SLA для внутренних клиентов LLM-платформы без путаницы
SLA для внутренних клиентов LLM-платформы нужен отдельно от внешнего SLA: разберем границы, метрики, ошибки и простой порядок согласования.
Почему одного SLA мало
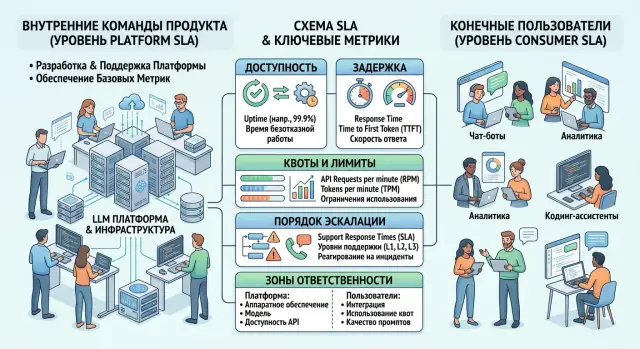
SLA для внутренних клиентов LLM-платформы почти никогда не совпадает с тем, что видит конечный пользователь. У платформы две аудитории с разными ожиданиями, и одна цифра доступности для них мало что объясняет.
Внутренний клиент - это команда продукта, которая встраивает модель в чат, поиск, классификацию заявок или помощника для операторов. Ей нужен рабочий API, понятные квоты, список доступных моделей, правила деградации и живой канал поддержки, если в проде что-то ломается. Для такой команды сбой начинается раньше, чем для пользователя: запросы еще проходят, но внезапно закончился лимит, пропал нужный провайдер или задержка выросла настолько, что сценарий уже не работает.
Конечный пользователь смотрит на другое. Ему все равно, какой провайдер стоит за ответом, через какой шлюз пошел запрос и как команда переключала маршрут между моделями. Он оценивает готовую функцию: ответ пришел или нет, помог ли он решить задачу, уложился ли сервис в пару секунд, не потерялись ли данные и не пришлось ли повторять действие.
Из-за этого один внешний SLA LLM-сервиса легко скрывает разные причины сбоя. API платформы может быть доступен, но нужная модели нет. Ответ может приходить, но слишком медленно для реального сценария. Запрос может формально обработаться, но квота уже исчерпана. Пользователь может не увидеть явной ошибки, пока команда вручную тушит инцидент и режет часть функциональности.
В банке это заметно сразу. Если помощник в мобильном приложении ответил через запасной маршрут и чуть хуже обычного, клиент может не заметить проблему. А вот продуктовая команда заметит: качество просело, чек на токены вырос, включился более дорогой провайдер, а по требованиям 152-ФЗ еще нужно проверить, где прошли логи и как это попало в аудит.
Поэтому мало обещать просто 99,9% доступности. Для внутренних команд нужен отдельный договор о том, как работает сама LLM-платформа. Для пользователя нужен другой договор - о том, как ведет себя функция в интерфейсе. Если смешать эти уровни, спор о качестве начнется в первый же инцидент.
Кто считается внутренним клиентом
У внутреннего клиента есть простой признак: команда зависит от LLM-платформы так же, как от отдельного сервиса, и не может спокойно работать, если платформа тормозит, меняет поведение или теряет доступ к моделям. Когда обсуждают SLA для внутренних клиентов LLM-платформы, речь идет не про всех сотрудников компании, а про тех, кто строит на этой платформе свои процессы, релизы и метрики.
Чаще всего таких клиентов несколько. Это продуктовые команды, которые встраивают LLM в поиск, чат, ассистента оператора, модерацию или генерацию контента. Это аналитика и data science, если они гоняют пакетные задачи, eval, разметку и эксперименты через тот же API. Это безопасность, compliance и юристы, которым нужны логи, audit trail, маскирование PII и контроль по 152-ФЗ. И это операционные команды: поддержка, антифрод, бэк-офис, контакт-центр. У них простой платформы быстро превращается в очередь из ручной работы.
Сводить их в одну группу нельзя. Для продукта больнее всего задержка ответа, скачки качества и лимиты по трафику. Для аналитики важнее окно выполнения задач и стабильные версии моделей. Для безопасности на первом месте не миллисекунды, а полнота логов, хранение данных в РФ и возможность разобрать спорный запрос. Для операционных команд критичен режим деградации: смогут ли люди продолжить работу вручную, если модель недоступна.
