Контроль расходов LLM: алерты, hard cap и лимиты команд
Контроль расходов LLM помогает поставить алерты, hard cap и отчёты по командам так, чтобы счёт не удивил CFO в конце месяца.
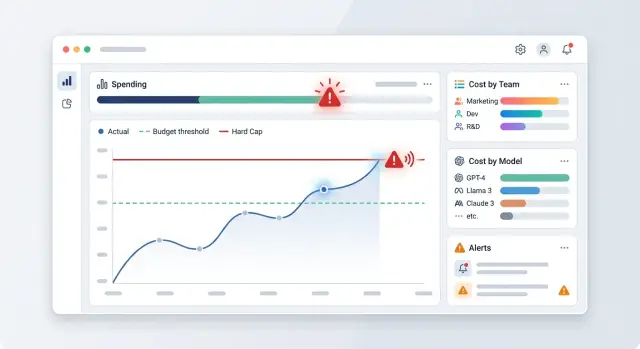
Где расход уходит из-под контроля
Счёт за LLM почти никогда не растёт ровно. Неделю всё выглядит спокойно, а потом за день расход прыгает в два или три раза. Обычно причина не в одном большом релизе, а в нескольких мелочах сразу: команда включила нагрузочные тесты, пилот получил больше трафика, разработчики подняли лимит контекста, а ретраи начали дублировать дорогие вызовы.
Чаще всего деньги утекают не в основном пользовательском сценарии, а рядом с ним. Тестовые стенды забывают выключить. Агентный флоу уходит в лишние итерации. Неудачный промпт тянет за собой длинную историю диалога, и каждый следующий запрос становится дороже предыдущего.
Перерасход обычно складывается из одних и тех же причин: ретраи без жёсткого лимита и без дедупликации, длинный контекст "на всякий случай", fallback на более дорогую модель после таймаута, параллельные эксперименты без общего обзора и batch-задачи, eval или внутренние тесты, которые сидят в том же бюджете, что и прод.
Общий месячный лимит почти не спасает. Он срабатывает слишком поздно. Когда команда замечает проблему 28 числа, разговор уже не о том, как её предотвратить, а о том, кто будет объяснять перерасход. Для финансов это худший сценарий: деньги уже потрачены, а причина расползается по догадкам.
CFO обычно не нужен разбор токенов по каждому запросу. Ему нужен понятный ответ на четыре вопроса: кто потратил, на что, когда начался скачок и можно ли было остановить его раньше. Если этих ответов нет до закрытия месяца, всё заканчивается ручными сверками.
Ещё хуже, когда одна цифра скрывает разные типы нагрузки. Продовый чат, внутренние eval, пилот с новым ассистентом и ночной импорт документов не должны лежать в одном общем ведре. Иначе команда видит только общий счёт, но не понимает, что именно сломало бюджет.
На практике полезнее смотреть не на "расход за месяц", а на скорость сжигания бюджета по дням и по владельцам. Если вчера команда тратила 8 тысяч рублей в день, а сегодня уже 27 тысяч, проблема есть уже сейчас. Ждать конца месяца в такой ситуации слишком дорого.
Что считать расходом, кроме токенов
Счёт по LLM почти никогда не сводится к формуле "входные токены + выходные токены". Перерасход обычно прячется в том, как запросы проходят через систему, сколько раз они повторяются и какие процессы запускаются без внимания команды.
Токены всё равно остаются базовой метрикой, но считать их надо по каждой модели отдельно. У одной модели дешевле вход, у другой дороже выход. Если продукт часто просит длинный ответ, итоговая сумма растёт даже при том же трафике. То же касается больших system prompt: один лишний абзац, умноженный на тысячи запросов в день, быстро превращается в заметную строку расходов.
Частая утечка бюджета - ретраи и таймауты. Клиент не дождался ответа за 12 секунд, отправил запрос ещё раз, а первый вызов всё же дошёл до провайдера. Для счёта это уже два запроса. Автоматические ретраи в SDK, очередях и воркерах делают ту же проблему тише, но дороже. Поэтому стоит считать не только успешные ответы, но и все попытки, включая отменённые и повторные.
