Права доступа в RAG: как не показать закрытый документ
Права доступа в RAG требуют фильтров до поиска, после ранжирования и перед выдачей. Разберём схему ACL, чтобы сниппеты не раскрывали закрытые данные.
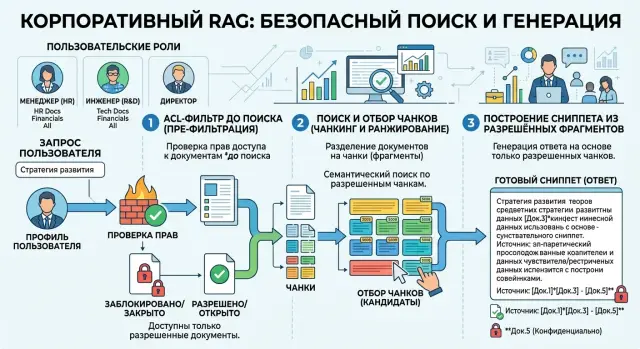
Где возникает риск
Права доступа в RAG ломаются не в одной точке, а сразу в нескольких. Самая частая ошибка проста: индекс уже прочитал текст, разбил его на чанки и положил в поиск, а проверку роли команда делает позже, уже в интерфейсе. Для пользователя это выглядит безопасно, но утечка происходит раньше.
Проблема начинается в момент retrieval. Векторный индекс и ранжирование работают по смыслу, а не по правам. Если закрытый чанк точнее отвечает на вопрос, поиск поднимет его выше открытого. Система еще не показала документ целиком, но уже выбрала закрытый фрагмент как лучший материал для ответа.
Следующий риск - сниппет. Во многих пайплайнах короткую цитату собирают сразу после поиска, чтобы показать, почему документ попал в результаты. Если ACL-фильтр стоит после этого шага, пользователь увидит одну-две строки из закрытого документа, даже если сам документ потом исчезнет из выдачи.
С LLM риск выше. Модель не обязана цитировать текст дословно, чтобы выдать секрет. Ей достаточно прочитать чужой фрагмент в контексте и пересказать смысл своими словами. Можно скрыть ссылку на источник и не показывать карточку документа, но утечка уже случилась в самом ответе.
Обычно это выглядит так:
- сотрудник ищет "условия бонуса для руководителей";
- поиск находит закрытый HR-документ и открытый регламент с общими правилами;
- ранжирование ставит закрытый чанк выше, потому что он точнее;
- сниппет или ответ модели берет фразу именно оттуда.
Пользователь не получил файл, но получил содержание. Для инцидента этого достаточно.
В корпоративной базе знаний такое случается чаще, чем кажется. Рядом лежат документы с похожими терминами: договоры, кадровые правила, внутренние расследования, коммерческие условия. Если фильтр доступа не встроен прямо в retrieval, закрытый текст просачивается через ранжирование, сниппеты, кэш ответов и журналы запросов.
Для компаний с требованиями 152-ФЗ риск шире обычной ошибки интерфейса. Утечь может не только сам документ, но и персональные данные в цитате, пересказе модели или техническом логе. Проверка доступа после генерации ответа почти ничего не спасает. К этому моменту система уже прочитала лишнее.
Что считать объектом доступа
Еще одна частая ошибка - считать объектом доступа только файл или страницу. Для поиска этого мало. Система индексирует и возвращает не файл целиком, а его части: заголовок, сниппет, отдельный чанк, таблицу, комментарий, цитату в ответе модели. Если закрытый абзац попал в выдачу, утечка уже произошла, даже если полный документ не открылся.
Поэтому объект доступа надо определять по тому, что система реально может вернуть пользователю. Простое правило такое: проверку проходит каждая единица, которую поиск умеет найти, ранжировать, процитировать или показать до открытия источника.
Обычно это несколько слоев:
- карточка документа с названием и служебными полями;
- превью или сниппет из первых строк;
- чанк, по которому работает retrieval;
- вложение, таблица или комментарий внутри документа;
- цитата и название источника в финальном ответе.
Чаще всего забывают про чанки. Документ может быть закрыт частично, а индекс хранит его куски как независимые записи. Тогда ACL-фильтр на уровне файла срабатывает, а на уровне фрагмента - нет. Один абзац спокойно проходит в ответ. Если вам нужны действительно безопасные сниппеты RAG, права надо навешивать на каждый возвращаемый кусок, а не только на исходный контейнер.
