Реранжирование в RAG: когда оно окупается на практике
Реранжирование в RAG помогает не всегда: разберем, для каких коллекций и запросов reranker улучшает ответ, а где только добавляет задержку.
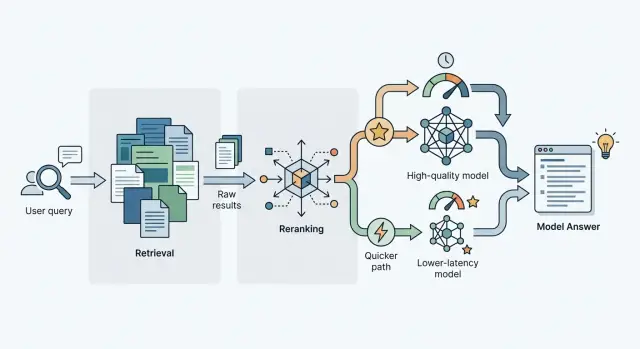
Где обычный поиск промахивается
Обычный top-k поиск хорошо находит "похожие" фрагменты, но это не всегда значит "самые полезные". Эмбеддинги часто цепляются за общую тему, а не за точный смысл вопроса. В итоге в контекст попадают куски, которые звучат близко к запросу, но не помогают дать точный ответ.
Особенно это заметно на длинных и составных вопросах. Если человек спрашивает про исключение, срок или редкое условие, поиск легко поднимает общий раздел документа, а не тот абзац, где спрятана нужная оговорка. Модель видит что-то уместное уже в первых кусках и строит ответ на этой основе, хотя ниже в выдаче мог лежать фрагмент лучше.
Есть и другая частая проблема - дубли. Когда база хранит один и тот же текст в нескольких версиях, шаблонах или соседних чанках, top-k забивается почти одинаковыми отрывками. Формально поиск сработал: все фрагменты релевантны. По факту контекст стал беднее, потому что вместо пяти разных сигналов модель получила один и тот же сигнал пять раз.
Из-за этого падает не только полнота, но и точность. Модель часто опирается на первый достаточно уместный кусок, особенно если он написан уверенно и содержит знакомые термины. Она не перечитывает базу как человек. Что попало в начало контекста, то чаще и влияет на ответ.
Проблема сильнее всего проявляется в коллекциях с однотипными текстами: регламентами, тарифными страницами, версиями договоров, статьями справки с похожей структурой. Чем больше документы похожи друг на друга по языку, тем труднее обычному поиску понять, какой фрагмент нужен именно для этого запроса. Он находит тему, но путается в деталях.
В таких местах реранжирование обычно и дает эффект. Оно не ищет заново, а пересматривает уже найденные куски и поднимает выше те, которые лучше отвечают на конкретный вопрос, а не просто похожи по словам или общей теме.
Для каких коллекций reranker дает прирост
Reranker полезен там, где поиск уже находит что-то близкое, но путает порядок результатов. Это частый случай: в топ-20 лежат почти правильные фрагменты, а на первых местах оказываются не те. Модель ответа читает шум, и итог получается расплывчатым или уходит в сторону.
Сильнее всего это видно на больших коллекциях с очень похожими документами. Если база состоит из шаблонов, типовых инструкций, договоров или карточек FAQ, обычный retriever часто цепляется за общие слова и пропускает небольшое, но решающее различие. Reranker лучше отделяет фрагмент, где совпал не только термин, но и смысл запроса.
Вторая зона роста - длинные документы, порезанные на десятки близких чанков. Один регламент на 80 страниц легко дает много соседних кусков с почти одинаковой лексикой. Поиск поднимает пачку похожих чанков из одного документа, хотя пользователю нужен один конкретный абзац. Реранжирование чаще выбирает именно тот кусок, где есть прямой ответ.
Хорошо работает оно и там, где один термин живет в нескольких смыслах. Слово "лимит" может относиться к кредитке, антифроду, бюджету кампании или квоте в API. Векторный поиск нередко смешивает такие случаи, особенно если формулировки в базе короткие. Reranker глубже смотрит на пару "запрос-фрагмент" и чаще поднимает нужный смысл выше.
Обычно прирост заметен в архивах правил, регламентов и внутренних политик с несколькими версиями одного документа, в базах договоров и приложений со схожей структурой, в больших FAQ, где один и тот же вопрос задают разными словами, и в базах знаний с шумными или неполными метаданными.
