Анонимизация или псевдонимизация LLM-журналов по 152-ФЗ
Сравниваем анонимизацию или псевдонимизацию LLM-журналов: что выбрать для аналитики, аудита и расследования инцидентов по 152-ФЗ.
Где в журналах LLM появляется риск
Риск в LLM-журналах начинается не только с поля prompt. Персональные данные расползаются по всей цепочке запроса и ответа, и команда часто замечает это слишком поздно.
Первый источник очевиден - сообщение пользователя. В промпт легко попадают ФИО, телефон, email, номер договора, адрес, дата рождения, детали заказа или жалобы. Если бот помогает оператору, туда же нередко уходят внутренние идентификаторы клиента. Даже без имени они уже могут указывать на конкретного человека.
Но на этом проблема не заканчивается. Модель часто повторяет данные из запроса. Если пользователь пишет: "Проверьте статус договора 45821 на Иванова Ивана", ответ может вернуть и имя, и номер договора, и часть истории обращения. Один и тот же набор данных в итоге живет сразу в нескольких полях лога.
Частая ошибка - считать опасным только user_message. На деле риск есть и в других частях журнала: в tool calls с параметрами поиска по CRM или биллингу, в результатах вызовов инструментов, во вложениях, в служебных метаданных вроде user_id, session_id, IP, tenant или номера обращения. Tool calls и вложения обычно опаснее обычного текста. В них больше контекста, а значит, проще восстановить картину о человеке, даже если явного ФИО нет ни в одном поле.
При этом команде нужен исходный след. Без него трудно понять, почему модель ошиблась, какой инструмент вернул лишние данные и на каком шаге произошел сбой. Для аудита и разбора инцидента полезен не только итоговый ответ, но и весь маршрут запроса.
Здесь и возникает конфликт. Полный лог "на всякий случай" удобен для инженеров, но по 152-ФЗ это плохая привычка. Чем больше сырого текста, вложений и промежуточных результатов вы храните, тем выше ущерб при утечке, шире внутренний доступ и сложнее доказать, что вы собираете только нужное.
Если запросы проходят через единый LLM-шлюз, риск выше еще и потому, что через одну точку идут разные модели, провайдеры и сценарии. Достаточно одного неаккуратного логгера, чтобы в хранилище оказалось больше данных, чем команда собиралась сохранять.
Чем отличаются два подхода
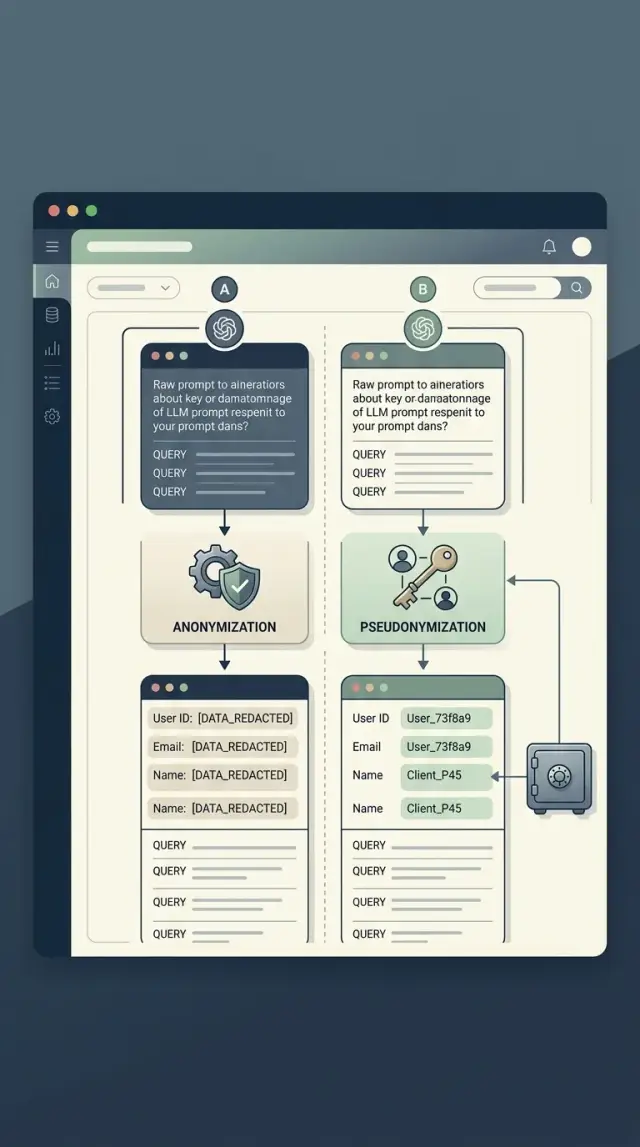
Разница простая: после анонимизации запись уже нельзя надежно связать с человеком, а после псевдонимизации связь остается, но хранится отдельно и под жестким доступом.
