Стоимость LLM в продакшене: как считать без сюрпризов
Стоимость LLM в продакшене складывается не только из токенов. Покажем, как учесть ретраи, длинный контекст, eval, кэш и поддержку.
Почему цены за токены недостаточно
Цена входных и выходных токенов дает только грубую оценку. В продакшене один ответ почти никогда не равен одному вызову модели. В счет попадают системный промпт, история диалога, служебные инструкции, формат вывода, а иногда еще поиск по базе знаний, проверка ответа и повторный запрос.
Из-за этого один и тот же сценарий на бумаге и в реальной системе стоит по-разному. Пользователь задает вопрос в поддержку, и снаружи это выглядит как один ответ. Но внутри система может сначала достать документы, собрать длинный контекст, попросить модель вернуть JSON, проверить схему и сделать ретрай, если формат сломался. Для бюджета это уже не один вызов, а цепочка действий.
Сильнее всего раздувают счет мелкие, но частые расходы: ретраи после таймаутов, 429 и сетевых сбоев, лишние токены из-за длинной истории и повторяющихся инструкций, кэш-промахи из-за пары измененных строк и отдельные вызовы на модерацию, классификацию или суммаризацию.
Поэтому смотреть только на тариф модели опасно. Дешевая модель с длинным контекстом и частыми повторами иногда обходится дороже, чем более дорогая модель, которая решает задачу с первой попытки и в меньшем числе токенов.
Считать лучше не цену модели, а цену функции. Не "сколько стоит миллион токенов", а "сколько стоит закрыть один тикет", "проверить один документ" или "сгенерировать один отчет". Такой подход быстро показывает, где вы платите за полезный результат, а где просто сжигаете токены на служебные шаги.
Это особенно заметно в схемах с маршрутизацией через единый API. Простой шаг можно отдать дешевой модели, а дорогую оставить для сложного. Тогда экономика видна сразу, а не после первого крупного счета.
Из чего складывается полный чек
Когда считают стоимость LLM в продакшене, обычно смотрят на цену входных и выходных токенов. Это только видимая часть счета. Реальные расходы растут из-за всего, что окружает один ответ модели.
Даже базовый запрос почти всегда больше, чем кажется. В него входят не только слова пользователя, но и системный промпт, служебные инструкции, формат ответа, история диалога и фрагменты из базы знаний. Пользователь мог написать 200 токенов, а в модель уйдет 2 000.
С выходом та же история. Если вы просите краткий ответ, а модель регулярно пишет по 700-900 токенов, переплата быстро накапливается. На большом трафике разница между "коротко" и "подробно" превращается в заметную строку бюджета.
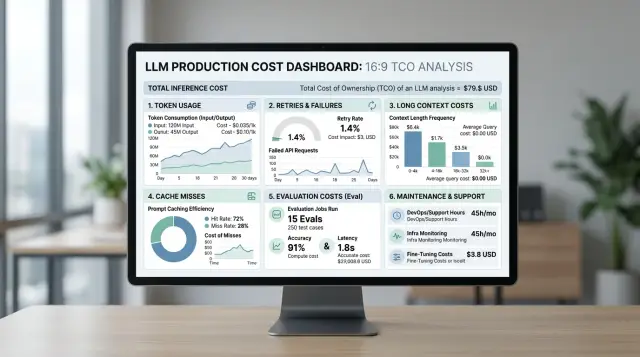
Полный чек обычно состоит из четырех слоев. Первый - все входные токены, включая системный промпт и служебный текст. Второй - выходные токены, даже если часть ответа потом не показывают пользователю. Третий - повторные запросы, если первая попытка упала, зависла или не прошла проверку. Четвертый - все, что идет рядом с инференсом: eval, хранение логов, ручная проверка спорных ответов и время команды.
Повторные вызовы часто недооценивают. Если один и тот же запрос сначала ушел в основную модель, потом в fallback, а затем еще раз после таймаута, вы уже заплатили не за один ответ, а за два или три. Для маршрутизации это нормально, но в расчете это надо считать как отдельные вызовы.
Есть и менее заметные траты. Логи занимают место, eval гоняет тестовые наборы, сотрудники поддержки разбирают жалобы, инженеры следят за лимитами, качеством и отказами. Если команда раз в неделю тратит 5-6 часов на разбор инцидентов и корректировку промптов, это тоже часть стоимости.
