Аварийное переключение LLM: схема для критичных сценариев
Аварийное переключение LLM помогает пережить сбой провайдера: разберем запасные модели, circuit breaker, правила деградации и порядок внедрения.
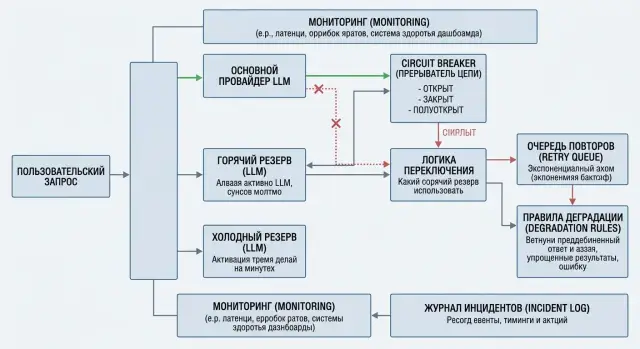
Почему один сбой останавливает весь сервис
Проблема редко в самой модели. Обычно ломается вся цепочка вокруг нее: один base_url, один провайдер, один набор лимитов и один путь до внешнего API. Пока все спокойно, это выглядит удобно. Когда начинаются сбои, такая схема быстро превращается в единую точку отказа.
Первыми обычно приходят таймауты. Запрос не завершился вовремя, приложение ждет, воркеры зависают, очередь растет. Через несколько минут страдает уже не только LLM-вызов. Чат не отвечает, оператор не видит подсказку, CRM не получает итог разговора. Один сбой начинает тянуть за собой соседние функции.
С ошибками 429 ситуация еще неприятнее. Провайдер жив, но ваш трафик больше не принимает. Если сервис без разбора повторяет запросы, он сам разгоняет нагрузку и доедает остаток лимита. Ошибки 5xx особенно болезненны в синхронных сценариях: пользователь уже ждет ответ, а система не может ни завершить действие, ни быстро уйти на запасной путь.
Один base_url опасен не только из-за падения провайдера. Сбой может случиться на DNS, в сети, в авторизации, биллинге, лимитах или в отдельном регионе. Если приложение жестко привязано к одному endpoint, переключение в аварии превращается в ручную работу прямо во время инцидента.
Есть процессы, которые нельзя просто поставить на паузу. Это подсказки оператору контакт-центра во время звонка, классификация обращений, проверка пользовательского ввода перед следующим шагом, поиск по базе знаний для первой линии поддержки, обязательные шаги во fraud- и compliance-потоках. В таких сценариях простой быстро становится заметен бизнесу.
Недоступность и просадку качества лучше разделять. Недоступность - это когда ответ не пришел, пришел слишком поздно или API вернул ошибку. Просадка качества - это когда ответ есть, но он слабее: менее точный, хуже держит формат, режет важные детали. Реакция в этих двух случаях разная. Если переключать трафик при каждом неидеальном ответе, система начнет метаться между моделями. Если не переключать вообще, один сбой остановит весь сервис.
Для команд в РФ риск выше, если важны локальные требования к логам, биллингу и обработке данных. Поэтому между приложением и внешними моделями часто ставят отдельный совместимый шлюз. Он позволяет менять маршрут запроса без переписывания клиента и не держать весь сервис на одном внешнем канале.
Когда сбой становится аварией
Авария начинается не после одной ошибки, а тогда, когда маршрут перестает держать нужный уровень ответа. Один таймаут сам по себе ничего не доказывает: сеть могла дернуться, провайдер мог кратко просесть, клиент мог закрыть соединение раньше времени. Если переключать весь трафик из-за каждого такого случая, вы получите скачки, а не отказоустойчивость.
Обычно работает короткое окно наблюдения - 30 или 60 секунд - и минимальный объем запросов. Простое правило такое: аварийный режим включается, если за окно накопилось достаточно запросов, например 20-50, и доля технических ошибок превысила порог. Для интерактивных сценариев часто хватает 3-5% на таймауты, 5xx и обрывы соединения. Если трафика мало, разумнее дождаться второго окна подряд, а не дергать переключение сразу.
