Разграничение доступа к промптам с чувствительными данными
Разграничение доступа к промптам помогает отделить шаблоны, переменные и логи по ролям и снизить риск утечек в разработке, аналитике и саппорте.
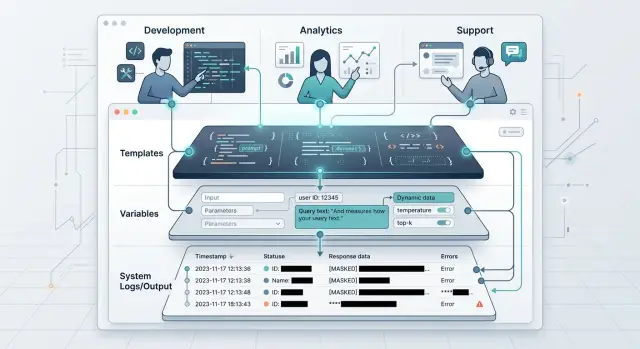
Где возникает риск
Риск появляется не в момент ответа модели, а раньше - когда один и тот же промпт начинают использовать разные команды для разных задач. Разработчики проверяют гипотезы, аналитики смотрят на качество ответов, саппорт разбирает спорные кейсы. Если у всех общий доступ, границы быстро стираются.
Сам шаблон промпта редко выглядит опасным. Проблема обычно в переменных, которые подставляются в него на лету. Именно в них часто лежат имена клиентов, номера договоров, тексты обращений, адреса, суммы и внутренние комментарии.
Чаще всего эти данные приходят сразу из нескольких систем: CRM, тикет-системы, клиентских чатов и внутренних заметок сотрудников. В этот момент простой шаблон превращается в контейнер для реальных персональных данных. Один сотрудник видит только текст запроса и не замечает проблемы. Другой открывает полный лог и получает доступ ко всей переписке клиента, хотя ему нужен был только код ошибки или итоговый ответ.
Логи усиливают этот риск. Многие команды по привычке сохраняют полный запрос и полный ответ, чтобы потом разбирать инциденты. На старте это удобно. Потом в логах скапливается лишний текст: старые обращения, служебные поля, фрагменты документов, номера телефонов. Если доступ к таким логам открыт слишком широко, утечка уже не выглядит редким сценарием.
В поддержке это видно особенно быстро. Оператор открывает карточку клиента, система подставляет данные из тикета и CRM, а модель готовит черновик ответа. Потом разработчик смотрит тот же лог, чтобы понять, почему ответ получился слабым. Аналитик берет выборку для оценки качества. Если доступы не разделены заранее, каждый из них видит больше, чем нужно для работы.
Особенно быстро риск растет там, где хотят запуститься без лишних согласований. На старте общий доступ правда экономит время. Через месяц оказывается, что шаблоны, переменные и логи лежат в одном месте, а правила доступа никто не зафиксировал. Тогда любая отладка, выгрузка или ручной разбор инцидента может открыть чужие данные не тому человеку.
Что разделить с самого начала
Проблемы с доступом начинаются задолго до первой ошибки модели. Часто команда складывает в одно место шаблон промпта, подставляемые данные, токены, тестовые примеры и рабочие логи. Через пару недель уже непонятно, кому что можно показывать без риска.
Проще всего строить доступ вокруг типов данных. Если разделить их в первый день, потом не придется срочно чистить логи, переносить секреты и закрывать лишние права.
Шаблон промпта лучше хранить отдельно от переменных. Шаблон - это текст и логика: инструкции, формат ответа, системные правила. Переменные - это данные из CRM, тикета, анкеты или чата клиента. Когда все слито в одну строку, любой, кто правит формулировку, видит и реальные данные пользователей. Обычно в этом нет никакой пользы.
Секреты тоже не стоит держать внутри промпта. API-ключи, служебные токены, внутренние идентификаторы и фрагменты конфигурации быстро расползаются по истории версий, заметкам и скриншотам. Потом их сложно собрать обратно. Проще считать промпт обычным текстом, а секреты держать отдельно - в менеджере секретов или в настройках сервиса.
Еще одна частая ошибка - смешивать рабочие логи с тестовыми данными. Разработчику нужен материал для отладки, но это не значит, что ему нужен доступ ко всем диалогам клиентов. Если у команды есть тестовый набор с обезличенными примерами, большую часть проверок можно делать без просмотра продакшн-логов.
Учебные примеры и реальные кейсы тоже лучше развести. Для обучения команды хватит коротких очищенных сценариев: запрос, набор переменных, ожидаемый ответ и типичная ошибка. Доступ к реальному кейсу лучше давать по запросу и с понятной причиной.
