Контур для чувствительных запросов: как разделить трафик LLM
Контур для чувствительных запросов помогает отправлять PII и внутренние данные в локальные модели, а остальной LLM-трафик вести через обычный маршрут.
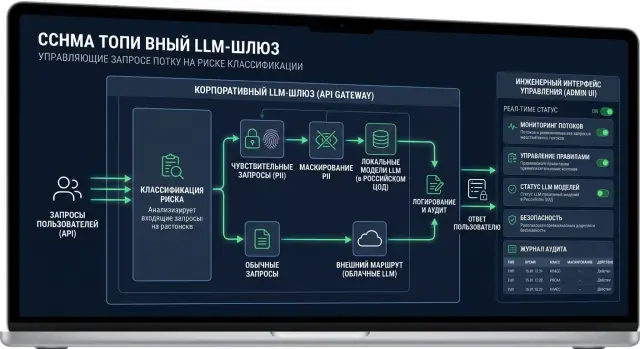
Почему один маршрут создает лишний риск
Когда все запросы идут по одному маршруту, система не различает обычные и чувствительные задачи. В один поток попадают вопросы из базы знаний, пересказ созвона, карточка клиента с ФИО и номером телефона, а иногда и внутренние документы. Для модели это просто текст. Для компании - нет.
Даже единый OpenAI-совместимый шлюз сам по себе не решает проблему. Если маршрут один, FAQ, персональные данные и служебные материалы проходят через одну и ту же политику. Настроить это легко, но в работе такой подход быстро начинает мешать.
Дальше появляется перекос. Если сделать правила строгими для всего трафика, команда упрется в лишние запреты. Сотрудник не сможет получить короткий ответ по внутренней инструкции только потому, что тот же маршрут рассчитан на обработку персональных данных. Если, наоборот, ослабить контроль ради скорости, в обычный путь попадут запросы, которые лучше держать в локальном контуре.
Один маршрут мешает и разбору инцидентов. После спорного случая все спрашивают одно и то же: почему этот запрос ушел именно туда? Если у запроса нет класса риска и отдельного правила маршрутизации, ответ обычно слабый: "так настроено по умолчанию". Для ИБ, юристов и владельца продукта этого недостаточно. Нужен понятный след решения.
Есть и более приземленная проблема - цена и задержка. Когда весь трафик идет через самый строгий контур, даже простые задачи становятся дороже. Короткий запрос вроде "суммируй новость в три пункта" не должен проходить тот же путь, что и обращение клиента с паспортными данными. Иначе вы платите за лишние проверки, а пользователь ждет дольше без причины.
Такой подход почти всегда рождает обходные привычки. Кто-то вручную вырезает чувствительные поля, кто-то отправляет часть задач в другой сервис, а кто-то вообще перестает использовать LLM там, где она могла бы экономить время. Отдельный контур нужен именно для разделения: рискованные данные идут в локальные модели, а обычные запросы - по стандартному маршруту с нормальной скоростью и понятной ценой.
Когда у запроса есть класс риска, команда может ответить на три простых вопроса: что отправили, куда отправили и почему.
Какие запросы считать чувствительными
Если текст помогает узнать человека, его деньги, внутренние процессы компании или устройство вашей системы, такой запрос лучше сразу считать чувствительным. Ошибка здесь дорогая: один "безобидный" промпт может увести в общий маршрут и персональные данные, и детали внутренней работы.
Первая группа очевидна: данные клиентов и сотрудников. Имя, телефон, почта, паспорт, СНИЛС, адрес, дата рождения, табельный номер, должность - все это требует повышенного внимания в контексте 152-ФЗ. Но список шире. Если в тексте есть сочетание признаков, по которым человека можно узнать, запрос тоже лучше отправлять в локальный контур.
Сюда же относятся платежные реквизиты и рабочие идентификаторы. Номер договора, заявки, счета, лицевого счета, карты, IBAN, внутренний customer_id - это уже не "просто техничка". По одному номеру аналитик может ничего не понять, но система, журнал или другой сотрудник легко свяжет его с конкретным клиентом или операцией.
Отдельный класс риска - живые тексты из операционных систем: заметки и карточки из CRM, тикеты поддержки и переписка с клиентом, расшифровки звонков и чатов, внутренние отчеты по кейсам, служебные инструкции с деталями процессов. Такие данные опасны не только из-за персональных данных. В них часто есть контекст бизнеса: причины блокировок, правила антифрода, исключения в процессах, внутренние формулировки для сотрудников.
