Отрицательные примеры для поиска по базе знаний: как собрать
Разберем, как собирать отрицательные примеры для поиска по базе знаний из плохих кликов, жалоб саппорта и пустых выдач, чтобы точнее настроить поиск.
Где поиск ломается на практике
Поиск по базе знаний редко ломается громко. Обычно все выглядит почти нормально: в выдаче есть знакомые слова, заголовки похожи на запрос, но человек все равно не находит ответ и уходит. Это самый неприятный тип ошибки. По логам кажется, что система что-то нашла, а для пользователя поиск уже бесполезен.
Первый частый сбой - плохой клик. Пользователь открывает документ, проводит там несколько секунд и сразу возвращается к выдаче или меняет запрос. Чаще всего это значит, что текст совпал по словам, но не по смыслу. Человек искал, как сбросить пароль в личном кабинете, а поиск показал общую статью про доступы или политику безопасности.
Есть и более коварный случай: документ выглядит релевантным, но ответа внутри нет. Запрос и статья пересекаются по терминам, продукту или названию функции, однако нужного шага, ограничения или условия в тексте нет. Для RAG это особенно болезненно. Модель получает правдоподобный, но пустой контекст и уверенно отвечает мимо.
Хороший индикатор такой поломки - работа саппорта. Клиент пишет в чат, что не может найти инструкцию, а сотрудник поддержки за минуту находит нужную статью вручную. Значит, документ в базе есть, его название понятное, но ретривер не поднял его достаточно высоко или вообще не увидел.
Еще один симптом - один и тот же запрос ведет в разные нерелевантные документы. Сегодня по запросу "не приходит код" человек видит статью про SMS-шаблоны, завтра - про настройки двухфакторной аутентификации, послезавтра - про ограничения оператора. Если правильного документа среди первых результатов нет, дело уже не в одном неудачном клике. Плавает сама логика поиска: индекс, фильтры, реранкер или нормализация запроса.
На практике поломка часто выглядит одинаково. Пользователь задает вопрос, открывает 2-3 результата, быстро закрывает их и идет в саппорт. Саппорт находит верную статью вручную. В логах поиск выглядит живым, а для бизнеса он уже не работает.
Именно такие эпизоды стоит собирать в первую очередь. Они ближе всего к реальным ошибкам и лучше всего показывают, где совпадение по словам выдает себя за ответ.
Что считать отрицательным примером
Отрицательный пример начинается там, где поиск формально что-то нашел, а человек все равно не решил свою задачу. Для пары "запрос-документ" это означает простую вещь: документ попал в выдачу, его открыли или даже прочитали, но он не дал нужный ответ.
Самый частый случай - клик есть, пользы нет. Пользователь ищет "как сбросить токен", открывает статью про выпуск нового токена и почти сразу возвращается назад. Для логов это успешный клик. Для обучения - плохой сигнал: слова совпали, смысл нет.
То же происходит, когда статья подходит по терминам, но промахивается по сценарию. Запрос про "ошибку авторизации в мобильном приложении" может привести в инструкцию для веб-кабинета. Такой документ нельзя считать релевантным, даже если в нем встречаются те же названия полей, коды ошибок и шаги входа.
Пустая выдача тоже дает полезный сигнал, если нужный материал уже лежит в базе. Тогда проблема не в отсутствии ответа, а в том, что ретривер его не поднял. В такой ситуации отрицательными становятся документы из верхних позиций, которые система показала вместо нужного. Сам запрос стоит сохранить как отдельный сигнал для настройки поиска.
Отдельная категория - жалобы из саппорта. Если оператор пишет, что пользователь снова открыл старую инструкцию, поиск тянет устаревший документ. Если в жалобе сказано: "статья про юрлиц, а вопрос был по физлицам", это тоже чистый отрицательный пример. Текст похож, задача другая.
