Синхронный вызов или очередь для LLM: как выбрать режим
Разберём, когда нужен синхронный вызов или очередь для LLM: по терпению пользователя, риску повторов, таймаутам и требованиям аудита.
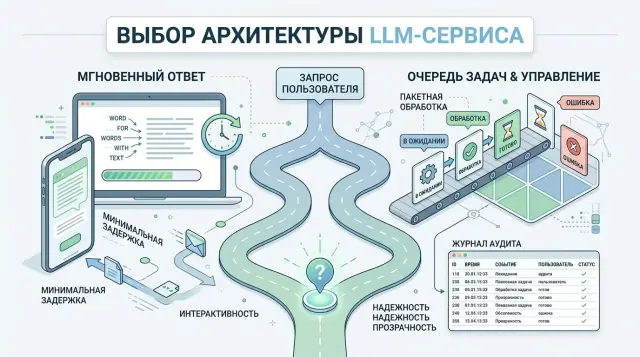
В чем выбор
Вы выбираете не между "быстро" и "медленно", а между двумя способами работы фичи.
Синхронный вызов держит пользователя в текущем экране и пытается вернуть результат сразу. Очередь принимает задачу, сохраняет ее и отдает ответ позже - в интерфейсе, через webhook, по почте или по повторному запросу статуса.
Для пользователя разница заметна сразу. В синхронном режиме он ждет один ответ и видит спиннер, прогресс или готовый текст. В режиме очереди он сначала получает подтверждение, что задача принята. Это снимает тревогу: система не зависла и не потеряла запрос.
Скорость модели - только часть решения. На практике режим ломают другие вещи: длинные промпты, скачущая задержка у провайдера, лимиты, повторные отправки из клиента, сетевые сбои и шаги после генерации. Даже если сама модель отвечает за 8 секунд, вся цепочка может занять минуту, если потом нужно записать результат в CRM, согласовать документ или запустить проверку.
Полезно разделять два типа работы. Если фича просто генерирует текст, краткое резюме или ответ в чате, синхронный путь часто удобнее. Если после ответа система что-то меняет во внешнем мире - создает заявку, отправляет письмо, обновляет карточку клиента, пишет данные в несколько систем - очередь обычно безопаснее.
Это особенно заметно там, где цена повтора высока. Два одинаковых абзаца в черновике неприятны, но терпимы. Две одинаковые заявки в биллинге или два письма клиенту - уже реальная проблема.
Аудит тоже меняет выбор. Если вам нужно хранить статус задачи, кто ее запустил, какой промпт ушел, какой ответ вернулся и что система сделала потом, очередь обычно дает более чистый след. Даже если команда работает через единый OpenAI-совместимый шлюз вроде RU LLM, режим вызова все равно выбирают на уровне продукта: один и тот же API подходит и для мгновенного ответа, и для фоновой обработки.
Простое правило такое: если человек сидит у экрана и ждет один текст, начинайте с синхронного вызова. Если задача может идти дольше, повторяться или запускать внешние действия, ставьте ее в очередь.
Сколько пользователь готов ждать
Терпение пользователя обычно решает больше, чем чистая скорость модели. Если человек смотрит на экран и ждет ответ, у вас мало времени. Если результат нужен через минуту или вообще без участия человека, синхронный вызов часто только мешает.
Для большинства LLM-фич работает такой ориентир:
| Сценарий | Что человек считает нормой | Когда начинаются повторы | Что лучше выбрать |
|---|---|---|---|
| Чат, поиск с ответом на экране | 2-5 сек | после 6-8 сек | Синхронный вызов |
| Форма с генерацией текста, суммаризацией, подсказкой | 5-12 сек, если есть явный прогресс | после 10-15 сек | Синхронно, если ответ почти всегда быстрый |
| Генерация длинного отчета, разбор файла, пакет документов | 10-20 сек уже раздражают | после 12-20 сек | Очередь и возврат статуса |
| Ночной импорт, разметка, внутренний скоринг, обогащение CRM | пользователь не ждет | повторов с экрана нет | Очередь или фоновый воркер |
В чате люди редко смотрят на спиннер дольше нескольких секунд. Они жмут кнопку еще раз, обновляют страницу или отправляют тот же запрос заново. Так появляются дубли, лишние списания токенов и путаница в логах.