Анонимизация
При анонимизации из журнала убирают или необратимо меняют признаки, по которым можно выйти на конкретного человека. Это не только email или телефон. Сюда же часто попадают user_id, номер договора, редкий адрес, точное время действия и фрагменты свободного текста, где пользователь назвал себя сам.
Такой журнал хорошо подходит для общей аналитики. По нему можно смотреть частоту запросов, долю ошибок, стоимость по моделям и темы обращений. Но если через месяц придет жалоба на ответ чат-бота, вернуться к исходному диалогу и точно понять, кто пострадал, уже не получится или будет слишком сложно.
Псевдонимизация
При псевдонимизации идентификаторы заменяют на токены. Например, user_id становится user_7f3a, а связь между токеном и реальным пользователем хранится в отдельной таблице или сервисе. У этой связки должны быть свой доступ, свой журнал обращений и узкий круг сотрудников.
Для аудита и расследований это заметно удобнее. Команда видит, что один и тот же user_token запускал цепочку запросов, получил конкретный ответ и потом создал обращение в поддержку. Если нужно, уполномоченный сотрудник поднимает таблицу соответствия и восстанавливает первоисточник.
На практике выбор выглядит так. Анонимизация удобна, когда вы хотите считать, сравнивать и строить отчеты без привязки к человеку. Псевдонимизация нужна там, где важно сохранить след событий и иметь возможность разобрать спорный случай. При этом псевдонимизированные журналы все равно остаются персональными данными по 152-ФЗ, потому что связь можно восстановить.
Обычно рабочая схема не бывает единой для всего. Часто команды держат три слоя: короткоживущий защищенный слой с исходными данными, рабочий журнал с токенами для аудита и отдельный обезличенный слой для аналитики и отчетов. Это заметно снижает риск и не ломает разбор инцидентов.
Как выбрать схему
Начинать лучше не с терминов, а с реального состава лога. В LLM-журналах обычно есть текст запроса и ответа, user_id или account_id, session_id, IP, время, model, provider, trace_id, токены, стоимость, задержка, код ответа, версия промпта и служебные флаги. И почти всегда туда случайно попадают данные из самого диалога: email, телефон, номер договора и другие идентификаторы.
Дальше решайте по цели каждого поля. Если оно нужно только для общей статистики, личная привязка там почти всегда лишняя. Если без поля нельзя восстановить цепочку событий по жалобе или спорной операции, ранняя анонимизация помешает расследованию.
Удобно пройтись по пяти вопросам:
- Какие поля реально пишет приложение, SDK, прокси и система наблюдения? Смотрите не документацию, а живой пример лога.
- Зачем нужно каждое поле? Метрики, аудит, расследование, отладка - это разные задачи.
- Кому нужен доступ? Аналитикам обычно хватает агрегатов и хешей, поддержке - маскированных фрагментов, ИБ и комплаенсу - обратимой связи с человеком по заявке.
- Какой срок хранения у каждого слоя? Сырые логи должны жить меньше, чем обезличенная статистика.
- Сможете ли вы разобрать типовой инцидент без открытия лишних данных всей команде?
На практике многим подходит смешанный вариант. Текст промпта и ответа маскируют или режут до безопасного фрагмента, идентификаторы пользователя переводят в псевдонимы, а таблицу соответствия держат отдельно под строгим доступом. Так аналитика логов не ломается, а аудит и расследование остаются возможными.
Что оставить для аналитики
Для аналитики обычно не нужен полный текст запроса и ответа. Команде хватает метаданных, по которым видно стоимость, скорость, частоту сбоев и изменения по маршрутам моделей. Это снижает риск и не мешает следить за поведением системы по дням, сценариям и провайдерам.
В аналитическом слое стоит оставлять только то, что можно посчитать и сравнить: входные и выходные токены, задержку, время в очереди, длительность стрима, код ответа, тип ошибки, маршрут модели и стабильный псевдоним сессии или пользователя. Этого достаточно, чтобы понять, почему вырос чек, где просела скорость и на каком маршруте чаще появляются 429 или 500. Текст для этого не нужен.
Для аналитики чаще выигрывает псевдонимизация, а не полная анонимизация. Полная анонимизация быстро ломает сквозные метрики: становится трудно посчитать повторные ошибки, длину сессии или разницу между новыми и постоянными пользователями. Стабильный псевдоним решает эту задачу лучше, если таблица соответствия хранится отдельно и доступ к ней есть у узкого круга сотрудников.
Сессии лучше группировать по техническому идентификатору, а не по ФИО, email или номеру телефона. Обычно для этого хватает внутреннего ID, пропущенного через HMAC или другой обратимо не читаемый способ, который дает один и тот же результат для одного пользователя, но не раскрывает его личность в аналитике.
