Лимиты запросов по командам и сервисам без перегрузки
Лимиты запросов по командам и сервисам помогают разделить квоты между продуктами, сдержать шумный трафик и сохранить стабильность общего контура.
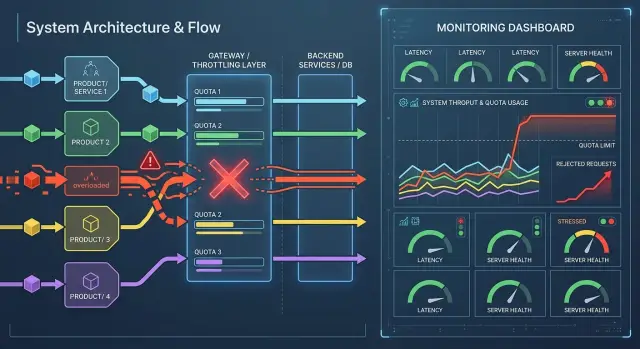
Откуда берется общий сбой
Общий сбой редко начинается с большой аварии. Чаще все ломает обычный всплеск в одном сервисе: массовая генерация, тест, переиндексация или неудачный цикл повторов после ошибки. Поток запросов резко растет и быстро съедает общий запас пропускной способности.
Если несколько команд пользуются одним контуром API, лимит почти всегда общий, даже когда кажется, что нагрузка у каждого сервиса своя. Так и ломаются лимиты запросов по командам и сервисам: один шумный сценарий забирает весь доступный запас, а остальные получают задержку без своей вины.
Дальше проблема растет по цепочке. Спокойные сервисы продолжают отправлять нормальный трафик, но их запросы уже встают в очередь. Очередь становится длиннее, время ответа растет, воркеры заняты дольше обычного. Через несколько минут деградация доходит и до тех частей системы, где нагрузка почти не менялась.
Особенно неприятны автоматические повторы. Когда сервис получает 429 или таймаут, он часто сразу пытается отправить запрос еще раз. На малом масштабе это помогает. В общем контуре такой подход легко превращает локальный всплеск в самоподдерживающуюся перегрузку: первый пик вызывает ошибки, ошибки включают повторы, а повторы создают новый пик.
В LLM-сценариях это видно особенно быстро. Допустим, у компании три продукта ходят через один OpenAI-совместимый адрес API, например через RU LLM. Один продукт запускает кампанию и резко увеличивает число обращений к модели. Даже если два других продукта работают ровно, их пользователи начинают ждать дольше, а часть запросов получает 429 или обрывается по таймауту.
Пользователь не видит внутреннюю причину. Он видит медленный чат, зависший ассистент, повторную отправку формы или пустой ответ. Для бизнеса это выглядит как общий сбой всей платформы, хотя источник часто очень узкий: один сервис без своей квоты, один бесконтрольный ретрай или одна задача, которую пустили в общий лимит вместе с живым пользовательским трафиком.
Пока трафик ровный, проблема скрыта. Как только один сценарий шумит громче остальных, страдают все.
Что считать квотой
Квота - это не один общий лимит на все случаи. Если считать только количество запросов, вы пропустите момент, когда сервис еще не уперся в частоту вызовов, но уже сжег бюджет или забил очередь длинными генерациями. Для LLM-нагрузки квота почти всегда состоит из нескольких ограничений сразу.
Для живого трафика обычно смотрят на запросы в минуту. Это понятная метрика для чатов, поиска и подсказок в интерфейсе. Она быстро показывает, что какой-то сценарий внезапно начал слать в несколько раз больше вызовов, чем обычно.
Но для генеративных задач одной частоты мало. Два сервиса могут отправлять одинаковое число запросов, а нагрузка у них будет разной: один просит короткий ответ, другой тащит длинный контекст и получает длинную генерацию. Поэтому для LLM почти всегда нужен еще и лимит по токенам в минуту.
Обычно квота включает несколько частей: запросы в минуту для онлайн-сценариев, токены в минуту для чатов и суммаризации, ограничение на число параллельных задач для пакетной обработки, денежный потолок на день или месяц и, при необходимости, отдельные лимиты по модели или провайдеру.
Параллельность стоит ограничивать отдельно. Пакетная обработка часто ломает контур не частотой входящих вызовов, а числом одновременных задач. Например, ночная переиндексация запускает сотни jobs, каждая держит длинный запрос, и интерактивный чат начинает ждать. Если поставить потолок на число параллельных заданий, пакетная обработка замедлится, но прод не встанет.
