Смена требований комплаенса в LLM без остановки фичи
Смена требований комплаенса не должна останавливать LLM-фичу. Покажем, как вынести маршрутизацию, хранение и маскирование в конфиг и менять правила без правок кода.
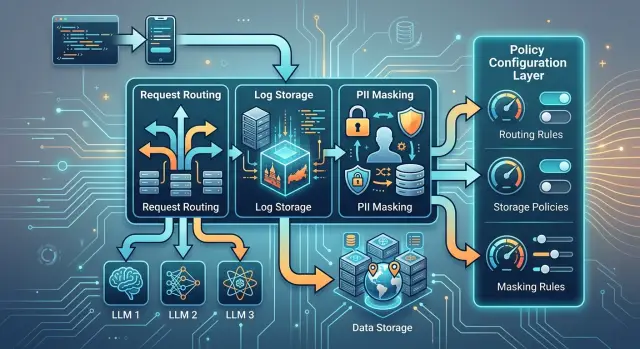
Почему новое требование стопорит LLM-фичу
Готовая LLM-фича редко останавливается из-за одного большого запрета. Чаще ее блокирует новое правило в неудобном месте. Например, чат-ассистент банка уже помогает операторам, а потом комплаенс говорит: запросы с паспортными данными нельзя отправлять внешним провайдерам, а логи с такими полями нужно хранить только в РФ и только после маскирования.
Вчера сценарий работал нормально. Сегодня его уже нельзя запускать без правок. И почти никогда это не касается только одного слоя.
Обычно сразу расходятся три вещи: маршрут запроса к модели, способ записи логов и срок их хранения, а еще системный промпт и правила маскирования PII.
Если эти решения живут в разных местах, команда быстро упирается в длинную цепочку согласований и релизов. Бэкенд меняет маршрутизацию. ML-инженер правит промпт. Безопасность проверяет, не уходят ли лишние поля в логи. Юристы и комплаенс смотрят, соответствует ли хранение новым требованиям. Потом начинается регрессия, потому что даже маленькая правка в LLM-пайплайне легко ломает тон ответа, формат JSON или обработку ошибок.
Поэтому смена требований выглядит как авария, хотя сама фича может быть стабильной. Бизнес задает простой вопрос: почему нельзя вернуть функцию за день? Ответ обычно такой: потому что политика вшита в продукт, а не отделена от него.
Особенно тяжело, когда правила уже размазаны по коду. Один сервис решает, в какую модель идти. Другой пишет сырые логи. Третий маскирует PII регулярками. А промпт еще и дублирует часть ограничений фразами вроде "не повторяй номер карты целиком". Тогда новое требование ломает не один сценарий, а всю связку сразу.
Если команда использует OpenAI-совместимый шлюз, часть таких изменений удобно держать ближе к маршрутизации, маскированию и логам. Но это помогает только в одном случае: правила не спрятаны в приложении.
Вопрос на самом деле один: где живет политика? Если ответ такой - в коде, в промпте и еще немного в настройках каждого сервиса, остановка почти неизбежна.
Что держать в конфиге, а не в коде
Когда комплаенс меняет правило вечером, команда не должна ночью править ветки if/else, промпты и ретраи. Код должен решать продуктовую задачу, а правила доступа, маршрутизации и хранения лучше вынести в конфиг, который читает шлюз и сервисы вокруг него.
Обычно меняется не сама фича, а условия ее работы: какой запрос куда можно отправить, что нужно скрыть перед отправкой и сколько хранить следы. Если это зашито в коде, любой новый запрет превращается в релиз. Если это лежит в конфиге, вы меняете политику за минуты.
В конфиг обычно стоит вынести пять вещей. Первая - список разрешенных моделей и провайдеров для каждого сценария. Внутренний поиск может идти в один пул моделей, а клиентский чат - только в маршруты, которые одобрила ИБ. Вторая - правила выбора маршрута по типу данных. Текст без персональных данных можно отправлять шире, а запросы с паспортом, телефоном или номером договора - только через российский контур. Третья - сроки хранения логов и бэкапов. Для одного сценария хватит короткого окна, для другого нужен более длинный срок для аудита и разбора инцидентов. Четвертая - маскирование PII до отправки запроса. Это не часть промпта и не задача фронтенда. Политика должна явно задавать, какие поля скрывать, чем заменять и в каких журналах хранить уже очищенную версию. Пятая - флаги экстренного отключения маршрутов. Если провайдер перестал проходить проверку или юристы ввели временный запрет, маршрут нужно выключать конфигом, без правки бизнес-логики.