С формами ситуация мягче. Если человек загрузил файл и видит понятный прогресс, он готов ждать дольше. Но есть предел: когда интерфейс молчит, ожидание выглядит как ошибка, а не как работа системы.
Если ответ часто выходит за 10-15 секунд, лучше сразу вернуть статус задачи, а не держать соединение открытым. Пользователь получает подтверждение, что система приняла запрос, а вы спокойно обрабатываете его в очереди, повторяете сбойный шаг и сохраняете историю без гонок.
Это особенно полезно там, где один запрос дорогой: анализ договора, генерация развернутого ответа для оператора, проверка большого набора документов. Для таких задач ждать синхронно неудобно даже тогда, когда модель иногда укладывается в лимит.
Отдельный случай - внутренние сценарии без пользователя на экране. Ночная категоризация обращений, массовая очистка PII, переоценка диалогов, обогащение карточек клиента не требуют мгновенного ответа. Тут почти всегда выигрывает очередь: она дает ретраи, контроль нагрузки и понятный журнал обработки.
В банке, телекоме или госсекторе это ощущается особенно быстро. Оператор в интерфейсе может подождать 3-4 секунды ради подсказки для ответа клиенту. Пакетная проверка 50 тысяч заявок в том же контуре уже должна идти фоном, с task ID, статусами и записью каждого шага для аудита.
Если коротко: человек на экране ждет секунды, не минуты. Все, что живет дольше этого окна, лучше превращать в задачу со статусом.
Что ломают повторы
Повторный запрос редко кажется большой проблемой, пока одна и та же операция не проходит дважды. Для LLM-фичи это особенно неприятно: пользователь видит одну кнопку, а система может создать два ответа, две записи в CRM, две задачи для оператора или два списания токенов.
Повторы появляются не из-за "ошибки пользователя", а из-за обычных сбоев. Человек нажал кнопку два раза. Клиент не дождался ответа и отправил запрос снова. Сеть оборвалась после обработки, но до получения ответа. Фронт поймал таймаут и решил, что запрос не дошел. Воркер в очереди взял задачу повторно после сбоя.
Проблема не в самом дубле, а в побочном действии. Если LLM только сгенерировал черновик письма, повтор можно пережить. Если тот же вызов уже отправил письмо клиенту, создал тикет или записал результат в учетную систему, дубль портит данные и создает лишнюю работу. В платежных, сервисных и согласовательных сценариях это быстро превращается в инцидент.
Хорошее правило простое: генерацию текста часто можно повторить, а внешнее действие нужно защищать. Сначала получите ответ модели, потом отдельно решайте, можно ли второй раз выполнять запись, отправку или смену статуса.
Как защититься
request_id помогает понять, что два запроса на самом деле относятся к одному и тому же бизнес-шагу. Клиент создает этот идентификатор один раз и передает его по всей цепочке: фронт, бэкенд, очередь, вызов модели, запись результата. Тогда сервис видит повтор и не делает действие заново.
Идемпотентность закрывает вторую часть задачи. Если система уже обработала request_id, она не запускает опасный шаг повторно, а возвращает прежний результат или текущий статус. Это особенно полезно там, где фронт часто перезапрашивает ответ после таймаута.
Обычно шаги делятся так:
- можно повторять: генерацию ответа, классификацию текста, извлечение полей;
- лучше повторять с кешем: суммаризацию длинного документа, rerank, перевод;
- нельзя повторять без защиты: отправку письма, создание заказа, смену статуса, запись в биллинг.
Для аудита это тоже важно. Если один пользовательский запрос оставил три почти одинаковые записи, потом сложно доказать, что именно произошло и какой ответ система считала финальным. В системах с audit trail, как у RU LLM, request_id и единая цепочка событий заметно упрощают разбор: видно, где пришел первый запрос, где случился ретрай и какой шаг сервис сознательно не выполнил второй раз.
Когда аудит влияет на архитектуру
Аудит начинает влиять на архитектуру в тот момент, когда ответ модели уже нельзя считать "черновиком без последствий". Если LLM пишет письмо клиенту, меняет лимит, создает документ для проверки или отвечает по данным с персональной информацией, одной записи в техническом логе мало. Нужен понятный след: кто запустил запрос, на каких данных, какой промпт и какая модель сработали, что система вернула и кто потом это утвердил.
