот же промпт может десять раз пройти нормально, а на одиннадцатый вернуть другой формат или резко замедлиться. Если команда просто меняет base_url на единый шлюз и оставляет старый код как есть, это удобно, но различия между моделями и провайдерами никуда не деваются. Их все равно нужно видеть отдельно.
Нормальный способ разбираться со сбоями прост: раскладывать путь запроса по этапам. Что пришло от клиента, какой промпт реально ушел, какую модель выбрали, сколько токенов ожидала система, что вернул провайдер, что сделал парсер, где сработал ретрай. Такой разбор быстро убирает половину ложных гипотез.
Если этого не делать, похожие симптомы смешиваются в одну кучу. Тогда таймаут выглядит как баг в JSON, баг в JSON - как проблема модели, а ошибка маршрутизации - как случайный сбой. Продакшен не любит догадки. Ему нужна раскладка по шагам.
Таймауты съедают ответ
Таймаут в LLM-стеке редко сводится к одной цифре. Часто команда ставит общий лимит, например 30 секунд, и считает, что этого достаточно. Потом пользователь ждет слишком долго, а вы все равно не понимаете, где застрял запрос: в сети, у провайдера или уже внутри вашего кода.
Минимум нужно разделять три уровня. Сетевой таймаут отвечает за установку соединения и чтение ответа. Провайдерский ограничивает сам вызов модели. Общий таймаут режет весь путь целиком, вместе с ретраями, валидацией схемы и фолбэком.
Без этого метрики начинают врать. Инцидент выглядит как "медленная модель", хотя на деле несколько секунд ушло на DNS, потом время съел провайдер, а после первого сбоя сервис еще ждал запасной маршрут.
Среднее время ответа почти бесполезно. Смотрите p50, p95 и p99 по каждому этапу: вход в API, маршрутизация, вызов модели, постобработка, запись логов. Тогда видно не только обычное поведение, но и длинный хвост, который и ломает продакшен.
Если вы работаете через единый шлюз, полезно отдельно мерить задержку до шлюза и после маршрутизации. Иначе хвост провайдера смешается с вашей сетью, и поиск причины затянется.
Для чата и пакетных задач лимиты должны отличаться. В чате пользователь редко готов ждать 20-25 секунд. Ночная обработка может терпеть дольше, если это снижает стоимость или позволяет использовать более сильную модель. На практике правило простое: для чата нужен короткий общий таймаут и один быстрый фолбэк, для batch-задач - более длинный лимит и спокойная очередь, а фоновые ретраи лучше вынести за пределы пользовательского запроса.
Самая неприятная ошибка здесь - ждать слишком долго после первого сбоя. Первая модель не ответила за 8 секунд, вторая получила еще 20, потом включился ретрай. Пользователь уже закрыл вкладку, а ваш стек все еще обрабатывает один и тот же запрос и забивает очередь для остальных.
Лучше вернуть короткую ошибку или упрощенный ответ, чем держать соединение до последнего байта.
Формат ответа уплывает
Сегодня модель возвращает аккуратный JSON, а завтра добавляет перед ним пояснение, меняет имя поля или кладет число строкой. Код ломается не из-за магии. Просто у ответа нет жесткого контракта.
Такое часто случается после смены модели, температуры или версии промпта. Если один OpenAI-совместимый эндпоинт маршрутизирует запросы к разным провайдерам, дрейф формата всплывает еще быстрее: одна модель держит схему ровно, другая вставляет лишний текст, третья пропускает поле, которое код считает обязательным.
Типичный сбой выглядит скучно, но бьет больно. Бот поддержки должен вернуть answer, category и needs_human, а модель присылает сначала текст для оператора, потом JSON, а затем комментарий вроде "я выбрал такую категорию". Пользователь проблему может не заметить. Парсер заметит сразу.
Рабочее правило простое: сначала проверяйте схему, потом разбирайте ответ и только потом передавайте его дальше. Если поле не прошло валидацию, останавливайте запрос сразу. Не пытайтесь додумывать ответ регулярками на лету. Такие заплатки живут до первого неудачного релиза.
Помогает разделение на четыре слоя: сырой ответ модели, версия промпта и системных инструкций, валидированный объект для кода и текст, который увидит пользователь. Когда все это смешано в одном куске, одна лишняя фраза ломает и интерфейс, и автоматику.
Сохраняйте сырой ответ вместе с версией промпта, моделью и параметрами вызова. Тогда инцидент можно разобрать за десять минут, а не гадать, где именно уехал формат: в новой модели, в шаблоне промпта или в постобработке.
