Прогноз исчерпания квот по моделям: ранние сигналы
Прогноз исчерпания квот по моделям помогает заранее увидеть пики спроса по сезонности, запускам и росту трафика и не ловить сбои в проде.
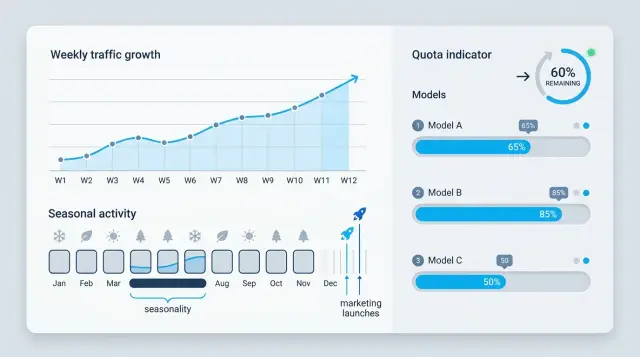
Почему квоты заканчиваются раньше плана
Средний трафик за месяц почти всегда выглядит спокойнее, чем реальная нагрузка. Если команда смотрит только на среднее число запросов в день, она не видит утренние пики, дни после релиза и рост в начале рабочей недели. На бумаге план выглядит безопасно, а в работе лимит уходит за несколько часов одной активной смены.
Проблема усиливается, когда почти весь поток идет в одну модель. Формально у вас может быть большой набор доступных моделей, но в продакшене обычно побеждает одна: она уже дала нужное качество, стоит в дефолтном маршруте или прошла внутренние тесты. Тогда общий запас квот мало помогает. Одна популярная модель быстро выжигает свой лимит, а остальные почти простаивают.
Это часто видно в системах с единым OpenAI-совместимым эндпоинтом, где технически переключиться между моделями несложно. Но само наличие фолбэков ничего не решает, если команда не следит, какая модель забирает 60-80% запросов.
Еще одна частая ошибка - считать только запросы. Квота обычно уходит не по числу вызовов, а по токенам и деньгам. Стоит продукту начать просить длинные объяснения, сводки звонков или развернутые ответы для поддержки, и расход меняется очень быстро. Запросов осталось столько же, но средняя длина ответа выросла в 2-3 раза. Для бюджета это уже совсем другой день.
У границы лимита система меняется резко. Сначала растет очередь на самой загруженной модели. Потом увеличивается задержка, роутер чаще уводит запросы в фолбэк, а фолбэк может оказаться дороже или слабее по качеству. Повторные попытки добавляют еще один слой трафика, и ситуация раскручивается сама.
Поэтому проблема часто не в маркетинге и не в сезонности как таковой. Чаще причина в сочетании четырех вещей: короткий пик, перекос в одну модель, длинные ответы и позднее включение запасного маршрута.
Чтобы прогнозировать расход квот нормально, смотрите не на "средний месяц", а на почасовой расход, долю трафика по моделям и длину ответа в каждом сценарии. Иначе план остается аккуратным только в таблице.
Какие сигналы собирать каждый день
Если смотреть только на общий объем запросов, прогноз почти всегда врет. Квота сгорает не там, где больше вызовов, а там, где выше расход токенов, больше повторов и чаще идут сбои.
Каждый день считайте по каждой модели хотя бы четыре вещи:
- число запросов;
- входные и выходные токены;
- долю ошибок;
- повторы после ошибок.
Одна модель может получать меньше вызовов, но сжигать квоту вдвое быстрее из-за длинных промптов и больших ответов.
Общий трафик тоже мало что говорит без разрезов. Делите данные по продуктам, каналам и регионам. Чат в личном кабинете, внутренний copilot для сотрудников и публичный API растут по-разному. Если свести их в одну линию, локальный всплеск потеряется, и вы заметите проблему слишком поздно.
Ежедневная сводка обычно полезна, если в ней есть расход запросов и токенов по моделям, ошибки по типам, особенно 429, трафик по продукту, каналу и региону, а также события, которые могли поднять спрос.