Метаданные доступа лучше хранить рядом с индексируемым объектом. У чанка должны быть роли, группы, владелец, идентификатор исходного документа и признак наследования прав. Если эти данные живут отдельно, фильтр легко ломается после переиндексации, кэширования или переноса в другой индекс.
Сразу определите, что именно пользователь может видеть. Название, превью и полный текст - это три разных уровня доступа. В одной базе знаний сотрудник может знать, что документ существует, но не иметь права читать его тело. В другой системе секретен уже сам факт существования проекта. Если не разделить эти уровни явно, поиск начнет раскрывать лишнее через заголовки, номера договоров и имена клиентов.
Наследование тоже должно быть частью модели доступа. Права часто приходят не из самого файла, а из папки, проекта, команды или рабочего пространства. Если документ переехал в другую папку, чанк не должен жить со старыми правами. Самый безопасный вариант - при любом переносе или смене ACL пересобирать права для всех дочерних объектов и версионировать их в метаданных.
В банке или телекоме это особенно заметно. Один документ может читать вся команда, а приложение к нему - только юристы и владелец. Если индекс видит оба объекта одинаково, поиск рано или поздно покажет лишнее.
Где ставить проверку в пайплайне
Одна проверка в конце не спасает. Если закрытый чанк попал в поиск или в сниппет, утечка уже началась, даже если модель потом не вставила этот текст в ответ.
Контроль доступа в RAG лучше ставить не в одной точке, а на каждом переходе между этапами. Тогда ошибка в одном слое не превращается в показ чужого документа.
До поиска и перед rerank
Самый безопасный вариант - отсекать чужие документы еще до векторного поиска. Если движок умеет совмещать semantic search с ACL-фильтром, передавайте в запрос роли пользователя, группы, tenant_id, статус документа и другие поля доступа. Тогда индекс ищет только среди разрешенных объектов, а не сначала "находит все", а потом убирает лишнее.
Но и этого мало. После поиска система обычно собирает набор кандидатов для повторного ранжирования, или rerank. На этом шаге права стоит проверить еще раз по исходному ACL, а не по старому кэшу из индекса. Роли меняются. Документ могли закрыть несколько минут назад. Индекс мог еще не обновиться.
Для повторной проверки обычно хватает четырех вещей:
- кто делает запрос;
- какие роли и группы у него есть сейчас;
- к какому документу и чанку относится кандидат;
- какая версия ACL действует в момент ответа.
Перед ответом модели
Сниппет нужно строить только из тех чанков, которые уже прошли проверку. Частая ошибка выглядит так: система скрыла документ на уровне списка результатов, но взяла цитату из соседнего чанка без новой проверки. Именно так в выдачу проскакивают строка договора, зарплата сотрудника или фрагмент письма с персональными данными.
В LLM должен уходить уже очищенный контекст. Не передавайте модели сырой top-k из retrieval и не надейтесь, что она "сама не использует лишнее". Модель не знает политику доступа. Она работает с тем текстом, который вы ей дали.
Полезно логировать и отказы. Сохраняйте не только факт блокировки, но и причину: нет роли, не совпал tenant, ACL устарел, чанк помечен как restricted. Если запрос идет через RU LLM, такой разбор удобно вести по аудит-трейлу каждого вызова. Когда случится инцидент, команда быстро увидит, на каком шаге лишний чанк прошел дальше.
Как собрать схему по шагам
Если права живут отдельно от поиска, утечка почти неизбежна. Достаточно одного старого чанка в индексе или одного rerank без фильтра, и закрытый текст попадет в кандидаты, а потом и в ответ.
Контроль доступа лучше собирать как единый контур, а не как набор несвязанных проверок. Тогда retrieval, rerank и генерация опираются на одни и те же правила и не спорят друг с другом.
- Выберите один источник истины для ролей и групп. Обычно это IAM, DMS или внутренняя система доступа. Поиск не должен сам "придумывать" права пользователя. Он только читает уже выданные роли, группы, отдел и исключения.
- Перенесите эти правила в индекс. У документа и у каждого чанка должны быть метаданные с allow и deny. Если доступ зависит от подразделения или проекта, это тоже надо хранить рядом. Наследование от документа к чанкам лучше считать явно, иначе один фрагмент легко останется без защиты.
- Научите retrieval применять ACL-фильтры до выборки текста. Иначе система найдет релевантный, но закрытый чанк и успеет показать его в сниппете. Для deny-правил держите жесткий приоритет: если allow и deny конфликтуют, выигрывает deny.
- Поставьте вторую проверку после rerank и прямо перед сборкой ответа. Это страховка от ошибок в индексе, кэше и промежуточных сервисах. Такой двойной барьер особенно нужен там, где есть сниппеты и цитаты из найденных кусков.
