Одна open-weight модель для всего стека: где она тянет
Разбираем, когда одна open-weight модель закрывает чат, извлечение, классификацию и модерацию, а когда стек лучше разделить по задачам.
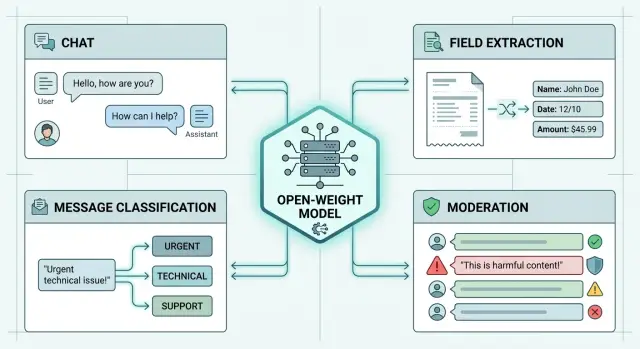
Почему стек моделей быстро разрастается
Обычно все начинается не с большой архитектурной идеи, а с одного сбоя. У чат-бота падает точность на сложных вопросах, и команда добавляет вторую модель. Потом на извлечении данных из текста всплывают ошибки в датах или суммах, и в стек уходит еще одна. Через месяц вместо одной open-weight модели у вас уже небольшой парк, собранный по следам отдельных инцидентов.
На первый взгляд это выглядит разумно. Качество и правда может вырасти. Но такой рост почти всегда точечный: одна модель лучше отвечает в чате, другая аккуратнее достает поля, третья строже работает в модерации контента. Каждая замена лечит свой симптом, а вся система становится тяжелее.
Проблемы быстро выходят за рамки качества:
- логи лежат в разных местах, и разбор сбоев тянется дольше;
- цены начинают расходиться сильнее, чем команда ожидала;
- правила безопасности и модерации начинают жить по-разному;
- A/B-проверки становятся мутными, потому что меняется сразу несколько частей;
- после каждого релиза все сложнее предсказать поведение в проде.
Есть и другая ловушка. Если у вас уже настроена маршрутизация моделей через единый шлюз, добавить новую модель очень легко. Поэтому команда чаще лечит просадку переключением, а не проверкой границ текущей модели. В первые недели это ускоряет работу. Потом замедляет все остальное: от отладки до финансового контроля.
На практике одна модель нередко закрывает нормальный рабочий уровень сразу для нескольких задач. Не идеальный, а достаточный. Если чат, классификация текстов и простое извлечение данных из текста укладываются в ваши допуски, раннее разрастание стека только добавляет шум. Сначала полезно честно проверить, где одна модель уже проходит по качеству, задержке и цене. Только потом становится понятно, где отдельная модель действительно нужна, а где команда просто испугалась пары плохих ответов.
Что значит "хватает на весь стек"
Одна модель "хватает на весь стек", если она решает все базовые задачи без сюрпризов. Не идеально, а ровно и предсказуемо. Для продакшена это обычно важнее, чем редкие блестящие ответы в демо.
Смысл простой: одна и та же модель должна нормально вести чат, доставать нужные поля из текста, ставить метки и не ломать формат ответа. Даже если в отдельном тесте она немного уступает лучшей специализированной модели, это еще не проблема. Проблема начинается тогда, когда команда тратит больше времени на обходные правила, ретраи и ручную проверку, чем экономит на единой схеме.
Смотрите сразу на четыре вещи: качество на реальных задачах, задержку под вашей нагрузкой, цену одного полезного результата с учетом ретраев и стабильность формата, особенно если ответ дальше читает код.
Средний результат легко вводит в заблуждение. Модель может аккуратно проходить 90% запросов, но путаться на длинных письмах, смешивать поля в JSON или срываться на спорных сообщениях в модерации. Этого уже достаточно, чтобы стек начал делиться. Худшие 5-10% примеров часто говорят о системе больше, чем красивая средняя цифра.