Во многих случаях проблема не в качестве текста как такового. Система просто слишком поздно понимает, что ответ уже нельзя безопасно использовать. Чем раньше вы режете невалидный формат, тем меньше мусора утечет в ретраи, очереди и бизнес-логику.
Токены считают не так
Одна из самых тихих поломок - неверный подсчет токенов. Запрос выглядит коротким, но модель упирается в лимит, обрывает вывод или внезапно уходит в таймаут после лишнего ретрая. Такие сбои долго маскируются под "нестабильного провайдера".
Чаще всего команда считает токены локально одним токенизатором, а запрос уходит в другую модель с другой разбивкой текста. Это особенно заметно, когда вы меняете маршрут между провайдерами через единый API: код тот же, а реальный расход уже другой.
Проблема почти никогда не ограничивается текстом пользователя. В лимит обычно входят system-сообщения, tool calls, JSON-схемы, история диалога и служебные поля. Команда смотрит только на вход, забывает оставить запас под ответ, а потом удивляется, почему модель обрывает вывод посреди объекта.
Базовая дисциплина здесь простая. Считайте токены тем токенизатором, который соответствует выбранной модели. Включайте в расчет system, tools и служебные сообщения. Резервируйте место под ответ заранее, а не по остаточному принципу. И обязательно сверяйте оценку на клиенте с фактическим usage у провайдера для разных типов запросов.
Быстрая проверка тоже простая: возьмите двадцать реальных запросов из логов, посчитайте токены на клиенте и сравните с тем, что вернул провайдер. Если расхождение стабильно держится на уровне 10-15%, это уже не погрешность, а источник будущих сбоев.
Самый неприятный случай появляется после "безопасной" замены модели. Вчера запрос помещался в 32k, сегодня та же история чата вместе с системным промптом уже не влезает. Один небольшой сдвиг ломает ответы, ретраи и бюджет сразу.
Ретраи плодят нагрузку
Один неудачный вызов сам по себе не страшен. Проблема начинается, когда приложение повторяет запрос 3-5 раз без общего лимита. Если у вас 40 воркеров и каждый делает по 4 повтора, короткий сбой у провайдера быстро превращается в волну лишних запросов. Очередь растет, задержка скачет, пользователи ждут еще дольше.
Ставьте лимит на весь пользовательский запрос, а не только на один HTTP-вызов. Если ответ должен прийти за 20 секунд, дайте всей цепочке, например, 18. В этот лимит входят ретраи, фолбэк, валидация и запись логов. Лимит закончился - запрос надо останавливать, даже если счетчик попыток еще не исчерпан.
Повторять стоит только временные сбои: 408, 429, 5xx и сетевые обрывы. Повторять 4xx без новой причины почти бессмысленно. Ошибка в схеме, битый JSON или неверный ключ сами не исчезнут. Добавляйте jitter к backoff, чтобы воркеры не приходили заново в одну и ту же секунду. И логируйте причину каждой попытки, иначе потом вы увидите только последний сбой, а не первый.
Такая проблема часто маскируется под "плохую модель", хотя источник в клиентской логике. Это особенно заметно в системах с маршрутизацией по нескольким провайдерам: один лишний ретрай может включить фолбэк, а затем отправить новый запрос по другому маршруту. Токенов и GPU-времени тратится больше, а шанс получить нормальный ответ почти не растет.
Если после релиза расход вырос, а качество не изменилось, я бы сначала проверил именно политику повторов.
Трассировка не объясняет сбой
Во время инцидента команда обычно видит только последствия: рост задержки, 500-е ответы и жалобы пользователей. Но без связной трассировки никто не понимает, какой запрос сломался, где он свернул на другой маршрут и почему ответ не дошел.
Частая ошибка проста: каждый слой пишет логи по-своему. Приложение знает один ID, шлюз - другой, провайдер - третий. Потом инженер открывает несколько систем и вручную собирает цепочку по времени. На один инцидент легко уходит час.
Нужен один request_id для всего пути запроса. Он должен проходить через приложение, LLM-шлюз, кэш, фолбэк и провайдера без замены. Внутри можно добавлять свои span_id, но родительский идентификатор должен оставаться тем же.
Для каждого вызова полезно видеть хотя бы модель, выбранный маршрут, версию промпта, факт срабатывания фолбэка, его причину, статус провайдера и задержку. Этого уже хватает, чтобы собрать внятную картину. Если запрос сначала ушел на одну модель, потом маршрут сменился, а затем схема не прошла проверку, вы увидите историю сбоя, а не просто флаг fallback=true.