Отдельный риск - версии документов. Поиск может вернуть старую редакцию просто потому, что текст там плотнее совпал с запросом. Если в базе лежат тарифы, инструкции или нормы в нескольких редакциях, ошибка становится дорогой: ответ будет звучать уверенно, но опираться на неактуальный текст. Реранжирование само по себе не решает проблему версионности, но часто помогает поднять выше более точный фрагмент, если retriever уже достал обе версии.
То же происходит в базах, где метаданные заполняли вручную. Теги пропущены, даты указаны не везде, названия отделов менялись. Фильтры в таких данных помогают слабо. Здесь реранжирование часто дает заметный прирост, потому что меньше зависит от качества служебных полей.
Если команда строит RAG по внутренним регламентам, FAQ и документам по 152-ФЗ, тестировать reranker почти всегда имеет смысл. В таких базах много похожих формулировок, старых версий и длинных текстов. Это как раз тот случай, где лишние 100-300 мс нередко окупаются более точным первым ответом.
Какие запросы он вытягивает лучше всего
Лучше всего реранжирование работает там, где обычный поиск уже нашел 10-20 вроде бы подходящих фрагментов, но не может выбрать один самый точный. Обычно это не простые запросы вроде "тариф на SMS", а вопросы, где смысл собирается из нескольких условий сразу.
Хороший пример - длинный вопрос с ограничениями: "Какой тариф действует для ИП в Москве, если оплата помесячная и нет автопродления?" Векторный или гибридный поиск часто вытаскивает куски про ИП, Москву или помесячную оплату по отдельности. Реранжирование чаще поднимает фрагмент, где условия встречаются вместе, а не разбросаны по разным документам.
Особенно заметен прирост на запросах с исключениями. Слова "кроме", "если не", "за исключением", "только при" ломают простую выдачу чаще, чем кажется. Поиск видит знакомые термины и тянет общий раздел, а reranker лучше различает, где правило общее, а где есть оговорка, которая меняет ответ.
Еще один сильный случай - вопросы, где совпадение слов не так важно, как совпадение смысла. Пользователь спрашивает: "Можно ли отключить услугу без штрафа?" А в базе написано: "досрочное прекращение допускается без удержания комиссии". Формулировки разные, но смысл один. Если в коллекции много похожих абзацев, реранжирование часто выбирает нужный фрагмент точнее, чем базовый retriever.
Хорошо помогает оно и на сравнениях. Когда человек спрашивает, чем отличается версия правил за 2023 год от версии за 2024-й, или какой тариф выгоднее при двух сценариях использования, поиск обычно приносит много соседних фрагментов. Дальше нужно понять, какой из них отвечает именно на сравнение, а не просто упоминает оба объекта.
Чаще всего выигрывают запросы с несколькими условиями в одной фразе, вопросы с оговорками и исключениями, сравнение редакций, тарифов, лимитов и правил, поиск одного точного пункта среди десятков почти одинаковых фрагментов, а также случаи, когда пользователь пишет своими словами, а документы написаны канцеляритом.
На практике это хорошо видно в базах регламентов, тарифов и договоров. Там много похожих заголовков, повторяющихся шаблонов и редакций. Если пользователь ищет не тему целиком, а один нужный абзац, реранжирование часто заметно улучшает ответ даже при той же базе и тех же чанках.
Где реранжирование только тормозит ответ
Реранжирование не дает пользы, если базовый поиск и так ставит нужный фрагмент в первые результаты. В такой схеме вы просто добавляете еще один вызов модели и получаете лишние 100-300 мс, а под нагрузкой и больше.
Первый частый случай - маленькая и чистая коллекция. Если в базе немного документов, у них понятные заголовки, мало дублей и аккуратная разбивка на фрагменты, обычный поиск уже работает достаточно точно. Reranker редко меняет порядок так, чтобы ответ стал заметно лучше для пользователя.
Почти всегда его стоит выключать для запросов по точному идентификатору. Номер формы, артикул, код ошибки, ID договора, точное название тарифа - все это лучше обрабатывает поиск по словам и точное совпадение. Если человек ввел "E0421" или "КНД 1151006", ему нужен один конкретный документ, а не сложная семантическая сортировка.
Та же логика работает в сценариях со строгими фильтрами. Когда вы уже отрезали все лишнее по продукту, версии, дате, филиалу или типу клиента, набор кандидатов и так становится узким. После таких фильтров reranker часто пересортировывает почти одинаковые фрагменты и не меняет итоговый ответ.
