Зависимость от одного провайдера LLM: как убрать без переделок
Зависимость от одного провайдера LLM мешает быстро менять модели. Покажем слой совместимости, единый мониторинг и общий учет расходов.
Где появляется привязка к одному провайдеру
Привязка начинается не в момент выбора модели, а раньше - когда команда пишет первый рабочий вызов и потом копирует его по всей системе. Сначала это удобно: один SDK, одна схема авторизации, один формат ответа. Через пару месяцев этот код уже живет в API, фоновых задачах, внутренних ботах и админке.
Потом выясняется неприятная вещь. Вы хотите сменить модель из-за цены, качества или доступности, а менять нужно не одну настройку, а десятки мест в коде. У одного сервиса свой клиент, у другого свои ретраи, у третьего отдельная обвязка под стриминг.
Частая ошибка - вписать имя модели прямо в бизнес-логику. Например: "если запрос дорогой, отправь его в gpt-4.1" или "если клиент VIP, включи Claude". С виду это мелочь. На деле название модели быстро прорастает в фичефлаги, тесты, документацию и продуктовые правила. Когда поставщик меняется, ломаются не только интеграции, но и сама логика продукта.
Проблему усиливают различия между провайдерами. Один возвращает понятные коды ошибок, другой прячет все в текст. Один режет запрос по токенам, другой по RPM или TPM. Один стабильно держит стриминг, у другого он периодически обрывается. Один отдает подробный usage, другой почти ничего не показывает.
Если приложение принимает эти различия как есть, пользователи начинают видеть чужие технические детали. Вместо нормального сообщения они получают сырую ошибку провайдера, таймаут без объяснения или странный отказ на длинный ввод. Для команды это еще хуже: поддержка не понимает, где сломалось, а разработчики ищут причину сразу в нескольких кабинетах.
Отдельная боль - наблюдаемость и деньги. Логи лежат в одном месте, лимиты в другом, счета в третьем. В компаниях, где важны аудит и контроль расходов, это быстро становится проблемой. Сложно понять, какой сервис вызвал модель, сколько стоил запрос и почему он ушел именно к этому провайдеру. Когда команд несколько, общий учет расходов обычно разваливается первым.
Обычно привязка уже есть, если модель упоминается в коде по имени, каждый сервис сам ходит в LLM API, ошибки наружу проходят без нормализации, а расходы собирают вручную по разным отчетам. Это не редкий крайний случай. Так выглядит большинство первых внедрений, которые делали быстро.
Что вынести в отдельный слой
Если приложение знает имена реальных моделей, правила ретраев, цены и токены доступа, зависимость возникает почти сразу. Чтобы убрать ее, сервис должен видеть не поставщика, а стабильный внутренний интерфейс.
Сначала зафиксируйте единый контракт запросов и ответов. Для бизнес-логики это обычный вызов: текст на входе, параметры генерации, структурированный ответ, usage и коды ошибок в одном формате. Тогда сервису все равно, пришел ответ от GPT-подобной модели, Qwen или любой другой модели.
Следом вынесите алиасы. Не пишите в коде gpt-4.1 или deepseek-v3.2 там, где живет продуктовая логика. Намного проще использовать имена вроде default_chat, cheap_draft, long_context, strict_json. Тогда вы меняете привязку алиаса в конфиге, а не выпускаете новый релиз. Разница очень практичная: смена модели занимает минуты, а не спринт.
Отдельно вынесите поведение при сбоях. Ретраи, таймауты, фолбэки и правила переключения между моделями не должны жить внутри каждого сервиса. Если один сервис повторяет запрос два раза, второй три, а третий молча уходит на запасную модель, контроль теряется очень быстро. Такие правила лучше держать в шлюзе или общей прослойке.
В этом слое обычно хватает пяти вещей: единого формата запроса и ответа, алиасов вместо реальных названий моделей, общих правил ретраев и таймаутов, нормализованного учета токенов и стоимости, а также отдельного хранения секретов и прав доступа.