Связывать нужно не только внутренние логи. Если вы работаете через шлюз, полезно сшивать в одну цепочку события приложения, самого шлюза и апстрима. Тогда видно, где началась проблема: в вашем коде, в маршрутизации, у конкретного провайдера или в новой версии промпта.
Отдельно записывайте причину фолбэка. Фраза "переключились на запасную модель" почти бесполезна. Гораздо полезнее запись вроде "timeout 18s на основном маршруте" или "schema validation failed после ответа модели".
Если трассировка не отвечает на четыре вопроса - какой был запрос, какой маршрут сработал, какая версия промпта ушла и почему включился фолбэк, - это не инструмент разбора, а просто склад логов.
Фолбэки делают хуже
Фолбэк помогает не всегда. Если переключать запрос на запасную модель без четких правил, один сбой быстро тянет за собой следующий. Первая модель упала по таймауту, вторая вернула другой JSON, третья не умеет tools, а приложение ломается уже не в LLM API, а в собственном коде.
Типичный сценарий такой: команда добавила резервную модель на случай инцидента, но не проверила, совпадают ли у нее размер контекста, работа с function calling и поведение при structured output. В итоге бот поддержки после переключения перестает создавать тикеты. Он отвечает обычным текстом вместо вызова функции, хотя до этого все работало.
Если у вас есть единый OpenAI-совместимый шлюз и можно быстро менять провайдера, соблазн понятен: добавить побольше запасных маршрутов и считать задачу закрытой. На практике цепочку переходов нужно определить заранее.
До релиза стоит проверить несколько вещей. У моделей в цепочке должны совпадать лимит контекста, поддержка tools и требования к формату ответа. Менять лучше по одному параметру за раз: сначала модель, потом уже температуру или схему. И обязательно считайте цену и задержку каждого перехода. Иногда запасной маршрут отвечает на полсекунды медленнее и стоит вдвое дороже без заметного выигрыша в качестве.
Хороший фолбэк скучный. Он дает почти тот же ответ, в том же формате, с понятной ценой и задержкой. Если запасной маршрут заметно меняет поведение системы, это уже новый источник сбоев.
Промпты и схемы живут без версии
Еще одна частая причина долгих расследований проста: команда меняет промпт, JSON-схему и парсер сразу, но не помечает это отдельными версиями. Через день ответ "вдруг" ломается, а понять источник уже нельзя. Код тот же, модель та же, а поведение другое.
Если версия не хранится рядом с релизом и с каждым запросом, расследование быстро превращается в спор по памяти. Кто-то правил системный промпт, кто-то добавил новое поле в схему, кто-то ослабил валидацию. В логах видна только ошибка парсинга, но не видно, какая именно связка промпта и парсера ее вызвала.
Рабочий вариант скучный, зато надежный: присваивайте версию промпту, схеме ответа и парсеру по отдельности; пишите эти версии в метаданные запроса и в релизные заметки; меняйте один слой за раз; держите прошлую версию доступной для быстрого отката.
Это экономит часы. Если новый промпт начал чаще пропускать поле status, можно быстро сравнить ответы до выкладки и после. Если проблема началась только после смены парсера, не нужно откатывать все приложение.
Хуже всего, когда команда выкатывает "маленькую правку" вечером перед выходными: новый промпт просит более свободный ответ, а старый парсер все еще ждет жесткий JSON. Поломка выглядит как случайный сбой модели, хотя на деле это рассинхрон версий.
Если вы используете единый шлюз, передавайте версии в атрибутах каждого вызова и смотрите их в трассировке. Это сильно сокращает путь от симптома к причине.
Пример: бот поддержки после релиза
После одного релиза бот поддержки начал странно "молчать" в длинных диалогах. На первых 2-3 сообщениях он отвечал нормально, но после 8-10 реплик часть запросов зависала, а часть заканчивалась пустым ответом. Пользователь видел одно и то же: индикатор загрузки крутится дольше обычного, потом чат просит повторить вопрос.
По метрикам картина быстро стала неприятной. Выросло число ретраев, p95 по задержке ушел вверх, а парсер стал чаще ловить обрыв JSON. Это был не отдельный баг, а цепочка: запрос шел дольше, клиент ждал до дедлайна, потом отправлял тот же запрос еще раз, и система сама наращивала себе нагрузку.
Причина оказалась не в модели и не в сети. После релиза команда добавила в системный промпт новый блок: правила тона, дополнительные проверки и еще один шаг перед финальной выдачей. На бумаге это выглядело безобидно. На деле каждый запрос стал тяжелее на несколько сотен токенов, а на длинной истории диалога этого хватило, чтобы сломать временной бюджет.