Рабочее правило простое: разработчик пишет один вызов модели, а конфиг решает, какая модель доступна, можно ли отправлять туда этот тип данных и что сохранить после ответа. Так меньше шансов, что команда забудет обновить старый cron, тестовый сервис или один из промптов.
Если у вас есть OpenAI-совместимый шлюз вроде RU LLM, этот слой особенно удобен. Приложение продолжает работать через тот же SDK и тот же формат запросов, а политики маршрутизации, хранение логов в РФ и маскирование PII меняются отдельно от кода.
Где проходит граница между кодом, промптом и политикой
Когда у команды смешаны код, промпты и правила комплаенса, любая правка бьет по всей фиче сразу. Юрист просит хранить логи только в РФ, безопасник требует маскировать паспортные данные, а разработчик лезет в шаблоны промптов и бизнес-логику, хотя проблема не там.
Разделение здесь довольно простое. Код отвечает за то, что делает продукт: принимает запрос, собирает контекст, вызывает модель, показывает ответ пользователю. Промпт объясняет модели задачу: каким тоном отвечать, что проверять, в каком формате вернуть результат. Политика живет отдельно. Она решает, можно ли отправлять этот запрос внешнему провайдеру, какие поля нужно замаскировать, сколько хранить логи и где именно их держать.
Коротко граница выглядит так:
- код знает сценарий продукта;
- промпт знает, что модель должна сделать;
- конфиг знает, куда можно отправлять данные и что с ними делать до и после вызова;
- политику можно менять без правки приложения.
Проблемы начинаются, когда комплаенс-прavила прячут в тексте промпта. Например, команда дописывает в шаблон что-то вроде "не используй персональные данные" и считает вопрос закрытым. Но промпт не контролирует маршрут запроса, не управляет логами и не гарантирует маскирование. Он только просит модель вести себя определенным образом.
Из-за этого любое новое требование превращается в дорогую правку. Нужно искать шаблоны, проверять ветки кода, заново гонять тесты и надеяться, что старый сервис нигде не отправит лишнее поле. Такой подход обычно ломается первым же новым регламентом.
Гораздо надежнее держать правила в конфиге рядом с маршрутизацией, хранением логов и сроками хранения. Тогда команда меняет политику для класса запросов, а не переписывает фичу. Код продукта при этом может вообще не меняться.
Как собрать слой политик по шагам
Когда приходит новое требование, команда часто сразу лезет в код, промпты и таблицы логов. Это почти всегда сбивает темп релизов. Лучше собрать отдельный слой правил в конфиге, чтобы приложение читало политику на каждом запросе и меняло поведение без новой сборки.
Сначала опишите классы данных. В начале обычно хватает трех: публичные, внутренние и ПДн. Усложнять схему сразу не стоит. Если запрос идет по базе знаний с открытыми материалами, это один класс. Если в тексте есть номер телефона, договор или паспортные данные, это уже другой класс, и маршрут для него должен быть строже.
Дальше привяжите к каждому классу список разрешенных моделей и провайдеров. Для публичных данных выбор шире. Для внутренних - уже. Для ПДн лучше оставить только те маршруты, где вы контролируете хранение, аудит и размещение логов в РФ. Если у вас есть OpenAI-совместимый шлюз, приложение может продолжать отправлять запросы в один эндпоинт, а правила выбора модели будут жить отдельно.
После этого задайте маскирование PII до вызова модели. Не надейтесь на промпт с просьбой "не использовать персональные данные". Система должна сама заменить ФИО, телефоны, номера карт, адреса и другие поля на маркеры еще до отправки текста. Если бизнес-процесс требует вернуть исходные значения, таблицу подстановки лучше хранить отдельно и недолго.
Затем вынесите в конфиг логику хранения логов. Решите, что именно вы пишете: полный текст, маскированный текст, хэш промпта, выбранную модель, провайдера, результат проверки политики. Срок жизни записей тоже задайте по классам данных. Полный лог на 90 дней нужен нечасто. Для многих сценариев хватает аудиторного следа без исходного текста.
В каждый запрос добавьте версию политики. Это простое поле часто экономит часы при разборе инцидента. Вы сразу видите, по каким правилам прошел конкретный ответ, и не спорите о том, какая конфигурация действовала в момент вызова.
Откат проверьте заранее. Новую политику держите рядом со старой и переключайте одним флагом. Если фильтр начал резать лишнее или маршрутизация слишком выросла в цене, команда вернет прошлую версию за минуту, без правок в коде и без паузы для LLM-фичи.