Такие события лучше фиксировать в тот же день, а не вспоминать потом по памяти. Релиз новой функции, скидка, рекламная волна, письмо по базе, вебинар, demo day у продаж - все это меняет нагрузку. Даже ручная рассылка на 500 клиентов часто дает более резкий пик, чем обычная реклама, потому что люди приходят в продукт почти одновременно.
Отдельно отмечайте смены маршрутизации между провайдерами. Для команд, которые работают через шлюз вроде RU LLM, это особенно заметно: одна и та же модель может пойти через другого провайдера с другими лимитами, задержкой и профилем ошибок. Если правило маршрутизации изменили во вторник, а рост трафика случился в среду, без этой отметки вывод будет неверным.
Хорошо работает простая таблица: дата, что изменилось, какой сегмент затронут, какие модели пострадают первыми. Через несколько недель становится видно, какие сигналы были шумом, а какие действительно предупреждали, что лимиты закончатся раньше плана.
Где взять историю для прогноза
Для прогноза нужна не "вся история", а чистый и ровный отрезок. Обычно хватает 8-12 недель, если в нем нет длинных провалов по логам, смены схемы учета посреди периода и других дыр. Один месяц часто слишком короткий: он плохо ловит недельные пики и слабо показывает, как спрос растет после обычных релизов.
Первая ошибка проста: смешать боевой трафик с тестами. Ночные прогоны, нагрузочные проверки, эксперименты команды ML и ручные запросы из песочницы легко раздувают картину. Если не отделить их сразу, прогноз покажет ложный рост, а лимиты окажутся завышены не там, где это нужно.
Нормальная база выглядит так: по каждому запросу видны время, модель, проект или сервис, число токенов и статус ответа; тестовый и боевой контур помечены разными признаками; разовые события вынесены в отдельные метки; данные можно свернуть по часу, дню и конкретной модели.
Что исключать и что помечать
Не удаляйте аномалии молча. Помечайте аварии у провайдера, собственные инциденты, переносы релизов, промо-рассылки, неожиданные всплески после публикаций и массовые ретраи клиентов. Потом можно решить, учитывать этот кусок в базовом тренде или считать отдельным сценарием.
Если часть нагрузки идет через единый OpenAI-совместимый эндпоинт, историю проще собирать в одном месте. Это удобно, когда одна команда работает с Qwen, другая с DeepSeek, а третья временно переключилась на другую модель из-за цены или задержки. В таком потоке особенно полезен почасовой ряд: квота обычно заканчивается не "за день", а в несколько перегруженных часов.
Приведите источники к одному формату
Берите логи биллинга, gateway-логи, метрики приложений и журнал релизов, но сводите их в одну схему. Одни и те же поля должны называться одинаково во всех источниках. Если в одном месте модель записана как gpt-4.1, а в другом как openai/gpt-4.1, вы получите лишний шум и кривую агрегацию.
Минимальный набор для прогноза такой: timestamp, модель, среда, команда или продукт, входные и выходные токены, число запросов, успех или ошибка, метка особого события. Этого уже достаточно, чтобы увидеть тренд, сезонность и моменты, когда квота начала уходить быстрее обычного.
Как учесть сезонность
Одной средней за неделю здесь мало. Квоты съедают не "в среднем", а в повторяющиеся часы и даты, когда нагрузка растет почти по расписанию.
Сначала разложите историю на простые срезы: будни, выходные и официальные праздники. У многих команд это три разных режима. В B2B-сценариях трафик часто падает в субботу и воскресенье, а в клиентских продуктах вечер и праздники, наоборот, дают рост.
Потом проверьте конец месяца, квартала и года. В это время всплывают отчеты, закрытия, сверки, массовые рассылки и другие процессы, которые резко поднимают число запросов. Если вы видите, что 28-31 числа нагрузка стабильно выше на 20-40%, это уже правило, а не случайный шум.
Отдельно посмотрите на ритм внутри дня. Часто пики видны по часам: например, с 10:00 до 12:00 сотрудники активно работают с ассистентом, а после 18:00 начинается поток пользовательских обращений. Если такие окна повторяются каждую неделю, их нужно закладывать в лимиты заранее.