Простой пример: бот поддержки отвечает на 10 000 обращений в день. Сами токены могут дать только половину расходов, если добавить ретраи, длинный системный промпт, контроль качества и дежурства команды. Поэтому считать нужно не цену модели, а цену одного полезного ответа, который дошел до пользователя без ошибки.
Длинный контекст быстро раздувает бюджет
Длинный контекст ломает расчет раньше, чем сама модель. При каждом новом запросе вы обычно отправляете не только последний вопрос, но и часть прошлой переписки, системные инструкции и служебные данные. Поэтому цена растет не по прямой, а скачками.
Если в начале чата было 1 500 входных токенов, то через 10-15 сообщений легко набирается 8 000-12 000. И вы платите за это снова и снова. Один лишний абзац кажется мелочью, но в длинном диалоге он умножается на каждый следующий вызов.
В поддержке это видно особенно хорошо. Первый вопрос клиента стоит дешево. Потом в запрос начинают ехать приветствие, уточнения, старая версия ответа, правила тона, политика возврата, куски CRM и весь хвост истории. Даже если модель уже поняла суть, вход продолжает пухнуть.
История чата полезна не всегда. После нескольких ходов старые реплики часто уже не влияют на ответ. Приветствия, подтверждения, закрытые темы, повторы и промежуточные формулировки только занимают место. Если модель каждый раз читает этот мусор, стоимость LLM в продакшене растет без пользы.
То же самое происходит с повторяющимися инструкциями. Команды часто на каждом запросе заново приклеивают длинный system prompt, правила безопасности, формат ответа и одинаковые справочники. Лучше держать только короткие постоянные правила, а остальное подмешивать по ситуации.
На практике помогают четыре вещи: сжимать старую часть диалога в короткое резюме, хранить отдельно факты и ограничения, передавать только релевантные фрагменты базы знаний и удалять закрытые ветки разговора. Резать контекст лучше по смыслу, а не просто по последним сообщениям. Иначе легко оставить свежую, но пустую болтовню и потерять важное условие из начала диалога.
Ретраи и сбои стоят дороже, чем кажется
Счет растет не только из-за цены токенов. Его часто раздувают повторные запросы, таймауты и запасные маршруты, которые команда включила "на всякий случай" и потом перестала замечать.
Ретрай обычно запускают четыре вещи: ошибки 429 и 5xx, долгий ответ модели, обрыв сети и невалидный результат, который приложение не может разобрать. Если у вас строгий JSON-формат или tool calling, один сбой парсинга легко превращается в еще один полный запрос.
Один лишний ретрай редко бывает дешевым. Если запрос уже ушел в модель, вы часто платите хотя бы за входные токены, а иногда и за часть вывода. Допустим, промпт весит 12 000 токенов, ответ - 800. Первый вызов завис на 18-й секунде, приложение не дождалось и отправило второй. Для бюджета это уже почти две операции вместо одной.
Для расчета удобно держать четыре числа: базовую стоимость одного запроса, среднее число ретраев на 100 запросов, долю таймаутов, после которых срабатывает fallback, и долю параллельных попыток.
Таймауты и fallback лучше считать отдельно. Если система ждет 20 секунд, а потом переключает запрос на другую модель, вы можете заплатить дважды: за неуспешную первую попытку и за успешную вторую. При маршрутизации через нескольких провайдеров это особенно важно, потому что у запасного маршрута тариф часто отличается от основного.
Параллельные попытки бьют по бюджету еще сильнее. Команда запускает сразу две модели, чтобы снизить задержку, а потом берет ответ той, что пришла первой. Для SLA это удобно, но деньги уже ушли в обе стороны, особенно если отмена второй попытки срабатывает поздно.
Если считать расходы честно, добавьте к цене токенов коэффициент надежности. Даже 2-3% ретраев на большом трафике быстро съедают месячный запас, а 1% параллельных запросов иногда обходится дороже, чем вся оптимизация промпта.