Хороший признак зрелой схемы простой: комплаенс меняет правило, а команда правит конфиг, а не приложение.
Пример с банковским чат-ассистентом
Банковский чат-ассистент каждый день принимает обращения клиентов: не проходит платеж, заблокировалась карта, не приходит код входа. В таких сообщениях люди почти всегда пишут ФИО, телефон и другие персональные данные. Новое требование в такой точке сразу бьет по продукту, безопасности и срокам.
Представим простую ситуацию. Юристы говорят: с этого дня нельзя отправлять ФИО и номер телефона во внешнюю модель без маскирования. Если правило сидит в SDK или прямо в промпте, команда лезет в код, гоняет тесты, выпускает новую версию и боится задеть рабочий сценарий. Для чат-фичи это плохой путь. Даже маленькая правка легко тянет лишний релиз.
Когда маскирование PII и политики маршрутизации лежат в конфиге, все выглядит спокойнее. Команда меняет правило один раз в слое политик, а не переписывает приложение. Сам диалог, шаблоны ответов и интеграции остаются прежними.
В рабочем потоке это выглядит так:
- клиент пишет: "Меня зовут Иван Петров, мой номер +7 999 123-45-67, не могу войти в приложение";
- слой политик маскирует имя и телефон до отправки запроса в модель;
- запрос с меткой ПДн идет только в разрешенные модели;
- логи и бэкапы остаются в российском контуре.
Фича при этом не останавливается. Ассистент продолжает отвечать, потому что промпты не менялись. Команда не трогает клиентский код и не переделывает SDK. Она просто обновляет конфиг и публикует новое правило.
Для такой схемы удобен единый шлюз между приложением и провайдерами. Например, в RU LLM можно держать маршрутизацию запросов, маскирование PII и хранение следов внутри российского контура, а приложение продолжит работать через OpenAI-совместимый API. Для команды это заметная разница: вместо срочного рефакторинга она меняет политику и сразу видит, что персональные данные идут только по разрешенному пути.
Такой пример хорошо показывает границу ответственности. Код отвечает за продуктовую логику, промпт - за поведение ассистента, а правила комплаенса живут отдельно и меняются без остановки сервиса.
Частые ошибки
Проблемы обычно начинаются не в день новой проверки, а намного раньше. Команда понемногу раскладывает правила по разным местам: часть уходит в код сервиса, часть - в системный промпт, часть - в конфиг шлюза, а что-то вообще остается в wiki. Когда приходит новое требование, никто уже не понимает, где именно нужно править поведение.
Самая дорогая ошибка - дублировать одно и то же правило в нескольких слоях. Например, сервис сам запрещает часть моделей, системный промпт просит не отправлять персональные данные, а шлюз еще и отдельно включает маскирование PII. На бумаге это выглядит надежно. На практике одно правило обновили, два забыли, и поведение разъехалось.
Не лучше и другая крайность, когда требования комплаенса смешивают с бизнес-логикой. Если код выбора ответа одновременно решает, какой тариф показать пользователю, какую модель вызвать и что можно писать в лог, менять такие правила тяжело. Любая правка тянет релиз сервиса, регрессию и новые согласования.
Список разрешенных моделей тоже часто кладут не туда. Сегодня он живет в одном файле, завтра его копируют в другой сервис, а через месяц он уже не совпадает с реальной политикой. Для команды с разными маршрутами, требованиями к хранению логов в РФ и запасными провайдерами это почти гарантированный источник ошибок.
Еще одна частая проблема - отсутствие версий у правил. Маскирование PII и сроки хранения логов меняются чаще, чем кажется. Если команда не версионирует эти настройки, потом трудно ответить на простой вопрос: почему запрос от 15 марта обработался так, а похожий запрос от 2 апреля уже иначе.
В банке это выглядит очень приземленно. Чат-ассистент вчера отправлял обращения клиентов на один набор моделей и хранил техлоги 30 дней. Сегодня юристы требуют другой срок хранения и более жесткое маскирование полей с паспортными данными. Если правила сидят в коде, фича встает до релиза. Если правила лежат в конфиге, команда меняет политику, прогоняет проверки и не ломает продукт.
Еще одна ошибка - смотреть только на финальный лог после маскирования. Проверять нужно оба этапа: что система успела записать до очистки и что осталось после нее. Утечки часто живут именно в промежуточных логах, трассировке SDK или отладочных событиях.