- Проверьте не только выдачу, но и отзыв доступа. Если сотрудника убрали из группы, закрытые чанки должны исчезнуть быстро, а не "когда индекс обновится ночью". Замерьте задержку обновления прав, инвалидацию кэша и поведение в момент гонки состояний.
Хороший тест очень простой: сотрудник видел документы финансового отдела утром, а после перевода в другую команду не должен видеть их днем. Если хотя бы один старый сниппет еще всплывает в поиске, схема не готова.
Для компаний, где важны RAG и 152-ФЗ, такая сборка нужна не только для безопасности, но и для аудита. Должно быть видно, какие роли пришли в запрос, какой ACL-фильтр в поиске сработал и почему система отбросила конкретный чанк.
Как защитить сниппеты и цитаты
Права доступа в RAG часто ломаются именно на сниппетах. Сам документ может остаться закрытым, но одна строка рядом с найденным термином уже выдаст фамилию, сумму, диагноз или код проекта.
Частая ошибка - хранить общий превью-текст отдельно от ACL-меток. Поиск берет готовое описание документа, показывает его за миллисекунды, а проверку прав делает позже. Так делать нельзя. Каждый фрагмент, из которого система строит сниппет, должен нести те же метки доступа, что и исходный текст.
Еще одна ловушка - склейка соседних чанков ради более "красивой" цитаты. Один фрагмент может быть разрешен, соседний - нет. Если движок соединяет их до проверки, в сниппет легко попадает лишняя строка. То же касается подсветки совпадений, превью таблиц и цитат в explainability.
Правило здесь жесткое: нет доступа к чанку - нет текста, заголовка и даже короткой подписи из него. Если доступ разрешен только к факту существования документа, интерфейс должен показать нейтральную карточку без содержимого. Если доступ запрещен полностью, документ должен выглядеть так, будто его не существует.
Пример для внутренней базы знаний
Менеджер отдела продаж вводит запрос: "какие бонусы действуют для моего отдела в этом квартале?" По смыслу вопрос попадает сразу в две зоны. Поиск видит HR-документ с точными таблицами выплат и общий регламент продаж, который доступен всему отделу.
Наивный RAG легко ошибается. Он сначала берет оба документа как релевантные, строит сниппеты, а уже потом вспоминает про роли. Этого хватает для утечки: в выдаче может мелькнуть название HR-файла или строка с процентами бонусов.
В рабочей схеме система действует иначе. Она находит кандидатов, сразу пересекает их с ACL пользователя и только после этого строит сниппеты и передает контекст модели. Если у менеджера нет роли HR, в пайплайн попадает только общий регламент продаж.
Это меняет и поиск, и ответ. Пользователь не видит документ "Бонусные коэффициенты Q2 для грейдов" даже как заголовок. Модель тоже не должна писать: "в одном из HR-документов указано..." или пересказывать цифры, которые встретились на этапе retrieval до фильтрации.
Нормальный ответ в таком случае опирается только на разрешенный текст. Например: "Для отдела продаж действует общий регламент начисления бонусов. Он описывает условия, сроки и порядок согласования. Для вашей роли доступны только эти правила". Такой ответ может быть короче, зато он не раскрывает лишнее.
Если команда отправляет запросы через OpenAI-совместимый шлюз вроде RU LLM, логика не меняется. Фильтр по ролям должен сработать до того, как фрагменты документа уйдут в модель. Иначе контроль доступа останется только на бумаге.
Для внутренней базы знаний это простой тест на зрелость системы: менеджер должен быстро найти свой регламент, а закрытый HR-файл должен выглядеть так, будто его вообще нет в его мире доступа.
Ошибки, которые ломают защиту
Большинство утечек в RAG случаются не из-за поиска самого по себе. Проблема обычно в том, что один шаг пайплайна забывает про роль, tenant, проект или срок действия доступа. Этого достаточно, чтобы закрытый текст попал в сниппет еще до финальной проверки.
Частая ошибка - хранить права только на уровне документа. Индекс режет документ на чанки, но вместе с текстом не переносит ACL-метки, владельца, группу и наследование прав. В итоге поиск возвращает "безымянный" чанк: сам документ закрыт, а кусок текста уже живет отдельно и проходит дальше по цепочке.
Не лучше работает и общий кэш результатов. Один пользователь с широкими правами открывает запрос, система кладет в кэш найденные чанки или готовый ответ, а потом другой пользователь получает тот же результат по похожему вопросу. Если кэш не привязан к роли, tenant и набору разрешений, он ломает защиту даже при правильном поисковом фильтре.