Usage тоже стоит привести к одной схеме сразу. Один провайдер возвращает prompt tokens и completion tokens, другой добавляет cached tokens, третий считает стоимость по своему правилу. Если все это нормализовать в одно событие, мониторинг, биллинг и аналитика начинают говорить на одном языке. Финансы видят расходы по сервисам и командам, а инженеры не спорят, чьи цифры правильные.
Секреты и доступы лучше держать вне приложения. Сервису не нужен набор ключей от разных провайдеров. Ему нужен один способ авторизации к общей точке входа. Если команда работает через OpenAI-совместимый шлюз, она часто может просто поменять base_url и оставить SDK, код и промпты без серьезных правок. У RU LLM эта схема как раз на это и рассчитана: приложение ходит в единый эндпоинт, а маршрутизация, биллинг и требования к хранению данных остаются в инфраструктурном слое.
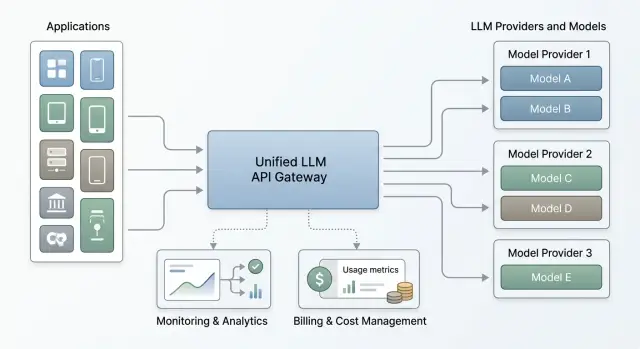
Как выглядит схема без переписывания кода
Проблема обычно начинается не с модели, а с того, что приложение знает слишком много о чужом API. Нормальная схема устроена иначе: приложение отправляет все запросы в один внутренний endpoint и всегда получает один формат ответа.
Между приложением и внешними моделями стоит шлюз. Он решает, куда отправить конкретный запрос, исходя из цены, задержки, доступности, требований к хранению данных или типа задачи. Если сегодня для суммаризации подходит одна модель, а завтра другая, правило меняют в шлюзе, а не в коде продукта.
Внутри такой схемы есть несколько простых ролей. Приложение вызывает единый LLM API и не знает, какой провайдер ответит на запрос. Шлюз применяет правила маршрутизации и при сбое может переключить трафик на другой источник. Адаптеры приводят параметры к общему виду: temperature, max_tokens, system prompt, tools, JSON output. Слой наблюдаемости собирает ошибки, задержку и расход токенов в один поток. Финансовый слой считает стоимость каждого запроса и привязывает ее к сервису, команде или клиенту.
На практике это выглядит просто. Продуктовый сервис просит: "дай краткое резюме диалога". Он не выбирает модель вручную и не хранит у себя тарифы провайдеров. Все это делает шлюз по своим правилам.
Если команда уже сидит на OpenAI-совместимом SDK, переход часто сводится к смене точки входа. Это и есть хороший признак: модель меняется, а бизнес-логика, мониторинг и биллинг остаются на месте.
Единый поток метрик нужен не для красоты. Без него быстро начинается хаос: в одном месте считают токены, в другом следят за ошибками, в третьем пытаются понять, почему вырос счет. Когда события собираются на уровне каждого запроса, команда видит полную картину: какой сервис вызвал модель, сколько занял ответ, сколько стоил запрос и какой маршрут сработал.
Хорошая схема дает очень приземленный результат. Допустим, support-бот работал на дорогой модели, а потом команда нашла вариант дешевле с тем же качеством. Достаточно поменять правило в шлюзе, проверить метрики и продолжить работу без релиза приложения, без переделки мониторинга и без новой логики биллинга.
Как внедрить это по шагам
Начните с карты всех вызовов LLM. Ищите не только основной бэкенд, но и фоновые задачи, CRM-скрипты, внутренние боты, ETL-процессы и тестовые стенды. Часто один старый сервис продолжает ходить напрямую к провайдеру и ломает всю идею единого слоя.
