Реестр потоков персональных данных для LLM-функций
реестр потоков персональных данных помогает связать формы, API, логи и бэкапы для LLM-функций в одном документе, понятном ИБ, юристам и разработке.
Почему схемы по отделам не работают
Когда каждый отдел описывает только свой кусок процесса, общая картина распадается. Для LLM-функций это особенно опасно: одни и те же персональные данные проходят через форму, API, логи, очереди, мониторинг и резервные копии, а в документах эти части часто живут отдельно.
Юристы обычно фиксируют цель обработки, текст согласия и правовое основание. Это нужно, но этого мало. Если в описании нет логов, трассировок ошибок и копий, документ не отвечает на простой вопрос: где именно остались данные пользователя после отправки запроса.
ИБ чаще смотрит на интеграции, доступы и сетевые точки. На схеме есть API, шлюз, провайдер, хранилище. Но без состава полей такая схема почти слепая. Endpoint виден, а то, что в поле "сообщение" пользователь мог оставить телефон, адрес или номер договора, к потоку не привязано.
Разработка тоже добавляет свой разрыв. Команда описывает сервис, базу и pipeline, но резервные копии нередко живут в другой таблице, у другой команды или в настройках инфраструктуры. В итоге прод-сервис формально описан, а его ночная копия как будто не относится к обработке ПДн.
До первого вопроса от аудита такая схема кажется удобной. Потом сразу всплывают пробелы: форма есть, но поля не связаны с конкретным API-запросом; API описан, но логи не привязаны к полям; сервис описан, но бэкапы и срок хранения вынесены отдельно; никто не может быстро показать полный маршрут одного набора ПДн.
На практике это выглядит просто. Клиент пишет в чат личного кабинета, указывает имя и номер телефона, а система отправляет текст в LLM-функцию. Если компания использует единый API-шлюз, запрос проходит через приложение, прокси, audit trail и хранилище логов. Когда эти части описывали разные люди в разных документах, команда тратит дни на ответ, который должен лежать в одном месте.
Поэтому реестр потоков персональных данных лучше строить не по отделам, а по фактическому движению данных. Тогда юристы, ИБ и разработка смотрят на один маршрут, а не спорят о разных фрагментах одной системы.
Что считать потоком в LLM-функции
Поток в LLM-функции - это не только момент, когда пользователь отправил текст в модель. Он начинается там, где данные впервые появились, и продолжается в каждой точке, где система их читает, копирует, хранит, маскирует, удаляет или передает дальше.
Для реестра удобно считать потоком любой переход между двумя узлами. Пользователь ввел текст в форму, чат принял сообщение, backend собрал запрос, API-шлюз переслал его в модель, сервис записал событие в лог, а потом backup-система забрала копию базы. Это не один абстрактный процесс, а цепочка отдельных движений данных.
Источник входа тоже бывает разным. Это может быть форма в личном кабинете, чат с оператором или ботом, карточка клиента в CRM, загруженный файл или данные, которые backend подтягивает из другой системы.
Дальше многие команды видят только вызов модели и пропускают остальное. Это ошибка. Если запрос ушел через API-шлюз, этот переход надо фиксировать отдельно. Если команда использует шлюз вроде RU LLM, в схеме стоит показать и сам шлюз, и выбранную модель: у них разные роли в обработке.
Поток не заканчивается после ответа модели. Почти всегда остаются следы: access-логи, application logs, трассировка запросов, метрики, очереди ретраев, кэш промптов и ответов. Даже если там хранится только часть текста или технический идентификатор, это все равно нужно проверить и описать.
Есть и тихие каналы, про которые вспоминают слишком поздно. Это ручные выгрузки в Excel, пересылка диалога в поддержку, дампы для отладки, резервные копии, тестовые стенды с копией продовых данных. Для юристов и ИБ это такие же потоки, как основной API-вызов.