Простое правило работает лучше сложных схем: один объект данных - одна зона доступа. Если саппорт разбирает странный ответ модели, ему обычно хватает версии шаблона и обезличенных полей. Оригинальный диалог клиента нужен только тому, кто отвечает за инцидент и может объяснить, зачем он его открывает.
Кто что должен видеть
Если всем открыть полный промпт, переменные и сырые логи, путаница начинается очень быстро. Одни люди меняют шаблоны, другие ищут причины ошибок, третьи отвечают клиенту. Им не нужен одинаковый доступ.
Права лучше выдавать по задаче, а не по должности на визитке. Один и тот же сотрудник может видеть больше в тестовом контуре и меньше в продакшне.
Обычно роли делят так:
- Разработчик видит текст шаблона, его версии, системные инструкции, правила вызова модели и технические ошибки. Реальные персональные данные клиента ему чаще всего не нужны. Для отладки обычно хватает маскированных значений и ссылки на версию шаблона.
- Аналитик видит метрики: долю успешных ответов, время отклика, стоимость, частые причины отказов и обезличенные примеры. Этого достаточно, чтобы понять, где проседает сценарий, без доступа к имени клиента, номеру договора или телефону.
- Саппорт видит итоговый ответ системы, статус обращения, категорию ошибки и безопасный фрагмент переписки. Ему не нужны скрытые инструкции, внутренние теги маршрутизации и служебные переменные.
- Сотрудник ИБ видит журнал действий, смену ролей, выгрузки логов, доступ к полным данным и следы ручного просмотра. Его задача - проверять, кто и зачем открывал чувствительные данные.
Такое разделение снижает риск лишнего доступа. И разбирать спорные ситуации тоже проще. Если кто-то выгрузил больше данных, чем требовалось, это сразу видно.
На примере банка это выглядит так: сотрудник поддержки видит, что клиенту ушел неверный итог и обращение нужно пересмотреть. Аналитик замечает, что ошибка часто возникает на одном типе запросов и в одной версии сценария. Разработчик смотрит, какой шаблон сработал и по какому правилу вызвали модель. ИБ проверяет, кто открывал полный лог и была ли выгрузка наружу.
Как настроить доступ по шагам
Начните с одного живого сценария, а не со всей системы сразу. Например, разберите обработку обращения клиента: кто пишет шаблон, откуда приходят переменные, что уходит в LLM, что попадает в логи и кто потом это читает.
На этом этапе полезно не обсуждать роли в общем, а нарисовать путь данных по шагам. Если в шаблоне есть текст для оператора, а в переменных - имя клиента, номер заказа и причина обращения, эти части уже стоит разделить. Так схема доступа строится на реальном потоке данных, а не на догадках.
Дальше назначьте владельца для каждой части. Шаблон обычно держит продуктовая или ML-команда, переменные - владелец бизнес-процесса или системы-источника, логи - команда эксплуатации или безопасности. Когда у объекта нет владельца, права быстро расползаются по чатам, тестовым стендам и выгрузкам.
После этого задайте не один флаг "можно или нельзя", а несколько простых прав: чтение шаблона, запуск сценария, изменение шаблона и экспорт логов. На практике именно экспорт чаще всего ломает всю схему. Аналитику нередко нужен просмотр обезличенного лога, но не выгрузка сырых данных. Саппорту нужен запуск готового сценария, но не правка шаблона. Разработчику может быть нужен тестовый запуск с синтетическими данными, а не доступ к рабочим логам.
Потом проверьте схему на одном процессе. Не берите сразу весь каталог промптов. Возьмите один частый сценарий, дайте роли нескольким группам, попросите их выполнить обычные действия и посмотрите, где люди утыкаются в лишние запреты, а где видят больше, чем нужно.
Если вы работаете через LLM-шлюз, отдельно проверьте, кто видит запрос целиком на уровне API, а кто - только результат и технические метки. Для команд с требованиями 152-ФЗ это не формальность. Доступ к логам, маскированию PII и аудит-трейлам лучше разложить до запуска, а не после первого инцидента.
Хорошая схема обычно выглядит скучно. У каждого есть ровно тот доступ, который нужен ему каждый день. И не больше.
Как хранить переменные отдельно от шаблонов
Самый безопасный вариант простой: шаблон живет отдельно, а личные данные подтягиваются только в момент запроса. Тогда разработчик видит текст с плейсхолдерами вроде {name} и {order_id}, но не видит реальные ФИО, номер заказа и сумму.