Проблема добивала систему в конце ответа. Бот должен был вернуть JSON по схеме, но из-за выросшей задержки и лимита на генерацию ответ иногда обрывался посреди поля. Приложение считало, что модель "ничего не сказала", хотя она просто не успела закончить структуру.
Исправление было простым: команда сократила системный блок, вынесла лишнюю проверку из промпта в код, урезала историю до последних реплик и отказалась от слепого ретрая на тот же запрос без паузы и без нового request_id. После этого длинные диалоги снова стали проходить стабильно.
Такой сбой легко принять за "тупящую модель". На практике один лишний шаг в промпте спокойно добавляет 15-20% к токенам, а вместе с ними приходят задержка, таймауты и битый формат ответа.
Как разобрать инцидент по шагам
Когда ответ от модели ломает цепочку, хуже всего чинить все сразу. Нужен короткий порядок действий, иначе команда тратит час на спор о гипотезах и не находит причину.
Сначала зафиксируйте рамку инцидента: точное время, маршрут, модель, затронутые сценарии и долю ошибок. Если проблема видна только в одном типе запросов, например в JSON-ответах или длинных диалогах, круг поиска сразу сужается.
Дальше работайте на сохраненном входе, а не на "почти таком же" запросе. Возьмите исходный промпт, параметры, системное сообщение, историю, схему ответа и идентификатор провайдера. Повтор того же входа быстро показывает, сломался ли маршрут, парсер или логика повторов.
- Найдите первую метрику, которая ушла вверх: задержка, доля 5xx, число ретраев, расход токенов или ошибки валидации.
- Проверьте таймауты по всей цепочке, а не только в клиенте. Часто gateway ждет дольше, чем апстрим или воркер.
- Сверьте схему ответа с тем, что реально вернула модель. Дрейф формата очень часто выглядит как "глючит модель", хотя падает JSON-парсер.
- Пересчитайте токены на том же входе и на той же модели. Ошибка даже в 10-15% уже ломает лимиты, цену и фолбэки.
- Разберите ретраи по логам. Если каждый timeout рождает еще три повтора, инцидент быстро превращается в самонагрузку.
После фикса не верьте одному удачному ответу. Прогоните короткий smoke test: несколько реальных запросов, один длинный диалог, один structured output и один запрос через запасной маршрут. Так вы находите первое место, где стек начал ломаться, а не лечите симптомы по очереди.
Что обычно делают не так
Чаще всего команда зацикливается на модели и теряет половину картины. Если ответ пропал или сломался, виноватым сразу назначают провайдера. На деле сбой нередко сидит в сети: DNS, балансировщик, прокси, TLS, очередь воркеров или лимиты на стороне шлюза.
Средняя задержка тоже часто успокаивает зря. Дашборд показывает 1.7 секунды, все довольны, а пользователи уже ловят таймауты. Причина банальна: среднее скрывает хвост. Если p95 уехал на 8-10 секунд, продакшен уже болит, даже когда среднее выглядит нормально.
Еще одна частая ошибка - не сохранять сырой ответ. Команда успешно парсит JSON, пишет только готовую структуру и выбрасывает оригинал. Потом формат слегка уплывает, парсер падает, а сравнить уже не с чем. Без сырого тела ответа трудно понять, где именно сломалась схема.
Инциденты нередко пытаются "лечить" новыми ретраями. Это плохая привычка. Один неудачный вызов превращается в три или пять, очередь растет, лимиты сгорают, задержка расползается по системе. Намного полезнее жестко ограничить число попыток, общий срок жизни запроса и набор кодов, при которых повтор вообще допустим.
Отдельно ломает диагностику привычка менять все сразу. Команда в одном релизе обновляет промпт, схему ответа, SDK и параметры таймаута. После этого никто не знает, что именно вызвало сбой. Рабочий порядок скучный: одно изменение за раз, метка версии в логах и быстрый откат.
Если у вас между приложением и моделью стоит LLM-шлюз, эта дисциплина нужна вдвойне. Появляется еще один слой, и без точных логов очень легко обвинить не тот компонент.
Короткий список проверок
Когда начинаются сбои, спорить о моделях уже поздно. Сначала проверьте, видите ли вы запрос целиком - от клиента до провайдера - и можно ли по логам восстановить цепочку событий за пару минут.