Денежный лимит тоже нужен. Он ловит случаи, когда технические метрики еще выглядят нормально, а команда случайно переключилась на дорогую модель и за день выбрала недельный бюджет. Дневной потолок защищает от резкого скачка, месячный помогает держать план расходов.
Разделение по модели и провайдеру часто дает самый заметный эффект. Цены, скорость и внешние лимиты у моделей сильно отличаются. Если вы работаете через единый шлюз и маршрутизируете трафик между разными провайдерами, такой разрез особенно полезен: одна квота держит массовый трафик на более дешевой модели, другая резервирует дорогую модель только для тех сценариев, где она правда нужна.
Если коротко, квоты для API работают только тогда, когда вы считаете не одно число, а несколько разных ограничений под разную нагрузку.
Где ставить границы
Общий лимит на весь контур почти всегда плохая идея. Если один продукт внезапно уходит в повторы, делает массовую индексацию или запускает неудачный эксперимент, он быстро съедает весь запас и тянет за собой остальных.
Первая граница проходит между командами. У каждой команды свой ритм релизов, свои пики и свои ошибки. Если поддержка, поиск и внутренний аналитический сервис сидят в одном пуле, вы не поймете, кто именно выбрал квоту, пока пользователи уже ждут ответа.
Разделение по слоям
Внутри команды полезно сразу отделить пользовательские сценарии от фоновых задач. Чат с клиентом, проверка документа и генерация ответа в интерфейсе должны жить отдельно от ночных jobs, массового эмбеддинга, evaluation и переиндексации. Фон легко разрастается и забирает все, если дать ему тот же лимит, что и продукту с живыми пользователями.
Следующий уровень - конкретный сервис или поток вызовов. Генерация ответов, embeddings, rerank и пакетная обработка не должны делить один потолок просто потому, что они относятся к одному продукту. Жесткий предел нужен именно на тот поток, который может стать шумным соседом. Где-то это будет лимит по запросам в минуту, где-то по токенам, а где-то по параллельности.
Даже если у вас несколько продуктов ходят через один адрес API, границы все равно должны оставаться раздельными. Один вход не означает один общий пул.
На практике хорошо работает простая схема: отдельная квота на команду, отдельные лимиты на пользовательский трафик и фон, жесткий потолок на каждый сервис внутри продукта, изолированный контур для тестов и небольшой резерв для ручных разборов и срочных задач.
Резерв лучше держать маленьким и не раздавать по умолчанию. Он нужен для инцидента, короткой проверки после фикса или важного релиза, а не для постоянной жизни еще одного сервиса.
Прод, тест и эксперименты смешивать не стоит. Тестовый прогон редко ведет себя аккуратно: кто-то поднял температуру, забыл про кеш, включил длинный контекст, и лимит ушел за час. Когда среды разделены, такой сбой остается локальным.
Если границы стоят на этих уровнях, ночная пакетная задача просто замедлится, а клиентский сценарий продолжит отвечать.
Как раздать квоты по шагам
Если делить лимиты на глаз, самый шумный сценарий быстро съест общий запас. Потом страдают все: и продукт с живыми пользователями, и фоновые задачи, и интеграции, которые в обычный день вели себя тихо.
Начните с полного списка потребителей трафика. Сюда входят не только продукты и команды, но и тестовые стенды, ночные jobs, переобучение, отчеты, внутренние боты и ручные скрипты поддержки. В контурах с LLM это особенно заметно: один массовый прогон через единый API может забрать лимит у всего остального.
Потом разделите сценарии по терпимости к задержке. Одни запросы спокойно ждут 5-10 минут в очереди. Другие нельзя душить даже на пике: вход пользователя, проверка заявки, ответы клиентам в рабочее время. Если не отметить это заранее, все получат одинаковые цифры, хотя цена ошибки у них разная.
После этого посмотрите на метрики хотя бы за месяц. Одного спокойного дня мало. Нужны обычная нагрузка, часовые пики, дни релизов, маркетинговые акции и пакетные прогоны. Для LLM лучше смотреть не только число запросов, но и токены, потому что два сервиса с одинаковой частотой вызовов могут нагружать контур совсем по-разному.
Дальше каждому продукту задают базовую квоту для обычного дня с небольшим запасом, сверху ставят жесткий максимум, а для критичных сценариев держат отдельный резерв. Пакетные задачи лучше сразу переносить в отдельное окно или на отдельный лимит. И у каждой квоты должен быть владелец.