Задержку считайте отдельно. Провайдер может отвечать формально успешно, но так медленно, что пользователь уже ушел. Для онлайн-сценариев полезнее следить за p95 или p99, чем за средним временем. Если p95 держится выше 6-8 секунд два окна подряд, это уже повод увести часть трафика на резерв, даже если статус ответа - 200.
Есть и тихие поломки. Их часто пропускают, потому что сеть и HTTP выглядят нормально. В метрику аварии стоит включать пустой текст при успешном статусе, битый JSON, сломанный function calling, обрезанный ответ, который нельзя разобрать, и ответы без обязательных полей схемы. Для автоматических цепочек такие сбои даже опаснее обычных 5xx: следующий сервис ждет строгий формат и ломается уже на своей стороне.
Сетевые и бизнес-ошибки лучше не смешивать. Таймаут, DNS-сбой, 502, 503, reset соединения и резкий рост задержки часто говорят, что маршрут пора отключать. А вот 400, слишком длинный контекст, неверная схема инструмента или блокировка по политике провайдера обычно означают проблему в самом запросе. Запасная модель это не исправит.
Рабочее правило простое: аварией считайте повторяемый технический сбой или заметную деградацию скорости в коротком окне, подтвержденную достаточным числом запросов. Все остальное сначала разбирайте как обычную ошибку приложения.
Как собрать основную и запасные модели
Одну модель почти никогда не стоит ставить в центр критичного сценария. Для продакшена лучше собрать небольшой набор: основная модель, горячий резерв и холодный резерв на случай длинной аварии. Такой набор дает не только запас по доступности, но и более спокойное переключение без ручной суеты.
Основную модель выбирайте не по общим рейтингам, а по своей задаче. Если сервис отвечает клиентам, меряйте точность на реальных диалогах. Если модель заполняет карточки, смотрите, как часто она ломает JSON, путает поля и добавляет лишний текст. Нередко модель, которая выглядит слабее на бенчмарках, ведет себя стабильнее в конкретном процессе. Для продакшена это часто важнее.
Горячий резерв должен быть максимально похож на основную модель по поведению. Он не обязан отвечать так же хорошо, но должен сохранять форму результата, длину ответа и стиль вызова API. Если основная модель возвращает строгий JSON, резерв тоже должен держать JSON без пояснений вокруг. Иначе вы переживете сбой провайдера, но сломаете свой пайплайн.
Перед запуском проверьте хотя бы четыре вещи: тот же формат ответа, близкую длину контекста, похожую работу с tool calling или structured output и приемлемую задержку под вашей нагрузкой.
Холодный резерв нужен для длинной аварии. Это может быть более дешевая модель, локально размещенная open-weight модель или вариант в российском ЦОДе, если внешний провайдер недоступен часами. Качество такого резерва может быть ниже, но он должен закрывать базовый сценарий без полной остановки сервиса.
Не стоит группировать модели только по цене. Намного надежнее разводить их по типам задач. Для извлечения полей из документов нужен один набор. Для чата с клиентом - другой. Для модерации и классификации - третий. Одна и та же запасная модель редко одинаково хорошо спасает все маршруты.
Ограничения по данным нужно проверить до запуска, а не в день аварии. Если в запросах есть персональные данные, сразу зафиксируйте, какие модели и провайдеры допустимы по 152-ФЗ, где хранятся логи и бэкапы и можно ли вообще отправлять такие запросы за пределы РФ. Здесь удобно иметь единый OpenAI-совместимый шлюз. Например, RU LLM позволяет держать несколько маршрутов через один эндпоинт и переключать провайдеров без смены SDK, кода и промптов, а логи и бэкапы при этом остаются в РФ.
Хороший признак рабочей схемы простой: при замене основной модели на резерв сервис теряет часть качества, но не теряет управление.
Как настроить circuit breaker
Circuit breaker лучше считать не для всего LLM-сервиса сразу, а для каждого маршрута отдельно. Нормальное правило - один контур на связку "модель + провайдер + регион". Если смешать в одном контуре две модели или два региона, можно случайно отключить рабочий запасной путь из-за чужих ошибок.
На практике это означает простую вещь: запросы к одной модели у провайдера A живут в своем контуре, а та же модель у провайдера B - в другом. Даже если снаружи у вас один совместимый endpoint, внутри маршрутизатора контуры лучше хранить раздельно. Тогда сбой на одном плече не тянет вниз остальные.
