Ручная проверка ответов ИИ: где нужна и как эскалировать
Разберём, когда ручная проверка ответов ИИ снижает риск, как задать пороги эскалации и не превратить проверку в бесконечную очередь.
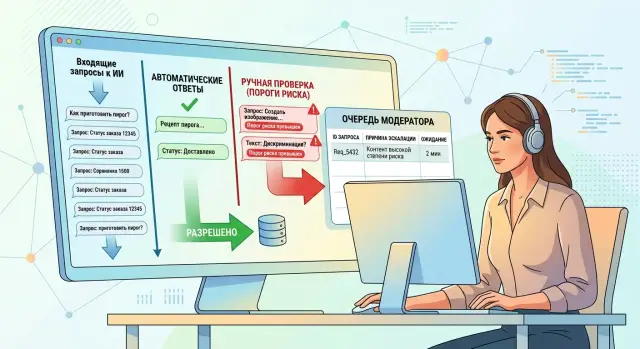
Почему ИИ не должен решать один
Модель может писать уверенно даже тогда, когда не знает ответ до конца. Для пользователя это выглядит как точный совет. Внутри системы в этот момент может быть слабый контекст, низкая уверенность или конфликт между источниками. Пользователь этого не видит.
Поэтому ручная проверка ответов ИИ нужна не там, где текст звучит неловко, а там, где ошибка меняет решение человека. Если бот перепутал формулировку в черновике письма, это неприятно. Если он неверно объяснил условия кредита, подсказал неправильный порядок действий при блокировке счета или отправил клиента не в тот процесс, последствия уже другие. Ошибка в тексте раздражает. Ошибка в действии стоит денег.
Есть и другая проблема: ИИ не показывает ваш внутренний порог сомнения. Команда может настроить фильтры, ретривал и оценки качества, но клиент видит только готовый ответ. Он не знает, что модель собрала его по неполным данным или выбрала самый похожий документ вместо правильного. Когда такой ответ касается платежа, персональных данных, договора или жалобы, оставлять последнее слово только машине рискованно.
Один неверный ответ легко запускает цепочку проблем. Клиент действует по подсказке, получает убыток, пишет претензию, а дальше подключаются юристы, поддержка и комплаенс. В банке или телекоме этого уже достаточно, чтобы команда потратила часы на разбор одного случая. В госсервисе или медицине цена ошибки еще выше.
Правило простое: чем ближе ответ к деньгам, правам пользователя, персональным данным или необратимому действию, тем нужнее человек в контуре ИИ. Не потому, что модель всегда ошибается. Потому что редкая ошибка в таких сценариях бьет сильнее, чем сто точных ответов помогают.
Из-за этого систему не стоит оценивать только по средней точности. Для рабочей схемы важнее другое: где один промах уже нельзя считать случайностью. Именно там человек должен подтверждать ответ, исправлять его или забирать диалог на себя.
Где ручная проверка действительно снижает риск
Ручная проверка нужна там, где ошибка что-то меняет для клиента, денег или доступа. Если бот перепутал формулировку в общем FAQ, это терпимо. Если он сам изменил статус заявки, лимит, тариф или права пользователя, риск уже совсем другой.
Чем труднее откатить решение, тем чаще нужен человек. Особенно это касается операций, после которых клиент теряет доступ, получает отказ, платит больше или подписывает текст с юридическим смыслом.
Отдельная зона риска - персональные данные и договорные тексты. Когда модель читает паспортные данные, реквизиты, медицинские сведения или проект договора, ошибка становится не только сервисной, но и регуляторной. Для российских команд это сразу связано и с 152-ФЗ: мало просто получить ответ, нужно понимать, кто его видел, что попало в лог и можно ли потом объяснить решение на аудите.
Без проверки лучше не выпускать ответы в нескольких типах сценариев:
- советы по деньгам, праву, медицине или безопасности;
- ответы, которые влияют на одобрение, отказ, лимит, тариф или уровень доступа;
- работа с договором, претензией, заявлением и другими текстами, где важна точная формулировка;
- случаи, где система сама показывает низкую уверенность, а ошибка стоит дорого;
- новые сценарии, по которым у команды еще нет нормальной статистики.
Низкая уверенность сама по себе не катастрофа. Проблема начинается, когда она совпадает с высокой ценой ошибки. Если бот сомневается в ответе про часы работы офиса, можно показать осторожный автоответ. Если он не уверен, можно ли повысить лимит или принять спорный документ, человека лучше подключать сразу.