Автопереключение на более дорогую модель тоже меняет экономику. На бумаге у вас может быть дешёвый маршрут по умолчанию, но в проде часть запросов уходит на более сильную модель из-за низкой уверенности, ошибок формата или перегрузки провайдера. Если таких переключений стало не 3%, а 18%, бюджет меняется резко, даже без роста пользователей.
Отдельно деньги съедают процессы, которые редко попадают в еженедельный отчёт: фоновые джобы с ночными прогонами, тестовые стенды, регрессионные проверки промптов, переиндексация и пакетная обработка старых данных. Они не видны пользователю, но счёт разгоняют отлично.
Если трафик идёт через единый OpenAI-совместимый шлюз, удобно собирать расход не только по токенам, но и по типу запроса, модели, провайдеру и окружению. В случае RU LLM это особенно полезно: через один эндпоинт проще увидеть, что прод держится в рамках, а перерасход пришёл из staging, eval или фонового воркера.
Минимальный набор полей для учёта простой: модель, провайдер, входные токены, выходные токены, число попыток, признак автопереключения, источник трафика и окружение. Без этой разметки счёт всегда выглядит случайным, хотя причина почти всегда очень конкретная.
Как разметить запросы по командам и продуктам
Если у запроса нет меток, расход быстро превращается в общий шум. Потом сложно понять, кто сжёг бюджет: продуктовая команда, внутренний бот поддержки или один POC, который забыли выключить. Для нормального контроля нужна простая и единая схема тегов.
Обычно хватает четырёх обязательных меток: команда, проект, среда и признак эксперимента. Этого достаточно, чтобы разделить прод, разработку и тесты, а потом быстро собрать расход по людям и задачам. Имена должны быть короткими и фиксированными. Лучше team=search, чем пять вариантов вроде search-team, poisk и search_prod.
Отдельная метка для экспериментов нужна почти всегда. POC и разовые тесты ведут себя хуже всего: их запускают быстро, промпты меняют каждый день, а про лимиты вспоминают поздно. Если помечать такие запросы как experiment=true или cost_center=poc, вы сразу видите, где расход нестабилен, и не путаете его с обычной нагрузкой продукта.
Словарь тегов должен держать один владелец. Чаще всего это platform team, ML platform или инженер, который отвечает за LLM-инфраструктуру и биллинг. Не стоит отдавать это каждой команде на своё усмотрение. Иначе одна команда пишет prod, другая production, третья main, и нормальный разбор счёта ломается.
Правило простое: новые значения тегов кто-то утверждает, а старые периодически чистят. Раз в месяц обычно достаточно. Если у вас единый шлюз для моделей, сводить расход по тегам заметно проще, потому что весь трафик проходит через одну точку.
Запросы без меток лучше не пускать в прод вообще. Мягкий вариант подходит только для dev и stage: помечать такие вызовы как unknown, складывать в отдельную группу и разбирать каждый день. В проде лучше жёсткое правило: нет team и project - запрос не уходит.
Сначала это кажется слишком строгим. На практике одна проверка на входе экономит много часов, когда приходит счёт и нужно быстро объяснить, кто и на что потратил деньги.
Как настроить алерты по шагам
Если контроль расходов появляется только в конце месяца, он уже мало помогает. Алерт должен сработать раньше, чем перерасход станет проблемой для бюджета или для дежурной команды.
Начните не с одного лимита, а с трёх. Дневной порог ловит резкие ошибки, недельный показывает, что пилот тихо растёт быстрее плана, а месячный держит общий бюджет. Обычно хватает трёх уровней на каждом горизонте: предупреждение, тревога и стоп-сигнал для ручной проверки. Например, 70%, 90% и 100% от лимита.
Отдельно поставьте детектор на скачок за час. Именно так чаще всего находят цикл ретраев, неудачный релиз или внезапный рост трафика из одного продукта. Если команда обычно тратит 4 000 рублей в час, а за последние 60 минут ушло 15 000, ждать дневного лимита уже поздно.