Открывать контур после одного сбоя почти всегда вредно. У LLM регулярно бывают короткие таймауты, редкие 5xx и сетевые всплески. Если реагировать на каждый такой случай, переключение начнет дергаться, а задержка вырастет сильнее, чем от самой ошибки.
Обычно хватает серии сигналов за короткое окно. Например, 5-10 неуспешных запросов подряд, либо доля ошибок выше порога, скажем 30-50% за 30-60 секунд. Для таймаутов часто ставят отдельный порог, потому что для пользователя они больнее. Ошибки 429 тоже стоит считать отдельно: если провайдер режет лимиты, вы хотите быстрее увести трафик в сторону, а не ждать общей деградации.
Когда контур открылся, не возвращайте на него весь поток сразу. Сначала дайте малую пробу: 5% трафика или один тестовый запрос раз в несколько секунд. Это режим half-open. Если ответы снова нормальные, порцию можно поднять до 10%, потом до 25%, и только потом вернуть обычный вес.
Закрывать контур тоже не стоит по одному удачному ответу. Один успешный вызов ничего не доказывает. Лучше требовать серию, например 10-20 подряд успешных запросов без роста задержки и без 5xx. Если маршрут отвечает, но вдруг стал в три раза медленнее, я бы не закрывал контур сразу.
Еще одна частая ошибка - смешивать в одном breaker бизнес-критичные и обычные вызовы. Короткий запрос на классификацию и длинная генерация письма ведут себя по-разному. Для критичных сценариев держите свои пороги, более короткие таймауты и более жесткое открытие контура. Тогда резерв включится раньше, а пользователи не будут ждать по 40 секунд, пока система "проверит еще раз".
Как деградировать без хаоса
Во время сбоя хуже всего делать вид, что ничего не случилось. Слабая или перегруженная модель часто дает длинный, уверенный и неточный ответ. Поэтому при переключении нужно менять не только маршрут, но и сам режим работы.
Профиль деградации лучше задавать не для модели, а для действия: поиск ответа, суммаризация, классификация, автодействие. Тогда система не спорит сама с собой в момент аварии, когда основной провайдер упал, а резерв медленнее и хуже держит длинный контекст.
Обычно первым делом сокращают max_tokens и размер контекста. Для многих задач это почти не бьет по качеству, зато сразу снижает задержку и стоимость аварийного режима. Следом отключают все, без чего можно прожить несколько минут или часов: вызовы инструментов, длинные цепочки промптов, повторные self-check запросы, расширенный поиск по нескольким источникам.
Если ответ нужен пользователю прямо сейчас, лучше перевести его в короткий шаблон. Не свободный текст на абзац, а 2-3 поля с фиксированной структурой: статус, причина, следующий шаг. Автодействия имеет смысл оставлять только там, где риск низкий. Простой тег для обращения - да. Изменение лимита, отправка юридически значимого текста или списание денег - нет.
Все спорные случаи лучше сразу отправлять на ручную проверку. Если резервная модель не проходит заранее заданный потолок риска, она может только советовать человеку, но не действовать сама. Это особенно полезно в сценариях, где LLM что-то подтверждает, классифицирует или влияет на деньги.
Хорошее правило такое: в режиме деградации система делает меньше, но делает это предсказуемо. Если правило нельзя объяснить оператору одной фразой, его почти наверняка стоит упростить до запуска.
Порядок переключения по шагам
Когда падает провайдер, хуже всего метаться между ретраями, ручными правками и срочными патчами. Переключение должно идти по одному и тому же сценарию.
- Сначала система определяет тип сбоя. Таймаут, всплеск 5xx, пустой ответ, сломанная JSON-схема и резкое падение качества - это разные случаи, и у каждого должен быть свой порог.
- Потом она делает только один быстрый повтор. Этого обычно хватает, чтобы пережить короткий сетевой сбой, но не устроить шторм из повторных запросов. Пауза должна быть маленькой, с джиттером, например 200-400 мс.