При таком требовании синхронный вызов часто уступает очереди. Синхронный путь хорош, когда пользователь ждет ответ на экране и риск невысокий. Но если нужен разбор спорных случаев, ручное подтверждение или повторная обработка после сбоя, очередь проще контролировать. Она дает явные статусы, хранит историю попыток и не теряет контекст, если внешний провайдер ответил ошибкой или по таймауту.
Что писать по каждому запросу
Для разбора инцидента обычно хватает не "всех логов подряд", а нескольких полей, которые легко искать и сопоставлять:
- request_id и user_id или service account;
- время запуска, окончания и длительность;
- версия промпта, системной инструкции и выбранной модели;
- маскированный фрагмент входа, хеш полного входа и хеш ответа;
- итоговый статус: выполнено, отклонено, ушло на ручную проверку, повторено.
Версию промпта и модели стоит писать всегда, если результат может повлиять на деньги, юридически значимый текст или действие в бизнес-системе. Иначе через месяц вы увидите спорный ответ, но не поймете, это был старый шаблон, другой роутинг или уже обновленная модель.
Статус, решение и ручное подтверждение лучше хранить не только в логах приложения, а в отдельной записи операции в базе. У этой записи должны быть этапы: "создано", "отправлено в модель", "получен ответ", "ожидает проверки", "подтверждено" или "отклонено". Если сотрудник утвердил ответ вручную, сохраните его ID, время и короткую причину. Тогда аудит увидит не просто текст ответа, а всю цепочку решения.
С 152-ФЗ это связано напрямую. Не складывайте сырые персональные данные в широкодоступные логи. Маскируйте PII до записи, держите полный текст только там, где он действительно нужен, и ограничьте доступ по ролям. Отдельно задайте срок хранения, чтобы журнал не превратился в склад лишних данных.
Если команда работает через RU LLM, часть базы уже есть: data residency в РФ, маскирование PII, AI-Law метки и audit trail на каждый запрос. Это снимает часть инфраструктурной работы. Но бизнес-решение, статус ручной проверки и связь с вашим пользователем все равно должны жить в вашей системе, иначе журнал останется неполным.
Таблица решений для типовых сценариев
Один и тот же LLM-ответ можно отдать сразу, а можно поставить в очередь и вернуть позже. Выбор обычно упирается в три вещи: сколько человек готов ждать, что случится при повторе запроса и нужно ли потом доказать, кто запустил операцию и что именно сделал сервис.
| Сценарий | Терпение пользователя | Риск повторов | Требования аудита | Выбор режима |
|---|---|---|---|---|
| Чат, подсказка, короткий ответ за 1-3 секунды | Низкое, ответ нужен сразу в интерфейсе | Низкий или средний, повтор обычно даст второй текст | Нужен базовый след: request_id, модель, время, статус | Синхронный вызов |
| Генерация текста, разбор документа, сводка за 10-30 секунд | Среднее, если есть понятный статус | Средний, люди часто нажимают кнопку еще раз | Нужна история попыток и итоговый статус | Очередь, либо синхронно только при очень стабильной задержке |
| Действия после ответа модели: письмо, тикет, запись в CRM, смена статуса | Низкое значение, человеку важнее надежность | Высокий, дубль создает реальные последствия | Нужен полный журнал шагов и ручных подтверждений | Очередь с идемпотентностью |
| Пакетная обработка, ночные задачи, внутренний скоринг | Пользователь не ждет | Повторы надо контролировать на уровне воркера | Нужен журнал обработки, ретраев и ошибок | Очередь или фоновые воркеры |
Если нужно очень короткое правило, оно такое. Синхронный вызов подходит для ответа, который человек сейчас читает на экране. Очередь нужна там, где результат приходит дольше, может повториться или запускает действие во внешней системе.
Как принять решение по шагам
Спор между синхронным вызовом и очередью обычно решает не модель, а цена ошибки. Если человек смотрит на экран и ждет ответ сейчас, у вас есть несколько секунд. Если задача может жить в фоне, лучше думать не о скорости, а о предсказуемом результате и чистом аудите.
Сначала разберите путь пользователя по экранам, а не по сервисам. Один и тот же LLM-запрос уместен в синхронном режиме в чате и совсем не подходит для синхронного режима при создании договора, где пользователь спокойно подождет статус "принято".
Дальше пройдите по пяти вопросам.
- Сколько секунд человек реально готов ждать на каждом экране.