Многие забывают про системные промпты. Это тоже чувствительный слой, если в них есть названия сервисов, роли агентов, внутренние маршруты, правила эскалации, стоп-слова или описания интеграций. Даже без данных клиента такой промпт раскрывает устройство вашего стека и логику принятия решений.
Простой тест работает лучше длинных споров. Если запрос отвечает хотя бы на один из двух вопросов, отправляйте его в строгий контур: можно ли по нему узнать человека или операцию, и можно ли по нему понять внутреннюю кухню компании. Например, фраза "сделай краткое резюме звонка по заявке 48173, клиент жалуется на блокировку карты" уже тянет на локальный маршрут, даже если в тексте нет ФИО.
Для таких случаев команды часто держат внешний маршрут для общего трафика, а чувствительные запросы ведут через локальные модели или через шлюз с обработкой и хранением данных в РФ. Это снимает часть риска еще до юридической проверки.
Как ввести классы риска
Классы риска нужны не для отчета, а для решения по каждому запросу: куда его отправлять, где хранить логи и какие модели вообще можно использовать. Если названия туманные, команда начнет спорить на каждом кейсе, а потом все снова сведется к одному общему маршруту.
На практике хватает трех или четырех классов. Больше обычно только мешает. Удобная схема может быть такой:
- Публичный. Нет персональных данных и коммерческой тайны, можно вести через обычный маршрут.
- Внутренний. Есть рабочая информация компании, но нет данных клиента. Нужны ограничения по логам и списку моделей.
- Персональные данные. В запросе есть ФИО, телефоны, адреса, номера договоров и похожие поля. Такой трафик лучше вести в локальный контур.
- Особо чувствительный. Платежные детали, медицинские сведения, материалы проверок, внутренние расследования. Для него обычно оставляют только локальные модели и более строгие правила логирования.
Для каждого класса сразу зафиксируйте две вещи: какие модели разрешены и где лежат логи. Иначе метка риска останется формальностью. Например, для запросов с персональными данными можно разрешить только модели в российском контуре, а логи и бэкапы хранить только в РФ. Для публичных запросов список шире, потому что риск ниже.
Кто ставит метку, зависит от вашего потока. Приложение лучше всех знает смысл операции: жалоба клиента, чат оператора, внутренняя аналитика. Шлюз хорошо ловит очевидные признаки вроде номера паспорта или телефона. Отдельный фильтр полезен там, где много сервисов и нужна единая проверка. Рабочая схема для продакшена обычно такая: приложение ставит исходный класс, шлюз проверяет его и может только повысить риск или отклонить запрос.
Отдельно пропишите правило для неизвестного класса. Угадывать нельзя. Если сервис прислал пустую или новую метку, запрос должен уйти в самый строгий маршрут или не уйти вовсе. В первые недели это раздражает, но потом спасает от тихих ошибок.
Еще один полезный шаг - собрать 10-15 спорных примеров и прогнать их вместе с командой. Запрос "сделай краткую выжимку по 500 обращениям" может быть безопасным, если данные уже обезличены. А фраза "подготовь ответ клиенту Ивану Петрову, его номер договора 4512" уже требует другого класса. После таких разборов правила перестают быть абстрактными, и маршрутизация начинает работать одинаково у разработки, ИБ и владельцев продукта.
Какие модели держать в локальном контуре
Для локального контура обычно хватает не набора из десяти моделей, а одной основной и одной резервной. Так проще держать качество под контролем, считать нагрузку и быстро разбирать сбои. Если моделей слишком много, команда тратит время не на защиту данных, а на постоянный выбор между почти одинаковыми вариантами.
Для запросов с персональными данными и внутренними документами лучше выделить одну-две модели, которые вы уже проверили на своих задачах. Одна может лучше справляться с извлечением фактов из анкет, заявлений и обращений. Вторая нужна как запасной маршрут, если выросла очередь, сломался провайдер или основная модель просела по качеству после обновления.
Общие бенчмарки полезны только как черновой фильтр. Они не отвечают на вопрос, как модель поведет себя на реальных письмах клиентов, сканах договоров, фрагментах CRM или служебных регламентах. Если банк выбирает модель для локального контура, ему важнее проверить точность обезличивания, аккуратность суммаризации и стабильность ответов на типовых внутренних шаблонах, чем смотреть на чужой рейтинг по математике или кодингу.