Короткие фактологические вопросы тоже не всегда требуют второй стадии. Если в базе есть один явный источник с точным числом, сроком или лимитом, ранкер почти ничего не улучшит. Вопрос вроде "сколько дней хранится заявление" обычно решает хороший retrieval, если нужный фрагмент содержит прямой ответ без двусмысленности.
Сильнее всего лишняя стадия ощущается в быстрых сценариях, где задержка заметна сразу: поиске в рабочем интерфейсе оператора, подсказках в чате, автодополнении, внутреннем copilot для саппорта. Даже лишние 150 мс портят ощущение скорости. Пользователь не скажет, что у вас слабый reranker. Он просто почувствует, что система стала медленнее.
Обычно реранжирование можно не включать, если совпадают сразу несколько условий: коллекция небольшая и без дублей, запросы часто содержат точные коды и номера, фильтры сильно сужают выборку до поиска, ответ почти всегда лежит в одном очевидном фрагменте, а сценарий чувствителен к задержке.
Практичное правило простое: если первый этап поиска уже кладет нужный фрагмент в первые 3-5 результатов в большинстве сессий, reranker для этого класса запросов лучше отключить. Быстрее будет не только ответ, но и вся цепочка RAG.
Как посчитать, окупается ли задержка
Если reranker добавляет 150 мс, этого мало для решения. Важно смотреть, меняется ли итоговый ответ: нашла ли система нужный документ, сослалась ли на верный пункт, перестала ли путать похожие фрагменты. В реранжировании есть смысл только тогда, когда растет качество ответа, а не просто меняется порядок кусков в выдаче.
Проверять это лучше на реальных вопросах. Возьмите выборку из живых запросов, сохраните два прогона для каждого случая - без reranker и с ним - и сравните результат по одной и той же шкале. Обычно хватает трех простых меток: ответ верный, ответ частично верный, ответ неверный.
Полезно считать сразу несколько вещей:
- среднюю задержку отдельно для поиска, реранжирования и генерации
- p95 отдельно, потому что длинный хвост раздражает пользователей сильнее всего
- цену не на один запрос, а на 1000 запросов
- эффект при rerank только top-10 или top-20 кандидатов, а не всей выборки
Так вы быстро увидите, где именно расходуются время и деньги. Иногда поиск работает быстро, генерация держится в норме, а reranker съедает почти весь запас по задержке. Бывает и наоборот: он добавляет всего 80-120 мс, но резко снижает число промахов на сложных вопросах.
Грубая модель расчета выглядит так:
выгода = прирост доли верных ответов - штраф за задержку - штраф за цену
Если хотите считать строже, переведите ошибки и ожидание в деньги. Логика простая: если неверный ответ в базе регламентов ведет к лишнему обращению сотрудника и тратит 10 минут рабочего времени, такой промах стоит дороже, чем дополнительные 200 мс. А вот в быстром внутреннем поиске по коротким точным запросам reranker часто не окупается: люди и без него находят нужный документ.
Еще один частый выигрыш дает выборочное включение. Не гоняйте reranker на каждом запросе. Включайте его там, где запрос длинный, содержит несколько условий, использует синонимы или ведет к набору очень похожих документов. На простых запросах обычный поиск по базе знаний часто дает тот же результат быстрее и дешевле.
Если прирост виден только в метриках поиска, а ответы почти не меняются, команда получила более медленный пайплайн без заметной пользы.
Как проверить это на своих данных
Проверять реранжирование лучше не на игрушечных примерах, а на живых запросах. Возьмите 50-100 запросов из поддержки, внутреннего поиска или логов чата. Этого уже хватает, чтобы увидеть, где reranker помогает, а где просто добавляет 200-500 мс без пользы.
Не чистите выборку слишком усердно. Если в логах есть короткие, кривые или двусмысленные формулировки, оставьте их. Именно на таких запросах система обычно и спотыкается в продакшене.
Что размечать
Для каждого запроса зафиксируйте две вещи: какой источник можно считать хорошим и какой ответ вы считаете приемлемым. Это не одно и то же. Иногда поиск нашел правильный документ, но генерация все равно ответила мимо. Тогда проблема не в ранжировании.