Полезно сразу понять, чей простой бьет по выручке, а чей - по срокам. Если LLM помогает продавать или удерживать пользователя в приложении, сбой быстро отражается на деньгах. Если платформа нужна для внутренней разметки, тестов или проверки гипотез, релиз просто уедет на неделю. Оба случая важны, но обещания им нужны разные.
Еще одна частая ошибка - не назначить владельцев с двух сторон. Со стороны платформы нужен человек, который отвечает за доступность, лимиты, инциденты и правила эскалации. Обычно это владелец платформы, руководитель ML Platform или дежурная команда. Со стороны продукта нужен владелец интеграции: продакт, техлид или менеджер сервиса, который понимает, какие сценарии можно замедлить, какие нельзя, и кто согласует компромисс во время сбоя.
Если в документе нет этих двух ролей и списка зависимых команд, SLA останется красивой бумагой. Работать он начинает тогда, когда каждая команда узнает в нем свой реальный риск.
Что платформа обещает внутренним командам
Внутренней продуктовой команде мало общей фразы про доступность сервиса. Ей нужен рабочий договор: какой эндпоинт доступен, сколько запросов платформа держит без просадки, как ведет себя при пике и что происходит, если лимит исчерпан. SLA для внутренних клиентов LLM-платформы обычно фиксирует не только процент аптайма, но и пределы по RPS, concurrency, размеру контекста и очереди.
Для LLM важна не одна задержка, а две. Первая - время до первого токена. Оно влияет на ощущение скорости в чате, в поиске и в подсказках оператору. Вторая - время до полного ответа. Его лучше считать отдельно для коротких и длинных сценариев, иначе цифра выйдет красивой только в отчете. На практике лучше обещать p95 для типовых запросов и отдельно описывать, что происходит с тяжелыми промптами, длинным контекстом и batch-задачами.
Поддержку для внутренних команд тоже нужно описывать прямо: кто отвечает первым, за сколько минут команда получит реакцию по инциденту, когда включается эскалация, куда писать ночью и кто принимает решение о fallback на другую модель или на упрощенный режим. Если этого нет, люди начинают искать знакомых в чате. Это уже не SLA, а лотерея.
Отдельный блок нужен для смены моделей и параметров. Нельзя молча заменить одну модель другой, обновить версию, изменить temperature по умолчанию или формат tool calling. Для внутренних клиентов это ломает тесты, оценки и иногда сам продукт. Если платформа работает как прокси, полезно заранее описать правила маршрутизации: в каких случаях меняется провайдер, что остается стабильным в API и сколько времени дается команде на проверку после анонса.
Если компания работает с персональными данными, внутренние команды ждут и регуляторных обещаний. Где лежат логи и бэкапы, кто видит промпты, как маскируются PII, сколько хранится аудит, можно ли выгрузить след запроса для проверки. Для 152-ФЗ это часть операционного договора, а не мелочь.
Хороший внутренний SLA читается как инструкция для реальной работы. После него команда понимает, чего ждать в обычный день, во время релиза и в момент сбоя.
Что обещают конечному пользователю
Пользователь не покупает выбор провайдера, fallback и переключение между моделями. Он ожидает, что функция в приложении просто работает: отвечает за разумное время, не просит нажать кнопку второй раз и быстро возвращается после сбоя.
Во внешнем SLA LLM-сервиса лучше обещать не состояние платформы, а состояние самой пользовательской функции. Если в приложении есть "сводка документа", "поиск по базе знаний" или "AI-ответ оператору", именно они и должны попасть в формулировку. Для клиента разница между проблемой в модели, прокси, сети или интеграции не имеет смысла.
Хорошая внешняя формулировка обычно держится на нескольких простых вещах:
- доступность функции в приложении;
- доля успешных ответов с первой попытки;
- срок восстановления после заметного сбоя;
- понятный язык без внутренней инженерной терминологии.
Такие обещания легко проверить глазами пользователя. Кнопка сработала или нет. Ответ пришел или человек нажал снова. Сбой длился 8 минут или 2 часа. Это честнее, чем писать про 99,9% доступности внутреннего API, если в интерфейсе ответ все равно не дошел.