Кэш промптов не спасает сам по себе
Кэш снижает расход там, где запросы действительно повторяются. Обычно это длинный system prompt, общие инструкции по стилю ответа, типовые правила безопасности и большие фрагменты контекста, которые многие пользователи получают почти в одном виде. В саппорте база знаний и шаблон ответа часто дают заметную экономию на входных токенах.
Проблема в том, что в продакшене совпадений меньше, чем кажется на демо. Один и тот же запрос быстро перестает быть одинаковым: вы добавили имя клиента, текущую дату, ID сессии, порядок документов из поиска, новый tool call или лишний служебный блок. Для провайдера это уже другой prompt, и кэш не срабатывает.
Часто кэш ломают сами команды. Чуть поменяли шаблон, вставили новый абзац в системную инструкцию, начали A/B-тест, подняли версию промпта с v12 до v13, и hit rate падает. Даже мелкие правки в разметке и разделителях могут превратить повторяющийся трафик в поток промахов.
Хорошая практика простая: держать стабильную часть prompt отдельно и менять ее редко. Все, что зависит от пользователя, времени и запроса, лучше выносить в переменные блоки. Так проще понять, где кэш действительно работает, а где экономия существует только в таблице.
Какие метрики смотреть
Не смотрите только на общий hit rate. Он легко обманывает, если у вас смешаны разные сценарии. Полезнее разложить картину по шаблонам, моделям и маршрутам, отдельно измерять долю входных токенов, которые реально пришли из кэша, и считать среднюю экономию в рублях на 1 000 запросов. Еще стоит смотреть latency для hit и miss по отдельности и проверять, как меняется hit rate после каждой правки шаблона.
Если у вас единый шлюз для нескольких провайдеров, эти цифры удобно сравнивать по маршрутам. Тогда видно, где длинный контекст стоит дешевле, а где кэш почти не дает эффекта.
Eval, мониторинг и поддержка тоже стоят денег
Цена запроса не заканчивается на токенах. Как только LLM попадает в продакшен, команда начинает платить за то, чтобы ответы оставались приемлемыми после каждого релиза, смены модели и правки промпта.
Первый слой расходов - автоматические проверки. После релиза никто не хочет узнавать о поломке из жалобы клиента, поэтому команды прогоняют тестовые диалоги, сравнивают ответы с эталоном, проверяют формат JSON, длину ответа, частоту отказов и долю опасных ответов. Даже если один прогон стоит недорого, при частых выкладках сумма растет быстро.
Второй слой - ручная разметка. Автотесты ловят не все. Спорные ответы обычно смотрят люди: аналитик, саппорт, иногда продукт. Если в неделю приходит хотя бы 300 сомнительных диалогов, а на один уходит 2-3 минуты, это уже часы оплачиваемой работы.
Третий слой - мониторинг и инциденты. Когда модель начинает чаще ошибаться, уходить в длинные ответы или ломать формат, кто-то получает алерт, идет в логи и разбирает причину. Потом команда правит промпт или роутинг и еще раз прогоняет регрессию. Ночная дежурная смена стоит дороже любого красивого графика в отчете.
На практике бюджет чаще всего утекает в четыре места: nightly и post-release eval, ручную проверку спорных кейсов, алерты и разбор инцидентов, а также время на правки промптов и повторные регрессии.
Простой пример: вы обновили системный промпт в поддержке клиентов. Токены почти не изменились, зато выросла доля ответов, которые нужно перечитывать вручную. Через неделю команда тратит 10 часов на разбор кейсов и еще 6 часов на новую серию тестов. Формально модель не подорожала. По факту стоимость системы выросла.
Подробные логи и аудит-трейлы помогают считать такие расходы точнее, но сами часы команды никуда не исчезают. Поэтому в бюджет сразу стоит закладывать не только инференс, но и постоянную проверку качества.
Как считать стоимость по шагам
Считать стоимость LLM в продакшене лучше не от цены за миллион токенов, а от цены одного успешного действия. Действие должно быть понятным бизнесу: закрытый тикет, готовый ответ клиенту, заполненная карточка товара или проверенный документ.
Если взять только средний расход токенов, цифра почти всегда получится слишком красивой. Реальный бюджет съедают длинные запросы, повторы, промахи кэша и время команды, которое редко попадает в первый расчет.
Рабочий порядок простой.