Достаточно простой разметки:
- нужный фрагмент есть в топ-3 или нет
- нужный фрагмент есть в топ-10 или нет
- ответ точный, приемлемый или плохой
- есть ли опасный промах: выдумка, устаревшее правило, не тот тариф
Потом прогоните один и тот же набор двумя способами: baseline без reranker и вариант с ним. Параметры должны быть одинаковыми везде, кроме самого реранжирования. Если вы одновременно меняете retriever, размер чанка и промпт, вы не поймете, что именно дало эффект.
Средние цифры полезны, но они часто скрывают неприятные случаи. Смотрите не только на общий прирост, но и на провалы. Бывает так: на 70% запросов все без изменений, на 20% стало лучше, а на 10% система начала поднимать очень похожие, но неверные документы. Для базы с регламентами это уже серьезная проблема.
Еще один важный шаг - разрезать результаты по типам запросов и по коллекциям. Отдельно смотрите короткие запросы, запросы с редкими терминами, вопросы с датами, номерами приказов, названиями продуктов. Отдельно - FAQ, регламенты, тарифы, переписку поддержки, wiki. Один и тот же reranker может заметно помочь на длинных нормативных документах и почти ничего не дать на коротких карточках товаров.
В конце оставьте простое правило включения. Например, включать reranker только для длинных коллекций, только для запросов длиннее пяти слов или только когда начальный поиск вернул много близких по смыслу документов. Такое правило обычно полезнее, чем попытка гонять реранжирование на каждом запросе.
Пример: база регламентов и тарифов
У поддержки часто одна и та же проблема: ответ вроде есть, но поиск приносит слишком много похожих фрагментов. В базе лежат тарифы, внутренние регламенты и старые рассылки по продуктам. Названия почти совпадают, формулировки тоже, а отличаются дата, редакция и иногда сам продукт.
Обычный поиск в такой базе часто поднимает сразу несколько версий одного документа. Агент видит рядом тариф от марта, обновление от июня и письмо с временной акцией. Все три текста похожи по словам, поэтому retriever считает их почти равными. Дальше в ответ легко попадает не тот фрагмент.
На таких данных реранжирование обычно окупается быстро. Оно не ищет документы заново, а берет верхние кандидаты и переставляет их по смыслу запроса. Если человек спрашивает про комиссию по конкретному продукту на конкретную дату, reranker чаще ставит выше нужный кусок, а не просто самый похожий по набору слов.
Это хорошо видно на двух типах запросов:
- "Какая комиссия за обслуживание корпоративной карты Премиум с 1 июля?"
- "Какая форма 0409123 нужна для этого случая?"
В первом случае прирост заметен сразу. Поиск может достать несколько тарифов по картам, старую рассылку о смене ставок и общий регламент по комиссиям. Реранжирование обычно поднимает фрагмент, где совпали сразу три вещи: продукт, тип комиссии и дата действия. Для оператора это разница между точным ответом с первой попытки и ручной проверкой трех документов.
Во втором случае пользы почти нет. Если в запросе есть точный номер формы, артикула или шаблона, обычный поиск и так попадает куда нужно. Тут reranker только добавляет задержку, потому что сильного выбора между похожими фрагментами нет.
На практике картина простая. Поддержка задает вопрос про комиссию, retriever возвращает 10-20 кандидатов, среди них много дублей старых редакций. Reranker ставит на первое место фрагмент из актуального тарифа по нужному продукту, а старые версии опускает ниже. Качество ответа растет не из-за "умного" текста, а из-за более точного первого фрагмента в контексте.
Если же база состоит из документов с редкими и точными идентификаторами, вроде номеров форм, кодов услуг или внутренних шаблонов, reranker для поиска часто лишний. В таких запросах лучше оставить быстрый retrieval и не тратить миллисекунды там, где поиск и так уверен.
Ошибки, которые съедают пользу
Реранжирование часто пытаются использовать как быстрый ремонт всей цепочки поиска. Это плохо работает. Если в базе лежат дубли, чанки нарезаны без смысла, а фильтры почти не используются, reranker просто аккуратнее сортирует шум. Качество ответа растет слабо, а задержка растет почти всегда.
Самая частая ошибка проста: команда отправляет на реранжирование 100-200 чанков без ясной причины. Обычно достаточно 20-40 кандидатов после первичного поиска. Все, что идет дальше, часто состоит из старых версий документов, почти одинаковых фрагментов и кусков без заголовка или даты. Модель тратит время на мусор, а генератор потом все равно получает слабый контекст.