Сравнивайте модели по нескольким простым критериям: качество на ваших примерах, задержка на коротких и длинных запросах, длина контекста для договоров и переписки, стоимость тысячи запросов и поведение под нагрузкой, когда одновременно приходят десятки или сотни задач.
Не отправляйте в локальный контур все подряд. Это частая ошибка. Локальные модели нужны там, где есть реальный риск: ФИО, телефоны, паспортные данные, медицинские сведения, служебные документы, внутренние комментарии сотрудников. Обычные задачи без чувствительных данных, например черновой рерайтинг маркетингового текста или классификация открытых отзывов, можно оставить на общем маршруте. Так вы не перегрузите локальные GPU и не раздуете бюджет.
Отдельно считайте запас мощности. Средняя нагрузка почти никогда не показывает реальную картину. Смотрите на пики: конец рабочего дня, массовые загрузки документов, сезонные кампании, отчетные периоды. Если локальный контур нужен для обязательных по политике компании запросов, он должен пережить и скачок трафика, и отказ одного узла. Здесь помогает простая схема: основная локальная модель, резервная локальная модель и жесткое правило, какие задачи можно временно поставить в очередь, а какие нельзя задерживать.
Если вы строите такой маршрут через RU LLM, удобно сначала сузить выбор до пары open-weight моделей, уже доступных на российской GPU-инфраструктуре, а потом прогнать их на своем наборе кейсов. После этого решение обычно становится проще: одна модель идет в основной контур, вторая остается резервом.
Как построить маршрут по шагам
Маршрут лучше собирать до первого токена. Если рискованный запрос уже ушел во внешний канал, исправлять поздно.
Обычно это делают в шлюзе перед вызовом модели. Туда попадает сам текст, файлы, системный промпт, имя пользователя, канал, продуктовый сценарий и другие метаданные. Этого достаточно, чтобы принять решение без сложной магии.
Базовая цепочка
Рабочая схема выглядит так:
- Шлюз принимает запрос и не отправляет его дальше, пока не проверит риск. Проверка должна идти раньше ретраев, кэша и выбора модели.
- Классификатор ищет признаки риска. Он смотрит на текст, вложения и метаданные: паспортные шаблоны, номера договоров, медицинские термины, внутренние теги вроде
customer_supportилиvip_client, источник запроса из CRM или бэк-офиса. - Система ставит класс и пишет причину. Нужна не только метка
strictилиstandard, но и короткое объяснение:contains_pii,bank_statement_pdf,source=hr_portal. - Шлюз выбирает маршрут. Строгие классы идут в локальные модели, обычные - по внешнему маршруту, где выше выбор моделей или ниже цена.
- Шлюз сохраняет решение в аудит и маскирует PII в логах. Потом команда видит, почему запрос попал в локальный контур, но не читает сырые персональные данные.
Такой порядок дает предсказуемость. Когда правила лежат в одном месте, команда не спорит, почему один и тот же запрос вчера ушел наружу, а сегодня нет.
Хорошая практика - разделить детектор и маршрутизатор. Детектор отвечает только за класс риска, а маршрутизатор выбирает модель, лимиты, policy и способ логирования. Так изменения проще тестировать.
Для банка пример простой. Клиент пишет: "Объясни, почему мне отказали по заявке 45821", и прикладывает выписку. Даже если сам текст короткий, файл и номер заявки поднимают риск. Шлюз ставит строгий класс, отправляет запрос в локальную модель и сохраняет в аудите причину выбора.
Если вы используете шлюз вроде RU LLM, удобно держать это в одной точке: там уже есть аудит-трейлы, маскирование PII и локальные модели в РФ. Но логика маршрута все равно должна быть вашей. Именно вы решаете, какие сигналы переводят запрос из обычного потока в строгий.
Где держать правила маршрутизации
Место для правил зависит от стадии проекта. На пилоте проще начать в приложении. Команда быстро меняет условия, смотрит логику на реальных запросах и не ждет изменений в общей инфраструктуре.
Но такой подход живет недолго. Как только LLM начинают использовать два-три сервиса, копии одной и той же логики расходятся. Один сервис отправляет запрос с ФИО в локальную модель, другой по ошибке ведет его во внешний маршрут, а третий вообще проверяет только часть полей.