Свободный текст лучше маскировать до записи в хранилище. Если текст не нужен для метрики, не сохраняйте его вообще. Если нужен небольшой набор для оценки качества, храните его отдельно, после маскирования PII и с коротким сроком жизни.
Продуктовые метрики и сырые журналы лучше разводить по разным контурам. В витрину для аналитиков отправляйте агрегаты и безопасные поля. Сырые журналы, если они вообще нужны, держите в более закрытом хранилище с другим сроком хранения и другим уровнем доступа.
Что нужно для аудита
Для аудита мало знать, что запрос был. Нужно восстановить цепочку действий: кто его отправил, под какой ролью работал, какая модель ответила, какой провайдер участвовал, какая версия промпта была активна. Иначе журнал есть, а проверить решение нельзя.
Здесь почти всегда нужна псевдонимизация. Полная анонимизация удобна для статистики, но она ломает проверку конкретного случая. Аудитор должен иметь возможность связать событие с человеком или сервисным аккаунтом, если на это есть законное основание и оформленный доступ.
Минимальный набор полей для аудита обычно включает время события с часовым поясом, внутренний идентификатор субъекта и его роль, идентификатор запроса или сессии, модель, провайдера, маршрут запроса и версию промпта или шаблона.
Это особенно важно, если команда меняет модели через единый API-шлюз. Один и тот же код приложения сегодня может уйти к одному провайдеру, а завтра к другому. Если в журнале нет провайдера и версии промпта, аудит быстро превращается в догадки.
Таблицу соответствия между псевдонимом и реальным человеком держите отдельно от основных журналов. Лучше в другом контуре доступа, с отдельными правами и своей историей обращений. Тогда утечка обычных логов сама по себе не раскрывает личность.
Расшифровку давайте только по заявке. У заявки должны быть номер, основание и срок доступа. И еще одно правило, которое часто забывают: логируйте сам факт расшифровки. Кто открыл соответствие, когда, по какой причине и какие записи посмотрел - это тоже часть аудита.
Со сроком хранения лучше не гадать. Возьмите внутренний регламент, цель обработки и требования 152-ФЗ, а потом проверьте, совпадает ли это с тем, как система реально удаляет данные. Частая ошибка проста: в политике указано 90 дней, а резервные копии лежат полгода.
Как разбирать инцидент без потери следов
При разборе инцидента хуже всего две крайности: открыть всем сырые логи или, наоборот, пытаться работать только по обезличенным сводкам. В первом случае команда выходит за пределы нужного доступа. Во втором теряет цепочку событий и не может понять, что именно произошло.
Рабочая схема обычно строится вокруг псевдонимизации. Она дает путь от жалобы к конкретному запросу, но не раскрывает личные данные всем участникам разбора. Если журналы анонимизированы без возможности обратной связи, расследование быстро упирается в предположения.
Практический порядок такой:
- Зафиксируйте опорные данные: ID запроса, время, затронутый сервис, среду, версию промпта или маршрута модели.
- Найдите всю цепочку событий по псевдониму сессии: входной запрос, вызов модели, фильтры, ретраи, ответ клиенту, действия после ответа.
- Сверьте технические признаки: кто запустил запрос, какой токен или ключ использовался, был ли prompt caching, менялся ли провайдер по маршрутизации.
- Открывайте расшифровку только если без нее нельзя подтвердить факт инцидента или уведомить нужного человека.
- Записывайте причину, выводы и меры в отдельную карточку инцидента, а не в сам журнал запросов.
Такой порядок сохраняет следы и снижает лишний доступ. Команда сначала смотрит на события и причинную связь, а не на персональные данные. На практике это еще и быстрее: по request ID и времени проще собрать картину, чем читать большие выгрузки с полными диалогами.
После разбора доступ нужно закрыть сразу. Временные выгрузки удаляют, локальные файлы очищают, а право на расшифровку отзывают у всех, кому оно больше не нужно. Иначе само расследование создает новый риск уже внутри команды.
Пример: жалоба после ответа чат-бота
Клиент банка пишет в поддержку: чат-бот ответил на вопрос по карте и вдруг показал чужой номер договора. Ошибка неприятная сама по себе, но для команды риск шире. Нужно быстро понять, откуда появился этот фрагмент: из текущего запроса, из истории диалога, из кэша, из RAG-источника или из чужой сессии.
На таком кейсе хорошо видно, что анонимизация и псевдонимизация дают разный результат. Обе меры снижают риск, но для расследования работают по-разному.
Если банк хранит только анонимизированный лог, команда обычно видит факт сбоя: время ответа, модель, статус, размер промпта, наличие цифр, похожих на номер договора. Но дальше след обрывается. Нельзя связать ответ с конкретной пользовательской сессией, проверить исходный текст жалобы и понять, был ли номер в первичном запросе или система подтянула его откуда-то еще.
