Сжатие контекста перед запросом: сводка, map-reduce, факты
Сжатие контекста перед запросом помогает уместить длинные регламенты, договоры и отчеты в один промпт. Сравним три подхода и их слабые места.
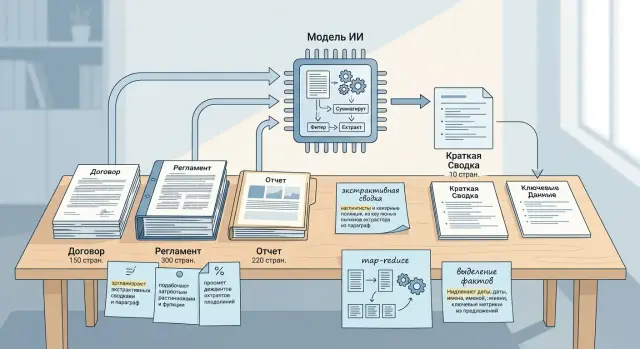
Почему длинный документ ломает ответ модели
LLM не читает длинный корпоративный документ так, как это делает юрист или аналитик. Модель получает текст внутри ограниченного контекстного окна. Если договор, приложения и служебные вставки не помещаются, система обрежет часть текста или это придется делать вручную. В обоих случаях смысл теряется еще до ответа.
Проблема не только в объеме. В длинных файлах почти всегда много шума: титульные страницы, оглавления, старые редакции, повторы, шаблонные формулировки, длинные определения. Все это занимает место рядом с тем, что действительно влияет на вывод: срок действия, исключения, лимиты ответственности, даты изменений, ссылки на приложения. Когда важный абзац тонет среди 80 страниц фона, модель берет общий смысл и упускает точную норму.
Из-за этого она легко смешивает версии документа. В первой редакции договора может быть одна схема оплаты, а в допсоглашении через десять страниц - другая. Человек замечает конфликт по дате и номеру приложения. Модель часто склеивает оба фрагмента в усредненный вывод, если актуальную часть не выделили отдельно.
Та же ошибка возникает с исключениями. Модель видит правило, но пропускает фразу вроде "кроме случаев, указанных в приложении 4". Ответ звучит уверенно, но уже неверно. Для корпоративных документов это обычный сбой: чем больше страниц, тем выше шанс, что исключение, оговорка или дата обновления выпадут из фокуса.
Обычно это выглядит так:
- ответ становится слишком общим;
- пропадают точные даты, суммы и номера пунктов;
- модель путает старую и новую редакцию;
- правило остается, а исключение теряется.
Даже большое контекстное окно не решает задачу само по себе. Если загрузить документ целиком, модель не начнет понимать его лучше автоматически. Она просто получит больше текста, в котором сложнее удержать внимание. Поэтому сжатие контекста нужно не только ради экономии токенов, но и ради точности: сначала отделить сигнал от шума, потом просить вывод.
Что сохранить до сжатия
Документ можно ужать очень сильно и все равно потерять смысл. Часто дело не в модели, а в том, что текст сжимают без четкой цели. Нужен не общий пересказ, а один конкретный вопрос к документу. Например: "проверь штрафы за просрочку поставки" или "найди условия досрочного расторжения для заказчика". Если цель расплывчата, при сжатии почти всегда исчезает то, что потом нужно для ответа.
Дальше стоит отделить факты, без которых вывод станет неверным. В корпоративных документах это обычно даты, суммы, валюты, сроки, роли сторон, лимиты, проценты и номера приложений. Разница между "10 рабочих дней" и "10 календарных дней" выглядит мелочью только до первой ошибки. То же самое с формулировками вроде "не позднее", "в течение" и "после получения уведомления".
Отдельный слой - исключения. Они часто прячутся в длинных абзацах, примечаниях и приложениях. Фраза "если иное согласовано сторонами" может менять весь смысл пункта. Спорные слова тоже нельзя размывать в краткой выжимке: "вправе", "обязан", "может", "по усмотрению заказчика". Для модели это несколько токенов. Для бизнеса - уже другой риск.
Перед сжатием полезно собрать короткий каркас:
- цель запроса;
- факты, которые нельзя потерять;
- исключения и спорные формулировки;
- привязку каждого фрагмента к разделу, пункту или странице.