Готовый промпт опаснее всего хранить целиком. В нем уже собраны и логика, и персональные данные, и иногда внутренние поля, которые модели вообще не нужны. Если такой текст попал в лог, тикет или чат команды, утечка уже произошла.
Где что хранить
Шаблон можно держать в коде, Git-репозитории или отдельном хранилище конфигурации. Переменные лучше держать в другом контуре: в базе приложения, CRM, helpdesk системе или временном объекте в памяти, который живет только во время обработки запроса.
Практичная схема выглядит так:
- шаблон содержит только текст, инструкции и плейсхолдеры;
- ФИО, номер заказа и сумму приложение подставляет в рантайме;
- секреты вроде API-ключей, токенов и служебных флагов лежат отдельно от шаблона;
- лог хранит ID запроса, статус и технические метки, а не полный набор переменных.
Если поле не влияет на ответ модели, не передавайте его. Внутренний комментарий оператора, fraud score, сегмент клиента, служебный email команды - все это часто попадает в промпт по привычке, а не по необходимости.
Доступ тоже лучше делить по набору полей, а не только по системам. Разработчику обычно хватает шаблона и тестовых данных. Аналитику нужны обезличенные выборки и метрики. Саппорт видит только те поля, без которых нельзя разобрать обращение, например маскированный номер заказа и время запроса.
Полезное правило простое: каждая роль получает минимальный набор переменных для своей задачи. Если сотрудник не может объяснить, зачем ему видеть сумму заказа или полное имя клиента, это поле лучше скрыть.
Срок хранения тоже задавайте отдельно для каждого типа данных. Переменные для генерации ответа можно удалять сразу после обработки, а для разбора инцидентов оставлять короткий срок, например несколько дней. Если данные нужны дольше, часто хватает хеша, маскированного значения или ссылки на запись в основной системе.
Как вести логи без лишних данных
Если в лог попал сырой диалог клиента с телефоном, почтой или паспортными данными, проблема уже случилась. Логирование для LLM лучше строить по простому правилу: писать минимум, которого хватает для разбора ошибки, а не все подряд.
Первый фильтр должен срабатывать до записи. Телефон, email, номер договора и другие личные поля нужно маскировать на входе, а не после инцидента. Если команда рассчитывает почистить архив позже, лишние данные уже лежат в архиве.
Что писать вместо полного текста
Во многих случаях для разбора хватает не полного диалога, а служебного следа запроса. Обычно сохраняют ID запроса, время, модель, статус ответа, код ошибки, длительность и несколько технических флагов. Этого достаточно, чтобы найти сбой, повторить маршрут и понять, на каком шаге все сломалось.
Полный текст нужен редко. Например, когда команда ищет причину плохого ответа в шаблоне или в подстановке переменных. Даже тогда лучше сохранять только короткий фрагмент или заранее очищенную версию без персональных данных.
Саппорту сырой лог почти никогда не нужен. Ему удобнее дать короткую выжимку: что сделал пользователь, на каком шаге возникла ошибка, какой ID запроса передать разработке и что клиент увидел на экране. Так саппорт решает задачу быстрее и не получает лишний доступ.
Обычно такой краткий след включает ID запроса, тип ошибки, время и канал обращения, обезличенное описание шага пользователя и статус эскалации.
Отдельно проверьте срок хранения. По 152-ФЗ нельзя держать данные дольше, чем это нужно для заявленной цели. Если лог нужен 30 дней для разбора инцидентов, не храните его полгода "на всякий случай". Лучше сразу зафиксировать состав логов, срок хранения и право доступа в одной схеме, чтобы у саппорта, аналитиков и разработки не было разных версий правил.
Пример из работы саппорта
Представьте обычный спорный кейс. Клиент пишет в поддержку и спрашивает, почему модель отказала в возврате товара. Если доступы настроены плохо, саппорт открывает полный лог запроса и видит лишнее: адрес, историю прошлых обращений, заметки менеджера, иногда и куски профиля клиента. Для такой задачи это не нужно.
Саппорту хватает короткой карточки инцидента. В ней есть номер заказа, итоговый ответ модели, код причины отказа и время запроса. Этого достаточно, чтобы объяснить клиенту, что система опиралась, например, на правило "срок возврата истек" или "товар входит в список исключений". Полный текст промпта и все подставленные поля саппорт не открывает.
Если случай нужно проверить глубже, подключается аналитик. Он получает уже обезличенный пример: категорию товара, тип причины отказа, версию шаблона, модель, результат и несколько технических меток. Вместо имени клиента - идентификатор, вместо точной даты покупки - интервал. Этого хватает, чтобы понять, где ошибка: в логике маршрута, в формулировке шаблона или в самих бизнес-правилах.