Для общего правила на все сервисы удобнее LLM-шлюз. Там один вход для трафика, значит и политика одна: этот класс запросов идет в локальный контур, этот - в обычный. Если команда уже работает через единый шлюз вроде RU LLM, такое правило проще внедрить централизованно, чем править каждый сервис отдельно.
Оркестратор нужен, когда одной развилки мало. Если перед маршрутом вы хотите добавить DLP-проверку, кэш, резервный путь и журнал причин выбора модели, отдельный слой оркестрации часто удобнее. Он держит не только правило "куда отправить", но и весь путь запроса: проверку, обогащение, повтор, откат.
Обычно хватает простого разделения: временные правила пилота живут в приложении, общие правила для всех команд - в шлюзе, а сложная логика с DLP, кэшем и fallback - в оркестраторе.
Главное - не раскладывать одну и ту же логику по всем трем слоям. Иначе никто не понимает, почему запрос ушел не туда. Если правило уже живет в шлюзе, приложение не должно дублировать его своими условиями, кроме редких локальных исключений.
Еще одна практичная мера - назначить владельца правил. Не "платформенную команду вообще", а конкретную роль: ML platform lead, архитектора или владельца LLM-платформы. У правил должен быть срок пересмотра. Например, раз в квартал команда проверяет, не изменились ли классы риска, состав данных и список локальных моделей.
Если этого не сделать, контур для чувствительных запросов быстро превращается в набор старых исключений. Формально маршрут есть, а по факту никто уже не помнит, зачем он устроен именно так.
Простой сценарий для банка
В банке такой маршрут должен работать незаметно для сотрудника. Оператор открывает одну форму, вставляет обращение клиента и получает ответ там же. Он не думает про контуры, модели и правила. Это делает шлюз.
Допустим, клиент пишет: "Алексей Смирнов, договор 48152, не понимаю, почему вырос платеж". В тексте есть ФИО и номер договора. Система сразу видит эти признаки, ставит запросу строгий класс риска и отправляет его в локальную модель, которая работает внутри российского контура.
Для оператора ничего не меняется. Он так же задает вопрос и ждет подсказку для ответа клиенту. Но строгий контур уже сработал: текст не ушел во внешний маршрут, а разбор выполнила локальная модель с нужными правилами хранения логов и аудита.
Теперь другой случай. Оператор спрашивает: "Как объяснить клиенту разницу между аннуитетным и дифференцированным платежом?" Персональных данных тут нет. Система помечает такой запрос как обычный и ведет его по стандартному маршруту, где можно выбрать более сильную или более дешевую модель без жестких ограничений.
В этом и смысл схемы: сотрудник не выбирает маршрут вручную. Ручной выбор почти всегда ломается под нагрузкой. Кто-то забудет переключить режим, кто-то ошибется, кто-то просто решит сэкономить время. Автоматическая маршрутизация по классам риска убирает этот риск из повседневной работы.
Для банка важен не только сам ответ, но и след. Аудит должен сохранять, что именно произошло с каждым запросом: какой класс риска присвоила система, какую модель она выбрала, по какому правилу сработал маршрут, кто отправил запрос и когда.
Если банк использует шлюз вроде RU LLM, такой журнал удобно держать рядом с самим маршрутом. Тогда команда видит не просто ответ модели, а полную цепочку решения. Для 152-ФЗ это часто важнее, чем несколько лишних процентов качества на части запросов.
Где команды чаще ошибаются
Проблемы обычно начинаются не в модели, а в правилах. Команда собирает контур для чувствительных запросов, но потом настраивает его слишком грубо и сама создает лишние расходы, задержки и слепые зоны.
Самая частая ошибка проста: почти любой запрос помечают как чувствительный. На старте так спокойнее, но через неделю локальный контур забивается обычными задачами, а бюджет уходит на то, что не требовало строгой изоляции. Если сотрудник просит "сделай краткое резюме встречи без имен клиентов", такой запрос не равен выгрузке анкеты с паспортными данными.
Вторая ошибка выглядит аккуратно, но часто ломается на практике: поиск PII только по регулярным выражениям. Регулярки находят телефон или email в явном виде, но плохо ловят свободный текст, сканы, таблицы, куски CRM-выгрузок и фразы вроде "клиент из Казани с договором на 12 млн". Риск часто сидит в контексте, а не в одном шаблоне.