Последний пункт часто пропускают. Зря. Если у выжимки нет источника, ее трудно проверить. Модель может дать уверенный ответ, а команда потом тратит время на ручной поиск исходного места. Когда документы идут через OpenAI-совместимый контур, например RU LLM, такую привязку удобно хранить рядом с каждым фрагментом и быстро сверять итог с оригиналом.
Хорошее сжатие не гонится за минимальным объемом. Оно оставляет то, что можно проверить и на что потом можно сослаться внутри команды.
Когда подходит экстрактивная сводка
Экстрактивная сводка берет куски из исходного текста и не переписывает их своими словами. Для корпоративных документов это часто плюс. Если юрист, комплаенс-специалист или владелец процесса потом сверяет ответ с оригиналом, точные формулировки экономят время и снижают риск спора о смысле.
Лучше всего этот метод работает там, где документ уже хорошо собран. Регламенты, политики, инструкции, типовые договоры и внутренние стандарты обычно имеют разделы, заголовки и повторяемую структуру. В таком тексте нужный смысл часто лежит в одном или двух абзацах, и модель может вытащить их почти без потерь.
Экстрактивная сводка особенно полезна, когда абзацы самодостаточны, структура документа читается сразу, а формулировку важно сохранить дословно. Она хорошо подходит для поиска правил, сроков, условий и ограничений.
Хороший пример - регламент обработки обращений. В одном пункте прямо сказано, кто отвечает за эскалацию, в другом указан срок ответа. Экстрактивный подход сохраняет оба фрагмента без риска, что модель смягчит норму или перефразирует ее неудачно.
Но слабое место у метода тоже очевидно. Он плохо держится на многословных текстах, где автор долго подводит к мысли, повторяет одно и то же и прячет смысл среди общих фраз. Тогда в сводку попадает шум: абзац вроде бы релевантен, а пользы почти нет.
Еще сложнее, когда одна мысль размазана по разным частям документа. Ограничение может быть в основном разделе, исключение - в приложении, срок действия - в примечании на другой странице. Экстрактивная сводка честно возьмет три куска, но не соберет их в одну ясную норму. В таких случаях нужен другой метод или хотя бы отдельная проверка после отбора фрагментов.
Если документ написан четко, этот способ прост и надежен. Если текст рыхлый, длинный и собран из оговорок, он быстро начинает тащить лишнее.
Как map-reduce работает на длинных файлах
Map-reduce полезен, когда файл уже не помещается в контекстное окно и одна общая сводка начинает смазывать детали. Схема простая: документ делят на части, получают короткий вывод по каждой части, а потом собирают общий результат из локальных выводов. Для длинных документов это часто надежнее, чем одна попытка прогнать все за раз.
Лучше всего подход работает на больших, но относительно ровных документах: регламентах, договорах, политиках, тендерной документации. Если резать файл на части близкого размера, модель отвечает стабильнее. Когда один кусок слишком короткий, а другой в три раза длиннее и забит исключениями, итоговая сводка обычно искажает баланс.
Помогает деление по смысловым блокам, но с контролем длины. Заголовки разделов полезны, однако слепо брать каждый раздел как есть не стоит. Приложение на две страницы и раздел на двадцать страниц требуют разной обработки, иначе локальные выводы будут несопоставимы.
На шаге map лучше просить не вольный пересказ, а короткий и жесткий формат ответа. Например: обязанности сторон, сроки, суммы, штрафы, исключения. Чем меньше свободы у модели в каждом куске, тем меньше шума на финальном reduce.
Небольшое перекрытие между соседними частями тоже помогает. Это особенно заметно в договорах, где одна мысль начинается в конце раздела, а условие или оговорка стоит в начале следующего. Большой overlap не нужен. Обычно хватает небольшого запаса, чтобы не потерять связку между фрагментами.
Рабочая схема выглядит просто:
- Делите документ на части близкого объема.
- Просите по каждой части короткий вывод в одном формате.
- Собирайте итог только из локальных выводов.
- Отдельно проверяйте суммы, сроки, ограничения и исключения.