Отдельно фиксируйте действия, которые меняют жизненный цикл данных. Маскирование PII перед отправкой, удаление диалога по запросу пользователя, очистка кэша, перенос записи в архив - это тоже часть потока. Если процесс обрывается на полпути, в реестре должна остаться понятная картина: что пришло, куда ушло, где сохранилось и кто может это потом увидеть.
Хорошее правило простое: если инженер может нарисовать стрелку между двумя системами или состояниями данных, эту стрелку стоит проверить для реестра.
Какие поля нужны в записи реестра
В реестре одна запись должна описывать не сервис целиком, а один понятный маршрут данных. Если пользователь оставляет запрос в форме, а затем текст уходит в API, попадает в логи и в резервные копии, это нужно собрать в одну связную карточку. Тогда безопасники, юристы и разработчики смотрят на один и тот же объект, а не на четыре разных документа.
Сначала зафиксируйте источник данных и точку сбора. Источник отвечает на вопрос, откуда пришли данные: форма в личном кабинете, чат на сайте, мобильное приложение, оператор колл-центра, CRM. Точка сбора показывает, где система впервые принимает эти данные: веб-форма, API-шлюз, SDK в приложении, почтовый ящик, интеграция с внешней системой.
Минимальный набор полей
В каждой записи полезно держать один и тот же набор граф:
- источник и точка сбора
- состав данных
- цель обработки
- получатели данных
- место и срок хранения
Состав данных лучше писать по полям, а не общими словами вроде "контактные данные". Намного понятнее выглядит запись, где отдельно указаны имя, телефон, email, текст запроса и вложения. Если LLM-функция принимает свободный текст, так и напишите: пользователь может сам вставить в него паспортные данные, номер договора, адрес или другую чувствительную информацию.
Цель обработки тоже нужна в явном виде. Например: ответ на обращение пользователя, классификация заявки, подготовка черновика ответа, поиск по базе знаний. Рядом укажите получателей данных: внутренняя команда поддержки, внешний LLM-провайдер, DLP-система, хранилище логов, подрядчик по резервному копированию. Если получателей несколько, лучше перечислить каждого, чем писать "внутренние и внешние системы".
Место хранения и срок хранения часто теряют, хотя именно на них чаще всего смотрят юристы и ИБ. Запишите, где лежат исходные сообщения, где лежат логи запросов, где хранятся вложения и куда уходят резервные копии. Для каждой точки укажите свой срок: 30 дней для технических логов, 1 год для обращений, 14 дней для временных файлов, по политике бэкапов для копий.
Отдельной строкой зафиксируйте меры защиты. Обычно здесь нужны три вещи: маскирование PII, запрет на логирование чувствительных полей и способ удаления. Например, команда может маскировать телефон и email до отправки в модель, отключать запись полного prompt в application logs и удалять обращение по идентификатору сразу из рабочей базы, логов и очереди на backup.
Если используете RU LLM, укажите его как отдельную точку маршрута. Тогда описание не обрывается на вызове модели, а включает путь данных до логов, аудита и хранения внутри РФ.
Как связать форму, API, логи и резервные копии
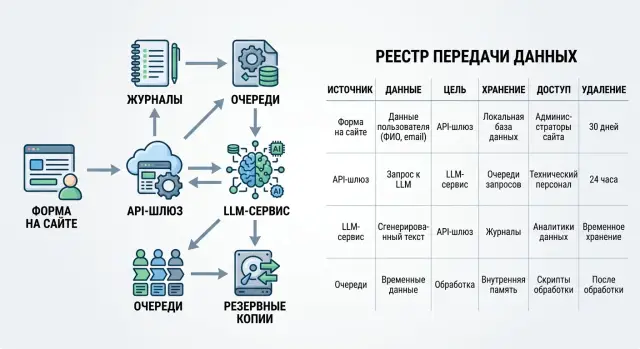
Реестр начинает работать только тогда, когда вы описываете не системы по отдельности, а один пользовательский запрос целиком. Для LLM-функции это обычно одна цепочка: поле формы, backend, LLM API, прикладной лог, системный лог, архив и резервная копия. Если разорвать эту цепочку, безопасность видит одно, юристы другое, а разработчики ищут данные вручную.