Полезно смотреть не только на общий объем, но и на каналы. Чат поддержки, API для внешних клиентов и внутренние batch-задачи живут в разном темпе. Если смешать их в один график, сезонность размоется, и прогноз станет слишком ровным.
Как не спутать шаблон с шумом
Повторяющийся пик обычно совпадает по дню, часу или дате несколько раз подряд. Разовый всплеск связан с конкретным событием: промо-кампанией, ошибкой в ретраях, большим импортом данных. Такие вещи лучше разводить вручную, иначе базовый спрос получится завышенным.
Небольшой пример. У ритейл-команды в будни трафик к модели держится около 1,2 млн токенов в день, а в последние три дня месяца поднимается до 1,8 млн. Если добавить к этому вечерний пик после SMS-рассылки, дневной запас квоты уже не спасает - модель упрется в лимит к ночи.
Если вы гоняете запросы через единый шлюз вроде RU LLM, считайте сезонность отдельно по модели, провайдеру и каналу. Один и тот же продукт может иметь спокойный ритм на open-weight модели в рабочие часы и острые пики на frontier-модели после внешних рассылок. Для прогноза это две разные кривые, и смешивать их не стоит.
Как учесть маркетинговые запуски
Маркетинговый запуск редко дает ровную нагрузку. Даже небольшой анонс может резко поднять поток запросов на несколько часов, а потом почти вернуть его к обычному уровню. Поэтому запуск лучше считать не как общий прирост за неделю, а как несколько коротких волн.
От маркетинга нужен простой набор данных: дата и точное время каждого касания, канал и формат, ожидаемый охват, сегмент аудитории и целевое действие. Иначе вы увидите уже сам пик, но не поймете, откуда он взялся.
Дальше считайте не клики, а реальные запросы. Между переходом по кампании и нагрузкой на модель почти всегда есть потери. Кто-то откроет страницу и уйдет. Кто-то дойдет до интерфейса, но не начнет диалог. Зато те, кто попробует сценарий, редко ограничиваются одним запросом. Обычно они делают 5-10 попыток: меняют промпт, перезапускают ответ, тестируют разные формулировки.
Простой пример: письмо ушло на 10 000 контактов, 4% кликнули, 20% из кликнувших дошли до первого сценария, средний пользователь сделал 6 запросов. Это уже 480 запросов. И приходят они неравномерно, а в первые часы после открытия письма.
Не ставьте рост только на день старта. За 2-3 дня до релиза люди видят анонсы, продавцы пишут клиентам, команда поддержки готовит материалы, кто-то получает ранний доступ. Часто это дает еще 10-20% от нагрузки дня запуска. Если сценарий связан с API, разгон бывает заметнее: разработчики начинают тесты сразу после первого упоминания.
После старта нередко приходит вторая волна. Ее дают догоняющие письма, ретаргетинг и внутренние пересылки вроде "посмотри, мы это запустили". Во многих командах она приносит еще 30-50% от первой волны через день или два.
Поэтому лучше держать запас на сценарий лучше плана. Если кампания сработает выше ожиданий, квота закончится в тот момент, когда интерес только растет. На первые 48 часов разумно заложить резерв хотя бы 25-30% и заранее решить, что делать при перегрузе: поднять лимит, временно увести часть трафика на соседнюю модель или сократить долю дорогих запросов.
Как собрать прогноз по шагам
Начните с базы, а не с пиков. Возьмите обычный рабочий день без распродаж, крупных релизов и аварий. Если трафик сильно гуляет, берите медиану за 2-4 похожие недели, а не один "удачный" день. Так прогноз не уедет вверх или вниз из-за случайного всплеска.
Дальше удобно идти по порядку.
- Разложите базовый день по часам. Сумма за сутки почти бесполезна, если нагрузка собирается в 2-3 окна.
- Добавьте поправки на день недели и час. У B2B-продуктов понедельник и вторник часто тяжелее пятницы, а у внутренних copilot-сценариев пик обычно идет в рабочее время.