Полезно сразу договориться, что считать успешным ответом. Если система вернула пустой текст, сломанный формат или слишком поздний ответ, пользователь не считает это успехом. Поэтому во внешний SLA часто включают не только факт ответа, но и базовое условие пригодности: ответ пришел в допустимое время и без явной ошибки.
Если под капотом у вас шлюз вроде RU LLM, это остается внутри команды. Во внешнем SLA лучше писать: "AI-функция в личном кабинете доступна по опубликованному графику обслуживания". И хуже писать: "Запросы автоматически маршрутизируются к доступным моделям". Вторая фраза описывает устройство системы, а не обещание клиенту.
Хороший внешний SLA читается без перевода с инженерного на человеческий. После чтения клиент должен понять одно: когда функция доступна, как часто она срабатывает с первого раза и как быстро вы чините заметный сбой.
Где проходит граница ответственности
Если ответ пользователю не дошел или пришел плохим, причина почти всегда не одна. Падает не "LLM целиком", а конкретный слой: сама платформа, внешний провайдер, сеть, интеграция продукта или бизнес-правило поверх ответа. Пока вы не разложили это по слоям, любой SLA быстро превращается в спор о том, кто виноват.
В SLA для внутренних клиентов LLM-платформы лучше сразу разделить четыре зоны ответственности. Платформа отвечает за прием запроса, маршрутизацию, доступность API, логи, биллинг и технические механизмы вроде ретраев или таймаутов. Провайдер или конкретная модель отвечает за то, что происходит после передачи запроса: задержку, rate limit, деградацию качества, отказ на своей стороне. Продуктовая команда отвечает за промпт, постобработку, проверку ответа и сценарий, в который попадает пользователь. Сеть и внешняя инфраструктура живут отдельно, их не стоит смешивать с отказом самой платформы.
Короткое правило выглядит так:
- если API не принимает запросы, это зона платформы;
- если провайдер вернул 5xx, timeout или резкий рост задержки, это зона провайдера;
- если модель ответила формально успешно, но промпт дал слабый результат, это зона продукта;
- если проверка отклонила ответ и не включился запасной сценарий, это тоже зона продукта;
- если пользователь потерял сессию из-за сети или фронтенда, это не инцидент LLM-платформы.
Самая частая ошибка - обещать продуктовым командам качество ответа как часть платформенного SLA. Платформа не может честно гарантировать, что любой промпт даст точный итог. Она может гарантировать другое: запрос дойдет, модель выберется по правилам, лог сохранится, а fallback запустится, если внешний вызов сорвется. Все, что связано с содержанием ответа, нужно описывать отдельно: кто пишет промпт, кто держит eval-набор, кто ставит фильтры и кто решает, когда показать пользователю шаблонный ответ вместо генерации.
Если вы работаете через внешних провайдеров, вынесите их влияние в отдельный раздел. Для внутренней команды полезно видеть два числа: доступность вашей платформы и доступность цепочки "платформа + провайдер". Тогда никто не путает свой контур с чужим.
Штрафы, сервисные кредиты или бюджет ошибок для LLM лучше привязывать только к своей зоне. Иначе платформа начнет отвечать за провалы, которые не контролирует, а продуктовая команда решит, что fallback и проверка ответа можно не делать.
Как собрать два SLA
Собирать два SLA лучше от пользовательского сценария, а не от списка сервисов. Иначе документ выходит аккуратным, но бесполезным: команда платформы обещает одно, продукт думает о другом, а спор начинается в первый же сбой.
Если вы готовите SLA для внутренних клиентов LLM-платформы, возьмите 2-4 сценария, где простой сразу бьет по деньгам, поддержке или риску. Для банка это может быть чат в мобильном приложении, суммаризация диалога оператора и проверка обращения на чувствительные данные.