Самое слабое место map-reduce - финальный шаг. Именно там модель любит сглаживать острые углы. В локальной выжимке может остаться фраза "штраф начисляется только после 10 рабочих дней просрочки", а в общей сводке останется просто "штраф за просрочку". Смысл уже другой.
Поэтому после reduce стоит делать короткую проверку по исходнику. Не всей сводки сразу, а по рискованным местам: датам, порогам, лимитам, исключениям и ссылкам на приложения. Если документ занимает 150 страниц, такая проверка все равно быстрее, чем разбирать ответ, который звучит уверенно, но пропустил одно важное условие.
Где лучше работает выделение фактов
Выделение фактов лучше всего работает там, где у документа понятная структура, а у команды есть точный вопрос. Это хороший вариант для договоров, анкет, политик, актов, заявок и регулярных отчетов. Модели не нужно пересказывать весь текст. Ей нужно достать ровно те данные, которые потом попадут в проверку, поиск или таблицу.
Сначала задайте схему полей. Не после пилота, а до первого запуска. Если вы ищете в договоре срок действия, порядок оплаты, штрафы, лимит ответственности и право на одностороннее расторжение, эти поля надо описать явно. Иначе модель выберет удобный для себя формат, и сравнивать результаты будет трудно.
Для этого метода лучше работает узкий запрос. Не стоит просить "извлечь все важное". Лучше просить только то, что нужно задаче. Например, для закупки можно тянуть ИНН контрагента, дату подписания, сумму, валюту, срок поставки и условия приемки. Так сжатие контекста дает меньше шума и лучше подходит для автоматической обработки.
Когда этот подход дает лучший результат
Этот подход особенно полезен в четырех случаях:
- нужно сравнить десятки похожих документов по одним и тем же полям;
- важна таблица, а не связный пересказ;
- в тексте много воды, приложений и повторов;
- результат потом проверяет человек или бизнес-правило.
Но и здесь есть слабое место. Метод плохо хранит фон. Если вы не описали поле, факт просто исчезнет из результата, даже если для юриста он был заметным. В политике ИБ можно вытащить срок хранения логов и список ролей, но пропустить оговорку про исключения, если для нее нет отдельного поля.
Поэтому схему лучше делать чуть шире, чем кажется нужным в начале. Полезно добавить поля вроде "особые условия", "исключения" или "неясная формулировка". Они не заменят чтение оригинала, но часто спасают от тихих потерь смысла.
Еще один практичный шаг - сравнивать версии промпта и схемы в одной таблице. Возьмите 20-30 документов, прогоните их через две версии извлечения и посмотрите, где поля стали пустыми, где модель начала путать формулировки, а где точность выросла. На таких сравнениях ошибки видны сразу.
Как выбрать метод
Выбор метода упирается в цену ошибки. Для сжатия контекста мало спросить, какой способ лучше. Сначала команда должна понять, что именно модель должна вернуть по документу.
Сформулируйте один рабочий вопрос. Не общий, а прикладной: "Есть ли в договоре штраф за досрочное расторжение?" или "Какие сроки оплаты указаны в приложениях?" Один точный вопрос сразу показывает, нужен ли вам общий смысл, сводка по частям или набор проверяемых фактов.
Потом оцените две вещи: цену пропуска и цену лишнего шума. Если модель пропустит пункт о штрафе, юрист или закупки примут плохое решение. В таком случае экстрактивная сводка часто слабовата, потому что берет самые заметные фрагменты, а не самые рискованные. Если лишние детали не страшны, а нужен быстрый обзор, сводка может быть хорошим стартом.
Дальше посмотрите на сам документ. Его структура решает половину задачи.
- Если документ короткий, ровный и без сложных приложений, начните с экстрактивной сводки.
- Если файл длинный, состоит из разделов и повторяет условия в разных местах, попробуйте map-reduce.
- Если нужны даты, суммы, стороны договора, лимиты и исключения, сразу тестируйте выделение фактов.
- Если документ смешанный, собирайте гибрид: факты для критичных полей и короткую сводку для общего контекста.
Повторы тоже важны. Map-reduce неплохо держится на длинных политиках, регламентах и договорах с приложениями, но может размазать редкий, но важный пункт, если reduce слишком агрессивен. Выделение фактов, наоборот, хорошо ловит конкретику, но хуже передает общий смысл спора, мотивацию сторон или оговорки между строк.