Еще одна типичная проблема в том, что команды смотрят только на поле user_message. Утечки приходят и из других мест: вложений и OCR-текста, системных промптов, RAG-фрагментов из базы знаний, истории диалога, метаданных, которые шлюз пишет в логи.
Есть и более опасный промах: резервный маршрут во внешнюю модель без новой проверки. Схема выглядит безобидно. Локальная модель не ответила вовремя, оркестратор отправил тот же пакет наружу, чтобы не держать пользователя. Если перед этим никто заново не прогнал классификацию и маскирование, вся защита оказалась декоративной.
Такой сбой особенно неприятен в банке или телекоме. Команда честно держит локальные модели для персональных данных, но fallback уходит во внешний маршрут, потому что его когда-то включили "на всякий случай". Потом аудит показывает, что чувствительные поля ушли не из основного контура, а через аварийный путь.
Еще одна частая ошибка связана с порядком обработки. Маскирование должно сработать до записи логов, трейсов и бэкапов. Если система сначала сохранила сырой запрос, а потом заменила поля звездочками, утечка уже произошла. В шлюзе вроде RU LLM это стоит проверить отдельно: где именно включаются маскирование PII, AI-Law метки и аудит-трейлы, и что из этого попадает в хранилище первым.
Хорошее правило простое: проверяйте не только основной маршрут, но и все обходные пути. Обычно ошибка прячется именно там.
Быстрые проверки перед запуском
Перед первым включением лучше ловить не сложные баги, а простые разрывы в логике. Обычно они всплывают не в модели, а на стыке сервисов, правил маршрута и журналов.
Если у вас есть контур для чувствительных запросов, проверьте не только сам роутинг, но и то, что происходит вокруг него. Один неверный флаг в API, одна пустая метка риска, и запрос с персональными данными уходит не туда.
Полезно пройтись по короткому списку:
- Каждый сервис либо передает метку риска явно, либо отправляет достаточно полей для ее расчета.
- Локальная модель проверена на реальных примерах, а не на удобных демо-запросах.
- Неизвестный класс, пустая метка или сбой классификатора отправляют запрос в безопасный маршрут, а не наружу.
- Логи, бэкапы и аудит не уносят следы обработки во внешний storage.
- Дежурная команда может взять один тестовый запрос и объяснить его путь по журналу без догадок.
На практике полезно сделать пять-десять контрольных запросов с заранее известным результатом. Например: запрос без персональных данных, запрос с ФИО и телефоном, запрос с паспортными полями, запрос с пустой меткой риска, запрос с ошибкой в классификаторе. Такой набор быстро показывает, где правила расходятся с ожиданиями.
Если вы строите схему через OpenAI-совместимый шлюз, вроде RU LLM, проверьте и служебные данные по каждому вызову: audit trail, AI-Law метки, место хранения логов. Для команд под 152-ФЗ это обычная часть приемки.
Хороший признак готовности простой: инженер на дежурстве может открыть журнал любого спорного запроса и за пару минут объяснить весь маршрут.
Что делать дальше
Не пытайтесь сразу перестроить весь трафик. Контур для чувствительных запросов лучше запускать на одном процессе, где риск понятен, а эффект легко посчитать. Часто для пилота берут обращения в поддержку, разбор писем клиентов или внутренний поиск по документам с персональными данными.
Хороший старт выглядит просто:
- Соберите небольшой набор реальных запросов и разметьте их по классам риска вручную.
- Прогоните этот набор через правила маршрутизации и посмотрите, где система ошибается.
- Отправляйте высокий риск в локальные модели, а обычные запросы - по стандартному маршруту.
- Сравните задержку, стоимость и долю запросов, которые ушли не туда.
Смотрите не только на общую точность. По каждому классу риска отдельно считайте ложные срабатывания и пропуски. Ложные срабатывания делают локальный контур дороже и медленнее, а пропуски опаснее: в этом случае чувствительный запрос может уйти во внешний маршрут.
Если пилот работает стабильно, не держите правила в пяти местах сразу: в коде сервиса, в промптах, в настройках прокси и в ручных исключениях. Перенесите маршрутизацию по классам риска в единый OpenAI-совместимый шлюз. Так проще менять правила, смотреть логи и понимать, почему конкретный запрос попал в тот или иной контур.