Не менее вредная привычка - тестировать систему на "красивых" запросах. В демо люди пишут точное название регламента, номер тарифа или редкий термин из документа. На таких запросах и обычный поиск выглядит умным. Проблемы видны на живых формулировках: "какой тариф сейчас действует для ИП", "где написано про срок хранения логов", "нужна ли новая версия согласия". Если в тестах нет таких запросов, оценка пользы почти ничего не значит.
Еще одна ловушка - смотреть только на retrieval-метрики. Recall@50 может выглядеть отлично: нужный фрагмент формально найден. Но пользователь не читает топ-50, и генератору тоже нет пользы от далекого попадания. Проверять нужно итоговый ответ: дал ли он верную норму, взял ли актуальную версию документа, не смешал ли два похожих правила.
Чаще всего пользу съедают дубли и старые редакции в коллекции, нарезка текста по фиксированному размеру вместо смысловых границ, отсутствие фильтров по типу документа, версии, дате или продукту, слишком тяжелая модель там, где хватило бы обычного фильтра, и оценка качества по поиску, а не по финальному ответу.
Это особенно заметно в базах с регламентами, тарифами и политиками по 152-ФЗ. Если запрос уже можно сузить по метаданным, сначала сделайте это. Когда в выдаче остаются только релевантные документы одной версии и одной категории, тяжелый reranker часто уже не нужен. Он окупается там, где после фильтрации все еще есть реальная путаница между близкими по смыслу фрагментами.
Быстрый чек-лист перед запуском
Реранжирование редко стоит включать для всех запросов сразу. Чаще оно помогает там, где первый поиск уже находит что-то близкое, но не умеет выбрать самый полезный фрагмент из похожих кандидатов.
Перед запуском проверьте пять вещей:
- коллекция уже большая и шумная, в ней много похожих документов или почти одинаковых фрагментов
- пользователи задают длинные запросы с несколькими условиями
- в top-k часто попадают дубли, соседние куски одного документа или спорные фрагменты
- дополнительная задержка помещается в ваш SLA
- команда может включать reranker только для сложных случаев, а не для всех запросов подряд
Если первые три пункта дают "да", а последние два не ломают скорость и архитектуру, шанс на пользу высокий. Если "да" только у одного пункта, реранжирование может оказаться красивой, но лишней надстройкой.
Есть простой ориентир. Если без reranker пользователь часто получает "почти верный" ответ, реранжирование нужно проверить. Если без него ответ либо сразу правильный, либо документов по теме вообще нет, пользы мало.
Лучший стартовый режим - включать реранжирование только после первичного top-k и только для запросов с явной сложностью: длинный текст, несколько фильтров, много сущностей, спорные кандидаты. Так вы не тратите задержку там, где она ничего не меняет.
Что делать дальше
Если reranker пока дает спорный результат, не меняйте модель первой. Чаще проблема в базе знаний: плохие чанки, пустые метаданные, дубли и слишком широкий top-k. Пока это не исправлено, реранжирование маскирует ошибки поиска, но не лечит их.
Начните с базы. Проверьте, что каждый чанк содержит одну мысль, а не три соседних раздела сразу. У документов должны быть нормальные заголовки, тип документа, дата, версия и другие поля, по которым можно отфильтровать мусор. Потом отдельно подберите top-k: если вы и так отдаете в reranker 50 слабых кандидатов, он потратит время на сортировку шума.
Короткий пилот лучше длинной дискуссии. Возьмите набор реальных вопросов, где обычный поиск уже ошибался, и задайте жесткий порог по задержке. Например, если reranker добавляет больше 150-250 мс, он должен давать заметный прирост по качеству именно на ваших запросах, а не в абстрактной средней картине.
Рабочее правило обычно выглядит так:
- включать reranker только для длинных, неоднозначных или многословных запросов
- не включать его для точных запросов по артикулу, номеру приказа или точному названию
- ограничивать число кандидатов, которые уходят на реранжирование
- оставлять обычный поиск быстрым путем по умолчанию
Такой режим почти всегда лучше, чем запускать reranker на каждый запрос. Он сохраняет скорость там, где поиск и так справляется, и тратит задержку только там, где она действительно окупается.
Если LLM-часть RAG должна работать в российском контуре, проверьте это до пилота, а не после. Для многих команд важны data residency, хранение логов в РФ и понятный аудит запросов. В таком случае можно заранее сверить требования с возможностями RU LLM на rullm.com: сервис дает единый OpenAI-совместимый эндпоинт, хранит логи и бэкапы в РФ и поддерживает маскирование PII и аудит-трейлы на уровне запроса. Это удобно, если нужно сохранить контур внутри РФ и не переписывать существующие SDK, код и промпты.
