Очередь на ручную проверку LLM: пороги без завала команды
Очередь на ручную проверку LLM легко перегрузить, если ставить пороги наугад. Покажем, как считать нагрузку, приоритеты и правила эскалации.
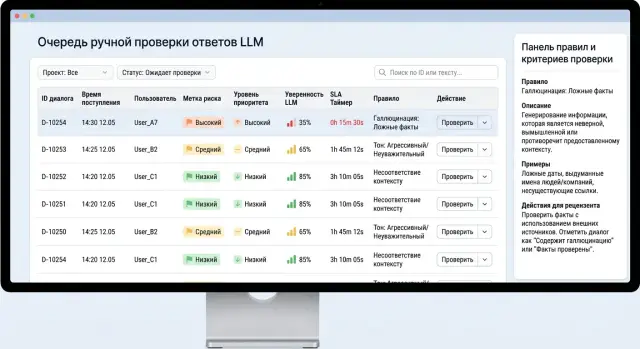
Почему очередь быстро растет
Очередь на ручную проверку растет не потому, что модель обязательно плохая. Обычно причина проще: входящий поток выше, чем команда успевает разобрать. Если за час в очередь попадает больше кейсов, чем люди закрывают за тот же час, хвост начнет расти в тот же день.
Один слишком мягкий порог раздувает очередь очень быстро. Допустим, LLM обрабатывает 20 000 ответов в сутки и отправляет на проверку все, что кажется хоть немного сомнительным. При 2% флагов команда получит 400 кейсов за день. Если правило срабатывает уже в 6% случаев, это 1 200 кейсов. Для модели это осторожность. Для смены - перегруз.
Редкий риск и массовый шум - разные вещи. По-настоящему опасных ответов может быть мало, например 0,2% потока. А расплывчатые, неловкие или нестандартные ответы встречаются намного чаще. Если система помечает их одинаково, очередь забивает не риск, а шум. Команда тратит время на безопасные, но странные ответы и позже добирается до того, что правда опасно.
Даже высокая точность не решает проблему сама по себе. Если автоответы верны в 97% случаев, это звучит отлично. Но на потоке 50 000 ответов в день оставшиеся 3% дадут 1 500 спорных случаев. Небольшая смена такой объем вручную не разберет.
Смотрите всего на две цифры:
- сколько ответов приходит в очередь за час или за день;
- сколько кейсов команда реально закрывает за тот же период без спешки и лишних ошибок.
Если в поддержку приходит 900 флагов в день, а три ревьюера успевают проверить 600, остаток 300 уходит на завтра. Через пять рабочих дней хвост вырастет до 1 500 кейсов. Если среди них есть высокий риск, он будет ждать рядом с мелким шумом.
На большом трафике через единый шлюз это видно особенно быстро. Например, если команда подключила поток через RU LLM и объем запросов резко вырос, ручная проверка сама за ним не подтянется. Пока входящий поток выше емкости смены, очередь будет ползти вверх, даже если модель в целом работает нормально.
Что считать сомнительным ответом
"Сомнительный" ответ - это не любой слабый ответ. В очередь стоит отправлять только то, что может навредить пользователю, нарушить правило или привести к дорогой ошибке для бизнеса. Если модель просто отвечает сухо или неуверенно, человек часто не нужен.
Проще всего делить такие ответы на две группы. Первая - опасные. Это утечка персональных данных, токсичный или запрещенный совет, уверенная выдумка там, где ошибка дорого обходится. Вторая - неуверенные. Тут модель уходит от темы, не понимает вопрос, просит лишнее уточнение или отвечает слишком общо. Это неприятно, но не всегда требует ручной проверки.
Типовые сигналы выглядят так:
- ответ не решает запрос и уходит в сторону;
- факт в ответе спорит с базой знаний, политикой или данными клиента;
- модель без причины просит, повторяет или раскрывает PII;
- в тексте есть токсичность, дискриминация или опасная инструкция;
- модель отказывает там, где по сценарию должна помочь.
Не стоит держать отдельный маршрут под каждую метку. Для очереди обычно хватает трех риск-классов. "Критический риск" - это PII, токсичность, опасные советы и явное нарушение политики. "Бизнес-риск" - фактические ошибки, конфликт с найденным источником, неверные суммы, сроки и статусы. "Сбой качества" - уход от темы, лишний отказ, низкая уверенность и плохой формат. Такая схема проще и для операторов, и для отчетов.