Рабочая схема выглядит так:
- Задайте базовые бюджеты на день, неделю и месяц для всей системы и для крупных команд.
- Добавьте правило на аномалию за час: фиксированная сумма или рост в 2-3 раза относительно нормы.
- Разведите каналы оповещения по срочности. Предупреждение можно слать в чат, тревогу - на почту и дежурному.
- Назначьте одного человека на смену, который подтверждает алерт, проверяет причину и закрывает инцидент.
- Сымитируйте превышение и проверьте, что сообщение дошло и кто-то действительно отреагировал.
Канал важен не меньше порога. Чат подходит для ранних сигналов, когда нужно просто обратить внимание. Почта полезна для истории и отчёта. Дежурный нужен там, где расход может вырасти за 15 минут и ударить по проду.
Ещё одна частая ошибка: алерт приходит всем, значит не отвечает никто. Укажите владельца прямо в правиле. Кто подтверждает сигнал, кто ищет источник расхода, кто решает, отключать ли фичу или менять модель.
Если весь LLM-трафик идёт через один API-шлюз, считать такие пороги проще. Видно общий расход, расход по провайдерам и моменты, когда одна модель внезапно начинает съедать бюджет быстрее остальных. Но даже хорошая отчётность не спасает, если алерт ни разу не проверили вручную. Тестовое превышение перед запуском экономит больше денег, чем кажется.
Как поставить hard cap и не сломать сервис
Жёсткая отсечка работает нормально только тогда, когда до неё есть мягкий лимит. Сначала поставьте порог предупреждения, например на 70% и 85% месячного бюджета команды. На этом этапе система ещё не режет трафик, а шлёт алерт, пишет владельцу бюджета и включает заранее согласованные меры экономии.
Обычно хватает двух действий: убрать дорогие модели из fallback-цепочки и снизить лимит на необязательные запросы. Так вы ловите перерасход раньше, а hard cap остаётся последним барьером, а не первым ударом по проду.
Когда бюджет всё же упёрся в потолок, отключайте нагрузку по очереди, а не всё сразу. Сначала песочницы и внутренние демо, потом batch-задачи, которые можно перенести, затем необязательный fallback на более дорогую модель и только после этого A/B-эксперименты или автооценку, если они не влияют на клиентский путь.
Критичные сценарии лучше вынести в белый список заранее. Если LLM участвует в антифроде, обработке обращений VIP-клиентов или внутреннем саппорте для дежурной команды, этим запросам нужен отдельный бюджетный контур. Для них можно оставить доступ только к одной проверенной модели и жёстко ограничить объём, но не рубить сервис полностью.
Молчаливый отказ злит людей и мешает разбору. Если hard cap сработал, верните понятную ошибку: лимит исчерпан, такие-то запросы заблокированы, лимит обновится тогда-то, временное снятие стопа согласуется там-то. Пользователь должен сразу понимать, это сбой или правило бюджета.
Заранее решите, кто может снять стоп и как это происходит. Обычно хватает короткой схемы: владелец бюджета подтверждает перерасход, дежурный инженер открывает доступ на фиксированную сумму или до конца суток, система пишет это в аудит. Без такого правила hard cap быстро превращается в хаос в чате.
Для контроля расходов LLM это скучная, но полезная дисциплина. Если весь трафик идёт через единый API-шлюз, такие правила проще держать в одном месте, а не размазывать по разным сервисам и ключам.
Как разбирать счёт по командам, моделям и провайдерам
Один общий счёт почти ничего не объясняет. Нужен срез, в котором видно, кто потратил деньги, на какие модели ушёл бюджет и какой провайдер дал этот расход.
Обычно хватает трёх измерений: команда, модель и провайдер. Добавьте к ним день или неделю, и у вас появится картина, по которой можно принимать решения, а не спорить по ощущениям.
Какие срезы смотреть
Сначала соберите простой отчёт за день и за неделю по каждой команде. Дневной срез ловит резкие всплески, недельный показывает, это разовый сбой или новая норма.
Смотрите не только на сумму. Полезно держать рядом ещё четыре числа: количество запросов, входные токены, выходные токены и среднюю стоимость одного успешного ответа. Так быстро видно, где команда стала чаще дёргать модель, а где модель просто начала отвечать слишком длинно.