Проверка обычно выглядит скучно, и это хорошо. Возьмите трудные случаи: шумные обращения, неполные данные, сарказм, опечатки, длинные цепочки писем. Если модель держит качество и форму ответа на таких примерах, ей можно доверить больше одной задачи.
Еще до запуска зафиксируйте порог, после которого маршруты разделяются. Например: если извлечение падает ниже 98% по нужным полям, если ответ выходит за лимит задержки или если JSON ломается чаще одного раза на 200 запросов, этот тип задач уходит на отдельную модель. Такой порог экономит недели споров.
Если вы тестируете через единый шлюз, например RU LLM, это особенно удобно: можно заранее задать правило маршрутизации и включать отдельный маршрут только там, где одна модель уже не держит нужный уровень.
Где одна модель тянет чат
Одна open-weight модель часто закрывает чат лучше, чем кажется. Для FAQ, простых диалогов и уточняющих вопросов отдельный парк моделей обычно не нужен. Если бот отвечает по понятным правилам, не принимает сложных решений и не должен держать длинную цепочку рассуждений, одной модели хватает.
Типичный пример - поддержка с повторяющимися вопросами. Пользователь спрашивает про статус заказа, условия возврата, способы оплаты или нужный документ. В таком режиме модель должна вежливо вести разговор, помнить пару прошлых реплик и не уходить в выдумки.
Проблемы начинаются не на первом ответе, а на четвертом или пятом. Пользователь меняет формулировку, добавляет детали, перескакивает на другой вопрос, потом возвращается назад. Если модель теряет нить, забывает ограничения или начинает противоречить самой себе, чат уже нельзя считать надежным.
Проверьте несколько простых сценариев:
- 6-8 реплик с уточнениями и сменой формулировок;
- длинное сообщение перед простым вопросом;
- пустой или слишком расплывчатый запрос;
- опасный запрос, где нужен ясный отказ.
Отдельно посмотрите на длинный контекст. Многие open-weight модели отвечают хорошо, пока история короткая, но после большого блока текста начинают игнорировать системную инструкцию, путать роли и пропускать важные детали. Снаружи все еще выглядит нормально, а внутри бот уже поплыл.
Есть и еще один недооцененный тест: как модель отказывает. Она не должна спорить с пользователем, давать опасные советы или заполнять пробелы выдумками, если данных нет. Нормальный чат-бот лучше попросит уточнение или честно скажет, что ответа не хватает.
Если модель держит многоходовый диалог, не теряет инструкции и спокойно отказывает там, где это нужно, ее уже можно ставить на заметную часть чатовых задач без лишнего зоопарка.
Что проверить на извлечении данных из текста
На извлечении данных из текста одна модель часто проходит демо, но спотыкается в работе. На чистом шаблоне она достает дату, сумму и номер договора без ошибок. Потом приходит письмо с опечатками, пересланный PDF или форма без одного поля, и стабильность исчезает.
Сначала проверьте повторяемость результата. Возьмите похожие документы и прогоните их несколько раз с одним и тем же промптом. Если JSON меняется от запуска к запуску, дальше будет больно: парсер начнет падать, а команда - дописывать костыли под каждый новый вариант.
Для базового набора тестов обычно хватает четырех типов примеров:
- чистый документ с понятной структурой;
- тот же текст, но с другим порядком полей;
- версия с шумом, опечатками и лишними фразами;
- документ, где одного или двух полей нет совсем.
Особенно внимательно смотрите на пропущенные поля. Нормальное поведение - вернуть null, пустой массив или другое заранее согласованное значение по схеме. Плохое поведение - додумать ответ, подставить соседнее поле или написать строку вроде "не найдено", хотя вы ждали валидный JSON.
Есть и простой прикладной тест: сколько исправлений нужно после первого ответа модели. Допустим, вы извлекаете из писем номер заказа, категорию проблемы и желаемый способ связи. Если оператор правит каждую десятую запись, это терпимо. Если правки нужны в трети случаев, одна модель уже не тянет задачу так хорошо, как казалось.