Если вы уже используете RU LLM, метки PII, AI-Law и аудит-трейлы по запросам можно сразу свести к этим трем классам, а не множить десятки флагов в интерфейсе.
Человека не нужно звать на каждый сбой качества. Часто хватает автоправила: повторить запрос с более строгим промптом, подложить найденный документ, скрыть PII, заменить ответ безопасным шаблоном или попросить пользователя уточнить детали. В очередь лучше отправлять то, где одна автопоправка риск не сняла.
Правило простое: если ошибку можно безопасно исправить машиной и пользователь почти ничего не теряет, ручная проверка не нужна. Если ответ может нарушить закон, политику или важный бизнес-процесс, его должен увидеть человек.
Как задать пороги по шагам
Порог нельзя брать "на глаз". Слишком низкий порог раздувает очередь за день. Слишком высокий пропускает ответы, которые лучше остановить до показа пользователю.
Начните со свежей выборки, а не со старого архива. Обычно хватает ответов за последние 1-2 недели. За это время уже видны текущие промпты, новые сценарии и реальное поведение модели. Архив полугодовой давности часто мешает: продукт уже изменился, вопросы пользователей тоже.
Дальше нужна ручная разметка. Не пытайтесь сразу придумать десять классов ошибок. Для первого прохода обычно достаточно 4-5 понятных типов: фактическая ошибка, опасный совет, пропуск важной детали, ответ не по вопросу, риск для персональных данных. После этого посмотрите, какая доля приходится на каждый тип и где модель ошибается чаще.
Рабочий порядок такой:
- Возьмите случайную выборку недавних ответов.
- Разметьте ее вручную по типам ошибок.
- Для каждой категории задайте допустимую долю эскалации.
- Прогоните правила на малой части трафика.
- Сравните, сколько шума попало в очередь и сколько плохих ответов система пропустила.
Один общий порог почти всегда дает плохой результат. Лучше задавать отдельные пороги по категориям. Для FAQ можно терпеть более высокий риск и отправлять на проверку 2-3% ответов. Для платежей, возвратов, юридических формулировок и тем с персональными данными порог обычно нужен строже, даже если ручная проверка вырастет до 10-15%.
Проверяйте правила на небольшой доле трафика, а не сразу на всем потоке. Подойдет 5-10% запросов или один канал поддержки. Смотрите на две вещи: сколько лишних ответов попало в очередь и сколько сомнительных ушло мимо нее. Если шум высокий, команда быстро устанет. Если пропусков много, порог слишком мягкий.
Меняйте по одному правилу за раз. Сначала поправьте порог уверенности. Потом отдельно добавьте правило для тем с PII. Потом проверьте, влияет ли длина ответа или ссылка на документ. Иначе вы просто не поймете, что именно сработало.
После каждого изменения фиксируйте результат: дату, правило, размер очереди, долю ошибок внутри очереди и долю пропусков. Через две недели такая таблица даст больше пользы, чем любая интуитивная настройка.
Как расставить приоритеты внутри очереди
Если все сомнительные ответы падают в один поток, команда начинает разбирать то, что громче, а не то, что опаснее. Очередь лучше сортировать по двум признакам: какой вред может принести ошибка и как быстро этот вред проявится.
Наверх поднимайте ответы, где ошибка бьет по деньгам, данным и жалобам. Это списания, возвраты, доступ к аккаунту, условия договора, обещания скидок, советы по действиям в личном кабинете и любые ответы, где модель могла раскрыть чужие персональные данные. Для банка, телекома или ритейла это прямой операционный риск.
Обычно хватает простой шкалы:
- P1 - риск потери денег, утечки данных или регуляторной жалобы;
- P2 - пользователь может сделать неверное действие или пропустить срок;
- P3 - ответ двусмысленный или спорный, но вред маловероятен;
- P4 - огрехи тона и стиля.
Нижние уровни не стоит смешивать с верхними. Если модель резко сформулировала ответ, но не ввела человека в заблуждение и не затронула его данные, такой кейс может подождать. Иначе команда тратит утро на запятые, пока наверху лежит ответ про возврат денег.
Срок реакции лучше привязать к уровню риска. Например, P1 команда проверяет за 10 минут, P2 - за час, P3 - до конца смены. Старые задачи тоже стоит отдельно контролировать: если кейс лежит 24 часа, система поднимает его на уровень выше или отправляет в отдельную полосу. Иначе в очереди быстро заводятся "вечные" задачи.