Для команд, которым нужен контур в РФ, такой слой удобно собирать на базе RU LLM. Платформа дает один OpenAI-совместимый эндпоинт, аудит-трейлы, маскирование PII и локальные open-weight модели в российских ЦОДах. Это практичный вариант, если требования по 152-ФЗ уже нужно выполнять в продакшене.
Дальше помогает обычная дисциплина, а не сложная схема. Раз в месяц пересматривайте классы риска, список признаков, выбранные модели и цену каждого маршрута. За это время меняются формы заявок, шаблоны документов и даже стиль запросов пользователей, и старая логика быстро начинает промахиваться.
Если сомневаетесь, упрощайте. Три ясных класса риска почти всегда лучше, чем десять спорных. Когда пилот дает мало пропусков и понятную стоимость, его можно расширять на соседние процессы.
Часто задаваемые вопросы
Зачем вообще делить трафик LLM на обычный и чувствительный?
Чтобы не гнать все запросы через один и тот же путь. Обычные задачи вроде краткого пересказа можно обрабатывать быстро и дешевле, а запросы с ФИО, номерами договоров, выписками и внутренними инструкциями лучше сразу вести в локальный контур.
Так у команды остается понятный ответ на три вопроса: что отправили, куда отправили и почему.
Какие запросы стоит сразу отправлять в локальный контур?
Сразу относите к чувствительным персональные данные, платежные реквизиты, номера договоров и заявок, тексты из CRM, тикеты поддержки, расшифровки звонков и внутренние документы.
Туда же попадают системные промпты и служебные правила, если по ним можно понять, как устроены ваши сервисы и процессы.
Хватит ли регулярных выражений, чтобы находить чувствительные данные?
Нет, одних регулярных выражений мало. Они ловят телефон или email в явном виде, но часто пропускают свободный текст, вложения, OCR, куски CRM и сочетания признаков, по которым человека все равно можно узнать.
Лучше совмещать шаблоны, метаданные источника и проверку контекста запроса.
Сколько классов риска обычно достаточно?
В большинстве команд хватает трех или четырех классов. Часто используют схему «публичный», «внутренний», «персональные данные» и «особо чувствительный».
Если классов слишком много, сотрудники начинают спорить о метках, а маршрут снова сводится к одному общему правилу.
Кто должен присваивать запросу класс риска?
Лучше всего, когда приложение ставит исходную метку, потому что оно знает смысл операции, а шлюз проверяет ее и может только поднять риск или отклонить запрос.
Такая схема снижает число промахов и не дает сервису по ошибке занизить класс.
Что делать, если сервис не смог определить класс риска?
Не угадывайте. Пустую или новую метку отправляйте в самый строгий маршрут либо блокируйте запрос до разбирательства.
Первые дни это раздражает, зато потом не возникает тихих утечек из-за неизвестных значений.
Сколько моделей нужно держать в локальном контуре?
Обычно достаточно одной основной модели и одной резервной. Этого хватает, чтобы держать качество, считать нагрузку и спокойно переживать сбои.
Выбирайте их по своим примерам: письма клиентов, договоры, CRM-фрагменты, внутренние регламенты. Чужие рейтинги тут помогают слабо.
Где лучше хранить правила маршрутизации?
На пилоте правила можно оставить в приложении, но для нескольких сервисов их лучше вынести в единый шлюз. Тогда политика будет одной для всех, а аудит станет проще.
Если у вас сложный путь с DLP, кэшем и аварийными сценариями, отдельный слой оркестрации тоже имеет смысл. Главное — не дублировать одну и ту же логику везде сразу.
Как настроить fallback, чтобы он не уводил чувствительные данные наружу?
Резервный путь должен проходить ту же проверку риска, что и основной. Если локальная модель не ответила, нельзя просто переслать тот же пакет во внешний маршрут без новой классификации и маскирования.
Иначе аварийный сценарий сам станет точкой утечки.
Как быстро проверить схему перед запуском?
Прогоните через систему несколько контрольных запросов с заранее понятным исходом: обычный текст, запрос с ФИО и телефоном, запрос с номером договора, пустую метку риска и ошибку классификатора.
После этого откройте журнал каждого кейса и проверьте, видна ли причина выбора маршрута, где лежат логи и сработало ли маскирование до записи. Если вы строите схему через RU LLM, проверьте audit trail, AI-Law метки и хранение данных в РФ.