Дальше разложите каждый сценарий на цепочку зависимостей. Опишите путь запроса целиком: клиентское приложение, API-шлюз, маршрутизацию модели, выбранного провайдера или свою модель, кэш, базу знаний и логирование. Добавьте служебные части, про которые часто забывают: авторизацию, маскирование PII, audit trail и хранение логов в РФ, если сценарий затрагивает 152-ФЗ и LLM-платформу в одном контуре. Для каждого звена назначьте метрику. Обычно хватает доступности, доли успешных ответов, p95 задержки и времени переключения на резерв. Сразу задайте порог и окно измерения: 99,9% за месяц, p95 не выше 2 секунд за 15 минут, подтверждение инцидента за 10 минут. И отдельно зафиксируйте часы поддержки и эскалацию: кто дежурит, в каком канале зовут владельца, кто переводит сценарий в деградированный режим.
После этого сравните внутренние и внешние обещания. Внутренний SLA должен быть строже, иначе у продукта не останется запаса на свой код, релизы интерфейса и ошибки интеграции. Если внешний SLA LLM-сервиса для конечного пользователя равен 99,5% в месяц, внутренний SLA платформы на тот же путь обычно ставят выше, например 99,9% на API-шлюз и более жесткий порог по задержке.
Проверка тут очень простая. Если продукт пообещал клиенту ответ за 5 секунд, а платформа допускает p95 в 5 секунд, документ уже сломан. То же самое с поддержкой: внешний канал 24/7 не сочетается с внутренней поддержкой только по будням.
Пример для банка
Банк запускает LLM-помощник в мобильном приложении. Клиент пишет: "Почему отклонили перевод?" Продукт обещает простой опыт: ответ появится быстро, без зависаний, и экран не сломается даже если одна из моделей даст сбой.
Для клиента это и есть внешний SLA LLM-сервиса. Он не думает про маршруты, квоты и провайдеров. Он видит только функцию в приложении: она ответила за 3-5 секунд или не ответила.
У продуктовой команды другой разговор с платформой. Внутренний договор обычно описывает четыре вещи: стабильный endpoint без срочной переписки кода при смене модели, понятные лимиты по RPS и токенам, ясный порядок инцидентов и предупреждение о деградации модели до того, как жалобы дойдут от пользователей. Это не обещания розничному клиенту банка. Это рабочий контракт между двумя командами.
Представим вечерний пик. Одна модель начинает отвечать не за 2 секунды, а за 11. Платформа не спорит с продуктом о причинах. Она отдает сигнал о деградации, сохраняет доступность API и показывает понятный статус. Продукт в ответ включает запасной сценарий: сокращает длину ответа, отключает свободный диалог и оставляет короткий вариант с готовыми подсказками.
Клиент банка может заметить, что помощник стал отвечать короче и суше. Но он не должен видеть внутренний конфликт в духе "у нас тормозит модель, ждите". Для него сбой выглядит как ограничение функции, а не как спор платформы, ML-команды и владельца приложения.
Если банк использует единый OpenAI-совместимый шлюз, такой переход проще: приложение не переписывают под нового провайдера посреди инцидента. Это особенно удобно там, где есть требования по 152-ФЗ, аудит действий и жесткие правила по данным. Внутренний SLA держит работу команд в порядке, а внешний SLA защищает опыт клиента. Смешивать их не стоит.
Где чаще ошибаются
Когда компании описывают SLA для внутренних клиентов LLM-платформы, они часто берут внешний SLA LLM-сервиса и переносят его внутрь почти без правок. На старте это кажется удобным, но быстро ломает ожидания. У конечного пользователя один опыт: ответ пришел или нет. У продуктовой команды другая задача: выбрать модель, уложиться в цену, пройти комплаенс и пережить сбой у провайдера.
Первая ошибка именно в таком копировании. Если снаружи сервис обещает 99,9% доступности API, внутри нельзя автоматически обещать те же цифры для любой модели и любой задачи. Даже единый OpenAI-совместимый endpoint не делает все модели одинаковыми по задержке, длине ответа и стабильности.
Вторая ошибка - одна метрика на все. Для короткого чата полезнее смотреть на задержку ответа. Для генерации отчета важнее, сколько запросов дошло до конца без обрыва. Для массовой обработки документов цена может быть не менее важна, чем аптайм. Один общий SLO для продуктовых команд почти всегда скрывает проблему, а не помогает ею управлять.