Обычно хватает пяти типов отрицательных примеров:
- кликнули и быстро вернулись в выдачу;
- открыли документ, а потом создали тикет;
- нашли статью со старыми шагами или старым интерфейсом;
- получили пустую выдачу при наличии нужной статьи в базе;
- увидели документ для другого продукта, роли или сценария.
Для обучения реранкера особенно полезны трудные отрицательные примеры, или hard negatives. Это документы, которые очень похожи на правильный ответ по словам, структуре и теме, но все равно ошибочны. Именно они лучше всего учат модель различать близкие сценарии.
Если коротко, отрицательные примеры - это не любой нерелевантный мусор, а правдоподобные промахи, которые реально мешают людям найти ответ.
Откуда брать плохие сигналы
Самые полезные отрицательные примеры уже есть в ваших данных. Обычно это не отдельный датасет, а следы того, что человек не нашел ответ с первой попытки.
Первый источник - логи поиска. Смотрите не только на клик, но и на то, что было после него. Если человек открыл документ и через несколько секунд вернулся в выдачу, это слабый или плохой матч. Если потом он кликнул другой результат и задержался там дольше, у вас уже есть почти готовая пара: первый документ как отрицательный, второй как более релевантный.
Много полезного дает цепочка безуспешных действий. Запрос без кликов, затем переформулировка, затем еще один запрос, и только после этого - полезный документ. Такой сценарий прямо показывает, что начальная выдача не помогла. Особенно информативны короткие серии из 2-3 попыток по одной задаче.
Второй сильный источник - тикеты саппорта. Если пользователь не нашел статью сам, а сотрудник поддержки вручную отправил нужный материал, это почти готовая разметка. Важно сохранить не только сам запрос, но и документ, который человек видел до обращения, если он вообще был в выдаче.
Третий источник - история неудачных ответов в RAG. Часто проблема видна не в финальном тексте модели, а раньше: ретривер принес не те документы, или реранкер поднял наверх похожий, но бесполезный текст. Если у вас есть история запроса, найденные документы и ответ модели, такие случаи стоит разбирать по одному сценарию.
Для каждого эпизода полезно сохранять минимум:
- исходный запрос;
- список показанных документов;
- клики и быстрые возвраты;
- переформулировку запроса, если она была;
- документ, который в итоге помог решить задачу.
Простой пример: сотрудник ищет "как вернуть часть заказа", кликает статью про полный возврат, быстро закрывает ее, меняет запрос на "частичный возврат", ничего не находит и пишет в саппорт. Саппорт отправляет точную инструкцию. Для обучения это очень сильный случай: первая статья - хороший отрицательный пример, а инструкция из ответа саппорта - положительный.
Как собрать датасет по шагам
Начните с живых запросов за последние 2-4 недели. Более старые логи часто портят выборку: документы уже обновились, формулировки ушли, а часть проблем вы уже закрыли. Если база знаний меняется быстро, разумно брать ближе к 14 дням. Если редко - можно взять полный месяц.
Дальше сократите массив до запросов, где ошибка бьет по времени, деньгам или нагрузке на саппорт. Сначала смотрят на частотные запросы. Потом - на дорогие промахи: после них человек открывает тикет, пишет в чат или делает несколько попыток с разными формулировками. Отдельно полезно собрать повторяющиеся ошибки. Если один и тот же вопрос снова уводит людей в неверную статью, это хороший материал для настройки ретривера.
Рабочая последовательность обычно такая:
- Выгрузите запрос, время, канал, идентификатор сессии, клики по выдаче, позицию клика, переформулировки и факт обращения в саппорт.
- Для каждого запроса сохраните топ-N документов из текущей выдачи. Часто хватает N = 10 или 20.
- Зафиксируйте версию документа на момент запроса. Иначе через неделю станет неясно, почему выдача считалась плохой.
- Уберите точные дубли и слишком пустые запросы вроде "не работает", если по ним нельзя честно оценить качество поиска.