- Есть ли после ответа модели побочные действия: письмо, тикет, запись в CRM, списание бонусов, смена статуса.
- Какие поля вы обязаны сохранить для разбора инцидента.
- Что вернет клиенту ваш сервис: готовый результат, статус "взяли в работу" или черновик, который обновится позже.
- Что произойдет при таймауте, двойном клике, повторе от клиента, медленном провайдере и обрыве сети.
После этого решение обычно становится очевидным. Если побочных действий нет, а ошибка стоит дешево, синхронный ответ проще и понятнее для пользователя. Если повтор может создать дубликат заявки или лишнюю отправку, очередь почти всегда выигрывает.
Пример из рабочего процесса
Оператор поддержки открывает карточку клиента и просит модель подготовить ответ на жалобу по задержке доставки. Ему нужен черновик прямо сейчас, пока он видит историю заказа, прошлые обращения и внутренние правила. Такой шаг лучше делать синхронно: сотрудник ждет несколько секунд, читает текст на экране, правит тон и решает, можно ли отправлять.
Синхронный режим хорош для черновика по простой причине. Он не меняет внешнее состояние. Если модель дала слабый ответ, оператор просто запрашивает новый вариант. Если страница перезагрузилась, никто не получил лишнее письмо, а в CRM не появилось дублей.
После нажатия "Отправить" логика меняется. Тут система уже делает действия, которые нельзя повторять без последствий: отправляет письмо клиенту, пишет комментарий в CRM, иногда меняет статус обращения. Эти шаги лучше ставить в очередь. Двойной клик, таймаут в браузере или обрыв сети легко приводят к повторам, а повторы здесь стоят дорого: клиент получает два письма, менеджеры видят две записи, а разбор инцидента тянется часами.
Очередь дает более спокойный режим работы. Приложение создает задачу, присваивает ей один идентификатор и обрабатывает шаги по порядку. Если почтовый сервис не ответил, воркер повторит попытку сам, а не заставит оператора гадать, ушло письмо или нет. Если CRM временно недоступна, задача не теряется и не просит человека нажимать кнопку еще раз.
Для сотрудника хватает простых статусов:
- "Черновик готов";
- "Отправка в очереди";
- "Письмо отправлено, CRM обновлена";
- "Нужна проверка".
Такой набор снимает лишние вопросы. Оператор видит, где именно остановился процесс, и не делает лишних действий.
Аудит тоже становится чище. Система хранит, кто запросил черновик, какой текст сотрудник утвердил, когда задача ушла в очередь и чем закончился каждый шаг. Если команда работает через RU LLM, audit trail по запросам помогает связать генерацию текста с последующей отправкой и записью в CRM. Для разбора спора с клиентом или внутренней проверки этого обычно достаточно.
Частые ошибки
Самая частая ошибка - смотреть только на среднее время ответа. Среднее почти всегда выглядит прилично, а ломают продукт длинные хвосты: один запрос отвечает за 4 секунды, другой за 35, третий уходит в таймаут. Пользователь помнит не p50, а момент, когда экран завис и непонятно, ждать дальше или нажимать снова.
Вторая ошибка - писать во внешнюю систему прямо из синхронного вызова. Например, менеджер нажал "сгенерировать ответ клиенту", LLM вернул текст, и сервис тут же сохранил его в CRM. Если сеть моргнула после записи, фронт может решить, что операция не удалась, и отправить тот же запрос еще раз. В итоге в CRM окажутся два комментария, а команда будет искать, где появился дубль.
Такие сценарии лучше разделять: синхронно вернуть статус, а запись во внешнюю систему делать как отдельный шаг с проверкой идемпотентности. Звучит скучно, но обычно экономит часы разборов.
Еще одна типовая проблема - ретраи без стабильного идентификатора запроса. Если у повтора нет одного и того же request_id, система не понимает, это новая задача или повтор старой. Для LLM-фичи это особенно неприятно: вы платите дважды, получаете два разных ответа и потом не можете доказать, какой из них пользователь видел первым.
С аудитом часто ошибаются так же предсказуемо. Сначала команда быстро запускает фичу, потом пытается собрать историю по кускам: немного из логов приложения, немного из очереди, немного из CRM, еще что-то из биллинга. Когда приходит внутренний контроль или спор по операции, цепочка уже рвется. Намного лучше, когда у каждого запроса сразу есть единый след: кто вызвал, какой промпт ушел, какой ответ пришел, что система сделала потом.