Разработчик смотрит на другой слой. Ему нужен шаблон промпта, его версия и список переменных, которые участвовали в запросе. Но значения чувствительных полей он видит не целиком. Вместо полного профиля клиента система показывает маскированные данные или заглушки вроде <city>, <days_since_purchase>, <return_reason>. Так разработчик понимает, какой текст реально ушел в модель, и не получает лишний доступ к персональным данным.
На практике процесс выглядит просто: саппорт отвечает клиенту по карточке инцидента, аналитик разбирает обезличенный пример и ищет повторяющиеся сбои, разработчик правит шаблон или правило на уровне версии, а руководитель команды или ИБ смотрит аудит действий и видит, кто что открывал.
Хороший признак тут один: ни один участник не просит "скиньте весь лог целиком". Каждый видит только тот слой данных, без которого он не сделает свою часть работы.
Ошибки, которые встречаются чаще всего
Самая частая ошибка скучная, но опасная: один общий логин на всю команду. Сначала это кажется удобным. Не нужно заводить роли, раздавать права и разбираться, кто что видит. Потом никто уже не может понять, кто открыл лог с персональными данными, кто скачал экспорт и кто поменял шаблон.
Вторая ошибка - хранить полные диалоги как есть. В лог попадает текст пользователя, номера заказов, телефоны, почта и внутренние комментарии оператора. Через месяц такой лог превращается в архив лишних данных, который начинают читать люди, которым это совсем не нужно.
Третья ошибка появляется на тестовом стенде. Команда копирует рабочие данные, чтобы быстрее проверить сценарии. Потом тестовый контур живет дольше, чем планировалось, и доступ к нему оказывается шире, чем к продакшну. В итоге чувствительные данные оказываются там, где их вообще не должны были хранить.
Еще одна проблема - постоянные временные исключения. Кому-то выдают расширенный доступ "на пару дней", потом забывают его закрыть. Через несколько месяцев таких исключений становится так много, что ролевая модель существует только на бумаге.
Короткий чек-лист перед запуском
Перед релизом проверьте не только качество ответа модели, но и то, кто именно видит промпт, переменные и логи. Ошибки тут обычно тихие: система работает, а лишний доступ уже открыт.
- У разработчиков, аналитиков и саппорта должен быть разный набор прав.
- Шаблоны нужно хранить отдельно от переменных.
- Логи стоит писать с отбором полей, а не целиком.
- Аудит должен показывать, кто менял шаблон и кто открывал чувствительные данные.
- Временный расширенный доступ лучше выдавать по заявке и на короткий срок.
Проверьте это на одном реальном сценарии. Допустим, клиент пожаловался на неверный ответ модели. Саппорт должен увидеть номер запроса, версию шаблона, код ошибки и маскированные данные. Разработчик - шаблон и технические детали. Аналитик - общую картину без персональных полей. Если кто-то видит больше, чем нужно для своей задачи, доступ стоит урезать.
Что сделать дальше
Начните с одного процесса, где утечка принесет самый заметный ущерб. Чаще всего это саппорт, антифрод, разбор обращений или внутренний помощник, который видит ФИО, телефоны, номера договоров и историю клиента. На таком участке быстро видно, где у вас смешаны шаблоны, переменные и логи.
Не пытайтесь сразу переписать всю схему доступа. Сначала выберите один поток запросов и зафиксируйте, кто что видит на каждом шаге. Разработчику обычно нужен шаблон и тестовые данные. Аналитику чаще хватает обезличенных примеров и итоговых метрик. Саппорту нужен ответ по кейсу клиента, но не полный лог чужих запросов.
Полезно оформить это в короткий регламент на 1-2 страницы. Без сложных формулировок. Достаточно описать роли, права, срок хранения данных и порядок выдачи временного доступа.
Отдельно проверьте сам LLM-шлюз. Если он хранит логи за пределами РФ, не умеет маскировать PII или не пишет аудит по запросам, проблема останется даже при хорошей ролевой модели. Для российских команд это обычно базовое требование.
Если вам нужен OpenAI-совместимый шлюз с хранением логов и бэкапов в РФ, встроенным маскированием PII и аудитом запросов, можно посмотреть RU LLM на rullm.com. У сервиса единый OpenAI-совместимый эндпоинт, поэтому команды часто меняют только base_url на api.rullm.com и продолжают работать со своими SDK, кодом и промптами без переделки.
Закройте эту работу простым действием: назначьте владельца схемы доступа и дату первой ревизии. Через две недели проверьте один живой кейс вручную - кто увидел шаблон, кто получил переменные, что попало в лог и можно ли это объяснить на внутреннем аудите.