В псевдонимизированном логе картина лучше. Имя клиента, номер телефона и договор скрыты, но сессия помечена устойчивым идентификатором. По нему команда связывает жалобу с одной цепочкой событий: входной запрос, системный промпт, найденные документы, ответ модели и последующие повторы.
Дальше помогает отдельная таблица соответствия. Ее держат вне основного контура логов и открывают только для разбора инцидента по строгому доступу. Тогда сотрудник ИБ или владелец сервиса может ответить на главный вопрос: номер договора пришел от пользователя или система показала чужие данные сама.
Обычно проверка идет в три шага: находят псевдоним сессии из жалобы, поднимают цепочку запросов и ответов за нужный промежуток, а затем через таблицу соответствия сверяют первичный запрос и реальные поля, если для этого есть основание. После такого разбора команда уже меняет систему, а не просто закрывает тикет. Чаще всего она маскирует номер договора еще до отправки в модель, убирает его из открытых журналов и правит правила логирования.
Где команды чаще ошибаются
Большинство промахов начинается с привычки "залогируем все, потом разберемся". В LLM это быстро превращается в полный промпт, ответ модели, почту, номер телефона и фрагменты договора в одном журнале. Так делают даже в тестовых средах, хотя контроль доступа там обычно слабее.
Еще одна частая ошибка - использовать один и тот же идентификатор пользователя во всех системах. Если одинаковый user_id живет в API-шлюзе, журнале приложения, BI и саппорте, любой человек с доступом к двум таблицам легко собирает полную историю действий. Для псевдонимизации это плохая схема: она упрощает аналитику, но почти убирает защиту от повторной идентификации.
Не лучше и вариант, когда таблицу соответствия кладут рядом с основным логом. Тогда псевдоним и его расшифровка лежат в одном бакете, одной БД или под одной ролью доступа. При утечке или ошибке в правах раскрывается все сразу.
Схема обычно ломается в нескольких типовых местах:
- raw-промпты попадают в dev и stage так же, как в prod;
- один токен пользователя используют во всех хранилищах и отчетах;
- таблица сопоставления лежит рядом с журналом запросов;
- инженеры держат постоянный доступ к расшифровке "на случай дебага";
- команда ни разу не проверяла разбор типового инцидента на практике.
Постоянный доступ инженеров к расшифровке обычно объясняют удобством. По сути это широкий просмотр персональных данных без конкретной цели. Гораздо лучше работает временный доступ по заявке: есть номер инцидента, срок и запись о том, кто и зачем открыл данные.
Есть и более тихий промах - дублирование сырых данных в соседние системы. Если шлюз уже маскирует PII и пишет след аудита, не стоит отправлять полный текст запросов в отдельный observability-стек "для надежности". Именно такие вторые копии потом всплывают в инцидентах, потому что о них забывают быстрее всего.
Проверить схему можно простым тестом. Возьмите одну жалобу на ответ чат-бота и попробуйте за 30 минут понять, какой запрос пришел, какая модель ответила, кто открывал расшифровку и какие поля маскировались. Если без полного raw-лога вы ничего не можете доказать, схема еще сырая. Если доказать можно, а лишние данные никто не видит, вы на верном пути.
Короткий чек-лист и следующие шаги
Спор между анонимизацией и псевдонимизацией лучше решать не по привычке, а по задаче. Если команде нужны только сводные цифры по качеству, нагрузке и стоимости, начинайте с анонимизации. Если нужно разбирать жалобы, спорные ответы чат-бота или внутренние инциденты, одной анонимизации почти всегда мало.
Рабочая схема обычно выглядит так:
- Для продуктовой аналитики оставляйте только те поля, которые нельзя вернуть к человеку напрямую.
- Для аудита и расследований используйте псевдонимы вместо прямых идентификаторов.
- Таблицу соответствия храните отдельно, под жестким доступом и с журналом обращений.
- Заранее определите, кто может восстанавливать личность и по какому основанию.
- Проверяйте схему на реальных логах, а не только на политике и диаграммах.
Если анонимизированных данных хватает для ежедневных отчетов, не усложняйте контур. Если без связи с конкретным обращением вы не можете ответить на жалобу клиента или восстановить ход инцидента, оставляйте псевдонимы, но сильно ограничивайте круг людей и действий.
На пилоте особенно удобно проверять схему там, где маскирование PII, хранение данных в РФ и audit trail уже встроены в запросный слой. Например, в RU LLM это можно проверить на одном OpenAI-совместимом эндпоинте без смены SDK, кода и промптов. Такой пилот быстро показывает, какие поля стоит удалить, какие замаскировать, а какие оставить только под строгим доступом.