Если вы гоняете такие проверки через единый OpenAI-совместимый эндпоинт, удобно отдельно посмотреть, как извлечение ведет себя на данных с маскированием PII. Иногда замена телефона, имени или адреса ломает связанное поле. Это лучше поймать до запуска. В RU LLM такие сценарии можно проверять в том же контуре, не меняя SDK и код.
Где классификация начинает просить отдельную модель
На наборе из 3-10 меток одна open-weight модель часто держит ровный результат. Особенно если классы заметно отличаются по смыслу: "возврат", "жалоба", "вопрос по оплате", "спам". В таких задачах модель, которая уже отвечает в чате, нередко так же уверенно раскладывает входящие тексты по категориям.
Проблемы начинаются там, где классы стоят слишком близко друг к другу. Разница между "жалобой" и "претензией" или между "отменой заказа" и "изменением заказа" кажется очевидной, пока вы не посмотрите на реальные сообщения. Люди пишут коротко, путают формулировки и смешивают несколько тем в одном абзаце. Модель начинает гадать по тону и отдельным словам, а не по правилу.
Дальше качество обычно ломают две вещи. Первая - длинные правила. Если команде нужен не просто ярлык, а решение по документу на несколько страниц, один промпт быстро раздувается и начинает вести себя неровно. Вторая - редкие метки. Когда класс встречается в 0,5-1% случаев, модель тянется к частым вариантам. Общая точность выглядит прилично, но дорогие ошибки прячутся именно там.
Что держать под контролем
Без порогов уверенности такая схема редко живет долго. Лучше сразу задать простое правило:
- уверенный ответ идет в систему автоматически;
- сомнительный случай уходит на ручную проверку;
- пары похожих классов разбираются отдельно;
- качество считается по каждой метке, а не только по среднему числу.
Если спорных случаев становится много, не мучайте один и тот же промпт. Проще выделить отдельную модель для сложных или редких классов. Если у вас уже есть маршрутизация моделей через единый API, такой переход проходит спокойно: приложение не меняется, меняется только правило отправки запросов.
Почему модерацию часто отделяют раньше
Одна модель может нормально вести чат, разбирать письма и раскладывать обращения по темам. На модерации контента запас ошибки обычно меньше. Если ассистент в чате ответил чуть хуже, пользователь просто переформулирует вопрос. Если фильтр пропустил угрозу, токсичную реплику, утечку персональных данных или обход правила, цена совсем другая.
Во многих командах один пропуск обходится дороже, чем серия лишних срабатываний. Ложный блок раздражает. Пропуск может привести к жалобе, ручному разбору инцидента или проблемам с комплаенсом. Для банка, телекома или крупного ритейла это обычная математика: лучше отправить сомнительный текст на повторную проверку, чем пропустить его дальше без фильтра.
Где универсальная модель проседает
Модерация быстро ломает иллюзию, что одна модель одинаково хорошо делает все. Люди пишут со сленгом, намеками, опечатками и смесью языков. Сегодня сообщение выглядит нейтрально, а завтра тот же смысл прячут в шутке, транслите или обрывках английского.
Простой пример: пользователь пишет в поддержку на смеси русского и английского, добавляет мемный жаргон и завуалированную угрозу. Для чата этого может хватить, чтобы ответить вежливо. Для модерации этого мало. Модель может не увидеть риск или, наоборот, начать блокировать безобидные фразы, если правила заданы слишком грубо.
Отдельный маршрут для модерации обычно нужен в четырех случаях:
- правила должны быть жесткими и проверяемыми;
- есть запрещенные категории с разной ценой ошибки;
- в потоке много сленга, транслита и смешанных языков;
- спорные случаи нужно отправлять на вторую проверку и сохранять понятный аудит решений.
На практике лучше работает не одна проверка, а короткая цепочка. Первый фильтр быстро отсекает явные случаи. Второй аккуратнее разбирает серую зону. Если вы строите такую схему через RU LLM, для модерации можно держать отдельный маршрут и аудит-трейлы по каждому запросу, не смешивая этот поток с обычным чатом.
Если универсальная модель нужна любой ценой, дайте ей узкую роль: предварительный фильтр, а не финального судью. На модерации это обычно честнее и дешевле, чем разбирать пропуски уже после запуска.