После этого прогоните 10-20 реальных примеров, а не один красивый файл. Берите документы, на которых команда уже знает правильный ответ. Сравнивайте не только точность, но и удобство проверки: где аналитик тратит 2 минуты, а где 20.
На практике перекос почти всегда остается. Один метод дает чистую, но бедную картину. Другой приносит слишком много текста. Поэтому нормальный финал - гибридная схема. Для корпоративного договора можно сначала извлечь факты по срокам, штрафам и суммам, а потом добавить короткий map-reduce по спорным разделам. Если команда гоняет такие тесты через единый OpenAI-совместимый эндпоинт, ей проще сравнивать методы на одних и тех же промптах и логах.
Пример на корпоративном договоре
Возьмем договор поставки на 120 страниц с приложениями. Внутри обычно есть сам текст договора, график поставок, таблицы ставок, порядок приемки и отдельные условия по штрафам. Вопрос у бизнеса при этом часто очень узкий: "Когда нужно оплатить счет и что будет за просрочку?"
Если просто отправить весь файл в модель, она легко смешает основной текст и приложения. Еще хуже, если срок оплаты указан в одном разделе, а штрафы и исключения спрятаны в приложении или протоколе разногласий. Поэтому метод сжатия лучше проверять на одном конкретном вопросе, а не на абстрактной задаче "сделай сводку".
Один вопрос, три подхода
Экстрактивная сводка обычно срабатывает первой. Поиск находит фрагменты вроде "Порядок расчетов" и "Ответственность сторон", затем в модель уходят исходные абзацы, а не пересказ. Для вопроса про сроки оплаты и штрафы это часто самый быстрый вариант: модель видит точную формулировку, например "оплата в течение 10 банковских дней" и "пеня 0,1% за каждый день просрочки". Минус простой: если важная оговорка лежит в приложении, система может ее не подтянуть.
Map-reduce ведет себя иначе. Документ режут на части, делают краткие выводы по каждой части, потом собирают общий обзор. Такой подход хорош, когда нужно понять весь договор целиком: как устроены поставки, приемка, расчеты, споры. Но на узком вопросе он часто теряет детали. Вместо точного ответа получится что-то вроде "есть срок оплаты и штрафы за просрочку", а юристу или финансисту этого мало.
Выделение фактов полезнее там, где ответ должен лечь в поля, а не в абзац текста. Схема может быть такой:
- срок оплаты;
- ставка штрафа;
- предел штрафа;
- исключения и условия применения;
- ссылка на раздел или приложение.
Тогда система собирает не обзор, а набор значений. Для того же договора результат выглядит понятнее: срок оплаты 10 банковских дней, пеня 0,1% в день, максимум 10% от суммы, штраф не начисляется на оспариваемую часть счета. Такой формат проще проверить и передать дальше в ERP, согласование или риск-контроль.
Если нужен быстрый ответ на один вопрос, чаще выигрывает экстрактивная сводка. Если нужен обзор всего файла, берите map-reduce. Если команде нужны точные сроки, ставки и условия в явном виде, выделение фактов почти всегда полезнее.
Где команды ошибаются чаще всего
Результат чаще портит не сама модель, а плохая подготовка текста. Команда берет длинный файл, режет его на куски, быстро прогоняет через один и тот же пайплайн и получает ответ, который звучит уверенно, но опирается на обрывки.
Частая ошибка - резать документ по фиксированному числу токенов и не смотреть на структуру. Так ломаются пункты договора, сноски, таблицы и приложения. Если модель видит начало строки "штраф не применяется при...", а продолжение осталось в другом чанке, она легко додумает условие сама.
Не меньше проблем дает путаница версий. В реальной работе рядом лежат проект договора, версия после правок юристов и подписанный вариант. Если в сводку попали куски из разных файлов, модель соберет гибридный ответ: срок из новой редакции, исключение из старой, сумму из приложения. На глаз это не всегда заметно.