Дальше лучше идти постепенно.
Сначала замените прямые имена моделей на алиасы. Вместо gpt-4o и других точных названий используйте что-то вроде summary_model, support_model, ocr_check_model. Бизнес-логика должна знать задачу, а не конкретную модель.
Потом поставьте перед текущим провайдером слой совместимости. Если у вас уже OpenAI-совместимый SDK, часто достаточно сменить base_url на единый шлюз. Это дает быстрый эффект: клиентская часть почти не меняется, а контроль уже уходит в одно место.
После этого приведите ответы к одному формату. Текст ответа, usage, finish reason, коды ошибок и таймауты должны выглядеть одинаково для всех моделей. Иначе каждый новый провайдер снова потащит условные ветки в код.
Выбор модели и правила фолбэка вынесите в конфиг. Там же задайте лимиты, приоритеты, запрет на отдельные модели для некоторых сценариев и условия переключения при ошибках. Тогда команда меняет правило за минуты, а не ждет релиз.
И только потом подключайте вторую модель на части трафика. Для начала обычно хватает 5-10% запросов. Сравните качество, задержку, долю ошибок и стоимость на одной и той же задаче, а затем решайте, расширять ли трафик.
На этом этапе не стоит переводить все сразу. Лучше взять один понятный сценарий - например, саммари звонков или классификацию обращений - и довести его до стабильной схемы. После этого остальные команды обычно повторяют тот же шаблон без долгих споров.
Если вторая модель нормально проходит даже на малой доле трафика, у вас уже есть рабочий запасной путь. В этот момент смена провайдера перестает быть аварией и становится обычной настройкой.
Как оставить единый мониторинг
Если метрики живут внутри каждого провайдера, вы снова зависите от его панели и формата логов. Лучше считать каждый запрос по одной схеме, даже когда сегодня работает одна модель, а завтра другая.
Начните с общего request_id. Генерируйте его на входе в систему и передавайте дальше в бизнес-логику, вызов модели, логи и ответ пользователю. Тогда один идентификатор свяжет жалобу в продукте, трассу в API и расход токенов.
В каждом событии стоит хранить один и тот же набор полей: request_id, алиас модели, версию промпта, число входных и выходных токенов, задержку, код ответа и причину фолбэка. Этого уже достаточно, чтобы не потеряться при смене маршрута.
Алиас сильно упрощает жизнь. Бизнес-логика обращается к support-bot-primary, а не к конкретной модели. Сегодня за этим именем стоит один маршрут, через неделю другой. Дашборды не ломаются, потому что они смотрят на алиас и сценарий, а не на внутреннее имя у провайдера.
Продуктовые метрики и метрики провайдера лучше разделить сразу. Продуктовые отвечают на вопрос, помогла ли модель пользователю: доля успешных ответов, время до первого токена, число переводов на оператора, завершение сценария. Метрики провайдера показывают уже другое: сетевые ошибки, таймауты, rate limit, стоимость запроса, долю фолбэков. Если все смешать в один график, искать источник сбоя будет мучительно.
Алерты нужны не только на 5xx и рост задержки. Часто первый сигнал проблемы - резкий рост фолбэков. Например, алиас обычно идет в основную модель в 95% случаев, а потом падает до 60%. Пользователь еще получает ответы, но качество и цена уже изменились.
То же самое с расходами. Если цена на один и тот же сценарий выросла вдвое, разбираться нужно сразу, а не после месячного счета. Имеет смысл ставить пороги на стоимость одного запроса, стоимость 1000 запросов и долю дорогих моделей в общем трафике.
Если вы используете общий шлюз, собрать такую картину намного проще. У запросов один формат, один путь и единые audit trail. Поэтому смена модели не тянет за собой новый способ считать ошибки, токены и деньги.