Как проверить одну модель на своем наборе задач
Проверять модель на красивых демо почти бессмысленно. Нужны живые примеры: диалоги, письма, заявки, карточки товаров, спорные сообщения пользователей. На каждую задачу соберите хотя бы 50-100 примеров, иначе выводы будут случайными. Если вы проверяете чат, извлечение данных из текста, классификацию текстов и модерацию контента, держите эти наборы отдельно.
Потом задайте для ошибок простой суд: pass или fail. Не пишите длинные критерии. Для извлечения fail, если модель пропустила обязательное поле, перепутала сумму или сломала формат. Для классификации fail, если метка неверная. Для модерации fail, если модель пропустила явное нарушение или, наоборот, режет нормальный текст. Чем проще правило, тем меньше споров.
Все прогоны делайте с одинаковыми промптами и настройками. Один и тот же temperature, одинаковый max tokens, один формат ответа. Иначе вы сравниваете не модель, а удачность настройки. Если тесты идут через RU LLM, удобно гонять один и тот же набор сценариев через единый OpenAI-совместимый эндпоинт и не менять код между провайдерами.
В одной таблице обычно хватает четырех полей:
- задача и размер набора;
- доля pass;
- медианная задержка;
- цена на 1000 или 10 000 запросов.
Этого достаточно, чтобы увидеть картину без самообмана. Например, одна модель может хорошо отвечать в чате и стабильно доставать номер заказа из письма, но проседать на короткой классификации, где важны 1-2 процента точности, или тормозить на модерации потока.
Разделяйте стек только там, где модель не держит ваш порог. Не там, где команде просто тревожно после пары неудачных ответов.
Пример: служба поддержки интернет-магазина
У интернет-магазина часто есть четыре типовых потока: вопросы о доставке, возвраты, разбор писем от клиентов и фильтр грубых сообщений. Во многих случаях одна модель закрывает это без россыпи отдельных сервисов.
Сценарий простой. Клиент пишет: заказ не пришел, оформите возврат, номер такой-то, покупка была 12 марта. Та же модель может ответить в чате по правилам магазина, сделать извлечение данных из текста и вытащить номер заказа с датой, а потом сразу отнести обращение к нужной теме. Обычно хватает 3-4 меток: обмен, брак, статус, жалоба.
Это удобно не только из-за кода. Команда держит один контур промптов, одну схему логов и один набор тестов. Если запросы уже идут через единый LLM-шлюз, такой подход легко проверить на реальном трафике без смены SDK и без лишней маршрутизации моделей.
Где начинаются проблемы? Обычно не в чате и не в разборе письма, а в модерации. Грубые сообщения, сарказм, двусмысленные угрозы и спорный тон ломают даже сильную модель чаще, чем обычные запросы вроде "где мой заказ".
Для проверки нужна отдельная выборка. Возьмите хотя бы такие случаи:
- прямое оскорбление сотрудника;
- скрытая агрессия без брани;
- жалоба с угрозой суда;
- ироничное сообщение, где тон неочевиден;
- обычное недовольство без нарушения правил.
Если модель путается только здесь, не спешите расширять весь парк. Часто хватает простого разделения: та же модель ведет чат, делает классификацию текстов и извлечение полей, а модерация контента уходит в отдельный поток проверки.
Это и есть нормальная граница. Вы не строите сложную схему раньше времени, но уже видите, где монолитный подход держится, а где начинает создавать лишний риск.
Частые ошибки при выборе одной модели
Команды чаще ошибаются не в самой модели, а в способе проверки. Они берут красивые демо-запросы, на которых любой сильный open-weight вариант выглядит убедительно, и почти не смотрят на живые обращения. А в реальных данных сразу вылезают обрывки фраз, OCR-шум, длинные переписки, странные сокращения и конфликтующие инструкции.
Вторая ошибка - складывать все задачи в один общий балл. Так удобнее для отчета, но бесполезно для решения. Если чат отвечает нормально, а извлечение полей путает сумму и дату, средняя оценка это скроет.