Если хотя бы один пункт ниже не закрыт, разбор инцидента почти всегда идет вслепую:
- один
request_idпроходит через клиент, бэкенд, шлюз, модель, постобработку и ответ пользователю; - в логах есть фактические входные и выходные токены, выбранный маршрут, провайдер и точная причина фолбэка;
- ретраи ограничены и по числу попыток, и по общему времени жизни запроса;
- JSON проходит валидацию до бизнес-логики;
- у команды есть одно место, где видны логи, аудит и маршрут запроса.
Для команд, которым важны требования 152-ФЗ и хранение данных в РФ, такой список особенно полезен. Например, в RU LLM на rullm.com этот слой можно закрыть единым OpenAI-совместимым эндпоинтом, аудит-трейлами на каждый запрос, маскированием PII и хранением логов и бэкапов на серверах в РФ. Но даже в этом случае сама дисциплина не исчезает: таймауты, версии промптов, валидацию схем и лимиты на ретраи все равно нужно настраивать отдельно.
Возьмите один недавний сбой и прогоните его по этому списку вручную. После такого разбора "случайные" проблемы обычно перестают быть случайными. Почти всегда ломается наблюдаемость, а не магия внутри модели.
Часто задаваемые вопросы
С чего начать разбор сбоя в LLM-стеке?
Начните с одного конкретного request_id и разложите путь по шагам: вход, сборка промпта, выбор маршрута, вызов модели, парсинг, фолбэк. Сразу смотрите, где выросла задержка или сломался формат. Такой разбор быстрее, чем спор о том, виновата модель или сеть.
Какие таймауты лучше ставить для чат-сценария?
Для чата ставьте короткий общий дедлайн и не растягивайте его ретраями. Полезно разделить сетевой таймаут, лимит вызова провайдера и срок жизни всего запроса, чтобы видеть, где ушло время. Если ответ не успевает, лучше вернуть короткую ошибку или упрощенный результат, чем держать пользователя в ожидании.
Когда ретрай помогает, а когда только вредит?
Повтор нужен только для временных сбоев вроде 408, 429, 5xx и сетевых обрывов. Если сломалась схема, пришел битый JSON или запрос неверный, новый вызов обычно повторит ту же ошибку. Обязательно ограничьте и число попыток, и общее время жизни запроса, иначе ретраи сами создадут нагрузку.
Почему модель вдруг перестает отдавать валидный JSON?
Обычно проблема не в магии модели, а в слабом контракте на выходе. Другая версия промпта, новая модель или смена провайдера легко добавляют лишний текст, меняют имя поля или тип значения. Проверяйте схему до бизнес-логики и сохраняйте сырой ответ, чтобы быстро увидеть, что именно уехало.
Как не ошибиться с подсчетом токенов?
Считайте токены тем токенизатором, который подходит выбранной модели, и берите в расчет не только текст пользователя. В лимит входят system-сообщения, история, tools, JSON-схемы и служебные поля. Еще оставляйте запас под ответ и сверяйте свою оценку с usage у провайдера на реальных запросах.
Что обязательно логировать для нормальной трассировки?
Держите в трассировке минимум: request_id, модель, маршрут, провайдер, версию промпта, факт фолбэка, причину фолбэка, задержку и фактический расход токенов. Этого уже хватает, чтобы понять, где началась поломка. Если у каждого слоя свой ID, инженер потом тратит время на ручную сборку цепочки.
Как настроить фолбэк, чтобы он не ломал систему?
Сначала проверьте совместимость, а уже потом включайте запасной маршрут в продакшен. У основной и резервной модели должны совпадать лимит контекста, работа с tools и требования к structured output. Хороший фолбэк меняет как можно меньше, иначе он приносит новый класс ошибок.
Зачем версионировать промпт, схему и парсер по отдельности?
Разносите версии промпта, схемы ответа и парсера отдельно. Записывайте их в метаданные каждого вызова и не меняйте все сразу в одном релизе. Тогда при сбое вы быстро увидите, что сломалось: текст инструкций, формат ответа или разбор результата.
Почему средней задержки недостаточно для мониторинга?
Среднее скрывает длинный хвост, а именно он чаще всего и бьет по пользователям. Смотрите p50, p95 и p99 по этапам, а не только по всему запросу целиком. Так вы заметите, что проблема сидит, например, в маршрутизации или постобработке, а не в самой модели.
Решает ли единый LLM-шлюз все проблемы продакшена?
Нет, сам по себе шлюз не убирает различия между моделями и провайдерами. Он упрощает интеграцию, дает единый вход, аудит и маршрутизацию, но таймауты, валидацию схем, версии промптов и политику ретраев вы все равно настраиваете сами. Если этого не сделать, старые проблемы просто переедут в новый слой.