Отдельно стоит проверить reranker. Многие команды аккуратно фильтруют retrieval, а потом отдают reranker полный текст кандидатов "для лучшего качества". Это плохая идея. Если reranker увидел закрытый фрагмент, он уже мог поднять его выше в выдаче, а иногда и передать его в генерацию через поля с цитатами или объяснением результата.
Еще одна тихая проблема - медленное обновление индекса после отзыва доступа. Пользователя уже убрали из группы, но старые ACL остаются в векторной базе, в кэше или в реплике индекса еще 10-30 минут. Для внутренней базы знаний этого окна хватает, чтобы сотрудник успел вытащить лишнее.
Команды часто тестируют только самый простой сценарий: "у автора есть доступ, ответ пришел". Так баги и остаются в проде. Нужны неприятные проверки: пользователь потерял роль минуту назад, документ переместили в закрытый раздел, один и тот же вопрос задают два сотрудника с разными правами, сниппет собирается из нескольких чанков, а ответ берется из кэша.
Я бы проверял защиту так:
- у каждого чанка есть собственные ACL-метаданные;
- кэш разделен по пользователю или по хэшу набора прав;
- reranker получает только уже отфильтрованные тексты;
- отзыв доступа быстро доходит до индекса и кэша;
- тесты ловят пограничные случаи, а не только идеальный сценарий.
Если хотя бы один пункт пропущен, безопасные сниппеты RAG быстро превращаются в формальность. Пользователь может не открыть сам документ, но увидит ровно тот абзац, который ему видеть нельзя.
Быстрая проверка перед релизом
Перед запуском RAG стоит пройти короткий контрольный список. Он занимает полчаса, но часто спасает от самой неприятной ошибки: пользователь не открывает документ, а кусок закрытого текста уже мелькнул в поиске или ответе.
Первое, что нужно проверить, - модель данных. Каждый чанк должен хранить owner, group, allow и deny, а не только ссылку на исходный документ. Права часто ломаются именно здесь: документ закрыт правильно, но отдельные чанки живут своей жизнью, и поиск тянет их как обычный контент.
Дальше проверьте порядок шагов в пайплайне:
- поиск сначала применяет ACL-фильтры и только потом считает ранжирование, сниппеты и цитаты;
- генератор ответа получает только те чанки, которые уже прошли проверку прав;
- кэш разделяется минимум по tenant и user, а лучше еще и по версии прав;
- логи сохраняют только нужные поля и не тащат сырой PII без причины;
- автотесты меняют роль пользователя, отзывают доступ и проверяют, что старые ответы и кэш сразу перестают подходить.
Пункт со сниппетами многие пропускают. Это ошибка. Если движок сначала нашел релевантный чанк, вырезал красивую цитату, а потом решил проверить доступ, утечка уже случилась. Правило простое: нет доступа к чанку - нет текста, заголовка и даже пары слов из него.
С кэшем тоже не стоит экономить на изоляции. Иначе сотрудник отдела закупок получит ответ, который система минуту назад собрала для юриста из того же tenant. На экране это выглядит как редкий сбой, а для аудита это уже инцидент.
Отдельно посмотрите на логи и трассировку. Для команд, которые работают с персональными данными и требованиями 152-ФЗ, лишний фрагмент текста в логах создает ту же проблему, что и лишний фрагмент в ответе пользователю.
Хороший финальный тест тоже простой: дайте сотруднику доступ к базе, выполните запрос, затем снимите роль и повторите тот же запрос. Если поиск, сниппет, кэш и логи везде ведут себя одинаково, релиз уже похож на рабочий.
Что сделать после первой версии
После первого запуска не стоит считать схему доступа законченной. В RAG утечки часто всплывают не в явном ответе, а в мелочах: в названии файла, в цитате на одну строку, в намеке на то, что документ вообще существует.
Сначала соберите простую матрицу ролей. Для каждой роли зафиксируйте, какие коллекции она видит, какие поля можно отдавать в ответе, а какие нельзя показывать даже в сниппете. Отдельно выпишите спорные типы документов: черновики договоров, HR-файлы, тикеты с персональными данными, письма с вложениями, служебные заметки. Обычно проблемы прячутся именно там, а не в "чистых" документах базы знаний.