Новые сценарии почти всегда требуют ручного фильтра на старте. Даже сильная модель ведет себя неровно, пока вы не собрали реальные примеры, не увидели частые промахи и не поняли, какие запросы ломают логику. Сначала очередь будет длиннее, зато потом вы снимете проверку там, где риск и правда низкий.
Если говорить совсем прямо, человеку стоит оставлять последнее слово в двух случаях: когда ответ меняет чье-то положение и когда ошибку потом трудно объяснить или исправить. Во всех остальных местах автоматика обычно работает быстрее и дешевле.
Что оставить автоматике, а что отдать человеку
Автоматика хорошо работает там, где ошибка обходится дешево и ее легко откатить. Если запрос типовой, ответ строится по понятным правилам, а пользователь не теряет деньги, доступ или статус заявки, модель можно пускать без ручного шага. Иначе ручная проверка ответов ИИ быстро превращается в узкое место.
Ориентир тот же: чем выше цена ошибки, тем ближе должен быть человек. Если ответ влияет на платеж, договор, персональные данные, лимит, отказ в услуге или юридически значимое сообщение, финальное решение лучше не отдавать модели.
Что можно оставить автоматике
Модели лучше поручать подготовительную работу. Она быстро собирает факты из базы знаний, находит нужный регламент, пишет черновик ответа, заполняет поля карточки и предлагает следующий шаг.
Обычно без ручного шага проходят частые вопросы с понятным шаблоном ответа, статусы заказов и заявок, пересказ внутренних инструкций без новых выводов, классификация обращений по теме и приоритету, а также черновики писем и подсказки оператору.
Но даже здесь лучше разделять черновик и действие. Пусть модель готовит текст или рекомендацию, а отправку клиенту, изменение лимита, блокировку операции или запись в официальный контур запускает правило или сотрудник. Это сильно снижает риск.
Что лучше отдать человеку
Редкие и спорные случаи почти всегда ломают простые схемы. Если в запросе не хватает данных, правила противоречат друг другу или клиент пишет не по шаблону, автоматика начинает звучать уверенно именно там, где уверенности нет.
Проверка человеком нужна, когда есть хотя бы один из этих признаков:
- запрос встречается редко и для него мало примеров;
- ошибка дорого обходится бизнесу или клиенту;
- ответ затрагивает 152-ФЗ, PII, жалобу или претензию;
- системе нужно не объяснить, а принять решение;
- модель нашла факты, но не может выбрать безопасный вариант.
На практике лучше всего работает простая схема: модель собирает факты и пишет аккуратный черновик, правила проверяют ограничения, а человек подтверждает спорный финал. Например, в банке ИИ может собрать историю обращения и предложить текст ответа, но решение по возврату комиссии или разблокировке операции принимает сотрудник по регламенту.
Если у вас уже есть OpenAI-совместимый стек, такой контур удобно строить поверх шлюза вроде RU LLM. Команда может оставить свои SDK, код и промпты без изменений, а слой правил и ручной проверки встроить в существующий процесс.
Как собрать схему эскалации
Схему эскалации лучше строить не от модели, а от действий, которые она запускает. Если ошибка может списать деньги, сорвать срок ответа клиенту или открыть лишние данные, такое действие сразу попадает в отдельную группу риска. Так ручная проверка ответов ИИ будет привязана к реальному ущербу, а не к общему недоверию к модели.
Сначала выпишите не типы запросов, а именно действия: поменять тариф, вернуть платеж, отправить документ, раскрыть статус заказа, показать персональные данные, передать заявку человеку. Один и тот же вопрос клиента может вести к разным последствиям. Проверять нужно не "текст про оплату", а "действие меняет деньги" и "ответ содержит чувствительные данные".
Дальше дайте каждому действию свой порог риска. Удобно считать его по двум вещам: цене ошибки и обратимости. Если ответ легко исправить, порог можно поднять. Если ошибка оставляет след в биллинге, договоре или истории доступа, порог должен быть ниже.
Обычно хватает трех исходов:
- низкий риск - автоответ без участия человека;
- средний риск - ручная проверка перед отправкой;
- высокий риск - отказ с коротким объяснением и новый запрос через безопасный канал.
Не стоит плодить пять или шесть веток. Чем проще правило, тем меньше спорных случаев и тем легче держать очередь под контролем.
Правила очереди
У каждой задачи должен быть срок жизни. Если проверка не началась за 10-15 минут, задача не должна висеть до вечера. Бот может вернуть безопасный ответ: принять обращение, попросить подтвердить данные еще раз или перевести разговор в канал с оператором по расписанию. Иначе очередь ручной проверки быстро превращается в склад старых кейсов.