Обычно хватает нескольких дисциплин: держать правила маршрутизации, сроков хранения и маскирования в одном конфиге, хранить версии политик рядом с датой ввода, проверять сырые и итоговые логи и не зашивать список моделей в код сервиса. Если команда не делает этого с самого начала, любое новое требование быстро превращается в ручной аварийный ремонт.
Как не потерять историю изменений
Когда комплаенс меняет правило, проблема часто не в самом изменении, а в памяти команды. Через две недели уже трудно ответить, какой маршрут работал для запроса, какая версия маскирования действовала и почему вообще включили этот флаг.
Поэтому у каждой политики должен быть свой policy_version_id. Добавляйте его в каждый вызов рядом с идентификатором модели, провайдера и среды. Тогда по любому инциденту можно быстро восстановить точную картину: какой запрос ушел в прод, по какому правилу его обработала система и что увидел пользователь.
Без этого команды спорят по логам и скриншотам. С этим спор обычно заканчивается быстро.
Полезно хранить рядом с версией политики короткий набор полей:
- кто внес изменение;
- когда его включили;
- почему его приняли;
- какой риск или требование оно закрывает;
- на что оно влияет: маршрут, логи, маскирование, ретраи.
Причину лучше писать обычным языком, без канцелярита. Например, "Новый запрет на передачу незамаскированных ФИО во внешние модели" намного понятнее, чем абстрактное "актуализация правил обработки данных". Через месяц такая запись сэкономит часы.
Старые версии лучше не удалять. Храните их так, чтобы команда могла откатиться за несколько минут, а не собирать прошлое состояние по кускам. Если новая политика случайно отправила часть запросов не туда или стала слишком агрессивно резать полезный контекст, быстрый откат спасет фичу без ночного релиза.
Аудит-трейл нужно сверять не только с конфигом, но и с фактическим маршрутом. В конфиге может стоять один провайдер, а в реальности фолбэк, кэш или ручное исключение увели запрос в другой путь. Если след в журнале не совпадает с реальным маршрутом, аудит теряет смысл.
Отдельная проверка нужна для маскирования PII. Система должна сначала замаскировать данные, а уже потом писать лог, бэкап или событие в мониторинг. Иначе в журнал попадет именно то, что политика пыталась скрыть.
В шлюзе это особенно удобно, когда версия политики, маршрут запроса и статус маскирования живут рядом в одном следе. Для команд, которые работают в РФ и хранят логи на российских серверах, это заметно упрощает разбор спорных случаев и откат после срочного требования.
Быстрый чек перед выкладкой
Перед выкладкой проверьте не только ответ модели, но и весь путь данных. При изменении требований чаще всего ломается не сама LLM-фича, а маршрут запроса, хранение логов и правила маскирования.
Хороший признак - новый режим включается одним параметром в конфиге, а не правкой кода в трех сервисах. Например, команда меняет policy_version или provider_group, прогоняет короткий тестовый набор и сразу видит, что запросы пошли по новому правилу. Если для этого нужен релиз приложения, значит политика все еще живет не там, где должна.
Перед продом полезно пройти короткий чек:
- у нового маршрута есть явный идентификатор версии, и команда знает, какой параметр его включает;
- тест с реальными ПДн-полями подтверждает, что запрещенный провайдер не получает исходные email, телефон и ФИО;
- логи и бэкапы уходят в нужное хранилище, а не остаются в старом контуре;
- маскирование срабатывает до отправки запроса наружу, а не только при записи в лог;
- откат на прошлую политику занимает несколько минут и не требует срочного патча.
Отдельно проверьте порядок шагов. Частая ошибка простая: команда смотрит на замаскированный лог и думает, что все чисто, хотя до провайдера уже ушли сырые данные. Нужна проверка на уровне трассы запроса или аудит-трейла, где видно, что именно система отправила наружу.
Если вы работаете через OpenAI-совместимый шлюз, такой тест удобно делать на одном и том же SDK без переписывания клиента. Это убирает лишний шум: вы меняете политику маршрутизации, а не поведение приложения.
Если каждый пункт проходит, выкладка становится рутиной. Если хотя бы один пункт проверить сложно, лучше остановиться и вернуть правило в конфиг. Потом это сэкономит не часы, а целый инцидент.
Что сделать дальше
Новые требования редко ломают саму LLM-фичу. Чаще ломается способ, которым команда спрятала правила: часть в коде, часть в системном промпте, часть в голове у разработчика. Поэтому первый шаг простой: соберите все такие места в один список и отметьте, что именно там зашито - выбор модели, запрет на внешнего провайдера, маскирование PII, срок хранения логов, включение аудита.