- Прибавьте спрос от каждого запуска отдельно. Новый баннер на главной, рассылка, релиз функции в личном кабинете и продажа через партнеров дают разный профиль нагрузки.
- Переведите запросы в токены. Считайте отдельно входные и выходные токены: короткий вопрос с длинным ответом и длинный контекст с коротким ответом нагружают лимиты по-разному.
- Сравните итог не только с лимитом модели, но и с лимитом провайдера. Это частая ловушка: модель еще доступна, а канал к конкретному провайдеру уже упирается в потолок.
Небольшой пример. В обычный вторник модель получает 120 тысяч запросов. По истории видно, что после 12:00 трафик растет в 1,4 раза, а день релиза дает еще плюс 18%. Но дальше важно умножать не только запросы, а и средний объем токенов на запрос. Если промпт стал длиннее из-за нового system message, рост в токенах может оказаться заметно выше роста по числу вызовов.
Если вы работаете через RU LLM, полезно держать рядом две таблицы: спрос по модели и спрос по провайдеру. В одном и том же OpenAI-совместимом потоке может быть нормальный запас по модели, но слабое место у конкретного провайдера. Тогда команда меняет маршрутизацию заранее, а не ждет, пока лимит закончится посреди запуска.
Идеальным прогноз бывает редко. Но даже грубая модель быстро показывает, где хватит запаса 10%, а где лучше заложить все 40%.
Пример обычного релиза
Представим простой запуск: в мобильном приложении появляется новый чат-помощник. До релиза команда смотрит на общий трафик и думает, что запаса по квотам хватит на неделю. Ошибка в том, что общий пик почти никогда не совпадает с пиком по самой дорогой модели.
В первый день после запуска уходит письмо по старой базе. Оно возвращает часть пользователей, которые давно не заходили в приложение. Трафик растет не взрывом, а волной: утром люди открывают чат из любопытства, вечером задают более длинные вопросы. По числу запросов рост может быть умеренным, зато средняя длина диалога часто ползет вверх уже в первые часы.
На вторые сутки картина кажется спокойной. Продуктовая команда видит, что лимиты еще далеки от потолка, и выдыхает. Но именно здесь полезно смотреть не на все запросы сразу, а на разрез по маршрутам и моделям. Простые сценарии часто уходят в легкую модель, а сложные вопросы, вложения или длинный контекст тянут тяжелую.
На третьи сутки подключается партнерский канал. Новых пользователей может быть меньше, чем после письма, но их поведение часто дороже. Они приходят из внешней публикации или рассылки, сразу тестируют помощника на сложных задачах и быстрее доходят до длинных ответов. В итоге общий трафик еще не вышел на максимум, а тяжелая модель уже упирается в лимит.
Типичный сдвиг выглядит так: всего запросов стало в 1,4 раза больше, а нагрузка на тяжелую модель выросла почти в 2 раза. Причина простая - доля сложных обращений выросла быстрее, чем общий поток. Если смотреть только на сумму по API, этот момент легко пропустить.
Хорошая команда готовит запасной маршрут заранее. Еще до релиза она решает, какие сценарии можно безболезненно перевести на более дешевую или более доступную модель. Короткие вопросы, переписывание текста и простые сводки остаются на легком маршруте, а тяжелую модель держат для анализа документов и длинных диалогов.
Если трафик идет через единый OpenAI-совместимый шлюз, такой перенос проще сделать без переписывания приложения: меняется маршрутизация, а клиентский код остается тем же. Это особенно выручает в день, когда спрос растет быстрее прогноза.
Где команды ошибаются чаще всего
Ошибки в прогнозе появляются не из-за формулы, а из-за слишком грубой картины трафика. Команда видит один ровный график по дню, считает среднее и думает, что лимита хватит. Потом квота заканчивается во второй половине недели, потому что среднее скрыло пики после релиза, рассылки или удачного демо.
Средний дневной трафик вообще плохо подходит для лимитов. Если по будням у вас 1,2 млн токенов, а по вторникам и четвергам нагрузка прыгает до 1,8 млн, смотреть нужно именно на такие дни. Для планирования полезнее держать хотя бы разбивку по часам, дням недели и типам запросов.