- Если повтор не помог, сервис открывает
circuit breakerдля проблемного маршрута. После этого новые запросы туда не идут 30-60 секунд. Так вы не тратите лимиты и не добиваете уже нестабильный канал. - Дальше трафик уходит на горячий резерв. Лучше переводить его ступенями: сначала 10%, затем 50%, потом весь поток, если схема ответа проходит валидацию и ошибки не растут.
- После восстановления основную модель тоже возвращают постепенно: 5%, 25%, 50% и только потом 100%.
На каждом шаге смотрите не только на доступность. Проверяйте формат ответа, длину, наличие обязательных полей, долю отказов по guardrails и простую бизнес-метрику. Для контакт-центра это может быть доля подсказок, которые оператор не переписывает вручную.
Если маршрутизация собрана в одном слое, поддерживать такой сценарий проще. Команда меняет правила в общей точке входа, а не переписывает каждый сервис отдельно.
Пример: банковский контакт-центр
Представьте вечер пятницы в банковском контакт-центре. Клиенты звонят из-за спорных списаний, лимитов и блокировки карты. Основная LLM здесь не отвечает клиенту напрямую, а помогает оператору: подсказывает, что спросить, какой сценарий открыть и какой следующий шаг предложить.
Пока модель работает нормально, оператор видит живую подсказку по диалогу. Это ускоряет разговор и помогает не пропустить проверку личности. Но если модель начинает тормозить, ошибаться или отдавать 5xx, линия не должна зависнуть вместе с очередью звонков.
В такой схеме circuit breaker нужен буквально как предохранитель. Как только система видит серию таймаутов или рост ошибок выше порога, она перестает слать трафик в основную модель и переводит поток на резерв. Резервная модель проще: она не пишет длинный текст, а только определяет интент и риск. Этого уже хватает, чтобы линия не остановилась.
Интерфейс оператора в аварийном режиме тоже меняется. Вместо свободной подсказки он получает короткий шаблон: проверить ФИО и кодовое слово, уточнить время последней операции, предложить временную блокировку карты, передать кейс старшему специалисту. Такой ответ беднее обычного, но он лучше тишины или случайной генерации.
Отдельно стоит обработать запросы с высоким риском. Если клиент просит срочно заблокировать карту, сообщает о взломе личного кабинета или о подозрительном переводе, система не должна полагаться даже на резервную классификацию как на финальное решение. Она сразу помечает кейс для ручной проверки и отправляет его специалисту по fraud или старшему оператору.
После восстановления основной маршрут тоже нельзя включать разом. Сначала дайте ему 10% звонков, потом 25%, потом половину. Смотрите на задержку, долю ошибок и расхождение с резервной классификацией. Для контакт-центра это практичная схема: в обычном режиме вы получаете скорость и качество, в аварийном - сохраняете управляемость, а рискованные случаи все равно остаются под контролем человека.
Почему резерв не срабатывает
Резерв ломается не в момент аварии, а намного раньше. Часто команда думает, что запасной путь уже готов, потому что в конфиге есть вторая и третья модель. Но при первом серьезном сбое выясняется, что все эти варианты завязаны на один и тот же лимит, один аккаунт или вообще на одного поставщика под разными названиями.
Если у основного и резервного маршрута общий rate limit, общий биллинг или одна организация у провайдера, авария бьет сразу по всем веткам. На бумаге есть отказоустойчивая схема, а в реальности - один общий рубильник.
Вторая типичная проблема - резервные модели никто толком не гонял на ваших промптах. Команда проверила, что модель "отвечает", и успокоилась. В проде выясняется, что одна модель держит формат, а другая пишет лишний текст, меняет поля местами или режет длинный контекст.
Особенно больно это бьет по JSON-ответам. Если сервис ждет строгую схему для классификации заявки, извлечения реквизитов или подсказки оператору, любая несовместимость ломает пайплайн. Резерв должен проходить те же тесты, что и основная модель: на ваших промптах, на ваших примерах и на ваших схемах. Минимальная проверка проста: JSON валидируется без ручной правки, обязательные поля и типы совпадают, модель не добавляет пояснения вне схемы, длина ответа остается в нужных пределах, а качество не проседает на частых реальных запросах.
Еще одна проблема - слишком ранний возврат трафика после сбоя. Провайдер на минуту ожил, метрика немного улучшилась, и сервис сразу включает его обратно. Через две минуты он снова падает, и система начинает качаться туда-сюда. Пользователи видят скачки качества, а команда получает шум вместо понятной картины.