Обычно хватает одного короткого прохода по репозиторию и промптам. Ищите условные ветки, env-переменные с неясным смыслом, шаблоны промптов с фразами про редактирование персональных данных и любые ручные исключения. Если правило нельзя поменять без релиза, это уже кандидат на вынос в конфиг.
Не пытайтесь вынести все сразу. Возьмите один сценарий с самыми жесткими требованиями. Часто это обработка запросов с персональными данными или внутренний чат для сотрудников. Перенесите для него три вещи: маршрут до разрешенных моделей и провайдеров, правила логирования и срок хранения, а еще маскирование PII до записи логов и трассировок.
После этого добавьте прикладные тесты. Проверяйте, какой маршрут выбирается для запроса с ПДн, что попадает в лог, какие поля маскируются и что происходит при смене политики на лету. Хороший тест здесь экономит не абстрактное время, а ночной инцидент, когда дежурный не понимает, можно ли оставить трафик на текущем провайдере.
План отката тоже нужен заранее. Он должен укладываться в пару шагов: вернуть прошлую версию конфига, переключить маршрут на запасной профиль, отключить запись чувствительных полей, проверить контрольный запрос. Если для отката нужен деплой, план слабый.
Если вам нужен единый OpenAI-совместимый шлюз в РФ, можно посмотреть на RU LLM. У него OpenRouter-совместимый прокси и единый OpenAI-совместимый эндпоинт, а хранение логов и бэкапов в РФ, маскирование PII и аудит-трейлы вынесены на уровень API-шлюза. Для многих команд это проще, чем держать такие правила в каждом сервисе по отдельности и менять код при каждом новом требовании.
Часто задаваемые вопросы
Почему комплаенс может внезапно остановить уже работающую LLM-фичу?
Потому что новое правило обычно бьет сразу по трем местам: куда идет запрос, что пишется в логи и как скрываются персональные данные. Если эти правила сидят в коде, промптах и настройках разных сервисов, любая правка превращается в цепочку релизов и проверок.
Что именно стоит хранить в конфиге, а не в коде?
В конфиг лучше вынести разрешенные модели и провайдеров, правила маршрутизации по типу данных, маскирование PII, сроки хранения логов и аварийное отключение маршрутов. Тогда команда меняет политику отдельно от продуктовой логики.
Как разделить код, промпт и политику без путаницы?
Код отвечает за сценарий продукта: принять запрос, собрать контекст и показать ответ. Промпт объясняет модели задачу и формат ответа. Политика решает, можно ли отправлять данные в этот маршрут, что скрыть до вызова и что сохранить после него.
С чего начать, если у нас пока нет слоя политик?
Обычно хватает трех классов: публичные данные, внутренние данные и ПДн. Этого достаточно, чтобы быстро настроить разные маршруты, логи и сроки хранения, не усложняя схему в первый же день.
Можно ли решить вопрос с персональными данными только промптом?
Нет, на промпт тут лучше не надеяться. Он может попросить модель не повторять чувствительные поля, но не управляет маршрутом запроса, логами и бэкапами. Скрывать PII нужно до отправки текста в модель и до записи в журналы.
Что логировать, чтобы не создать новую проблему?
Минимум такой: версия политики, выбранная модель, провайдер, класс данных и результат проверки правил. Полный текст нужен не всегда. Во многих сценариях хватает маскированного лога и аудиторного следа без исходных данных.
Зачем добавлять policy_version в каждый запрос?
Версия политики сразу показывает, по каким правилам прошел конкретный запрос. Без нее команда потом спорит, какая конфигурация действовала в момент вызова и почему похожие запросы обработались по-разному.
Как безопасно выкатить новое правило перед продом?
Сначала проверьте, что маскирование срабатывает до отправки наружу, а не только при записи в лог. Потом убедитесь, что новый маршрут реально выбрался, логи ушли в нужное хранилище и откат на прошлую политику занимает минуты, а не требует деплоя.
Какие ошибки встречаются чаще всего?
Часто команды дублируют одно и то же правило в коде, промпте и шлюзе. Еще одна ошибка — не проверять промежуточные логи и трассировки. Тогда итоговый лог уже чистый, а сырые данные успели попасть в SDK-события или техжурналы.
Поможет ли OpenAI-совместимый шлюз менять правила без правок приложения?
Да, если шлюз берет на себя маршрутизацию, маскирование и логи, а приложение продолжает ходить в один OpenAI-совместимый эндпоинт. В таком варианте команда меняет политику на уровне шлюза и не трогает клиентский код без нужды.