После проверки нужен короткий путь назад. Проверяющий выбирает одно из трех действий: одобрить, поправить или отклонить. Потом бот отправляет финальный ответ и сохраняет причину решения. Эта метка потом помогает учить правила: что действительно нужно отдавать человеку, а что можно вернуть в автоматический поток.
Если команда работает через RU LLM, причину эскалации можно хранить рядом с аудит-трейлом запроса и метками AI-Law. Это упрощает разбор спорных случаев и избавляет от отдельного ручного журнала.
Как не завалить очередь
Очередь растет не потому, что ИИ всегда ошибается. Чаще команда сама отправляет на ручную проверку слишком много обычных случаев. Если человек смотрит все подряд, проверка быстро становится узким местом.
Ручная проверка работает хорошо только тогда, когда в нее попадает верхний слой риска. Это платежи, персональные данные, спорные отказы, обещания по срокам, нестандартные условия договора. Простые вопросы вроде статуса заявки или правил доставки лучше оставлять автоматике, если модель уже стабильно проходит такие сценарии.
Режьте диалог на задачи
Длинный чат почти всегда выглядит страшнее, чем есть на самом деле. Но оператору не нужен весь разговор на десять экранов, если внутри всего две понятные задачи: смена адреса и возврат денег.
Полезнее сначала разложить диалог по типам задач, а потом решать, что именно эскалировать. Тогда одна ветка уйдет человеку, а остальное закроется автоматически. Это заметно сокращает очередь.
Оператору лучше показывать не сырой лог, а короткий пакет:
- последний запрос пользователя;
- сжатую сводку контекста;
- черновик ответа от модели;
- причину эскалации;
- уровень риска или правило, которое сработало.
Тогда человек тратит не пять минут на чтение переписки, а 30-60 секунд на решение.
Повторы тоже раздувают очередь. Один и тот же клиент может отправить три сообщения подряд с одной и той же проблемой, а система создаст три проверки. Лучше склеивать такие обращения по пользователю, теме и короткому окну времени. Если вопрос уже ушел оператору, повтор не должен открывать новую задачу.
Смотрите на долю эскалаций каждый день
Общая цифра мало что говорит. Нужна доля эскалаций по каждому сценарию: возвраты, жалобы, изменение персональных данных, спор по тарифу, запрос на удаление данных. Если один тип внезапно вырос с 8% до 22%, причина обычно очень приземленная: сломалась классификация, изменился шаблон ответа или модель стала хуже понимать формулировки пользователей.
Если вы работаете через RU LLM, удобно писать в лог причину эскалации и тег сценария на каждый запрос. Потом проще увидеть, где очередь растет из-за реального риска, а где из-за плохого правила.
Нормальная цель проста: человек смотрит мало, но смотрит именно то, где его решение действительно меняет исход.
Пример: поддержка банка без лишней ручной работы
Запросы в поддержку банка удобно делить по простому правилу: объяснение может дать ИИ, изменение статуса карты делает только сотрудник. Это и есть рабочая ручная проверка ответов ИИ: человек смотрит не все подряд, а только те обращения, где ошибка может повлиять на деньги, доступ к счету или безопасность.
Клиент пишет: "Я вернулся из поездки, карта не проходит. Как снять блокировку?" В таком виде это обычный вопрос. ИИ может сам объяснить, почему банк иногда ставит ограничение после поездки, какие документы могут понадобиться, сколько обычно длится проверка и через какой канал ее лучше пройти. Для клиента это быстро. Для поддержки это значит, что простые вопросы не занимают очередь.
Сценарий меняется, когда в сообщении появляется просьба что-то сделать: "Снимите блокировку сейчас" или "Измените статус карты". Если клиент еще и вставил номер карты, запрос сразу получает высокий приоритет. Тут уже мало дать совет. Нужны проверка личности, просмотр антифрод-меток и решение сотрудника.
Как это выглядит в работе
Система может вести такой запрос по короткой схеме:
- ИИ определяет, это вопрос или просьба выполнить действие;
- если это вопрос без операции по счету, ИИ отвечает сам;
- если клиент просит изменить статус карты, запрос уходит оператору;
- если в тексте есть номер карты или другие персональные данные, система поднимает приоритет и маскирует чувствительные фрагменты.
Если банк использует шлюз с маскированием PII, модель не видит номер карты целиком. Это снижает риск утечки и не мешает маршрутизации.
Оператору не нужно писать ответ с нуля. Он получает готовый черновик: краткую суть обращения, причину эскалации и вариант ответа клиенту. Например, просьбу пройти идентификацию, уточнить дату последней поездки и перейти в безопасный канал. На такое решение сотрудник часто тратит 20-30 секунд, а не несколько минут.