Если вы работаете через шлюз вроде RU LLM, где audit trail встроен в каждый запрос, базовую часть собрать проще. Но бизнес-действия все равно нужно привязывать к тому же идентификатору на своей стороне. Иначе аудит модели есть, а аудит действия в продукте - нет.
Отдельно раздражает пользователя отсутствие понятного статуса. Люди нормально ждут, если видят "обрабатываем", "проверяем", "готово" или "нужна повторная отправка". Они начинают жать кнопку снова, когда интерфейс молчит. Тогда вы сами создаете повторы, а потом пытаетесь лечить их ретраями и блокировками.
Обычно тревожные признаки выглядят так:
- в дашборде красивое среднее время, но саппорт жалуется на зависания;
- после таймаутов появляются дубли в CRM, чатах или тикетах;
- один и тот же запрос сложно проследить между API, очередью и фронтом;
- пользователь не понимает, задача еще идет или уже сломалась.
Если эти симптомы уже есть, не чините их по одному. Сначала введите стабильный request_id, явные статусы для пользователя и единый журнал событий. После этого выбор между синхронным вызовом и очередью становится намного спокойнее.
Проверка перед запуском
Много ошибок видно за день до релиза, если команда отвечает на несколько неприятных вопросов без скидок на оптимизм. Для LLM-фичи это полезнее, чем спорить о паттернах на схемах: проблемы почти всегда всплывают в ожидании, повторах и разборе спорных случаев.
Сначала проверьте ожидание глазами пользователя, а не по логам сервера. Если экран зависает 12 секунд, человеку все равно, что модель думала только 7, а остальные 5 ушли на сеть, ретраи и постобработку. Для чата это часто уже слишком долго. Для генерации отчета или расшифровки звонка - нормально, если интерфейс честно показывает статус.
Потом разберите повторный запрос. Пользователь нажал кнопку еще раз, мобильное приложение перезапустило вызов, gateway сделал retry, worker получил задачу повторно. Если команда не может точно сказать, создаст ли это второй ответ, второе действие или вторую запись в CRM, запускать рано.
Перед релизом полезно проверить пять вещей:
- команда знает, сколько секунд человек реально ждет до первого заметного результата;
- для повторного запроса есть ясное правило: вернуть тот же результат, создать новый или отклонить дубль;
- у каждого запроса есть уникальный идентификатор, который проходит через API, очередь, воркер и клиентский лог;
- логов хватает, чтобы восстановить цепочку: кто отправил запрос, какая модель ответила, был ли retry, что вернулось наружу;
- поддержка может за пару минут объяснить инцидент без созвона с разработкой.
С уникальным идентификатором лучше не экономить. Один request_id, который живет от фронта до воркера, сильно упрощает жизнь. Без него трудно понять, это один долгий запрос, три повтора подряд или смесь обоих случаев.
Для команд с жесткими требованиями к аудиту планка выше. Если LLM влияет на письмо клиенту, внутреннее решение или действие сотрудника, нужен след запроса: входные данные, версия промпта, модель, время, результат фильтров и факт повтора. В российском контексте это особенно важно там, где потом нужно показать историю обработки и хранить логи внутри РФ.
Хороший тест простой. Дайте поддержке один спорный кейс: "пользователь нажал два раза и получил странный ответ". Если они не могут быстро собрать маршрут запроса и объяснить, что произошло, архитектура еще сырая.
Если на любой пункт ответ расплывчатый, не выбирайте режим по привычке. Сначала добавьте idempotency, request_id и нормальные логи. Это дешевле, чем потом ловить дубли, таймауты и жалобы после запуска.
Что делать дальше
Не пытайтесь сразу выбрать один режим для всех LLM-функций. Возьмите один сценарий, где уже есть заметная нагрузка и понятная цена ошибки. Подходящий кандидат - генерация ответа клиенту, разбор обращения или внутренний copilot, где повторный запуск может стоить денег, времени или испортить историю действий.
Дальше соберите простые цифры на реальном трафике. Среднее время почти всегда успокаивает зря. Смотрите p95 и p99: именно там видно, начнет ли синхронный путь раздражать пользователя, а очередь - копить хвост из задач. Если среднее равно 4 секундам, а p99 уходит в 35, для интерфейса это уже совсем другой опыт.