- Выберите один сценарий. Не "поддержка клиентов вообще", а, например, "ответ на входящий вопрос без перевода на оператора".
- Замерьте не только средний запрос, но и p95 по входу, выходу и длине истории. Именно хвост часто и раздувает счет.
- Добавьте операционные потери: долю ретраев, fallback на более дорогую модель, кэш-промахи, модерацию и повторные вызовы после таймаута.
- Посчитайте постоянные расходы рядом с инференсом: eval, мониторинг, алерты, разбор инцидентов, часы ML-инженера и разработчика.
- Разделите общий месячный расход на число успешных действий. Так вы получите честную цену, с которой можно идти к бизнесу.
Небольшой пример. Допустим, бот поддержки делает 100 000 ответов в месяц. Средний запрос стоит 0,7 рубля, но p95 уже тянет на 2,1 рубля. Если 8% запросов уходят в ретрай, 12% - в fallback, а кэш срабатывает хуже, чем ожидалось, фактическая цена ответа легко растет до 1,1-1,3 рубля еще до учета команды.
Потом добавьте то, что обычно забывают: ежемесячные eval-прогоны, хранение логов, дежурство по инцидентам, обновление промптов и разметку плохих ответов. Даже 20-30 часов команды в месяц могут заметно поднять расчет затрат на LLM, если трафик пока не очень большой.
Если вы используете шлюз с маршрутизацией по нескольким провайдерам, расходы нужно считать по фактическому распределению трафика. Иначе модель бюджета получится слишком гладкой и мало полезной.
Пример расчета для поддержки клиентов
Допустим, одно обращение в поддержку превращается в диалог на 8 сообщений. До пятого сообщения контекст еще короткий. Потом история переписки начинает давить на бюджет: модель получает почти весь прошлый диалог заново, и входные токены растут быстрее, чем кажется.
Сообщения 1-5 дают 5 200 входных токенов и 900 выходных. Сообщения 6-8 - уже 9 000 входных и 700 выходных. Итого на один диалог получается 14 200 входных и 1 600 выходных токенов. При цене 0,6 руб. за 1 000 входных и 1,8 руб. за 1 000 выходных базовая стоимость диалога равна 11,4 руб.
Теперь добавим ретраи. Если 3% запросов уходят на повтор, средняя прибавка составит еще 0,34 руб. на диалог.
Остается fallback. Пусть в 10% обращений система отправляет последний шаг на запасную модель, потому что первая не уложилась в лимит, дала слабый ответ или вернула ошибку. Один такой дополнительный шаг стоит 3,75 руб., значит fallback добавляет в среднем 0,38 руб. на каждое обращение.
Дальше идет eval. Команда раз в неделю берет выборку из 100 диалогов, прогоняет ее через автооценку и вручную смотрит спорные ответы. Допустим, на модели уходит 250 руб., а на работу аналитика и инженера - еще 4 000 руб. Если за неделю приходит 1 000 обращений, такой eval добавляет 4,25 руб. на одно обращение.
Получаем честный средний расчет:
11,4 + 0,34 + 0,38 + 4,25 = 16,37 руб. на один диалог.
На 1 000 обращений это уже 16 370 руб. И это без учета крупных инцидентов, ручной правки промптов и времени команды на разбор жалоб. Поэтому стоимость LLM в продакшене почти всегда выше, чем просто цена токенов из прайса.
Частые ошибки в расчетах
Бюджет чаще всего ломает не цена модели, а слишком оптимистичная таблица. Команда берет средний запрос, умножает его на число обращений и получает аккуратную цифру. В продакшене это почти всегда заниженная оценка.
Среднее значение само по себе мало что говорит. Один короткий вопрос может стоить копейки, а длинный диалог с историей сообщений, проверкой формата и повторной генерацией съедает цену десятков обычных запросов. Поэтому смотрите не только на среднее, но и на верхние хвосты: хотя бы p95 по входным токенам, выходу и числу попыток.
Еще одна частая ошибка - считать только текст пользователя и финальный ответ. В счет входят системный промпт, служебные инструкции, история диалога, JSON-схемы, tool calls и другие служебные токены. На коротких задачах эта часть иногда больше самого вопроса.