При такой схеме ИИ закрывает рутину, а человек принимает решение там, где ошибка дорого стоит. Очередь не раздувается, потому что в нее попадают не все обращения, а только те, где банк действительно берет ответственность на себя.
Ошибки, из-за которых очередь растет
Очередь ручной проверки чаще ломается не из-за плохой модели, а из-за плохих правил. Система шлет слишком много задач людям, операторы тратят время на лишнее, а действительно рискованные случаи ждут дольше всех.
Самая частая ошибка - один и тот же порог риска для всех сценариев. Это почти всегда дает перекос. Для ответа про график работы нужен один уровень строгости, для расчета штрафа, отказа в выплате или ответа по персональным данным - другой. Если порог общий, безопасные запросы попадают в очередь вместе со спорными. Очередь растет, а пользы мало.
Не менее вредная привычка - отправлять на проверку весь чат, когда сомнение вызвал один шаг. Оператору приходится читать десять сообщений вместо одного фрагмента, который действительно влияет на риск. В поддержке банка это особенно заметно: спорный абзац про комиссию легко тонет в длинной переписке про смену пароля и статус заявки. Проверять нужно конкретный ответ, а не весь диалог целиком, если контекст уже сохранен в карточке.
Еще одна причина роста очереди - слишком длинная форма для оператора. Если человек должен вручную проставить десять полей, выбрать три кода причины и написать комментарий на полстраницы, каждая задача живет в системе лишние минуты. Форма должна отвечать на один вопрос: можно выпускать ответ, нужно править или нужно передать дальше.
Без дедлайна очередь быстро превращается в склад старых задач. Обычно работает простой порядок:
- срочные задачи получают жесткий срок и отдельный канал;
- обычные живут в очереди ограниченное время;
- просроченные ответы система отзывает, упрощает или отправляет на повторную генерацию.
Есть и тихая проблема: команда не разбирает, почему запросы вообще уходят на ручную проверку. Если каждую неделю в очередь летят одни и те же случаи, дело часто не в пользователях, а в промпте, классификаторе риска или слишком широком наборе триггеров. Если у вас есть аудит-трейлы и метки причин, их стоит смотреть не для отчета, а для чистки правил.
Хороший признак здоровой системы простой: объем очереди падает после разбора причин, а не после найма новых операторов. Если очередь держится только на росте команды, схему уже пора переделывать.
Короткий список проверок перед запуском
Перед запуском ручная проверка ответов ИИ должна опираться на ясные правила, а не на общее недоверие к модели. Если правило нельзя объяснить оператору в одной фразе, оно почти всегда слишком широкое и быстро раздует очередь.
Сначала составьте короткий список действий, где последнее решение принимает человек. Обычно сюда попадают финансовые условия, отказ клиенту, работа с персональными данными, юридически значимые сообщения и любые ответы, после которых уже нельзя просто извиниться и откатить действие.
Для каждого сценария задайте порог риска и назначьте одного владельца. Порог можно привязать к сумме операции, типу клиента, теме запроса, уровню уверенности модели или наличию персональных данных. Владелец должен быть один, без размытой общей ответственности.
Покажите оператору причину эскалации в явном виде. Ему нужен не сырой лог на десятки строк, а короткая метка: "низкая уверенность", "запрос на возврат выше лимита", "обнаружены персональные данные", "ответ влияет на тариф". Тогда человек тратит время на решение, а не на расшифровку системы.
С первого дня измеряйте долю эскалаций, среднее время ответа и цену ошибки. Эти три числа быстро показывают, где схема работает, а где вы отправляете человеку слишком много безопасных случаев или, наоборот, пропускаете рискованные.
И еще нужен аварийный режим. Команда должна уметь за несколько минут выключить автоответ только в проблемном сценарии, не ломая весь канал. Это особенно полезно в поддержке банка, страховой или любого сервиса с персональными данными.
В российских командах обычно добавляют еще одно правило: причина эскалации должна сохраняться рядом с аудитом запроса. Если вы работаете в контуре 152-ФЗ, это заметно упрощает разбор спорных случаев и избавляет от споров по памяти.
Хороший запуск выглядит довольно скучно. В очередь попадает немного запросов, оператор сразу понимает, почему система позвала его, а команда видит, какой порог нужно поправить первым.
Что сделать дальше
Выберите один процесс, где цена ошибки видна сразу в деньгах, риске или жалобах. Не берите весь контур поддержки или весь документооборот разом. Лучше начать с узкого места: ответа по спорной операции, изменения условий заявки или сообщения с персональными данными.