Начните с общего идентификатора запроса. Присвойте его в момент отправки формы или на входе в API и протащите через все узлы: HTTP-запрос, очередь, вызов модели, логи приложения, аудит, экспорт и запись о бэкапе. Если команда использует LLM-шлюз, полезно хранить связку из внешнего request_id и внутреннего audit id. Тогда одну операцию можно собрать без догадок.
Сам путь лучше описывать как короткую последовательность шагов. Пользователь вводит текст в форме и нажимает отправку. Backend принимает поля, добавляет user_id, account_id, IP, session_id или номер заявки. Сервис отправляет промпт и метаданные в LLM API с тем же request_id. Приложение пишет результат в боевую базу и в операционный лог. Ночью система копирует базу и логи в архив или резервную копию.
В реестре покажите не только сам путь, но и места, где состав данных меняется. Часто backend чистит текст, маскирует телефон, добавляет атрибут клиента, считает риск-метку или пишет ответ модели рядом с исходным сообщением. Это уже новая версия набора данных, и ее нужно отметить отдельно. То же относится к выгрузкам для поддержки, датасетам для evaluation, prompt cache и отладочным дампам. Если копия существует дольше пары часов, лучше считать ее самостоятельной записью, а не прятать в строку "технические логи".
Боевой трафик, тестовые данные и стенды разведите явно. У них разные источники, сроки хранения и круг доступа. Самая частая путаница возникает, когда разработчик берет реальный запрос из продакшена, кладет его в staging и забывает про это в реестре. Для таких сред заведите отдельные идентификаторы потоков и сразу укажите, какие данные там запрещены, какие разрешены только после маскирования и попадают ли они в резервные копии.
Если запись сделана аккуратно, по одному request_id команда за минуту покажет, что пользователь ввел в форму, что ушло в API, что осталось в логах и в какой резервной копии это еще лежит.
Как собрать реестр по шагам
Если пытаться описать сразу весь контур, команда быстро утонет в деталях. Начните с одной LLM-функции. Подойдет самый понятный сценарий: чат-форма в личном кабинете, автосводка обращения или классификация входящего текста.
Дальше берите не схему из презентации, а один живой запрос. Отправьте тестовое сообщение и пройдите его путь руками: что пользователь ввел, что фронтенд отправил, что принял backend, что ушло во внешний или внутренний LLM-сервис, что попало в логи, очередь, мониторинг и резервные копии. Такой проход обычно вскрывает то, чего нет ни в одном согласованном документе.
Рабочий порядок простой. Сначала выберите один сценарий и зафиксируйте его границы: от точки ввода до удаления или архивирования данных. Потом прогоните один запрос с понятными маркерами, чтобы легко найти его в логах и таблицах. После этого запишите каждый переход: форма, API, gateway, модель, ответ, логи, очереди, хранилища, бэкапы. И только затем подключайте владельцев по пути потока: продукт отвечает за смысл функции, DevOps знает инфраструктуру, ИБ видит контроль доступа, юристы проверяют правовые основания и сроки хранения.
На этом этапе почти всегда выясняется, что данные живут дольше, чем казалось. Команда часто помнит про основную базу, но забывает про error-логи, трассировку, дампы очередей, S3-архивы или копии в тестовой среде. Если запросы к моделям идут через RU LLM, в схему стоит сразу добавить audit trail, маскирование PII, место хранения логов и бэкапов в РФ. Иначе юристы увидят одну картину, а инженеры другую.