После пилота зафиксируйте правила в явном виде. Какие метрики вы смотрите: hit rate, nDCG, долю правильных ответов, среднюю и p95 задержку, цену запроса. Какой у вас бюджет на reranker. Что делает система, если reranker недоступен: снижает top-k, идет в обычный retriever или отвечает по fallback-схеме.
Если не записать это сразу, через месяц команда снова начнет спорить по ощущениям. А здесь нужен не спор, а понятный режим работы, который можно повторить на новых коллекциях и новых моделях.
Часто задаваемые вопросы
Когда reranker действительно стоит проверять?
Тестируйте его там, где поиск уже находит близкие фрагменты, но часто ставит наверх не тот. Чаще всего это базы регламентов, тарифов, договоров, FAQ и длинных документов с похожими чанками.
Если у вас маленькая чистая коллекция без дублей, прирост обычно слабый, а задержка вырастет сразу.
Какие запросы reranker улучшает сильнее всего?
Лучше всего он вытягивает длинные вопросы с несколькими условиями, исключениями и сравнениями. Еще он помогает, когда человек пишет своими словами, а в документах тот же смысл сформулирован по-другому.
Если запрос звучит как «что действует для ИП в Москве без автопродления», вторая стадия часто поднимает более точный абзац, чем обычный top-k.
Когда reranker только замедляет ответ?
Отключайте его для точных кодов, номеров форм, артикулов, ID договоров и других запросов с явным совпадением. В таких случаях поиск по словам и так быстро находит нужный документ.
Еще не добавляйте его в сценарии, где каждые 100–200 мс заметны пользователю, например в подсказках оператору или автодополнении.
Сколько фрагментов отправлять на реранжирование?
Чаще всего хватает 20–40 кандидатов после первого поиска. Если отправить сильно больше, модель начнет сортировать шум: старые версии, дубли и соседние куски без пользы.
Начните с top-10 или top-20 и сравните качество. Так вы быстрее поймете, где проходит разумная граница по времени и цене.
Как понять, что задержка окупается?
Смотрите не только на порядок выдачи, а на финальный ответ. Если система стала чаще выбирать верный пункт, меньше путать редакции и реже давать опасные промахи, лишние миллисекунды могут себя оправдать.
Проверьте среднюю задержку, p95 и цену на серии запросов, а не на одном примере. Потом сравните долю верных ответов без reranker и с ним.
Решает ли reranker проблему старых версий документов?
Нет, сам по себе он версионность не чинит. Если retriever не достал актуальную редакцию или метаданные в базе пустые, reranker не угадает правильную дату из воздуха.
Он помогает в другом месте: когда в кандидаты уже попали и старая, и новая версии, он чаще поднимает выше более точный фрагмент по смыслу запроса.
Что нужно исправить в базе до включения reranker?
Сначала приведите в порядок базу. Уберите дубли, проверьте разбиение на чанки, добавьте дату, тип документа, версию и другие поля, по которым можно сузить выборку.
Если этого не сделать, reranker будет просто аккуратнее сортировать мусор. Качество чуть подрастет, но запас пользы вы быстро упретесь в плохие данные.
Как быстро проверить пользу на своих данных?
Возьмите 50–100 живых запросов из логов и прогоните их в двух режимах: без reranker и с ним. Для каждого случая отметьте, попал ли нужный фрагмент в верх выдачи и получился ли приемлемый ответ.
Не чистите выборку до блеска. Кривые и короткие формулировки как раз показывают, помогает ли вторая стадия в реальной работе.
Как лучше включать reranker в проде?
Самый практичный путь — включать его не для всех запросов, а только для сложных. Подойдут длинные вопросы, несколько условий в одной фразе, спорные кандидаты в top-k и коллекции с большим числом похожих документов.
Для простых запросов оставьте быстрый retrieval по умолчанию. Так вы не тратите время там, где порядок фрагментов почти ничего не меняет.
Что проверить заранее, если RAG должен работать в российском контуре?
До пилота проверьте, где физически живут данные, логи и бэкапы. Если запросы и тексты нельзя выносить из РФ, вам нужен контур с хранением в России, маскированием PII и понятным аудитом запросов.
Это стоит решить заранее, а не после теста. Иначе вы получите рабочую схему на бумаге, которую потом нельзя пустить в прод.