Вторая частая ошибка связана не с числом запросов, а с длиной ответа. Команда следит за входящими токенами, но забывает, что после новой версии промпта или интерфейса модель начинает отвечать длиннее. Запросов столько же, а расход квоты уже выше на 20-40%.
Еще одна проблема - складывать все модели в одну линию. Так удобно для общего дашборда, но плохо для прогноза. Одна модель расходуется ровно, другая живет на коротких всплесках, третья включается только в сложных кейсах. Если смотреть только на общий объем, локальный перегруз по одной модели вы заметите слишком поздно.
Часто за пределами прогноза остаются внутренние источники нагрузки: автотесты перед релизом, демо для продаж и партнеров, стенды разработки и QA, evaluation-прогоны, ручные эксперименты команды. По отдельности это мелочи. Вместе они легко съедают заметную часть дневного лимита, особенно если кто-то гоняет дорогую модель в фоне.
И еще один постоянный промах: запасной маршрут включают слишком поздно. Сначала команда ждет, пока основная модель почти упрется в лимит, и только потом переключает трафик. К этому моменту уже растет очередь, ломаются SLA и начинается ручная суета. Если вы работаете через LLM-шлюз, резервный маршрут лучше проверять заранее и включать по порогу, а не после сбоя.
Нормальная практика проще, чем кажется: считать токены по каждой модели отдельно, видеть длину ответов, помечать внутренний трафик и заранее тестировать резервный путь. Тогда прогноз получается ближе к реальности, а не к красивой средней цифре.
Быстрая проверка перед запуском
За час до релиза не нужно пересчитывать всю модель спроса. Нужно быстро понять, переживут ли квоты обычный день, неделю после запуска и тот час, когда пользователи придут одновременно. Если у команды есть только средний прогноз на сутки, этого мало: квота чаще заканчивается не за день, а за 40 минут пика.
Хорошая проверка смотрит на каждую модель отдельно. Одна модель может держать обычный трафик, но просесть в пике из-за длинных ответов или всплеска retry-запросов. Поэтому запас лучше считать в токенах, а не только в числе вызовов.
Перед стартом обычно сверяют пять вещей:
- прогноз нагрузки на день, неделю и самый плотный час;
- остаток квоты по каждой модели;
- порог раннего сигнала, после которого дежурный уже вмешивается;
- календарь продуктовых и маркетинговых событий на те же даты;
- общую панель, где одновременно видны ошибки, расход токенов и остаток лимита.
Порог раннего сигнала лучше ставить заранее. Практичный вариант такой: если модель съела 50-60% дневного лимита к полудню или часовой расход ушел выше прогноза на 20-25%, дежурный получает сигнал и проверяет, что изменилось. Иначе команда узнает о проблеме слишком поздно, когда пользователи уже получают 429 или рост задержки.
Маркетинг и продукт часто ломают прогноз не со зла, а из-за разных календарей. Один запланировал рассылку на утро, другой включил новую функцию в тот же слот, и нагрузка сложилась. Пять минут на сверку перед запуском обычно полезнее, чем потом срочно резать лимиты.
Простой пример: релиз стоит на 11:00, а письмо клиентам уходит в 11:15. Если в прогнозе есть только суточное число, все выглядит спокойно. Если есть расчет на час пик, сразу видно, что одна модель выйдет в красную зону к 12:00, и команда заранее переносит часть трафика на запасной маршрут или снижает максимальную длину ответа.
Такая проверка работает только тогда, когда дежурный видит всю картину сразу. Если ошибки лежат в одном месте, токены в другом, а лимиты в третьем, реакция всегда будет запаздывать.
Что делать после первого прогноза
Первый расчет почти всегда расходится с реальным трафиком. Это нормально. Прогноз начинает работать только тогда, когда команда регулярно сверяет его с фактами и быстро правит допущения.
В спокойный период пересчитывайте прогноз раз в неделю. Этого хватает, чтобы увидеть новый рост, просадку по выходным или сдвиг в распределении запросов между моделями. Если впереди релиз, промо или большой клиентский запуск, пересчитайте отдельно именно этот период.