Для поддержки, антифрода или бэк-офиса это разные риски, и считать их вместе не стоит. Чат можно терпеть с редкими шероховатостями, а ошибка в классификации тикета или в извлечении реквизитов быстро превращается в ручную работу и жалобы.
Многие почти не смотрят на формат ответа на длинных входах. На коротком примере модель честно отдает JSON, а на письме с историей переписки внезапно добавляет пояснение перед объектом, теряет поля или обрезает вывод. Именно такие сбои ломают пайплайн чаще, чем сложные вопросы пользователя.
Еще один частый промах - добавлять вторую модель слишком рано. Кажется, что отдельная модель для классификации или модерации сразу все исправит. Но пока вы не измерили цену ошибки, это гадание. Иногда ошибка в 2% почти не влияет на бизнес, а новый маршрут только добавляет задержку, тесты и ночные разборы.
Рост числа маршрутов сам по себе дорог. Нужно понять, кто и когда отправляет запрос в другую модель, как откатывать решение и где искать причину сбоя. Если вы работаете через единый API-шлюз, подключить новый маршрут технически легко. Поддерживать его в продакшене все равно будет ваша команда.
Перед расширением парка проверьте пять вещей:
- 100-200 реальных примеров по каждой задаче;
- отдельную метрику для чата, извлечения, классификации и модерации;
- формат ответа на длинных входах;
- цену ошибки в рублях, времени или ручных проверках;
- стоимость отладки каждого нового маршрута.
После такой проверки часто оказывается, что одна модель тянет больше, чем казалось. Но это видно только на живых данных и раздельных метриках, а не на демо.
Быстрая проверка перед запуском
Перед стартом нужен не большой бенчмарк, а короткий тест на реальной работе. Возьмите по 20-30 живых примеров для чата, извлечения, классификации и модерации. Если одна модель проходит только "средний" чат, но сыпется на разметке полей или спорных сообщениях, это видно за один вечер.
До теста зафиксируйте порог качества. Например: не ниже 95% на извлечении номера заказа и суммы, не выше 2% ложных блокировок в модерации, одинаковый JSON-ответ в 19 из 20 похожих кейсов. Если записать планку после прогона, команда почти всегда подгонит вывод под уже полученный результат.
Хороший быстрый прогон обычно включает пять проверок:
- реальные, а не учебные примеры по всем четырем задачам;
- заранее записанный порог качества, понятный всей команде;
- стабильный формат ответа на серии похожих кейсов;
- отдельный тест для модерации, а не спрятанный внутри чат-сценария;
- понятную цену при росте трафика хотя бы в 5-10 раз.
Стабильность формата особенно часто недооценивают. Модель может отвечать умно, но в одном случае вернуть "order_id", в другом "id заказа", а в третьем вообще абзац текста. Для продакшена это не мелочь, а лишний код, ручные правки и ошибки в интеграции.
С модерацией лучше быть строже. Проверьте токсичность, спам, утечки персональных данных и пограничные случаи отдельно от обычного диалога. Чат может выглядеть аккуратно, но на спорных фразах давать слишком мягкий ответ.
И еще один приземленный вопрос: сколько это стоит при росте. Считайте не цену одной тысячи запросов, а месяц работы с вашим пиком нагрузки. Если тесты идут через единый OpenAI-совместимый шлюз, такие цифры проще снять заранее на одном и том же наборе сценариев.
Что делать дальше
Не расширяйте стек заранее. Сначала возьмите одну open-weight модель и задайте для каждой задачи простой порог: какой уровень точности, сколько ложных срабатываний, какая задержка и какая цена на 1000 запросов вам подходят.
Если модель держит чат, извлечение и базовую классификацию в этих рамках, этого уже достаточно для первого релиза. Отдельный маршрут нужен не потому, что "так делают все", а потому что на ваших данных есть ясный провал.
Дальше лучше идти короткими циклами:
- Соберите один набор примеров для всех задач: диалоги, письма, заявки, спорные тексты для модерации.
- Прогоните их через одну модель и оцените не общее впечатление, а цифры по каждому типу ошибок.