Отдельно сравнивайте модели по цене и реальной пользе. Если одна модель стоит в два раза дороже, но почти не меняет качество в вашей задаче, держать её нет смысла. Для саппорта это видно по доле принятых ответов, для внутреннего поиска - по числу перезапросов, для генерации кода - по объёму ручных правок после ответа.
С провайдерами логика такая же. Если один и тот же сценарий через другого провайдера стоит дороже, а задержка и качество не меняются, вы нашли плохой маршрут. В шлюзе вроде RU LLM это видно особенно хорошо: запросы идут через единый OpenAI-совместимый эндпоинт, и потом можно поднять аудит-трейл по модели, провайдеру и стоимости каждого вызова.
Ещё один полезный сигнал - ответы с необычно длинным выводом. Часто перерасход начинается не с роста трафика, а с того, что один промпт внезапно стал возвращать по 4-5 тысяч токенов там, где раньше хватало 400. Такие ответы лучше помечать отдельно и разбирать вручную.
Как принимать решения по цифрам
После такого разбора действия обычно простые: сменить маршрут для конкретной команды или сценария, опустить лимит output tokens там, где ответы раздуваются, перевести часть задач на более дешёвую модель или оставить дорогую модель только для случаев, где она действительно окупается.
Хороший отчёт не обязан быть красивым. Он должен за пять минут отвечать на три вопроса: кто потратил больше обычного, какая модель дала этот рост и был ли в этом смысл. Если ответа нет, счёт уйдёт вверх раньше, чем команда это заметит.
Пример: пилот улетел в перерасход на второй неделе
У одной команды пилот начинался спокойно: чат для сотрудников и небольшой внутренний помощник для аналитиков. Бюджет дали один на двоих, потому что объём казался маленьким. На первой неделе этого хватало.
Проблема пришла ночью. Команда аналитиков гоняла автотесты и eval-наборы после каждого обновления промптов, а в конфиге по умолчанию осталась дорогая модель, которую брали для ручной проверки качества. Скрипты крутились каждый час, и за одну ночь они сожгли больше, чем дневной продовый трафик за три дня.
Алерт тоже не помог. Его поставили на общий дневной порог, поэтому он сработал уже после скачка, когда расход за час вырос в несколько раз. К утру стало ясно, что контроль был только на бумаге: счёт ещё не пришёл, но месячный лимит уже заметно просел.
Команда не стала рубить весь сервис. Она ввела hard cap только для второстепенного трафика: ночных тестов, sandbox и разовых экспериментов. Пользовательские запросы оставили жить, но перевели на отдельный лимит и более дешёвую модель по умолчанию.
После разбора выяснилось, что общая корзина скрывала реальную картину. Пока все запросы шли без тегов, казалось, что перерасход дал один продукт. На деле деньги утекали из трёх мест сразу: ночные прогоны, повторные ретраи и ручные тесты без лимита.
Они добавили простую разметку в каждый запрос:
team: support или analyticsenv: prod, stage, testpurpose: user, eval, batch, manualbudget: soft или hard
После этого каждой команде дали свой потолок, а для тестов поставили отдельное правило: если часовой расход прыгает выше нормы, система режет только test и eval-трафик. Прод не страдает.
Через неделю картина стала простой. Финансы видели, кто тратит, на какие модели и в какое время. Инженеры быстро нашли шумные джобы. А общий бюджет перестал быть общей проблемой. Если пилот делят две команды, один кошелёк почти всегда ломается первым.
Ошибки, которые быстро съедают бюджет
Самая дорогая ошибка - один общий лимит на всю компанию. Сначала это кажется удобным: один бюджет, один счёт, меньше настроек. На практике команда с активным пилотом быстро съедает запас, а продовая часть узнаёт об этом по отказам или по письму от финансиста.
Почти так же плохо, когда прод и песочница живут в одном контуре. Разработчик гоняет длинные промпты, тестирует fallback, сравнивает пять моделей подряд, а деньги уходят из того же кошелька, что и клиентский трафик. Для CFO это один расход. Для инженеров это две разные истории, и считать их нужно отдельно.