Проверка тоже простая: дайте запись человеку, который не строил эту схему, и попросите ответить на пять вопросов. Где вводятся ПДн? Куда они уходят дальше? Кто имеет доступ? Как долго они хранятся? Где именно их удаляют? Если на любой вопрос приходится гадать, реестр еще сырой.
Первый вариант не бывает идеальным. Но если он собран по одному реальному запросу и подтвержден логами, с ним уже можно работать и для безопасности, и для 152-ФЗ.
Пример для чат-формы в личном кабинете
Пользователь открывает чат в личном кабинете и пишет: "Хочу вернуть заказ, не подошел размер". Форма отправляет три поля: текст сообщения, номер заказа и email, чтобы система нашла покупку и связала обращение с аккаунтом.
В реестр такой случай лучше вносить не одной строкой "чат поддержки", а как связанную цепочку. Тогда служба безопасности и юристы видят не абстрактный процесс, а точные переходы данных между формой, API, логом и резервной копией.
Как выглядит цепочка
Форма в личном кабинете передает сообщение, номер заказа и email в backend поддержки. Цель простая: принять запрос на возврат и найти нужный заказ.
Дальше backend отправляет запрос в API-шлюз для LLM. На этом шаге шлюз может добавить служебные метки: request_id, tenant_id, время запроса, признак маскирования PII, метку для аудита.
Затем шлюз передает данные в модель. Полный email модели нужен не всегда, поэтому его часто маскируют или убирают совсем, если для ответа хватает текста обращения и номера заказа.
После этого лог сохраняет статус ответа, код ошибки при сбое, выбранную модель, время обработки и маршрут запроса. Затем резервная копия забирает журнал по своему расписанию, чтобы команда могла восстановить данные после инцидента.
В реестре запись по форме и запись по логу не должны сливаться в одну. У них разная цель, разный срок хранения и разный круг доступа. Оператор поддержки может видеть текст обращения, номер заказа и email, потому что он решает вопрос клиента. Модель может получать только текст и часть атрибутов заказа, если этого хватает для ответа. Инженер эксплуатации обычно видит только технический лог: статус, время, идентификатор запроса, иногда имя модели. Администратор резервного копирования видит копию журнала, но ему не нужен доступ к самой форме.
Если команда использует OpenAI-совместимый шлюз вроде RU LLM, в описании потока полезно отдельно отметить, где включается маскирование PII, где хранятся логи и бэкапы и какие audit trails появляются на каждом запросе. Для 152-ФЗ такой разрез полезнее, чем схема "чат -> ИИ" одним блоком. По нему сразу видно, где персональные данные нужны для работы, а где их лучше не передавать вовсе.
Где чаще ошибаются
Самая частая ошибка проста: команда описывает только прод и забывает все, что живет рядом. Песочницы, staging, prompt playground, тестовые формы, отладочные endpoint'ы и временные интеграции часто получают те же данные, что и боевая схема. Для юристов и безопасности это не мелочь, а такой же поток ПДн с отдельным маршрутом, доступами и сроком хранения.
Не меньше путаницы возникает, когда в одной записи смешивают пользовательский текст и техметки. Текст сообщения может содержать ФИО, телефон, адрес или детали заказа. Техметки обычно включают user_id, session_id, IP, request_id, модель, токены, время запроса и признак ошибки. Эти данные живут по-разному: текст чаще маскируют и удаляют раньше, а техлоги иногда держат дольше для разбора сбоев. Если свалить все в одно поле "данные запроса", реестр быстро теряет смысл.
Еще один частый промах - слишком общее описание маршрута. Фраза "передача в LLM" ничего не объясняет. Нужно назвать конкретный сервис: API-шлюз, внешний провайдер, собственный inference-сервис, лог-pipeline, хранилище бэкапов. Если команда работает через прокси вроде RU LLM, в записи стоит указать сам шлюз, а затем следующий узел маршрута, если он есть. Иначе невозможно понять, где именно лежат логи, кто видит запрос и какой договор закрывает этот участок.