Этот шаг многие пропускают. Лучше всего работает простое правило: владелец сервиса подает запрос на изменение лимита, дежурный или платформенная команда смотрит метрики и меняет квоту на понятный срок. Без такого порядка временное исключение быстро превращается в постоянную дыру.
Как пережить всплеск
Всплеск сам по себе не проблема. Проблема начинается, когда короткий рост трафика съедает весь общий лимит и пользовательские сценарии ждут вместе с фоном. Нормальная схема устроена так: системе можно дать немного воздуха, но выше заданного потолка она не идет.
Обычно помогает двухуровневое правило. Для интерактивных запросов вы разрешаете короткий всплеск на несколько секунд или минут, чтобы пережить резкий приток. После этого срабатывает жесткий потолок, и лишний трафик не выдавливает весь остальной контур.
Фоновые задачи лучше сразу убирать из общего потока. Ночные пересчеты, массовые суммаризации, переиндексация и генерация черновиков должны идти через очередь с отдельной скоростью выдачи. Если пустить такие задачи напрямую, один удачный запуск кампании легко создает шумного соседа в общем контуре.
Когда квота заканчивается, важно снижать нагрузку по очереди. Сначала ограничивают пакетную обработку и прочий фон. Потом урезают дорогие необязательные вызовы. Затем переводят некритичные маршруты на более простую или менее загруженную модель. Основной пользовательский поток трогают последним.
Еще одна частая ошибка - агрессивные повторы. Если сервис получает 429 или таймаут и тут же шлет новый запрос, пик только растет. Лучше сократить число попыток, добавить backoff и случайную паузу между ними. Даже 300-800 мс jitter часто снимают цепную реакцию на уровне нескольких сервисов.
Запасной маршрут тоже нужен заранее, а не в день аварии. Для части трафика можно держать переход на более дешевую или менее загруженную модель. Если трафик идет через RU LLM, правило маршрутизации можно поменять на стороне шлюза, не переписывая клиентские SDK, код и промпты. Это удобно именно в момент всплеска, когда времени на доработки уже нет.
Хороший пример выглядит так: чат поддержки остается на быстром основном маршруте, а пакетная обработка 50 тысяч обращений уходит в очередь и при пике переключается на более дешевую модель. Пользователь почти не замечает всплеск, а защита общего лимита не ломается.
Пример для трех продуктов
Представим команду с общим лимитом 100 запросов в минуту к LLM. У нее есть три сценария: чат поддержки для клиентов, поиск по базе знаний для сотрудников и ночная оценка промптов. Если пустить их в один пул без правил, ночной прогон или всплеск поиска легко съест весь запас.
Рабочее распределение может быть таким:
- чат поддержки - 50 запросов в минуту, резерв постоянный, приоритет самый высокий;
- поиск по базе знаний - 30 запросов в минуту и короткий запас до 40 при всплеске;
- ночная оценка промптов - 20 запросов в минуту, но только через отдельную очередь.
На бумаге это не выглядит идеально ровным. Зато схема хорошо ведет себя под нагрузкой. Чат не зависит от того, сколько документов сейчас ищут сотрудники и сколько тестов гоняет ML-команда. Поиск получает свою среднюю квоту и небольшой запас, потому что у него бывают короткие пики, например после обновления базы или рассылки по саппорту.
С пакетной обработкой лучше не спорить. Ночная оценка промптов редко требует ответа прямо сейчас, поэтому ей не нужен доступ к лимиту в реальном времени. Очередь забирает свободные слоты постепенно. Если днем начинается пик, новые задачи просто ждут окна, а не выталкивают живой трафик.
Представим обычный день. В 11:15 у чата поддержки резкий рост после сбоя в мобильном приложении. Чат забирает свои 50 запросов в минуту и продолжает отвечать. Поиск держится в своей зоне и может коротко подняться до 40. Оценка промптов не лезет вперед и остается в очереди до вечера.
Пользователи почувствуют это по-разному. Клиент в чате получит ответ почти сразу. Сотрудник поддержки иногда подождет поиск на пару секунд дольше. Аналитик, который запустил ночной прогон днем, увидит статус "в очереди". Это нормальный обмен: менее срочный сценарий уступает место тому, где каждая минута заметна.
Отдельный учет по каждому продукту обязателен. Даже если все сервисы ходят через один OpenAI-совместимый адрес API, их стоит разделять по проектам, ключам или меткам учета. Тогда команда видит, кто съел лимит и деньги: чат, поиск или оценка. Без этого любой спор заканчивается фразой "API опять тормозит", а это почти всегда слишком грубое объяснение.