Месячный счёт тоже обманывает. Если команда смотрит только на итог в конце месяца, она замечает проблему слишком поздно. За это время один неудачный релиз может умножить расход в несколько раз: выросли токены в ответе, включился дорогой провайдер, ретраи пошли по кругу. Нужен более короткий ритм - хотя бы дневной срез и простые сигналы по скачкам.
Отдельная ловушка - не отделять POC от постоянной нагрузки. В пилоте люди почти всегда делают то, что в проде запрещено: длинный контекст, много ручных прогонов, сравнение моделей на одних и тех же данных. Если такой трафик смешать с рабочим, кажется, что продукт стабильно дорогой, хотя на самом деле бюджет съедает временный эксперимент.
Ещё один тихий убийца бюджета - fallback без верхнего порога. Сервис не может достучаться до основной модели и уходит на запасной маршрут. Если там модель в 3-5 раз дороже и никто не поставил потолок по цене или по дневному расходу, аварийный режим начинает сжигать деньги быстрее, чем обычная нагрузка.
Это часто видно в командах, которые подключают единый OpenAI-совместимый шлюз и радуются, что код менять не надо. Это удобно, но без разделения по средам, продуктам и командам единая точка входа прячет источник перерасхода. Потом спорят все: продукт винит ML, ML винит интеграцию, а счёт уже приехал.
Хорошее правило простое: отдельный лимит на команду, отдельный лимит на среду, отдельный контур для пилотов и жёсткий потолок на fallback. Иначе даже аккуратная система учёта не спасёт.
Быстрый чек-лист перед запуском
Перед запуском полезно пройтись по короткому списку. Он выглядит скучно, зато часто экономит больше, чем разовая оптимизация промптов. Один пропуск - и через неделю уже непонятно, кто потратил деньги: прод, тесты или одна команда с неудачным пилотом.
- У бюджета должен быть конкретный владелец. Не "платформа" и не "ML-команда", а человек, который видит лимит, получает алерты и решает, что делать при перерасходе.
- В каждом запросе нужны метки команды, проекта и среды. Иначе расходы смешаются, и вы не отделите эксперимент в staging от реального трафика в prod.
- Поставьте два порога. Мягкий лимит предупреждает заранее, а hard cap останавливает рост счёта, если команда не заметила сигнал или отложила разбор.
- Проверьте алерт руками. Проще всего временно занизить порог и отправить несколько тестовых запросов, чтобы убедиться: уведомление дошло, в нём есть сумма, модель и источник расхода.
- Убедитесь, что отчёт можно разрезать по модели, проекту и среде. Если виден ещё и провайдер, вы быстрее поймёте, где расход вырос из-за маршрутизации, а где из-за самих сценариев.
На практике всё просто. Допустим, одна команда гоняет eval на дешёвой модели, а другая случайно отправила batch-задачу в более дорогую. Если в запросах нет меток, в счёте это сольётся в одну цифру. Если hard cap не стоит, перерасход продолжится до утра. Если алерт никто не проверял, сообщение может уйти не туда и остаться без ответа.
Для OpenAI-совместимого шлюза, такого как RU LLM, этот минимум особенно удобен: команды могут не менять SDK и код, но теги, лимиты и отчёты всё равно нужно продумать до запуска. Самый частый промах не в цене токена, а в отсутствии дисциплины учёта.
Если хотя бы один пункт из списка не готов, запуск лучше сдвинуть на день. Это дешевле, чем потом разбирать неожиданный счёт по памяти и догадкам.
Что сделать дальше
Не раскатывайте лимиты сразу на всю компанию. Начните с одного продукта, где уже есть живой трафик и понятный владелец. Для первого цикла хватит недельного лимита, а не месячного: так перерасход видно раньше, и команда успевает поправить маршрутизацию, промпты или выбор модели до неприятного счёта.