После этого разделите примеры на две группы. Первая - шум. Сюда попадают расплывчатые запросы, случайные клики, устаревшие статьи и случаи, где в базе знаний вообще нет ответа. Их лучше хранить отдельно. Если смешать шум с нормальными ошибками, обучение реранкера быстро уедет в сторону.
Вторая группа - сильные отрицательные примеры. Здесь запрос понятный, правильный документ в базе есть, но поиск поднимает вверх похожий, но неверный материал. Например, человек ищет "смена юридического адреса", а в топе видит статьи про смену фактического адреса и обновление реквизитов. По словам документы близки, по смыслу - нет. Для обучения это один из самых полезных случаев.
Не пытайтесь собрать идеальный набор за один проход. Для первого цикла часто хватает 300-500 запросов, если это частые, дорогие и повторяющиеся ошибки. Такой набор уже помогает улучшить поиск на реальных сбоях, а не на учебных сценариях.
Как размечать пары "запрос-документ"
Плохая разметка ломает весь датасет быстрее, чем маленький объем. Если один разметчик ставит "частично", а другой в таком же случае пишет "нерелевантно", ретривер и реранкер учатся на шуме. Поэтому правила должны помещаться на одну страницу и отвечать на один вопрос: что считать хорошим ответом на запрос пользователя.
В инструкции лучше сразу дать 5-7 коротких примеров из вашей базы знаний. Людям проще держаться правил, когда они видят живые пары, а не общие формулировки.
Удобно использовать три метки:
- "релевантно" - документ прямо отвечает на запрос и помогает закрыть задачу без догадок;
- "частично" - тема совпадает, но не хватает шага, условий, версии продукта или точного сценария;
- "нерелевантно" - документ уводит не туда и не помогает решить запрос.
Одной метки мало. Рядом с "частично" и "нерелевантно" лучше фиксировать причину ошибки. Подойдет короткий справочник причин: "устарело", "не тот продукт", "не тот шаг". Список должен быть коротким и стабильным. Иначе разметчики начнут расходиться в трактовках.
Полезно хранить сразу две формы запроса: исходную и очищенную. Исходный запрос показывает, как человек пишет на самом деле: с опечатками, лишними словами и внутренним жаргоном. Очищенная версия нужна для анализа и повторяемой разметки.
Простой пример: исходный запрос "не открывается акт сверки в личном кабе", очищенная версия - "не открывается акт сверки в личном кабинете". Один и тот же документ может получить метку "частично", если он описывает вход в кабинет, но не объясняет, что делать именно с актом сверки. Причина в таком случае - "не тот шаг".
Если база знаний связана с RAG, храните разметку рядом с идентификатором документа, версией статьи и датой оценки. Иначе через месяц будет непонятно, модель ошиблась или статья уже изменилась.
Пример с жалобой в саппорт
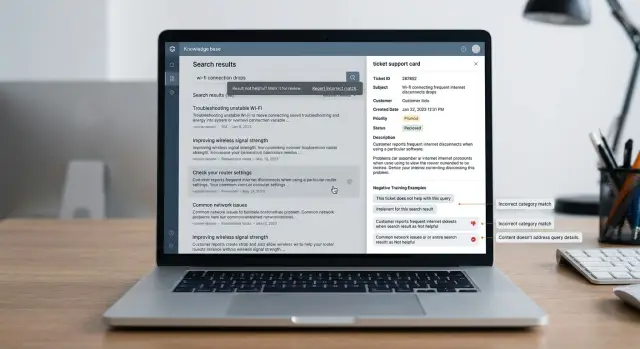
Клиент пишет в чат: "не могу сменить способ оплаты". Поиск цепляется за слово "подписка" и первым показывает статью про отмену подписки. Формально тема рядом, но ответ не тот.
Пользователь открывает статью, не находит нужных шагов и возвращается в саппорт. Для команды это полезный сбой. Он показывает не просто плохую выдачу, а опасный случай, где документ выглядит уместным и поэтому легко проходит в верх поиска.