Где чаще всего ошибаются
Самая частая ошибка проста: общий лимит делят поровну. На бумаге это выглядит честно. В работе почти всегда выходит перекос.
У одного продукта 10 тысяч коротких запросов в час, у другого 300 тяжелых обращений с длинным контекстом, а у третьего редкий, но очень чувствительный трафик. Если всем дать одинаковую квоту, один сервис будет простаивать, второй упрется в потолок, а третий сорвет SLA в самый плохой момент. Лимиты запросов по командам и сервисам нужно считать от реальной нагрузки, а не от числа владельцев.
Вторая ошибка - смотреть только на количество запросов. Для LLM этого мало. Один запрос на 200 токенов и один запрос на 20 тысяч токенов для общего контура вообще не равны. Если смотреть только на запросы в минуту, тяжелый сценарий спокойно съест весь запас по токенам и положит соседние сервисы, хотя формально лимит по запросам никто не превысил.
Еще одна типичная проблема - одинаковый приоритет у пакетной обработки и пользовательского трафика. Ночной импорт, массовая разметка, генерация отчетов и переиндексация не должны конкурировать с чатом поддержки, оплатой или помощником операторов. Пакетная задача подождет. Прод не должен ждать.
Плохие признаки видны быстро: после жалобы просто поднимают лимит одному сервису, никто не знает, кто сжег токены за последний час, клиенты после 429 шлют новые запросы без паузы, а несколько сервисов ходят в API под одним общим ключом.
Поднять лимит после инцидента легко. Но если правила остались прежними, вы просто переносите сбой на следующую неделю. Нужны отдельные квоты, приоритеты и жесткие пределы для шумных сценариев.
Отдельный промах прячется в клиентах. Команда видит 429 и считает, что проблема в шлюзе или провайдере. А потом выясняется, что SDK делает мгновенный retry пять раз подряд. Так локальная перегрузка превращается в лавину. Проверьте backoff, лимит повторов и поведение очередей.
И последнее: один общий ключ на все сервисы почти всегда ломает диагностику. Пока вы не разделили трафик по ключам, командам или хотя бы по меткам, вы не увидите, кто шумит, кто простаивает и кому правда нужна дополнительная квота.
Короткий список проверок
Хорошая схема квот видна не в таблице, а в момент всплеска. Если один продукт внезапно вырос в три раза, команда должна сразу понять, кто съедает лимит, что можно притормозить и кто может дать временный запас.
Сначала проверьте ownership. У каждого продукта, сервиса или крупного сценария должен быть конкретный владелец квоты. Не "платформенная команда" и не "все вместе", а человек или роль, которые отвечают за лимит, следят за расходом и согласуют изменения. Иначе шумный сосед в общем контуре останется ничьей проблемой до первого сбоя.
Потом посмотрите на метрики. Одного графика по общему трафику мало. Нужны остаток лимита по каждому продукту, пики по времени, доля 429, рост очереди и скорость повторных попыток. В общем LLM-шлюзе это особенно заметно: если вы видите только суммарную картину, то не поймете, кто именно выбил защиту общего лимита.
Еще один простой тест - поведение клиента, когда лимит кончился. Нормальный клиент ждет, делает backoff и снижает частоту запросов. Плохой клиент начинает спамить повторами и сам превращает короткий всплеск в аварию на полчаса.
Отдельно проверьте фоновые задачи. Индексация, пакетная оценка, массовая генерация и ночные пересчеты должны уметь останавливаться без вреда для основного потока. Если фон нельзя быстро приглушить, он почти всегда конкурирует с пользовательскими запросами в самый плохой момент.
Наконец, заранее определите правило эскалации: кто принимает решение, на какой срок можно поднять лимит и что происходит потом. Например, продукт получает плюс 20% на два часа, затем лимит автоматически возвращается, а команда разбирает причину всплеска на следующий рабочий день. Если на любой из этих вопросов ответ звучит расплывчато, схема еще сырая.
Что сделать дальше
Начните с одного реестра, даже если это обычная таблица. В нем должны быть все продукты, сервисы, владельцы и их квоты. Пока такого списка нет, распределение трафика между продуктами почти всегда превращается в набор исключений, о которых помнит один человек.
В реестре достаточно пяти полей: владелец сервиса, базовый лимит, допустимый короткий всплеск, правило при упоре в квоту и получатель сигнала, если расход уходит выше нормы.