Хорошее правило на старте простое: лимит должен быть достаточно низким, чтобы ошибка была дешёвой, и достаточно высоким, чтобы пилот не умер в первый же день. Если сервис тратит 20-30% бюджета уже к середине недели, вы быстро поймёте, это нормальный спрос или перекос в запросах.
Дальше зафиксируйте правила стопа. Это лучше согласовать не только с инженерами, но и с CFO и владельцами сервисов. У всех должна быть одна версия ответа на три вопроса: кто получает сигнал, кто может поднять лимит и что происходит после hard cap - полная остановка, переход на более дешёвую модель или только отключение необязательных сценариев.
Раз в неделю смотрите не весь отчёт целиком, а три источника затрат: какие модели съели большую часть бюджета, какие команды или продукты дали всплеск трафика и где деньги ушли на повторы, длинный контекст или неудачные эксперименты. Этого обзора обычно хватает, чтобы держать расходы под контролем без тяжёлой отчётности.
Если у вас несколько команд и нужен единый OpenAI-совместимый эндпоинт с биллингом и аудит-трейлами внутри РФ, такие ограждения удобно собирать поверх RU LLM. Особенно когда важно держать логи и бэкапы в российском контуре и не склеивать отчётность из нескольких систем вручную.
Нормальный следующий шаг простой: выберите один сервис, поставьте недельный лимит, назначьте ответственного и проведите первый разбор через семь дней. После этого быстро становится видно, что можно масштабировать, а что лучше запретить сразу.
Часто задаваемые вопросы
С какого лимита лучше начать: дневного, недельного или месячного?
Сначала ставьте дневной и часовой контроль, а месячный оставьте как общий потолок. Дневной порог ловит резкие ошибки, а часовой быстрее показывает ретраи, ночные джобы и внезапный рост трафика.
Какие теги нужны в каждом LLM-запросе?
Обычно хватает четырёх меток: team, project, env и признак эксперимента вроде experiment=true или отдельного purpose. Если этих полей нет, вы быстро теряете ответ на вопрос, кто именно тратит деньги.
Что обычно незаметно раздувает счёт?
Чаще всего счёт разгоняют ретраи без дедупликации, длинный контекст "на всякий случай", fallback на дорогую модель и тесты, которые сидят в одном бюджете с продом. Такие вещи редко видны в общем месячном числе, но именно они дают скачки.
Когда hard cap уже нужен, а когда хватает алертов?
Ставьте мягкие пороги раньше жёсткой отсечки, например на 70% и 90% бюджета. Так команда успеет убрать дорогой fallback, снизить лимит output tokens или остановить второстепенный трафик до полного стопа.
Как включить hard cap и не уронить прод?
Не режьте всё сразу. Сначала отключайте sandbox, eval, batch и внутренние демо, а критичные сценарии держите в отдельном контуре с своей моделью и своим лимитом.
Кто должен отвечать за бюджет LLM?
Назначьте одного человека, а не абстрактную команду. Этот владелец получает алерты, подтверждает перерасход и решает, кто и на сколько может временно поднять лимит.
Нужно ли отделять prod, stage и eval по бюджету?
Да, иначе разработка и пилоты маскируют реальный продовый расход. Когда prod, stage, test и eval лежат в разных контурах, вы быстрее находите источник скачка и не спорите о причинах по памяти.
Как понять, что бюджет съедает fallback на дорогую модель?
Посмотрите на долю автопереключений и на расход по моделям за день или час. Если дешёвый маршрут на бумаге есть, а в отчёте растёт более дорогая модель, значит fallback уже меняет экономику.
Что показывать CFO вместо сырых токенов?
Ему обычно нужны не токены по каждому вызову, а четыре вещи: кто потратил, на что ушли деньги, когда начался скачок и можно ли было остановить его раньше. Отчёт по командам, моделям, провайдерам и времени закрывает этот запрос лучше, чем сырые логи.
С чего начать, если мы уже работаем через единый LLM-шлюз?
Начните с одного сервиса с живым трафиком и понятным владельцем. Если трафик идёт через единый OpenAI-совместимый шлюз вроде RU LLM, проще сразу ввести теги, недельный лимит, часовой алерт и первый разбор через семь дней.