Есть и более приземленная вещь: логи не показывают, где именно все сломалось. Если в трассировке нет этапов "маршрутизация -> вызов провайдера -> валидация схемы -> ретрай -> переключение", команда видит только общий 500 и гадает, кто виноват. Без таких логов невозможно быстро понять, упал провайдер, сломался парсер JSON или сработало неверное правило деградации.
Хороший резерв - это не список запасных моделей. Это проверенные маршруты, разные лимиты, строгая валидация и логи, по которым инженер находит место сбоя за несколько минут.
Что проверить перед запуском
Перед релизом смотрите не только на красивую диаграмму, но и на поведение сервиса под нагрузкой и при сбоях. Переключение ломается не на идеальном стенде, а в тот момент, когда основная модель отвечает медленно, а резерв формально жив, но выдает другой формат, хуже качество или неожиданные отказы на боевых запросах.
Перед запуском стоит проверить несколько вещей. У вас должны быть хотя бы два независимых источника модели. Если оба маршрута идут через одного провайдера или один регион, это не резерв. Для каждой функции нужен свой режим деградации: классификация, поиск ответа, суммаризация и генерация письма не должны упрощаться одинаково. Пороги срабатывания нужно записать заранее, а не обсуждать во время инцидента. Например, p95 выше 8 секунд в течение 3 минут, доля 5xx выше 4%, таймауты выше 2%.
Отдельно проверьте совместимость резервных моделей с вашими схемами, инструментами и длиной контекста. И еще один пункт, который часто забывают: трассировка должна ясно показывать, какой маршрут выбрали, был ли ретрай, сработал ли breaker, что вернула валидация схемы и когда трафик ушел на резерв. Без этого расследование затянется.
Если есть возможность, устройте короткое учение до релиза. На несколько минут отключите основной маршрут и посмотрите, как сервис ведет себя под реальной нагрузкой. Такие проверки быстро снимают лишнюю самоуверенность.
Что делать дальше в проде
Не пытайтесь сразу закрыть все сценарии. Начните с одного, где сбой сильнее всего бьет по SLA, деньгам или очереди операторов. Для банка это может быть классификация входящих обращений о блокировке карты. Сразу опишите три состояния: штатная работа, аварийный режим и полный отказ. Если основная модель молчит дольше порога, система идет на запасную. Если не отвечает и она, сервис выдает короткий безопасный шаблон и передает диалог человеку.
После этого соберите одну рабочую таблицу, а не набор заметок в разных местах. В ней должны быть основная и запасные модели для каждого сценария, лимиты по задержке, ошибкам и бюджету, владелец сервиса, владелец маршрутизации и список действий, которые можно оставить в деградации, а что нужно отключать сразу. Такая таблица быстро показывает слабые места. Обычно проблема не в отсутствии резервной модели, а в том, что никто не знает, кто меняет пороги, кто принимает решение о возврате в норму и кто потом смотрит на счет после инцидента.
Заведите журнал инцидентов. После каждого заметного сбоя записывайте не только время и код ошибки, но и то, как сработал circuit breaker, на какую модель ушел трафик, насколько выросла задержка и сколько запросов пришлось отдать в ручную обработку. Без такого разбора одна и та же поломка вернется очень быстро.
Стоимость и качество в аварийном режиме почти всегда меняются сильнее, чем ожидает команда. Дешевая запасная модель может поднять долю ошибок в извлечении фактов, а более сильная резервная модель - заметно увеличить счет. Смотрите не только на цену за токен, а на итог по сценарию: точность маршрутизации, число эскалаций, среднее время ответа, долю сообщений, которые оператор переписал вручную.
Если вам нужен один OpenAI-совместимый вход к нескольким провайдерам и работа внутри РФ, это удобно обкатывать через RU LLM. Такой слой позволяет менять только base_url, проверять маршрутизацию между провайдерами и тестировать резервные модели без переделки клиентского кода. Для российских команд это еще и способ не выносить логи, бэкапы и биллинг за пределы локального контура.
И последнее: устраивайте учебный сбой по расписанию. Раз в месяц отключайте основного провайдера на короткое окно и смотрите, что ломается на самом деле. После пары таких прогонов аварийное переключение перестает быть схемой в вики и становится рабочим механизмом.