Как собрать расходы и биллинг в одном месте
Привязка часто держится не на коде, а на деньгах. Если команда считает расходы только по месячному отчету провайдера, она теряет контроль. Непонятно, какая фича съела бюджет, где помог кэш и во сколько реально обошлась новая модель.
Считать нужно на уровне каждого запроса. У него есть свой маршрут, модель, объем токенов, цена провайдера и внутренний владелец расхода. Тогда вы видите не усредненную сумму за месяц, а живую картину: какой сценарий дорогой, где цена выросла и что можно перевести на другую модель без спора на уровне ощущений.
Минимальный набор полей здесь простой: prompt tokens, completion tokens, cache hit или cache miss, провайдер, модель, итоговая цена запроса, команда или cost center. Эти поля нужно нормализовать до того, как данные попадут в отчет. У разных провайдеров токены считаются немного по-разному, а кэш они вообще показывают каждый по-своему. Если не привести все к одной схеме, сравнение моделей быстро ломается.
Полезно разделить две суммы. Первая - внешняя цена провайдера. Вторая - внутренняя цена для бизнеса. Одна и та же генерация может идти по ставке провайдера, но внутри компании вы относите ее в отдельный центр затрат: поддержка, антифрод, поиск по базе знаний, генерация карточек товара. Тогда финансы и продукт смотрят на одни и те же запросы, но отвечают на разные вопросы.
Если у вас единый LLM API, этот слой удобно собрать в одном месте. Запросы уже идут через общий эндпоинт, значит логику учета не нужно дублировать в каждом сервисе. Это сильно упрощает биллинг, когда вы меняете провайдера, а формат учета остается прежним.
Расходы обычно достаточно смотреть в трех разрезах: по командам, по фичам и по моделям. Этого хватает, чтобы увидеть, кто тратит больше всех, какая функция дает пик расходов и где дорогая модель не дает заметной пользы.
Новая модель почти никогда не должна попадать в прод только по цене за миллион токенов из прайса. Сравнивайте ее на реальных объемах. Возьмите неделю боевого трафика, посмотрите средний размер prompt, долю длинных ответов, cache hit rate и только потом считайте бюджет. Нередко модель с более высокой ставкой дает меньший итоговый чек, если отвечает короче или лучше попадает в кэш.
Пример: команда меняет модель без релиза
У команды поддержки есть чат-ассистент для операторов. В коде сервиса нет имени модели и нет имени провайдера. Сервис отправляет все запросы в алиас support-chat, а правила маршрутизации лежат отдельно.
Днем команда держит более точную модель, потому что в это время больше сложных диалогов и выше цена ошибки. Ночью тот же алиас уходит на более дешевый маршрут. Операторы почти не замечают разницы, а расход на токены падает.
Правила могут быть совсем простыми: днем support-chat идет в основной маршрут, ночью в более дешевый, при таймауте или серии 5xx сразу переключается на запасной, а 10% трафика можно отправить в новую модель для сравнения качества.
Если основной провайдер падает в середине дня, команда не собирает срочный релиз. Она не меняет SDK, не правит промпты и не трогает бизнес-логику чата. Достаточно переключить маршрут у алиаса. Для сервиса снаружи все выглядит так же: тот же endpoint, тот же формат ответа, те же поля логов.
Мониторинг тоже не ломается. Дашборды смотрят не на конкретного провайдера, а на support-chat: задержка, ошибки, доля эскалаций к человеку, расход токенов, стоимость на диалог. Если правило было "не больше N рублей на 1000 сессий", оно продолжает работать и после переключения на запасной маршрут.
С качеством лучше не гадать. Команда сначала пускает на новую модель малую долю запросов и сравнивает результаты с текущей. Обычно смотрят на три вещи: сколько ответов оператор принял без правок, как часто диалог уходит на старшего специалиста и сколько минут занимает обработка обращения. Если новая модель держит тот же уровень или проседает в пределах допуска, трафик переводят полностью.