VIP-кейсы не стоит подмешивать в общий поток без явного правила. Статус клиента сам по себе не должен обгонять риск утечки данных у обычного пользователя. Лучше задать точное условие: повышенный приоритет VIP получает только там, где цена ошибки правда выше, например в платежах или закрытии договора.
Сравнение здесь простое. Если модель дала VIP-клиенту неточный ответ о комиссии, это может быть P2. Если она показала обычному пользователю чужой остаток по счету, это P1 и идет первым.
Как держать нагрузку в пределах смены
Очередь ломается не из-за плохих людей, а из-за плохой математики. Если команда физически закрывает 400 проверок за смену, а система каждый день отправляет 550, хвост появится даже при очень аккуратной работе.
Сначала посчитайте реальную скорость, а не красивую цифру в планах. Возьмите обычную смену, выберите 2-3 проверяющих и посмотрите, сколько кейсов каждый закрывает за час без спешки. Потом вычтите время на спорные случаи, внутренние вопросы и повторные просмотры.
Простая формула выглядит так:
емкость смены = люди × проверок в час × полезные часы
полезные часы = длина смены - время на спорные кейсы и разборы
Допустим, один человек закрывает 18 проверок в час. Смена длится 8 часов, но 1,5 часа уходят на сложные кейсы и сверку. Остается 6,5 полезных часа, то есть 117 проверок на человека. Если в смене 4 человека, потолок команды - около 468 кейсов. Все, что выше, почти гарантированно уйдет на следующий день.
Когда поток выше емкости, не пытайтесь проверять все подряд. Лучше сразу ограничить вход в очередь. Иначе силы уходят на второстепенные сигналы, а действительно рискованные ответы ждут слишком долго.
На практике помогает простое правило:
- критичные метки идут всегда;
- средний риск идет, пока очередь не дошла до лимита;
- слабые сигналы попадают только в выборку;
- повторяющиеся типовые случаи снимаются с ручной проверки.
Стоп-механизм тоже не должен быть сложным. Например, если очередь уже заняла 80% дневной емкости, система перестает ставить в нее второстепенные кейсы и оставляет только высокий риск. Если очередь превысила 100%, в ней остаются только красные случаи и небольшая случайная выборка для контроля качества.
Такой режим особенно полезен, когда флаги приходят сразу из нескольких мест: от правил, от модели-оценщика и от продуктовых фильтров. Без отсечки даже хороший пайплайн быстро перегружает смену. Цель здесь скучная, но правильная: к концу дня очередь почти пустая.
Пример для клиентской поддержки
Представьте чат поддержки банка. Клиент спрашивает: "Почему перевод не проходит?" или "Какой у меня лимит на переводы сегодня?" Для LLM это опасная зона. Ошибка здесь быстро превращается в жалобу, повторное обращение или неверное действие со счетом. Поэтому ручную проверку лучше строить не по общему ощущению риска, а по типу ответа.
Сразу человеку стоит отправлять ответы, где модель может повлиять на деньги клиента или исказить актуальные правила банка. Это ответы с точной суммой лимита для конкретного клиента, объяснение причины отклоненного перевода или блокировки, а также совет, который меняет действие клиента: повторить перевод, ждать, звонить в банк, менять настройки.
Если модель не опирается на свежие данные по клиенту и текущие правила, такие ответы не стоит выпускать в чат даже при хорошем общем качестве. Цена ошибки здесь слишком высока.
Серая зона шире, чем кажется. Клиент спрашивает: "Есть ли лимит на переводы по номеру телефона?" Если модель отвечает общим правилом без цифр и прямо пишет, что точный лимит зависит от тарифа или статуса клиента, такой ответ часто можно пропустить без ручной проверки. Но если она добавляет примерную сумму, ссылается на вчерашние условия или путает переводы между своими счетами и перевод по СБП, ответ лучше поставить в очередь со средним приоритетом.
Тут работает простое правило: чем больше в ответе персональных данных, денег и причин отказа, тем ниже порог на эскалацию. Чем ближе ответ к общей справке, тем выше порог.
Разница по дням видна сразу. В день с низким порогом система отправляет человеку почти все сомнительные ответы. Из 1 000 диалогов в очередь уходит, например, 220. Команда тратит смену на однотипные проверки вроде "где посмотреть лимит", а срочные случаи про зависший перевод ждут вместе со всеми.
В день с нормальным порогом в очередь попадает 70-90 ответов. Наверх поднимаются кейсы с отказом в переводе, спорной суммой лимита и любым расхождением с внутренней базой правил. Простые вопросы про общие условия модель закрывает сама.