Дальше саппорт решает вопрос вручную. Агент находит правильную инструкцию, например статью "как изменить карту для автоплатежа" или "как поменять способ оплаты в личном кабинете", и отправляет ее клиенту. После этого у вас уже есть почти готовый обучающий пример.
Для датасета стоит сохранить четыре объекта:
- исходный запрос клиента;
- документ, который поиск показал первым;
- документ, который реально помог решить вопрос;
- короткую пометку, почему первая статья не подошла.
Неверная статья в таком кейсе идет в hard negative для этого запроса. Это хороший hard negative, потому что он близок по словам и теме, но расходится по намерению. Если модель не научить различать такие пары, она и дальше будет путать "сменить способ оплаты" с "отменить подписку", "отключить автоплатеж" и другими соседними сценариями.
Полезно сохранить и поведение пользователя: открыл ли он статью на 5 секунд, вернулся ли назад, написал ли второе сообщение вроде "это не то". Эти сигналы помогают отделить случайный клик от реальной ошибки поиска.
Одна жалоба сама по себе почти ничего не меняет. Но если саппорт соберет 30-50 похожих случаев за месяц, вы увидите устойчивый шаблон. После этого ретривер можно доучить на паре "запрос - правильный документ", а реранкеру дать контрастную пару "запрос - неправильный, но похожий документ". Обычно именно на таких узких путаницах качество растет быстрее всего.
Как использовать эти данные в ретривере и реранкере
Отрицательные примеры по-разному работают на двух слоях поиска. Ретривер учится не тащить в выдачу "почти похожие" документы, а реранкер учится переставлять уже найденных кандидатов. Если кормить обе модели случайным мусором, обучение станет слишком легким и почти не изменит поведение на живых запросах.
Для ретривера
Ретриверу нужны сильные отрицательные пары. Берите документы, которые очень близки по словам и теме, но не решают запрос. Например, пользователь ищет "сброс пароля в личном кабинете", а в кандидаты попадает инструкция для администратора или статья для старой версии продукта. Такие пары полезнее, чем случайная страница "о компании".
Обычно работает простая схема: на один запрос оставляют один положительный документ и несколько сильных отрицательных. Хорошие источники для них - плохие клики, документы из первых позиций неудачной выдачи и похожие статьи из того же раздела. Так ретривер лучше разделяет близкие смыслы, а не только очевидно разные темы.
Для реранкера
Реранкеру полезно сохранять весь набор документов, которые модель перепутала между собой, а не только победителя. Если по запросу в первых пяти позициях были три очень похожих статьи, именно на них и надо учить реранкер. Его задача - не найти документ с нуля, а поднять правильный выше тех, что выглядят правдоподобно, но ведут не туда.
На практике стоит сохранять запрос, правильный документ и первые документы из ошибочной выдачи. Полезно добавить старую позицию документа в ранжировании и отметить, был ли плохой клик или жалоба после просмотра. Сильные отрицательные примеры лучше держать отдельно от случайных.
Это разделение важно. Случайные отрицательные примеры годятся для быстрой санитарной проверки, но не для основного обучения. Если смешать их с сильными, метрики могут вырасти на бумаге, а первые позиции не станут лучше.
Смотрите не только на общий recall, но и на точность в начале выдачи: Precision@1, Precision@3, MRR или nDCG на малой глубине. Пользователь редко листает далеко. Если модель стала лучше на двадцатой позиции, это почти незаметно. Если она чаще попадает в первую или вторую, разница видна сразу.
Ошибки, которые портят выборку
Если команда берет в датасет только пустые выдачи, она видит лишь один тип поломки. На практике поиск чаще ошибается иначе: пользователь вводит нормальный запрос, система показывает правдоподобный, но чужой документ, и человек кликает по нему просто потому, что ничего лучше не видно. Такие плохие клики часто полезнее пустых результатов. Они показывают, с чем ретривер путает нужный ответ.