Где чаще всего ошибаются
Первая ошибка - имя модели живет прямо в обработчике фичи. После этого любая замена превращается в релиз, регресс и срочный разбор логов. Имя модели должно лежать в конфиге или слое маршрутизации, а не внутри бизнес-логики.
Вторая ошибка - менять модель и промпт в один день. После такого никто не понимает, что именно ухудшило результат: новая модель, другой system prompt, измененная температура или новый лимит контекста. Надежнее менять по одному параметру и гонять один и тот же набор тестовых запросов.
Третья ошибка связана со сбоями провайдера. Таймаут, 429 или ошибка внешнего API не должны попадать к пользователю так, будто это ответ модели. Пользователь должен получить понятное сообщение приложения, а система - отдельный код ошибки, причину маршрута и запись в метриках.
Еще одна типичная проблема - лимиты и квоты, завязанные только на одного поставщика. Так проще стартовать, но после подключения второй модели или своего шлюза старые правила начинают мешать: одни запросы режутся слишком рано, другие внезапно обходятся слишком дорого.
С учетом токенов путаница еще заметнее. Один провайдер считает кэш отдельно, другой включает служебные токены, третий отдает usage в своем формате. Если команда смотрит только на цифры провайдера и не сверяет их со своим счетчиком, расхождение быстро вырастает до неприятных сумм. Даже когда биллинг собирается в одном месте, сверка после смены модели все равно нужна.
Эта дисциплина выглядит скучно, но экономит много времени. Имя модели лежит вне кода, промпт меняют отдельно, ошибки провайдера логируют отдельно, лимиты задают на уровне маршрутизации, а расходы сверяют регулярно. Тогда смена модели перестает быть аварией.
Проверка перед запуском
Перед запуском проверьте не только ответы модели. Проверьте, переживет ли ваша схема ее замену без релиза, ручных правок и сломанных отчетов.
Рабочий тест выглядит просто: возьмите один и тот же запрос, прогоните его через основной маршрут, потом через запасной, а затем посмотрите не только на текст ответа, но и на весь след запроса. Если после замены модели у вас меняются метрики, теряются идентификаторы или исчезает стоимость, архитектура еще не готова.
Для быстрой проверки обычно хватает пяти вопросов:
- Можно ли сменить модель через конфиг или алиас без деплоя приложения?
- Один ли
request_idпроходит весь путь - от продукта до логов и биллинга? - Видите ли вы расходы на уровне запроса, команды и алиаса?
- Реально ли срабатывает фолбэк при timeout, 429 или пустом ответе?
- Остаются ли те же дашборды после переключения маршрута?
Хороший признак такой: бизнес-логика вообще не знает, какая модель стоит за алиасом summary-prod или support-chat. Она отправляет запрос в единый LLM API и получает ответ в одном формате. Все остальное - маршрутизация, фолбэк, учет токенов и биллинг - живет ниже.
Если команде нужен OpenAI-совместимый шлюз внутри российского контура, тут полезен RU LLM. Он позволяет оставить привычные SDK и код, а вопросы data residency, биллинга в РФ и аудита вынести из приложения в общий слой. Но сам принцип не зависит от конкретного провайдера: сначала проверьте замену модели на сбое и в отчетности, и только потом запускайте трафик.
Что делать дальше
Такая зависимость редко исчезает после одной большой миграции. Она уходит, когда команда меняет порядок работ. Сначала убирает прямую привязку в точке входа, а уже потом добавляет сложные правила выбора моделей.
Хороший старт - один рабочий сценарий и один алиас. Например, вынесите генерацию ответа для поддержки в support-chat, а внутри него пока оставьте одну модель. Бизнес-логика продолжит обращаться к тому же имени, и позже вы сможете менять поставщика без правок в коде продукта.
Следующий шаг - подключить второго провайдера, даже если первый работает стабильно. Не ждите сбоя, роста цен или лимитов. Пока все спокойно, проще проверить совместимость ответов, таймауты, формат ошибок и разницу в стоимости.