Один и тот же запрос для разных ролей
Возьмите один набор реальных запросов и прогоните его от имени разных пользователей. Не меняйте формулировки. Если запрос "покажи условия по бонусам за квартал" дает разный результат для HR, руководителя группы и обычного сотрудника, это нормально. Если закрытый документ мелькает в цитате, заголовке или подсказке только у одной роли, вы нашли дыру.
Смотрите не только на финальный ответ модели. Проверяйте всю цепочку: какие документы вернул поиск, какие чанки прошли ACL-фильтр, что попало в контекст, что ушло в сниппет. Удобно держать короткий чек:
- ответ ссылается на документ, о котором пользователь не должен знать;
- сниппет раскрывает имя файла, автора или дату закрытого материала;
- модель смешивает открытый и закрытый фрагмент в одном абзаце;
- кэш возвращает результат, собранный для другой роли.
После этого включите аудит выдачи и разберите ложные допуски вручную. Каждый такой случай лучше оформлять как отдельный дефект с причиной: ошибка фильтра в поиске, слишком широкий доступ к чанку, неверная нормализация ролей, повторное использование старого контекста. Если не раскладывать это по причинам, команда обычно чинит только промпт, а утечка остается в индексе или в кэше.
Для команд в РФ такой контур удобно проверять через RU LLM. Единый OpenAI-совместимый эндпоинт позволяет гонять один и тот же сценарий без смены SDK, а встроенные аудит-трейлы и маскирование PII помогают увидеть, что именно система передала модели и что стоит скрыть раньше. Это особенно полезно там, где RAG должен работать в рамках 152-ФЗ, а логи и разбор инцидентов нужно держать внутри РФ.
Если нашли хотя бы один ложный допуск, не ограничивайтесь локальной правкой. Повторно прогоните тот же набор запросов по всем ролям. Только так можно понять, вы закрыли дыру или просто сдвинули ее в другое место.
Часто задаваемые вопросы
Что в RAG может утечь, кроме самого файла?
Нет. Утечь может заголовок, сниппет, один чанк, строка из таблицы, пересказ модели и даже кусок текста в логе. Если система показала хоть часть закрытого содержания, это уже инцидент.
Хватит ли проверки прав после ответа модели?
Нет. К этому моменту система уже могла прочитать чужой текст, вставить его в сниппет или передать в контекст модели. Проверяйте права до retrieval, после rerank и еще раз перед сборкой ответа.
На каком уровне лучше хранить ACL в RAG?
Храните ACL у каждой единицы, которую поиск умеет вернуть пользователю. Обычно это документ, чанк, превью, вложение и цитата. Рядом держите роли, группы, tenant, владельца, версию ACL и признак наследования прав.
Почему прав на уровне документа часто недостаточно?
Потому что поиск живет не файлами, а фрагментами. Индекс может вернуть отдельный абзац как самостоятельную запись, и фильтр на уровне файла его уже не остановит. Так закрытый кусок попадает в сниппет или ответ.
Как не сломать защиту через кэш?
Привяжите кэш хотя бы к пользователю, tenant и версии прав. Иначе один сотрудник откроет запрос с широким доступом, а другой получит тот же готовый результат. После смены роли сразу сбрасывайте старые записи.
Как правильно отзывать доступ к документам?
Сначала меняйте права в одном источнике истины, потом быстро обновляйте индекс и кэш. Замерьте, сколько времени старые ACL живут в системе после отзыва. Если окно длится даже несколько минут, сотрудник успеет вытащить лишнее.
Нужно ли скрывать сам факт существования документа?
Да, если у вас разные уровни видимости. В одной системе можно показать только факт существования документа, в другой нельзя раскрывать даже название проекта. Сразу разделите права на заголовок, превью и полный текст.
Где ACL в RAG ломается чаще всего?
Чаще всего схема ломается в rerank, сборке сниппетов, склейке соседних чанков, общем кэше и логах. Еще один частый источник проблем — старый индекс после переноса файла или смены роли. Если любой из этих шагов живет без свежего ACL, ждите утечку.
Как быстро проверить схему доступа перед релизом?
Дайте сотруднику доступ, выполните запрос, затем снимите роль и повторите его через несколько минут. Смотрите не только на ответ модели, но и на поиск, сниппет, кэш и логи. Если хоть где-то всплыл старый фрагмент, релиз рано выпускать.
Чем RU LLM полезен для безопасного RAG?
RU LLM помогает вести аудит вызовов, маскировать PII и держать логи внутри РФ, что удобно для работы по 152-ФЗ. Но шлюз не заменяет ACL в вашем поиске. Фильтр по ролям должен сработать до того, как текст уйдет в модель.