Другая частая ошибка - складывать в минусы все, что не заняло первое место в выдаче. Так выборка быстро засоряется спорными случаями. Если документ частично отвечает на вопрос, а рядом лежит почти такой же дубль, не делайте из них жесткий негатив. Иначе модель выучит странное правило: похожий текст всегда плохой. Для реранкера это особенно вредно.
Вот несколько правил, которые спасают от шума:
- не записывайте в минусы дубли и старые копии одной статьи;
- не путайте слабый ответ с явно неверным;
- проверяйте, не возник ли конфликт из-за шаблонных фраз и одинаковых заголовков;
- держите спорные пары отдельно и разбирайте их вручную.
Свежесть тоже часто ломает разметку. Запрос "как подключить SSO" мог вести на верную статью полгода назад, но после релиза продукт поменялся, и теперь тот же документ уже уводит человека не туда. Если команда не хранит дату запроса, версию продукта и статус статьи, она получает шум вместо сигнала.
Есть и более тихая проблема - язык. Клиенты пишут "не приходит код", "не пускает в кабинет", "счет задвоился". Команда внутри говорит "OTP", "личный кабинет", "дублирование транзакции". Если смешать эти слои без пометки, модель начнет учиться внутреннему жаргону, а не живым формулировкам. Потом поиск хорошо выглядит на тестах команды и заметно хуже работает на реальных запросах.
Поэтому полезно разделять хотя бы три источника текста: язык пользователя, язык саппорта и язык документации. Даже простая метка в датасете уже помогает понять, где именно путается ретривер - на клиентских словах, на устаревших статьях или на дублях, которые случайно попали в минусы.
Короткий чек-лист перед запуском
Если запустить обучение на сырой выборке, модель быстро выучит шум. Лучше проверить данные заранее, чем потом разбирать странные ответы в проде.
- Отделите обучение от проверки. Один и тот же запрос не должен попадать в обе части.
- Посмотрите на состав запросов. В наборе нужны и частые короткие формулировки, и длинные редкие вопросы с деталями, опечатками и разговорными словами.
- Подпишите причину у каждой отрицательной пары. Не просто "не подходит", а "похожая тема, но другой сценарий", "устаревший документ", "совпали слова, но смысл другой".
- Сверьте выборку с саппортом и продуктом. Команда должна заранее назвать промахи, после которых пользователь чаще всего пишет в поддержку, злится или бросает задачу.
- Уберите спорные метки. Если по паре нет согласия, отложите ее в отдельную папку и не тащите в обучение.
Тестовый набор лучше собирать из свежих случаев. Тогда видно, помогает ли новая версия ретривера на реальных проблемах, а не только на старых примерах, к которым команда уже привыкла.
Хорошо работает и простая контрольная проверка. Возьмите запрос "не приходит код подтверждения" и посмотрите, что модель ставит выше. Документ про смену номера телефона может выглядеть похожим из-за общих слов, но он станет нормальным negative только если вы явно записали причину такой ошибки. Иначе через месяц никто не вспомнит, почему пара попала в выборку.
Если данных пока мало, не пытайтесь брать объемом. Набор из 300 чистых и понятных отрицательных примеров обычно лучше, чем 3000 спорных. Для первого запуска этого достаточно, чтобы увидеть, где модель путает намерение, а где ей просто не хватает хороших документов.
Что делать после первого цикла
Первый прогон редко дает идеальную выдачу. После него полезно не гадать, стало лучше или хуже, а проверять это на одном и том же наборе запросов. Возьмите контрольный список из реальных формулировок пользователей: коротких, кривых, с опечатками, с терминами саппорта. Прогоните его через старую и новую версию поиска и смотрите не только на метрики, но и на разницу в первых 3-5 документах.
Если новая версия стала лучше на чистых запросах, но хуже на спорных, это уже важный сигнал. Обычно именно спорные запросы и ломают RAG в проде. Один неудачный документ в топе часто тянет вниз весь ответ модели.