Если разложить это на короткий план, он выглядит так: сначала заменить прямой вызов провайдера на единый endpoint, затем ввести алиасы для сценариев, потом проверить второго поставщика на одном наборе запросов и только после этого добавлять полную маршрутизацию, общий биллинг и аудит.
Для многих команд этого хватает, чтобы снять самый неприятный риск за несколько дней. Сначала меняется только точка входа. Правила маршрутизации, фолбэк, A/B-проверки и ограничения по цене можно добавить позже, когда базовый слой уже работает.
Главная цель здесь простая: при смене модели вы делаете одно изменение в инфраструктурном слое, а не открываете десятки репозиториев. Если эта цель достигнута, значит зависимость от одного провайдера вы уже убрали.
Часто задаваемые вопросы
С чего начать, если у нас уже есть прямая интеграция с одним LLM API?
Начните с карты всех вызовов LLM. Найдите бэкенд, фоновые задачи, боты, скрипты и тестовые стенды, где код ходит напрямую к провайдеру. Потом замените имена моделей на алиасы вроде support_chat и поставьте перед текущим API общий слой с одним форматом ответа.
Нужно ли переписывать код, чтобы убрать привязку к провайдеру?
Чаще всего нет. Если сервисы уже работают через OpenAI-совместимый SDK, команде часто хватает сменить base_url и токен доступа. Бизнес-логика, промпты и клиентский код при этом можно оставить почти без правок.
Зачем вообще вводить алиасы моделей?
Алиас отделяет задачу от конкретной модели. Код обращается к summary_model или support_chat, а шлюз уже решает, какая модель стоит за этим именем сегодня. Поэтому вы меняете маршрут в конфиге, а не выпускаете релиз.
Где лучше хранить ретраи, таймауты и фолбэки?
Держите их в одном месте, а не внутри каждого сервиса. Шлюз или общая прослойка должны решать, сколько раз повторять запрос, когда ждать ответ и в какой момент уходить на запасной маршрут. Так все сервисы ведут себя одинаково, и команде легче разбирать сбои.
Как не сломать мониторинг, когда мы меняем модель или провайдера?
Сохраните один request_id на весь путь запроса и собирайте события в общей схеме. Логируйте алиас, маршрут, задержку, токены, код ответа и причину фолбэка. Тогда дашборды останутся прежними даже после смены модели.
Что нужно собирать для нормального учета токенов и стоимости?
Считайте расход на уровне каждого запроса. Берите входные и выходные токены, cache hit или miss, цену провайдера, итоговую стоимость и владельца расхода внутри компании. Если вы сразу нормализуете эти поля, финансы и инженеры будут смотреть на одни и те же цифры.
Когда имеет смысл подключать вторую модель?
Подключайте ее рано, но на малой доле трафика. Возьмите один понятный сценарий, пустите 5–10% запросов через новый маршрут и сравните качество, задержку, ошибки и цену. Так вы получите запасной путь без риска для всего продукта.
Как проверить, что замена модели пройдет без сюрпризов?
Проверяйте не только текст ответа. Прогоните один и тот же набор запросов через основной и запасной маршрут, затем сравните request_id, usage, стоимость, finish reason и работу фолбэка. Если после переключения пропадают метрики или меняется формат событий, слой еще не готов.
Что делать с ошибками провайдера, чтобы они не лезли наружу?
Не отдавайте пользователю сырую ошибку внешнего API. Приложение должно показать понятный ответ, а шлюз должен записать код сбоя, причину переключения и факт фолбэка в метрики. Тогда поддержка увидит, что произошло, а не будет искать причину по разным кабинетам.
Подойдет ли нам OpenAI-совместимый шлюз вместо прямых интеграций?
Да, это часто самый простой путь. Такой шлюз позволяет оставить привычные SDK и формат запросов, а маршрутизацию, биллинг, аудит и хранение данных вынести ниже уровня приложения. Если вам нужен контур в РФ, RU LLM закрывает этот сценарий через один endpoint.