Часто задаваемые вопросы
Как понять, что уже пора переключать трафик на резерв?
Смотрите на короткое окно, а не на один неудачный запрос. Если за 30–60 секунд набралось достаточно трафика и доля таймаутов, 5xx или обрывов связи вышла за ваш порог, маршрут уже не держит нагрузку.
Задержку считайте отдельно. Если p95 держится выше 6–8 секунд два окна подряд, для онлайн-сценария этого уже достаточно, чтобы увести часть трафика на резерв, даже если ответы формально идут с кодом 200.
Какие ошибки считать аварией, а какие нет?
Нет. Технические сбои и ошибки самого запроса лучше разделять. Таймауты, DNS-сбои, 502, 503, reset соединения и резкий рост задержки обычно говорят о проблеме на маршруте.
А вот 400, слишком длинный контекст, битая схема инструмента или блокировка по политике провайдера чаще всего значат, что сломан сам запрос. Переключение на другую модель тут редко помогает.
Сколько ретраев делать перед переключением?
Обычно хватает одного быстрого повтора. Он помогает пережить короткий сетевой сбой и не разгоняет шторм из повторных запросов.
Пауза должна быть маленькой, с джиттером, например 200–400 мс. Если повтор не помог, лучше открыть circuit breaker и отправить запрос на резерв, чем жечь лимиты серией ретраев.
Как выбрать горячий резерв для критичного сценария?
Берите модель, которая ведет себя похоже на основную в вашем процессе. Если основная модель отдает строгий JSON, резерв тоже должен держать тот же формат, не добавлять лишний текст и не путать поля.
Перед запуском прогоните резерв на своих промптах, схемах и боевых примерах. Общие бенчмарки полезны, но они не покажут, как модель ведет себя в вашем пайплайне.
Зачем нужен холодный резерв, если уже есть горячий?
Он нужен, когда авария тянется не минуты, а часы. В такой момент важнее сохранить базовый сценарий, чем держать прежнее качество.
Холодным резервом часто ставят более дешевую модель или локально размещенную open-weight модель. Она может отвечать проще, но сервис не встает полностью.
Как лучше настроить circuit breaker?
Держите отдельный breaker на связку «модель + провайдер + регион». Так сбой на одном плече не отключит рабочий запасной путь.
Контур лучше открывать не после одного промаха, а после серии ошибок за короткое окно. Возвращать трафик тоже нужно постепенно: сначала малая проба, потом рост доли, если маршрут снова отвечает стабильно.
Что менять в режиме деградации, кроме самой модели?
Во время сбоя урежьте режим работы, а не делайте вид, что все по-старому. Сократите max_tokens, уменьшите контекст и выключите то, без чего сервис проживет несколько минут.
Для ответа пользователю лучше перейти на короткий шаблон с фиксированной структурой. Если риск высокий, система должна советовать человеку, а не делать действие сама.
Почему запасная модель часто не спасает?
Чаще всего резерв ломается не в день аварии, а раньше. Команда думает, что запасной путь есть, а потом выясняет, что у основного и резерва общий лимит, один аккаунт или один поставщик под разными именами.
Еще одна частая причина — резерв не гоняли на ваших промптах. Модель отвечает, но ломает JSON, режет контекст или меняет поля местами, и пайплайн падает уже у вас.
Как безопасно вернуть трафик на основную модель после сбоя?
Не включайте основную модель обратно одним движением. Сначала дайте ей малую долю трафика, потом поднимайте вес ступенями и смотрите на ошибки, задержку и формат ответа.
Если провайдер ожил на минуту и снова просел, резкий возврат только устроит качели. Лучше подождать серию успешных запросов без нового всплеска задержки.
Нужно ли переписывать клиент, чтобы переключаться между провайдерами?
Не обязательно. Если вы ставите OpenAI-совместимый шлюз между приложением и моделями, часто хватает смены base_url, а SDK, код и промпты остаются прежними.
Для команд в РФ такой слой удобен еще и тем, что он помогает держать маршрутизацию, логи и биллинг в одном месте. Это упрощает аварийное переключение и не заставляет править каждый сервис отдельно.