Команды обычно спотыкаются в нескольких местах:
- режут текст посередине таблицы, списка или пункта;
- смешивают редакции документа из-за похожих названий файлов;
- убирают координаты фрагмента и теряют страницу, раздел или номер пункта;
- ждут, что один метод подойдет и для договора, и для переписки, и для регламента;
- тестируют типовые кейсы, но не проверяют редкие исключения, оговорки и сноски.
Потеря координат особенно дорогая. Если модель пишет: "в договоре есть право на одностороннее расторжение", этого мало. Юристу или менеджеру нужен номер пункта, страница и, если есть, приложение. Без этого ответ нельзя быстро проверить, а значит, пользы от него почти нет.
Один метод для всех файлов тоже редко работает. Экстрактивная сводка может неплохо держать политику или длинную статью, но на скане договора с таблицами и приложениями она часто теряет смысловые узлы. Выделение фактов лучше держит сущности и условия, но хуже передает ход рассуждения. Map-reduce помогает на очень длинных документах, но любит размывать редкие исключения на этапе финальной сборки.
Редкие исключения почти всегда ломают систему уже в проде. Например, 95% договоров содержат обычный срок оплаты, а 5% прячут особое условие в приложении или сноске. Если команда не добавила такие случаи в набор проверок, красивый ответ легко окажется неверным.
Хорошая привычка проста: хранить рядом с каждым фрагментом версию файла, страницу, раздел и дату. Если запросы идут через RU LLM, аудит-трейлы в каждом запросе помогают потом восстановить цепочку и понять, какой именно текст модель видела. Это заметно экономит время, когда ответ уже ушел в работу.
Быстрая проверка перед запуском
Перед продом полезнее один скучный прогон, чем неделя споров после первой ошибки. У любого метода сжатия одна цель: сократить текст, но не сломать смысл. Если модель уверенно отвечает по неверно сжатому документу, цена ошибки растет быстро.
Начните с проверки источников. Каждый вывод должен вести к конкретному месту в документе: номеру раздела, странице, абзацу или фрагменту текста. Если ответ нельзя быстро открыть и сверить, такой пайплайн лучше не выпускать. Для договора это особенно заметно: модель пишет про штраф, а в документе речь шла только о пене за другой случай.
Потом проверьте факты, которые чаще всего теряются при сжатии. Обычно ломаются не общие формулировки, а детали:
- даты начала и окончания;
- суммы, лимиты, ставки и проценты;
- запреты, условия и исключения;
- отрицания вроде "не допускается" или "не позднее";
- ссылки на приложения и отдельные пункты.
Отрицания стоит смотреть отдельно. Одна потерянная частица "не" меняет смысл целого раздела. То же самое с исключениями. Фраза "кроме случаев, указанных в приложении 3" часто исчезает в сводке, а потом модель отвечает слишком широко.
Тестовый набор не должен состоять только из длинных файлов. Короткие документы тоже нужны. На них проще заметить слишком агрессивное сжатие, когда система урезает даже то, что помещалось целиком. Длинные файлы, наоборот, покажут, как метод ведет себя на повторах, вложенных условиях и таблицах.
Хорошая проверка всегда включает ручную сверку. Не нужно читать сотни примеров. Хватает нескольких документов разного типа, если человек смотрит внимательно и отмечает конкретные расхождения между исходником и сжатой версией. Лучше взять один короткий приказ, один длинный договор и один регламент с исключениями.
Если после такой проверки остаются ответы без источника, пропавшие суммы или смазанные ограничения, проблему нужно чинить до запуска. Иначе система будет экономить токены, но терять то, ради чего документ вообще читали.
Что делать дальше
Начните с одного типа документа. Не берите сразу все: договоры, регламенты, переписку и отчеты. Для пилота лучше выбрать один поток, где структура похожа от файла к файлу, а ответ модели легко проверить вручную.
Хороший первый кандидат - корпоративный договор, шаблон закупки или внутренний регламент. На таких документах быстро видно, где экстрактивная сводка теряет детали, где map-reduce искажает формулировки, а где выделение фактов дает слишком сухой результат.
Дальше соберите короткий набор вопросов от тех, кто реально читает эти документы. Обычно хватает 10-15 вопросов от юристов, аналитиков или риск-команды. Вопросы должны быть прикладными: срок действия, штрафы, условия расторжения, ограничения по данным, список сторон, суммы, исключения.