Если поток идет через RU LLM, имеет смысл сохранять аудит-трейл и причину флага по каждому запросу. Тогда ревьюер видит не просто текст ответа, а понимает, почему система вообще отправила его на проверку.
Где команды чаще ошибаются
Самая частая ошибка - ставить один и тот же порог на все сценарии. Ответ про статус заказа, совет по возврату денег и объяснение условий кредита несут разный риск, но часто получают одну и ту же логику эскалации. В итоге команда тратит время не там, где ошибка действительно дорого стоит.
Вторая частая проблема выглядит тише: очередь копят неделями и почти не разбирают, почему она растет. Люди видят только число кейсов в хвосте и начинают нанимать еще проверяющих или резко менять порог. Это лечит симптом, а не причину. Рост обычно дает что-то одно: новый промпт, новый сценарий, смена модели или неудачно настроенное правило.
Еще одна ловушка - после запуска новой модели отправлять человеку почти все ее ответы. На короткий период это нормально. Как постоянный режим - нет. Если вы используете маршрутизацию моделей, например через RU LLM, лучше явно отделить этап наблюдения от обычной работы: взять контрольную выборку, проверить рискованные типы запросов и только потом расширять ручную проверку.
Еще одна ошибка - смотреть только на число эскалаций. Меньше эскалаций не всегда значит лучше. Возможно, система просто перестала замечать плохие ответы. Поэтому нужен набор метрик, который показывает картину целиком:
- долю действительно проблемных ответов внутри очереди;
- долю пропущенных ошибок вне очереди;
- среднее время до ручного решения;
- возраст самых старых элементов в очереди.
Отдельно следите за тем, что происходит после правок в промпте. Команды часто обновляют инструкции, формат ответа или policy layer и забывают пересмотреть правила эскалации. После этого старые пороги начинают ловить не риск, а новый стиль ответа.
Нормальное рабочее правило здесь одно: каждое заметное изменение в промпте, модели или маршруте запросов должно запускать короткую перепроверку порогов. На это уходит несколько часов, зато очередь не распухает молча.
Быстрая проверка перед запуском
Перед запуском проверьте не только модель, но и то, сколько сомнительных ответов команда реально успеет разобрать за смену. Очередь ломается не из-за одного неудачного порога, а из-за набора мелких упущений: нет лимита, непонятна причина эскалации, метрики никто не смотрит.
Сначала считайте людей, потом настраивайте модель. Если смена проверяет в среднем 160 кейсов, не ставьте рабочий лимит тоже на 160. Нужен запас на всплески. Часто разумнее держать лимит на уровне 120-130, а при переполнении временно поднимать порог для низкого риска или переводить часть кейсов в выборочную проверку.
Перед релизом полезно пройтись по короткому списку:
- у очереди есть предел на смену, и команда знает, что делать при переполнении;
- для каждого типа риска задан свой порог и свой срок реакции;
- интерфейс показывает причину эскалации одной строкой, без длинного лога;
- вы заранее считаете шум, пропуски и среднее время ручной проверки;
- у правил есть владелец и дата ближайшего пересмотра.
Пороги почти никогда не работают одинаково для всех рисков. Подозрение на утечку персональных данных, токсичный ответ и сомнительная фактическая ошибка требуют разной реакции. Если смешать их в один поток с одним SLA, срочные кейсы быстро застрянут рядом с теми, что спокойно могли подождать до конца дня.
Причина эскалации должна читаться за пару секунд. Не "score 0.61", а "возможны персональные данные" или "низкая уверенность в факте про тариф". Тогда проверяющий не тратит первые полминуты на догадки.
Метрики лучше смотреть хотя бы несколько смен подряд. Шум показывает, сколько безопасных ответов вы отправили людям зря. Пропуски показывают, сколько плохих ответов прошли мимо очереди. Среднее время проверки помогает понять, выдержит ли процесс обычный понедельник, а не только спокойную пятницу.
Если вы уже ведете аудит-трейлы и причины срабатывания в RU LLM, назначьте владельца правил до запуска, а не после первого сбоя. И сразу поставьте дату пересмотра, например через две недели после релиза. Иначе временные настройки живут месяцами и медленно забивают очередь.
Что сделать в следующем спринте
Самая частая ошибка - пытаться охватить все каналы и все типы риска сразу. Так команда почти гарантированно получает шумную очередь и споры о правилах вместо разбора реальных кейсов. Лучше взять один канал, где поток уже понятен, и одну группу рисков. Для поддержки это может быть чат и только ответы с юридическими обещаниями, возвратами или персональными данными.