Многие считают стоимость только по успешным ответам и забывают про все попытки до успеха. Это сильно искажает расчет. Если запрос ушел в ретрай, модель вернула невалидный JSON или оркестратор переключил провайдера, каждая попытка стоит денег. Полезно держать две метрики: стоимость одной попытки и стоимость успешного ответа.
Отдельная путаница возникает, когда в одну корзину складывают разный трафик: боевые запросы пользователей, ручные тесты команды, автоматические eval-прогоны, нагрузочные и регрессионные проверки. Если смешать все вместе, средняя цифра станет красивой, но бесполезной. Боевой трафик нужен для финансового плана, а тестовый - для бюджета разработки и контроля качества.
И последняя ошибка встречается постоянно: расчет сделали один раз и больше не пересматривают. После роста нагрузки меняется почти все - длина контекста, доля кэш-промахов, число ретраев, требования к мониторингу и поддержке. Если вы меняете модель, системный промпт или схему маршрутизации, пересчитывайте расходы заново. Иначе сюрпризы появятся уже после запуска.
Быстрая проверка перед запуском
Перед запуском полезно сделать короткую сверку на одной странице. Она часто ловит дыры в бюджете лучше, чем длинная таблица с тарифами.
Проверьте пять вещей. Во-первых, считайте не цену запроса, а цену успешного ответа. В нее входят повторные вызовы, модерация, fallback на более дорогую модель и все токены, которые ушли в неудачные попытки. Во-вторых, отдельно оцените долю длинных диалогов. Даже если их всего 10-15%, они могут съесть заметную часть месячного бюджета. В-третьих, зафиксируйте реальный hit rate кэша, а не ожидаемый. Разница между 60% и 25% очень быстро превращается в лишние счета. В-четвертых, задайте жесткий лимит на ретраи и fallback, иначе редкие сбои провайдера начнут тянуть деньги и задержку сразу в двух местах. В-пятых, сразу заложите время команды на поддержку: кто смотрит алерты, разбирает жалобы, правит промпты и проверяет деградацию качества.
Есть и простой стресс-тест: возьмите 1 000 типовых диалогов и посчитайте три сценария - обычный день, день со всплеском длинных сессий и день с ростом ошибок у провайдера. Если сумма заметно меняется, значит модель затрат еще хрупкая.
Для команд с российскими требованиями к данным есть еще один практический вопрос: где живут логи, трассировка и аудит. Если не учесть это заранее, позже появятся отдельные расходы на интеграцию, хранение и контроль доступа.
Что делать дальше
После расчета не оставляйте цифры в заметках. Перенесите их в простой калькулятор в таблице или BI-системе и назначьте человека, который отвечает за обновление. Иначе стоимость LLM в продакшене снова начнет плыть уже через пару недель.
Хороший базовый шаблон обычно включает один ряд на каждый сценарий: чат поддержки, классификацию, поиск по базе знаний, внутреннего ассистента. Для каждого сценария полезно считать средний вход, средний выход, длину контекста, долю ретраев, hit rate кэша, цену eval, часы поддержки и запас на пиковую нагрузку. Даже такая грубая модель быстро показывает, где деньги уходят не в токены, а в побочные издержки.
Дальше нужны метрики, которые команда видит постоянно: токены по сценариям и моделям, средняя длина контекста и p95, hit rate кэша по типам запросов, доля ошибок, таймаутов и ретраев, а также факт против плана по расходам за неделю и месяц.
Раз в месяц сверяйте план и факт. Если расхождение больше 10-15%, обычно причина довольно приземленная: изменился промпт, вырос контекст, сломался кэш, появилась лишняя повторная генерация или команда добавила более дорогую модель в fallback.
Если вам нужен единый OpenAI-совместимый эндпоинт в РФ, можно отдельно проверить, как маршрутизация влияет на реальную цену сценария. Например, RU LLM дает один совместимый API для разных провайдеров и моделей, а команды могут сохранить свои SDK, код и промпты без переделки. Для части компаний это еще и вопрос учета, рублевого B2B-биллинга и хранения логов внутри РФ.
Нормальный следующий шаг очень простой: собрать первую версию калькулятора за один день, подключить метрики и через месяц проверить, где прогноз ошибся сильнее всего.