После этого прогоните один и тот же набор файлов через три подхода и сравните их по одинаковым метрикам:
- точность ответа на контрольные вопросы;
- цена обработки одного документа;
- задержка до финального ответа;
- стабильность на похожих файлах;
- удобство ручной проверки.
Не пытайтесь выбрать победителя по одному числу. Экстрактивная сводка может быть дешевле, но пропускать редкие оговорки. Map-reduce лучше держит объем, но иногда сглаживает смысл на стыке частей. Выделение фактов удобно для поиска конкретных условий, но хуже отвечает на вопросы, где нужен общий контекст.
Если команде важны маршрутизация моделей, биллинг в РФ и хранение логов внутри страны, такой пилот можно прогнать через RU LLM на rullm.com. Это удобно, когда нужно сравнить несколько моделей через единый OpenAI-совместимый эндпоинт и не переписывать существующий код.
До выхода в прод зафиксируйте схему проверки. Кто размечает эталонные ответы, как считается ошибка, какой процент промахов допустим, какие поля нельзя терять ни при каких условиях. Если этого нет, команда почти всегда спорит не о качестве, а о впечатлениях.
Нормальный результат пилота выглядит просто: на одном типе документа у вас есть понятная таблица по точности, цене и задержке, видны слабые места каждого подхода, и ясно, что идет в рабочий контур, а что остается запасным вариантом.
Часто задаваемые вопросы
Почему модель ошибается на длинном договоре?
Потому что длинный файл забивает контекст шумом. Модель видит общую картину, но теряет даты, суммы, номера пунктов, исключения и легко смешивает старую редакцию с новой.
Спасает ли большое контекстное окно от ошибок?
Не всегда. Большое окно дает больше текста, но не отделяет полезные фрагменты от титульных листов, повторов и приложений. Если сначала не сжать документ под конкретный вопрос, точность часто не растет.
Что нельзя терять при сжатии текста?
Сохраняйте то, без чего вывод станет неверным: даты, суммы, валюты, сроки, роли сторон, лимиты, проценты, исключения и спорные слова вроде «вправе» или «обязан». Сразу привязывайте каждый фрагмент к странице, разделу или пункту, чтобы команда быстро сверила ответ с исходником.
Когда лучше брать экстрактивную сводку?
Этот способ подходит, когда формулировку нужно сохранить почти дословно. Он хорошо работает на регламентах, политиках и типовых договорах, где нужное правило лежит в одном-двух абзацах и его потом легко проверить по оригиналу.
В каких случаях map-reduce дает лучший результат?
Map-reduce берите для длинных файлов, которые уже не помещаются в один запрос. Он удобен для договоров с приложениями, политик и тендерной документации, если вам нужен обзор по всему документу, а не ответ по одному узкому пункту.
Когда полезнее выделение фактов, а не сводка?
Выделение фактов нужно там, где результат должен лечь в поля, таблицу или проверку. Для договоров это обычно срок оплаты, ставка штрафа, лимит ответственности, право на расторжение и ссылка на раздел, где это написано.
Как выбрать метод под конкретный документ?
Сначала задайте один рабочий вопрос к документу. Если нужен быстрый обзор, начните с экстрактивной сводки; если файл длинный и разбит на разделы, пробуйте map-reduce; если нужны точные значения для проверки или системы, сразу делайте выделение фактов.
Как правильно делить длинный документ на части?
Режьте по смысловым блокам, но следите, чтобы части были близки по объему. Не обрывайте таблицы, сноски и пункты посередине, а между соседними кусками оставляйте небольшое перекрытие, чтобы не потерять условие на стыке.
Как быстро проверить, что пайплайн не ломает смысл?
Смотрите не только на общий смысл, а на рискованные места. Возьмите несколько реальных документов, сверяйте ответ с исходником и отдельно проверяйте даты, отрицания, суммы, лимиты, исключения и ссылки на приложения.
Можно ли сочетать разные методы в одном пайплайне?
Да, и на практике это часто самый удобный вариант. Например, можно сначала вытащить факты по срокам, суммам и штрафам, а потом добавить короткую сводку по спорным разделам, чтобы не потерять общий контекст.