На один спринт этого достаточно. Цель не в том, чтобы построить идеальную систему. Нужно проверить, держится ли очередь в рамках смены и не теряет ли она действительно опасные ответы.
Минимальный план на спринт:
- Выберите один канал и один риск-сценарий.
- Поставьте стартовый порог и дневной лимит на число эскалаций.
- Прогоните поток 5 рабочих дней с обязательной ручной сверкой.
- Отмечайте два типа ошибок: шум и пропуски.
- В конце недели примите одно решение по порогу - поднять, снизить или оставить.
Ручная сверка нужна каждый день, а не только в конце. Иначе вы увидите итоговые цифры, но не поймете, почему система шумела во вторник и пропустила риск в четверг. Достаточно короткой формы для ревьюера: "сработало зря", "нужно было эскалировать", "не уложились в SLA", "ответ спорный, но допустимый".
Отчет тоже не должен разрастаться. Обычно хватает одной страницы с тремя блоками: что чаще всего шумит, что уходит мимо очереди и где команда не успевает проверить кейс вовремя. Если нашли проблему, не пытайтесь чинить все сразу. Один спринт - одно решение. Иначе будет сложно понять, что дало эффект.
Если вы строите такой контур через RU LLM, проверьте это еще до пилота: есть ли аудит-трейлы по каждому запросу, включена ли маскировка PII и хватает ли выбранной модели по качеству для вашего потока. Иногда более точная модель снимает часть ручной нагрузки уже на первой неделе.
Хороший результат спринта выглядит довольно буднично: очередь предсказуема, люди успевают ее разбирать, а спорных кейсов становится меньше. С этого уже можно спокойно подключать следующий канал или следующий тип риска.
Часто задаваемые вопросы
Почему очередь растет, даже если модель отвечает нормально?
Потому что входящий поток выше, чем команда успевает проверить. Даже хорошая модель создаст хвост, если правила отправляют в очередь слишком много безопасного шума.
Что вообще считать сомнительным ответом?
Нет. Вручную лучше отправлять ответы с риском для пользователя, бизнеса или правил: утечку PII, опасный совет, явную фактическую ошибку в дорогом сценарии. Сухой тон, общий ответ или лишняя осторожность сами по себе не требуют ревью.
Можно ли ставить один порог на все сценарии?
Почти всегда нет. Для общей справки порог можно держать выше, а для платежей, возвратов, договоров и PII — ниже. Один общий порог обычно либо забивает очередь, либо пропускает риск.
Как быстро подобрать стартовый порог без гадания?
Возьмите свежую выборку за 1–2 недели и разметьте ее вручную по простым типам ошибок. Потом запустите правила на малой доле трафика и посмотрите, сколько шума попало в очередь и сколько плохих ответов прошло мимо.
Как расставить приоритеты внутри очереди?
Сначала поднимайте то, что может привести к потере денег, утечке данных или жалобе. Потом — ответы, где пользователь может сделать неверное действие или пропустить срок. Спорный стиль и тон держите внизу, чтобы они не мешали срочным кейсам.
Как понять, сколько ручных проверок команда реально выдержит?
Посчитайте емкость смены по факту: сколько кейсов один человек закрывает за час без спешки, и сколько полезных часов остается после сложных разборов. Если система шлет больше, чем команда реально тянет, хвост появится в тот же день.
Что делать, если очередь уже переполнена?
Срежьте вход для слабых сигналов и оставьте только высокий риск. Средний риск пускайте, пока очередь не дошла до лимита, а низкий переводите в выборку или снимайте автоправилами.
Какие метрики показывают, что пороги настроены плохо?
Смотрите не только на число эскалаций. Нужны еще шум внутри очереди, пропуски вне очереди, среднее время до ручного решения и возраст самых старых кейсов. Так вы увидите, где система грузит людей зря, а где пропускает риск.
Нужно ли звать человека на каждый сбой качества?
Не должен. Если машина может безопасно исправить ответ сама — например, скрыть PII, повторить запрос с более строгим промптом или попросить уточнение — человека лучше не звать. В очередь отправляйте случаи, где после автопоправки риск остался.
С чего начать в следующем спринте, чтобы не утонуть в настройках?
Возьмите один канал и один риск-сценарий, а не весь продукт сразу. Запустите пилот на 5 рабочих дней, каждый день отмечайте шум и пропуски, а в конце недели меняйте только одно правило, чтобы понять эффект.