Плохая запись реестра обычно узнается быстро. В ней указан только основной API, но нет staging и тестовых стендов. В одном поле смешаны текст пользователя и служебные идентификаторы. Вместо названий сервисов стоит общая формулировка вроде "LLM" или "внешняя модель". Не описаны выгрузки в поддержку, CSV для разбора инцидентов и ручные отчеты. Срок хранения остался старым, хотя команда включила новое логирование или трассировку.
С выгрузками в поддержку ошибаются даже аккуратные команды. Они честно описывают форму, API и основные логи, но забывают про Excel-файл, который аналитик раз в неделю отправляет в саппорт, или про ручной отчет для разбора жалобы. С точки зрения потока данных это не разовая операция, а отдельный канал доступа.
Есть и еще одна неприятная мелочь: логирование меняют часто, а реестр почти никогда. В январе хранили только request_id, в марте добавили сырой prompt для дебага, а срок хранения остался прежним. После такого реестр формально есть, но он уже не совпадает с системой. Для проверки хватает одного вопроса: "Что именно мы начали писать, куда и на сколько дней?" Если ответ ищут по чатам, запись пора переписать.
Короткая проверка перед релизом
Перед релизом не пытайтесь допридумать реестр на ходу. Откройте одну запись и пройдите путь данных глазами человека, который не писал код. Если чат-форма принимает телефон и текст обращения, вы должны увидеть, где эти поля появились, куда ушли и где остались после обработки.
Здесь хватает короткой проверки:
- у каждого поля есть источник
- у каждой копии есть срок хранения
- у каждого участка пути есть владелец
- для каждой точки видно, что происходит с ПДн
- юрист и ИБ понимают запись без устных пояснений
Чаще всего команды честно описывают основную обработку и забывают про копии. Поле "email" может жить не только в таблице заявок, но и в access log, в трассировке ошибки, в дампе очереди и в резервной копии за прошлую неделю. Если срок хранения указан только для базы, запись еще не готова.
С владельцами та же история. Если в реестре написано просто "backend" или "DevOps", это почти бесполезно. Нужна роль или команда, к которой можно прийти с вопросом: кто меняет маскирование, кто чистит старые архивы, кто отключает ручную выгрузку.
Отдельно проверьте ручные действия. Они ломают аккуратные схемы чаще кода. Поддержка скачала CSV, аналитик выгрузил диалог, разработчик включил расширенный лог на время отладки - и у вас уже новый поток, которого нет в записи.
Хороший тест простой: дайте запись юристу и специалисту по ИБ, ничего не объясняйте и молча подождите их вопросы. Если они спрашивают, откуда взялось поле, где хранится копия или кто отвечает за удаление, реестр надо дописать до релиза.
Что делать после первой версии реестра
Первая версия редко бывает полной. Это нормально. Гораздо хуже ждать идеальную схему и месяцами не фиксировать реальные потоки данных.
После первой версии реестр лучше сразу перевести в рабочий режим. Начните с двух-трех функций, через которые проходит самый большой трафик или самые чувствительные данные. Обычно это чат в личном кабинете, форма обращения в поддержку и внутренний API, который отправляет запросы в модель.
Такой старт дает живую картину. Команда быстро видит, где данные входят в систему, что уходит в LLM, какие логи остаются, кто их читает и когда резервные копии удаляют. На этом этапе не нужно описывать все подряд.
Полезнее держать шаблон записи рядом с релизным процессом. Если команда добавляет новую LLM-функцию, меняет промпт, включает логирование или подключает другого провайдера, запись в реестре обновляют в тот же цикл. Иначе документ стареет уже через неделю, а юристы и безопасность начинают работать с разными версиями реальности.
Практика обычно сводится к нескольким простым действиям: назначить владельца записи для каждой функции, добавить проверку реестра в чеклист релиза, пересматривать запись после смены модели, провайдера, маршрута запроса или состава логов и хотя бы раз в месяц сверять реестр с тем, что реально настроено в коде и инфраструктуре.