До релиза договоритесь не только о таймауте. Команда должна одинаково понимать, что считается успешным завершением, когда клиенту показывают "в обработке" и в какой момент запрос можно запускать повторно.
Полезно заранее зафиксировать четыре вещи:
- какие статусы видит пользователь и бэкенд;
- по каким ошибкам работает ретрай, а по каким нет;
- как вы предотвращаете повторы одного и того же запроса;
- что попадает в аудит и как маскируются персональные данные.
Если этого нет, проблемы начнутся не в модели, а на стыке API, очереди и поддержки. Один сервис посчитает задачу новой, другой - повторной, а потом будет трудно доказать, кто и когда запустил обработку.
Если команде нужен единый OpenAI-совместимый эндпоинт в РФ, удобно, когда и синхронный путь, и очередь идут через один слой. В случае с RU LLM можно сохранить текущие SDK, код и промпты, поменяв только base_url на api.rullm.com. Это упрощает переход, когда часть запросов нужно отдавать сразу, а часть отправлять в фон, при этом держать логи и бэкапы в РФ и получать audit trail по каждому запросу.
Хороший следующий шаг очень простой: выберите один сценарий, неделю снимайте p95 и p99, затем утвердите статусы, ретраи и правила аудита. После этого решение между синхронным вызовом и очередью обычно становится очевидным без долгих споров.
Часто задаваемые вопросы
Когда синхронный вызов действительно подходит для LLM-фичи?
Берите синхронный вызов, когда человек сидит у экрана и ждет один ответ прямо сейчас. Чат, короткая подсказка, резюме текста или черновик ответа обычно хорошо работают так, если результат почти всегда приходит за несколько секунд.
В каких случаях лучше сразу ставить задачу в очередь?
Очередь лучше там, где задача живет дольше обычного запроса или запускает действие во внешней системе. Если после ответа нужно отправить письмо, создать запись в CRM, обновить статус или пережить ретрай без дублей, очередь обычно дает более спокойную работу.
Сколько времени пользователь готов ждать ответ на экране?
Для чата люди обычно терпят около 2–5 секунд. Если ответ часто уходит дальше 6–8 секунд, пользователь начинает жать кнопку снова или обновлять страницу, и в этот момент синхронный сценарий быстро портит опыт.
Что делать, если пользователь нажал кнопку два раза?
Сначала блокируйте повторный клик в интерфейсе, но не надейтесь только на фронт. На сервере держите один request_id для всего бизнес-шага и возвращайте прежний результат или текущий статус, если клиент прислал тот же запрос еще раз.
Зачем нужен request_id, если и так есть логи?
request_id связывает фронт, API, очередь, вызов модели и запись результата в одну цепочку. Без него трудно понять, это новый запрос или повтор старого, а потом сложно разбирать дубли, таймауты и лишние списания токенов.
Что обязательно писать в аудит по каждому запросу?
Обычно хватает идентификатора запроса, автора запуска, времени старта и конца, версии промпта, модели и итогового статуса. Если запрос может повлиять на деньги, документы или действия сотрудника, добавьте маскированный фрагмент входа, хеш входа и хеш ответа.
Можно ли смешать оба режима в одном процессе?
Да, это часто самый удобный вариант. Черновик ответа можно отдать синхронно, а отправку письма, запись в CRM или смену статуса лучше вынести в очередь и защитить идемпотентностью.
Почему нельзя смотреть только на среднее время ответа?
Среднее время скрывает длинные хвосты. Продукт ломают не быстрые ответы, а те случаи, где один запрос внезапно идет 30 секунд, фронт получает таймаут, а пользователь не понимает, ждать дальше или запускать заново.
Какие статусы лучше показывать пользователю?
Покажите человеку простой и честный статус: запрос принят, идет обработка, готово или нужна проверка. Когда интерфейс молчит, люди сами создают повторы, а потом команда тратит время на разбор дублей и спорных действий.
Как внедрить это без большого переписывания системы?
Начните с одного сценария, где цена ошибки уже заметна: например, черновик ответа оператору или разбор обращения. Если вы работаете через единый OpenAI-совместимый слой вроде RU LLM, можно оставить текущие SDK и код, а решение о синхронном режиме или очереди принять на уровне продукта для каждого шага отдельно.