Часто задаваемые вопросы
Почему нельзя смотреть только на цену токенов?
Потому что вы платите не только за текст пользователя и финальный ответ. В счет обычно входят system prompt, история диалога, служебные инструкции, формат JSON, поиск по базе знаний, проверки и повторные запросы после ошибок.
Поэтому считайте не цену миллиона токенов, а цену одного полезного результата: закрытого тикета, проверки документа или готового отчета.
Что считать за единицу стоимости в продакшене?
Берите одно понятное действие и считайте полный путь до успеха. Например, не "запрос к модели", а "ответ клиенту без перевода на оператора".
Потом сложите средние и p95 по входу и выходу, ретраи, fallback, кэш-промахи, eval, мониторинг и часы команды. После этого разделите общий расход на число успешных действий.
Правда ли, что длинный контекст сильнее всего раздувает бюджет?
Да, и очень быстро. Каждый новый запрос часто тащит за собой старые сообщения, системные правила и служебные блоки, поэтому вход растет от шага к шагу.
Если чат длинный, вы много раз платите за один и тот же хвост. Сжимайте старую часть диалога в резюме и передавайте только то, что реально влияет на ответ.
Какие сбои чаще всего делают LLM дороже?
Чаще всего деньги утекают из-за 429 и 5xx, таймаутов, сетевых сбоев и ответов, которые приложение не может разобрать. Если вы ждете строгий JSON или tool calling, один сбой легко превращает один запрос в два.
Смотрите не только долю ошибок, но и среднее число попыток на 100 запросов. Даже 2-3% ретраев на большом трафике дают заметную прибавку к месячному счету.
Как правильно учитывать fallback на другую модель?
Fallback считайте отдельно от базового запроса. Если первая модель не ответила вовремя или дала слабый результат, вы можете заплатить и за первую попытку, и за запасную.
Лучше сразу знать долю таких переключений и среднюю цену дополнительного шага. Иначе бюджет выглядит аккуратно только в таблице, а не в реальном трафике.
Поможет ли кэш промптов заметно снизить расходы?
Нет, сам по себе не спасает. Кэш работает там, где у вас много одинаковых или почти одинаковых частей prompt, но в продакшене совпадения быстро ломают имя клиента, дата, ID сессии, порядок документов и мелкие правки шаблона.
Держите стабильную часть отдельно и меняйте ее редко. А еще смотрите не только hit rate, но и сколько рублей кэш реально экономит на 1 000 запросов.
Какие метрики смотреть вместо среднего расхода?
Смотрите не только среднее, но и p95 по входным токенам, выходу и числу попыток. Именно хвосты часто и ломают расчет, потому что длинные диалоги и повторные вызовы стоят намного дороже обычных.
Полезно отдельно мерить стоимость одной попытки и стоимость успешного ответа. Так вы сразу видите, где расход дает сама задача, а где его дают сбои и оркестрация.
Нужно ли включать в расчет eval, мониторинг и ручную проверку?
Да, и нередко это крупная часть бюджета. После каждого релиза команда гоняет тестовые наборы, смотрит спорные ответы, чинит промпты, разбирает алерты и инциденты.
Если трафик пока небольшой, даже 20-30 часов в месяц могут сильно поднять цену одного успешного действия. Поэтому закладывайте эти часы в расчет сразу, а не после запуска.
Как быстро проверить бюджет перед запуском?
Начните с 1 000 типовых диалогов и посчитайте три режима: обычный день, день с длинными сессиями и день со всплеском ошибок у провайдера. Если сумма сильно скачет, модель затрат еще сырая.
Перед запуском полезно зафиксировать лимит на ретраи и fallback, реальный hit rate кэша и долю длинных диалогов. Это ловит дыры в бюджете лучше, чем общий тариф по модели.
Когда единый шлюз и маршрутизация реально экономят деньги?
Маршрутизация помогает, когда вы даете простые шаги дешевой модели, а сложные оставляете более сильной. Так вы платите за результат точнее и не тратите дорогую модель на все подряд.
Если у вас один OpenAI-совместимый эндпоинт и логи живут внутри РФ, команде проще сравнивать маршруты, вести учет и не менять SDK, код и промпты при переключении между провайдерами.