После сравнения сразу пополняйте датасет свежими ошибками. Не ждите квартальной пересборки. В рабочий набор обычно входят новые жалобы из саппорта, плохие клики, запросы с нулевой пользой и новые версии статей, которые меняют правильный ответ.
Короткие циклы почти всегда полезнее редких больших обновлений. Раз в неделю, а иногда и чаще, команда может взять 20-50 свежих случаев, быстро разметить пары "запрос-документ" и заново проверить ретривер и реранкер на контрольном наборе. Так проще ловить дрейф языка: новые названия продуктов, внутренние аббревиатуры и частые ошибки в формулировках.
Для такой работы особенно важны нормальные логи. Если вы собираете RAG-сценарии в среде с требованиями 152-ФЗ, удобнее сразу держать трассировку запросов, логи и хранение данных внутри российской инфраструктуры. Например, в RU LLM логи и бэкапы остаются на серверах в РФ, а маскирование PII и аудит-трейлы встроены в каждый запрос. Это упрощает разбор неудачных кейсов: команда видит, какой запрос пришел, что вернул поиск и какой документ модель взяла в ответ.
Хороший результат первого цикла выглядит довольно прозаично: меньше странных документов в топе, меньше жалоб на то, что поиск не понял вопрос, и понятный список ошибок на следующую неделю. Именно так отрицательные примеры начинают работать на качество, а не лежат мертвым архивом.
Часто задаваемые вопросы
Как понять, что поиск сломан, если клики есть?
Если люди открывают 2–3 результата, быстро возвращаются в выдачу и потом идут в саппорт, поиск уже не решает задачу. По логам клики есть, но пользы нет: система находит похожие слова, а не нужный ответ.
Что считать отрицательным примером для поиска?
Берите в минус не любой нерелевантный мусор, а документ, который выглядел правдоподобно и все же не помог. Обычно это статья из выдачи, по которой был клик, быстрый возврат или тикет после просмотра.
Чем hard negative отличается от обычного минуса?
Hard negative — это почти правильный документ, который расходится по сценарию, роли, версии продукта или шагу. Он полезнее случайной страницы, потому что учит модель различать близкие случаи, а не только далекие темы.
Откуда брать плохие сигналы для датасета?
Смотрите сначала в логи поиска, цепочки переформулировок и обращения в саппорт. Если пользователь не нашел ответ сам, а сотрудник потом быстро прислал нужную статью, у вас уже есть хороший обучающий эпизод.
За какой период лучше собирать логи?
Обычно хватает свежих логов за 2–4 недели. Старые данные часто портят выборку: статьи уже изменились, интерфейс обновился, а причина промаха стала другой.
Какие данные нужно сохранить по каждому случаю?
Сохраняйте сам запрос, топ документов из выдачи, клики, быстрые возвраты, переформулировки и документ, который в итоге помог. Если база меняется часто, фиксируйте и версию статьи на момент запроса.
Как лучше размечать пары запрос-документ?
Проще всего начать с трех меток: релевантно, частично и нерелевантно. Рядом с частичными и плохими парами записывайте короткую причину вроде «устарело», «не тот продукт» или «не тот шаг», чтобы разметка не расползалась.
Какие ошибки чаще всего портят выборку?
Не складывайте в минусы дубли, старые копии одной статьи и спорные пары, где документ частично отвечает на вопрос. Не стоит брать и случаи, где в базе вообще нет ответа: это уже другой тип проблемы.
Как использовать отрицательные примеры в retriever и reranker?
Для retriever берите один правильный документ и несколько сильных отрицательных, которые близки по словам и теме. Для reranker храните весь набор похожих кандидатов из ошибочной выдачи, чтобы он учился поднимать верный документ выше соседних промахов.
Сколько примеров нужно для первого запуска?
Для первого цикла часто хватает 300–500 чистых запросов, если это частые и дорогие промахи. Такой объем уже показывает, где поиск путает намерение, а где проблема в самих документах.