Потом возьмите самый шумный сценарий за последнюю неделю и запустите на нем пилот. Не пытайтесь сразу закрыть весь контур. Если один сервис чаще других съедает общий запас, проверьте его первым: сколько запросов он дает в минуту, где у него пики и как меняется картина после отдельной квоты. Обычно уже на этом шаге видно, где запас тратится зря.
Раз в месяц сверяйте лимиты с фактическим расходом. Квота, которую назначили полгода назад, редко остается правильной. Один продукт растет, другой переезжает на кеш, третий меняет модель и начинает тратить вдвое больше. Если не пересматривать цифры, защита общего лимита быстро становится формальностью.
Если вы ведете LLM-трафик через RU LLM, полезно заранее договориться, как помечать продукт, сервис и провайдера в каждом запросе. Тогда по встроенным аудит-трейлам проще увидеть, кто именно создал нагрузку, на какую модель ушел трафик и где начался рост затрат. Для контуров с персональными данными это еще практичнее: логи и бэкапы хранятся в РФ, а маскирование PII помогает не тащить чувствительные поля в разбор инцидента.
И отдельно проверьте правила для трафика, который подпадает под 152-ФЗ. Нужно точно знать, где лежат логи, кто их читает и какие поля попадают в трассировку. Такие детали нельзя оставлять на потом.
Если сделать только три шага на этой неделе, хватит и этого: собрать реестр, включить пилот на самом шумном сценарии и назначить ежемесячный пересмотр квот. После этого квоты перестают быть бумажным правилом и начинают защищать систему в реальной нагрузке.
Часто задаваемые вопросы
Почему один сервис может замедлить все остальные?
Обычно один шумный сценарий быстро забирает общий запас запросов, токенов или параллельных задач. Остальные сервисы не растят нагрузку, но встают в ту же очередь и начинают ловить задержки, 429 и таймауты.
Какие квоты нужны для LLM, кроме запросов в минуту?
Для LLM мало считать только запросы в минуту. Смотрите еще токены в минуту, число одновременных задач и денежный потолок на день или месяц, иначе длинные генерации или дорогая модель тихо съедят весь запас.
Хватит одного общего лимита на весь API?
Общий лимит на весь контур почти всегда создает проблемы. Лучше сначала разделить квоты по командам или продуктам, а потом внутри них развести живой трафик, фоновые задачи и отдельные сервисы.
Как отделить пользовательский трафик от фоновых задач?
Сразу дайте чату, поиску и другим сценариям с пользователем свой лимит и свой приоритет. Переиндексацию, evaluation, массовую генерацию и прочий фон отправляйте в очередь с отдельной скоростью, чтобы они ждали окно, а не спорили с продом за один и тот же ресурс.
Что делать с 429 и таймаутами?
Не шлите новый запрос сразу после ошибки. Сократите число повторов, добавьте backoff и случайную паузу между попытками, чтобы сервис не превратил короткий пик в долгую перегрузку.
Как выдать стартовые квоты без гадания?
Возьмите метрики хотя бы за месяц и посмотрите обычный день, пики, релизы и пакетные прогоны. Потом дайте каждому сценарию базовую квоту с небольшим запасом, сверху поставьте жесткий потолок и назначьте владельца, который просит изменение лимита по факту, а не на глаз.
Как пережить короткий всплеск без общего сбоя?
Разрешите короткий всплеск для интерактивных запросов, но держите жесткий потолок выше этого окна. Когда запас кончается, сначала режьте фон и необязательные вызовы, а основной поток пользователей оставляйте последним.
Как понять, кто именно съедает лимит?
Разделите трафик по проектам, токенам доступа или хотя бы по меткам продукта и сервиса. Тогда вы увидите, кто дал пик, кто сжег бюджет и где именно выросла очередь, вместо общего ощущения, что просто тормозит API.
Как часто пересматривать квоты?
Проверяйте квоты не реже раза в месяц и после заметных изменений в продукте. Новый релиз, смена модели, рост контекста или запуск кеша быстро меняют реальную нагрузку, и старая цифра перестает защищать систему.
Чем помогает единый шлюз вроде RU LLM при раздаче квот?
Если трафик идет через RU LLM, команда может помечать в запросах продукт, сервис и провайдера, а потом разбирать нагрузку по аудит-трейлам. В момент пика можно сменить маршрут на стороне шлюза и перевести часть трафика на другую модель без правок в клиентском коде.