Отдельно смотрите на изменения, которые часто считают чисто техническими и не вносят в описание потоков ПДн. Например, команда оставила тот же интерфейс формы, но перевела запросы на другого провайдера модели. Для пользователя ничего не изменилось. Для комплаенса изменилось многое: новый получатель, другой маршрут, другой срок хранения логов и, возможно, другой контур резервного копирования.
Если вы используете RU LLM, это стоит зафиксировать прямо в записи: единый OpenAI-совместимый endpoint, через который идет вызов моделей, хранение логов и бэкапов в РФ и audit trail по каждому запросу. Такой узел в схеме заметно упрощает разговор между разработкой, ИБ и юристами: все смотрят на одну точку входа, а не собирают картину по нескольким подрядчикам и сервисам.
Хороший реестр живет вместе с продуктом. Если после релиза изменилась модель, провайдер или состав логов, запись нужно менять в тот же день. Иначе через пару месяцев документ вроде бы есть, но пользы от него почти нет.
Часто задаваемые вопросы
Почему нельзя вести реестр по отделам?
Потому что данные идут не по оргструктуре, а по системам. Если юристы описали согласие, ИБ — интеграции, а разработка — сервисы, никто не видит полный путь одного сообщения от формы до логов и бэкапов.
Что в LLM-функции считать отдельным потоком данных?
Считайте потоком каждый переход данных между двумя точками. Форма, backend, API-шлюз, модель, логи, очереди, кэш, архив и резервная копия — это части одной цепочки, если через них проходит один запрос.
Какие поля нужны в записи реестра?
Начните с пяти полей: источник, состав данных, цель обработки, получатели, место и срок хранения. Потом добавьте меры защиты, владельца и точки удаления, чтобы команда сразу понимала, кто что хранит и кто это чистит.
Как связать форму, API, логи и бэкапы в одной записи?
Возьмите один запрос и дайте ему общий request_id на входе. Потом протяните этот идентификатор через backend, LLM API, логи приложения, аудит и резервные копии, чтобы по одной записи быстро собрать весь маршрут.
Как описывать свободный текст, если в нем могут быть ПДн?
Не пишите просто «текст обращения». Лучше сразу указать, что пользователь может вставить в сообщение телефон, адрес, номер договора или другие чувствительные данные. Тогда команда не забудет про маскирование, логирование и сроки удаления.
Нужно ли включать staging и тестовые стенды в реестр?
Да, и лучше развести их явно. У staging, песочницы и playground часто другой круг доступа, другой срок хранения и свой риск, особенно если разработчик переносит туда реальные запросы из продакшена.
Почему нельзя смешивать форму, логи и техметки в одну сущность?
Лог и форма редко живут по одним правилам. Оператору нужен текст обращения и email, а инженеру эксплуатации обычно хватает статуса, времени, request_id и имени модели. Если смешать это в одну запись, реестр быстро теряет смысл.
Зачем отдельно указывать API-шлюз вроде RU LLM?
Если вы гоняете запросы через RU LLM, покажите его как отдельный узел маршрута. Так вы фиксируете не только вызов модели, но и путь через единый OpenAI-совместимый endpoint, audit trail, маскирование PII и хранение логов и бэкапов внутри РФ.
Как быстро проверить реестр перед релизом?
Дайте запись человеку, который не писал код, и попросите ответить на пять простых вопросов: откуда пришли ПДн, куда они ушли, кто их видит, сколько они лежат и где их удаляют. Если человек начинает гадать, запись еще сырая.
Что делать с реестром после первой версии?
Обновляйте запись в тот же цикл, когда команда меняет модель, провайдера, маршрут запроса или состав логов. Иначе документ живет своей жизнью, а безопасность и юристы смотрят уже не на систему, а на старую схему.