Третья ошибка живет на стороне клиента. Платформа может ответить за 12 секунд, но SDK в приложении оборвет запрос на десятой. Или клиент сделает три ретрая и сам раздует нагрузку во время сбоя. Или продукт поставит слишком маленький лимит на контекст и потом обвинит платформу в плохом результате. Если не считать таймауты, ретраи и ограничения клиента, цифры в отчете будут красивыми, но бесполезными.
Четвертая ошибка связана с разбором инцидентов. Команда продукта часто складывает в одну корзину падение провайдера, плохой промпт, переполнение контекста, неверный парсинг ответа и отказ бизнес-правил на своей стороне. В такой схеме платформа чинит чужую логику, а продукт не видит свои слабые места.
Пятая ошибка самая дорогая: обещают слишком высокий аптайм без резерва. Красиво звучит 99,95%, но такие цифры требуют запасных маршрутов, понятного failover, лимитов на трафик и внятного бюджета ошибок. Если у вас одна модель на все и нет плана на деградацию, высокий процент в SLA станет источником споров, а не доверия.
Есть простой тест. Если команда не может быстро ответить, где кончается зона платформы и начинается зона продукта, SLA написан слишком общо.
Короткая проверка перед запуском
Перед запуском SLA не должен жить в голове одной команды. Если правила не записаны, ночной сбой быстро превращается в спор: это проблема платформы, модели, провайдера или продукта.
Хорошая проверка занимает 15-20 минут и почти всегда ловит самые дорогие промахи до релиза.
- У внутренних команд должен быть свой SLA, а не копия обещаний для пользователей.
- У каждой метрики должен быть владелец и понятный источник данных: gateway-логи, APM, трассировка SDK, мониторинг провайдера или биллинг.
- Порог задержки нужно считать с учетом размера промпта, числа выходных токенов и режима ответа, а не одним числом на все случаи.
- Условия включения запасного маршрута должны быть зафиксированы заранее, а не решаться в чате по настроению.
- Ночная эскалация должна доходить до живого человека, который может принять решение.
Отдельно проверьте требования 152-ФЗ, если в запросах есть персональные данные. Именно здесь чаще всего забывают, кто отвечает за маскирование PII, где хранятся логи и кто смотрит audit trail при разборе сбоя.
Если хотя бы на один пункт команда отвечает расплывчато, запуск лучше притормозить на день. Это дешевле, чем разбирать ночной инцидент сразу с продуктом, безопасностью и бизнесом.
Что делать дальше
Не пытайтесь сразу описать весь SLA для внутренних клиентов LLM-платформы. Возьмите один сценарий, который команда продукта запускает каждый день и который легко проверить руками. Например, генерацию ответа оператору, проверку анкеты или краткое резюме обращения. Для него задайте 2-3 метрики: время ответа, долю успешных запросов и поведение системы при сбое провайдера.
Потом дайте этому сценарию пожить хотя бы месяц. За это время быстро видно, где обещание полезно, а где оно только мешает. Часто команды вписывают слишком много: отдельные лимиты по каждой модели, редкие режимы деградации, ручные исключения. Если метрику никто не смотрит или ее нельзя честно измерить, уберите ее из договора.
Хорошая ревизия через месяц обычно отвечает на четыре вопроса: что реально ломалось и как часто это замечали продуктовые команды, какие обещания можно проверить по логам без ручного разбора, где проходит граница между проблемой платформы и проблемой внешнего провайдера, и какие условия нужны только для одного сценария, а не для всех команд.
Если вы строите такой слой в РФ, полезно сравнить свою сборку с готовыми вариантами. Например, у RU LLM есть OpenAI-совместимый endpoint, хранение логов и бэкапов в РФ, встроенные audit trail и маскирование PII. Для команд, которым нужно закрепить в SLA data residency, биллинг и поддержку внутри РФ, это может упростить сам договор и сократить число спорных зон.
Когда первый сценарий устоялся, зафиксируйте его как шаблон для остальных продуктовых команд. Не нужен регламент на двадцать страниц. Обычно хватает короткого документа, где есть метрики, исключения, порядок эскалации и формат ежемесячного пересмотра. Тогда внутренние обещания не расползаются от команды к команде, а внешний SLA LLM-сервиса остается понятным и для бизнеса, и для пользователей.