- Отдельно сравните эту модель и frontier-модель на одном и том же наборе.
- Добавляйте второй маршрут только там, где разница заметна в деньгах, качестве или задержке.
На практике второй маршрут чаще всего появляется не из-за чата. Обычно раньше ломаются модерация, сложное извлечение из грязного текста или редкие классы, где ошибка дорого стоит. Если разница между моделями видна только в двух процентах случаев и не влияет на процесс, новый маршрут может принести больше сложности, чем пользы.
Если команде нужна инфраструктура внутри РФ, биллинг в рублях и единый OpenAI-совместимый эндпоинт, такой тест удобно проводить через RU LLM. Можно сравнить frontier-модели и open-weight модели на одном наборе запросов без смены SDK, кода и промптов.
Следующий шаг простой: выберите 100-300 реальных примеров, зафиксируйте пороги и примите решение по фактам. Либо оставляете одну модель еще на квартал, либо отделяете только самый проблемный маршрут.
Часто задаваемые вопросы
Когда одной open-weight модели правда хватает на весь стек?
Да, часто хватает. Если одна модель стабильно ведет чат, возвращает валидный JSON, держит нужную задержку и не выходит за бюджет, раннее дробление стека только добавит отладку и лишние маршруты.
По каким метрикам проверять одну модель?
Смотрите не на средний балл, а на ваш порог. Обычно хватает четырех метрик: доля pass, медианная задержка, цена полезного результата с учетом ретраев и стабильность формата на длинных входах.
Где одна модель обычно тянет чат без отдельного парка?
Берите живые диалоги с 6–8 репликами, длинные сообщения перед простым вопросом, расплывчатые запросы и случаи, где нужен отказ. Если модель не теряет инструкцию, не спорит с пользователем и не выдумывает детали, ее можно ставить на заметную часть чатовых задач.
Что проверить на извлечении данных из текста в первую очередь?
Сначала проверьте повторяемость. Прогоните похожие документы несколько раз с одним промптом и посмотрите, меняется ли JSON. Потом дайте модели шумный текст, другой порядок полей и документы с пропусками. Нормальный результат — однотипный формат и null там, где данных нет.
Когда классификация уже просит отдельную модель?
Пока меток мало и они заметно отличаются, одна модель часто справляется нормально. Проблемы начинаются на близких классах, длинных правилах и редких метках. Если спорных случаев много, лучше вынести эту часть в отдельный маршрут.
Почему модерацию часто выделяют раньше чата и извлечения?
Потому что цена ошибки там выше. Неровный ответ в чате обычно переживают, а пропуск угрозы, токсичности или утечки персональных данных тянет жалобы, ручной разбор и риск для комплаенса. Поэтому модерацию часто отделяют раньше остальных задач.
Сколько примеров нужно для нормальной проверки модели?
На быстрый старт обычно хватает 50–100 примеров на задачу. Для решения перед релизом лучше собрать 100–300 реальных кейсов отдельно для чата, извлечения, классификации и модерации. Меньше — и выводы слишком легко ломаются от пары удачных примеров.
Как заранее задать порог, после которого нужен второй маршрут?
Зафиксируйте его до теста. Например: извлечение нужных полей не ниже 98%, JSON ломается не чаще одного раза на 200 запросов, ложные блокировки в модерации не выше 2%, задержка укладывается в ваш лимит. Такой порог режет споры внутри команды.
Как правильно считать стоимость, если модель вроде бы дешевая?
Чаще всего команды смотрят только на цену тысячи запросов и забывают про ретраи, ручные правки и ночные разборы. Считать лучше стоимость месяца под вашей нагрузкой: сколько выйдет трафик, сколько ошибок уйдет на ручную проверку и сколько времени съест новый маршрут.
Можно ли сравнить несколько моделей без переделки приложения?
Да, это удобно. Через единый OpenAI-совместимый эндпоинт можно гонять один и тот же набор сценариев без смены SDK, кода и промптов. В RU LLM это помогает спокойно сравнить open-weight и frontier-модели, а потом включить отдельный маршрут только там, где есть явный провал.