После каждого запуска сравнивайте план и факт в одних и тех же числах: сколько запросов ждали, сколько получили, какие модели выросли сильнее других, где пользователи начали чаще повторять запросы. Без такой сверки ошибка быстро накапливается, и через месяц цифры уже мало что значат.
Рядом с таблицей прогноза полезно вести короткий журнал: дата события, ожидаемый и фактический трафик, модели, которые ушли выше плана, причина отклонения и то, что команда поменяла после этого. Причины лучше записывать сразу. Например: "письмо по базе дало всплеск в 1,8 раза", "новый onboarding добавил длинные промпты", "часть трафика ушла на более дорогую модель из-за смены фолбэка". Через несколько недель такие заметки дают больше пользы, чем еще один красивый график.
Если команда ведет LLM-трафик через RU LLM, удобно заранее проверить маршруты, лимиты и запасные модели в одном OpenAI-совместимом контуре внутри РФ. Это особенно полезно, когда код уже завязан на привычный SDK и один эндпоинт, а нагрузка может резко сместиться между моделями и провайдерами.
Правила фолбэка тоже не стоит замораживать. Обновляйте их после каждого заметного отклонения: какие модели можно включать первыми, какие подходят только для коротких запросов, а какие лучше оставить для платящих клиентов или внутренних команд. Тогда следующий пик не сорвет лимиты в первый же день, а пройдет по сценарию, который вы уже проверили на цифрах.
Часто задаваемые вопросы
Почему квота может закончиться раньше плана, если средний трафик выглядит нормальным?
Потому что среднее за месяц скрывает пики. Квота обычно уходит в несколько перегруженных часов после релиза, рассылки или в начале рабочей недели, а не равномерно по дням.
Почему мало считать только количество запросов?
Потому что квоту съедают не сами вызовы, а токены, повторы и ошибки. Две модели с похожим числом запросов могут тратить совсем разный бюджет, если у одной длиннее промпты и ответы.
Какие метрики по моделям стоит проверять каждый день?
Смотрите по каждой модели число запросов, входные и выходные токены, долю ошибок и повторы после ошибок. Если добавить к этому разрез по продукту, каналу и региону, риск видно намного раньше.
Почему одна модель упирается в лимит, хотя общий запас еще есть?
Так бывает, когда одна модель стоит в дефолтном маршруте и забирает большую часть потока. Общий запас по всем моделям не спасает, если 60–80% запросов идут в один и тот же маршрут.
Сколько истории нужно для нормального прогноза?
Обычно хватает 8–12 недель чистой истории. Сразу отделите боевой трафик от тестов, автопрогонов, песочницы и ручных экспериментов, иначе прогноз покажет ложный рост.
Как отличить сезонность от случайного всплеска?
Ищите пики, которые повторяются в те же дни, часы или даты несколько раз подряд. Если всплеск привязан к одному письму, аварии или ретраям, считайте его отдельным событием, а не базовым спросом.
Как учесть рассылку или релиз в прогнозе?
Считайте запуск как короткие волны, а не как ровный рост за неделю. Берите время отправки, охват, сегмент и примерную конверсию в реальные сценарии, а потом переводите это в запросы и токены по часам.
Что важнее перед пиком: лимит модели или лимит провайдера?
Проверяйте оба ограничения сразу. Модель может еще иметь запас, а конкретный провайдер уже упрется в свой потолок, особенно если вы меняли маршрутизацию через шлюз.
Когда лучше включать запасной маршрут?
Не ждите 429 и длинной очереди. Если к полудню модель уже съела 50–60% дневного лимита или часовой расход ушел выше прогноза на 20–25%, переключайте часть трафика заранее.
Что делать, если первый прогноз сильно разошелся с реальностью?
Сразу сравните план и факт по одним и тем же числам: запросы, токены, модели, ошибки и повторы. Потом поправьте допущения и запишите причину отклонения, чтобы следующий расчет стал точнее, а не просто другим.