Потом дайте автоматике поработать две недели и не подкручивайте ее каждый день. Смотрите не только на долю автоответов, но и на то, что люди потом исправляли вручную. Если редактор чаще меняет тон или формулировки, а смысл остается тем же, ручная проверка в этом месте не нужна. Если человек регулярно правит суммы, статус, юридический смысл или убирает лишние данные клиента, именно там контроль действительно меняет исход.
Полезно собрать простой набор метрик:
- сколько ответов ушло без человека;
- сколько случаев дошло до ручной проверки;
- в каком проценте случаев человек менял смысл ответа;
- сколько времени заняла проверка;
- сколько опасных ошибок прошло бы без эскалации.
После этого сократите очередь без жалости. Ручная проверка ответов ИИ нужна не там, где просто страшно, а там, где человек реально снижает риск. Если команда почти всегда нажимает "одобрить" без правок, этот тип запросов стоит вернуть в автоматический режим. Если правки редкие, но последствия у ошибки дорогие, оставьте эскалацию только для них.
Для команд в РФ лучше сразу решить, где лежат логи, кто видит промпты, как маскируются персональные данные и как вы потом покажете историю решения на аудите. Это не стоит откладывать. Когда поток вырастет, перенос журналов и правил доступа обычно болезненнее, чем сама настройка модели. Отдельно зафиксируйте сроки хранения, роли доступа и способ помечать запросы, которые подпадают под внутренние правила или 152-ФЗ.
Если нужен единый слой для маршрутизации моделей и журналирования внутри РФ, можно использовать RU LLM. У сервиса OpenAI-совместимый эндпоинт: команда меняет base_url на api.rullm.com и продолжает работать со своими SDK, кодом и промптами, а логи, бэкапы, аудит-трейлы и маскирование PII остаются в российском контуре. Это удобно, когда вы тестируете эскалацию запросов ИИ сразу на нескольких моделях и не хотите собирать отдельную обвязку для каждой.
Нормальный первый шаг на этой неделе такой: выберите один сценарий, включите логирование, назначьте 2-3 причины эскалации и через 14 дней удалите все правила, которые не дали пользы.
Часто задаваемые вопросы
В каких случаях ИИ нельзя оставлять последнее слово?
Человека стоит подключать там, где ответ влияет на деньги, права пользователя, доступ, персональные данные или другое действие, которое трудно откатить. Если ошибка меняет чье то положение, лучше не оставлять финал только модели.
Что можно смело оставить автоматике?
Да, если ошибка обходится дешево и ее легко исправить. Обычно без ручного шага проходят типовые FAQ, статусы заявок, пересказ регламентов без новых выводов и черновики ответов для оператора.
Что делать, если модель не уверена в ответе?
Сначала смотрите на цену ошибки. Если модель сомневается в безобидном вопросе, можно дать осторожный ответ или попросить уточнение. Если сомнение касается лимита, возврата, договора или чувствительных данных, диалог лучше сразу передать сотруднику.
Как быстро выделить рискованные сценарии?
Опирайтесь не на тему вопроса, а на действие после ответа. Отдельно пометьте все, что меняет тариф, статус, доступ, платеж, договор или раскрывает данные. Потом задайте простой порог: сколько стоит ошибка и можно ли ее быстро исправить.
Сколько уровней эскалации делать?
Обычно хватает трех веток. Низкий риск уходит в автоответ, средний идет на проверку перед отправкой, высокий получает отказ или перевод в безопасный канал. Если веток больше, команда начинает путаться и очередь растет.
Как не завалить очередь ручной проверки?
Не отправляйте человеку все подряд. Режьте длинный чат на отдельные задачи, показывайте оператору только последний запрос, короткую сводку, черновик ответа и причину эскалации. Повторы одного и того же обращения лучше склеивать в одну проверку.
Нужно ли оператору читать весь диалог целиком?
Нет, обычно это лишняя работа. Если риск вызвал один шаг, оператору нужен именно этот фрагмент и короткий контекст, а не вся переписка. Так сотрудник решает быстрее и реже пропускает важное.
Какие метрики покажут, что схема работает?
Смотрите на долю эскалаций по сценарию, среднее время проверки, долю случаев, где человек меняет смысл ответа, и число опасных промахов без эскалации. Эти метрики быстро показывают, где правило помогает, а где только грузит очередь.
Что важно учесть при работе с персональными данными?
Сразу маскируйте чувствительные фрагменты, ограничивайте доступ к логам и сохраняйте причину эскалации рядом с аудитом запроса. Для команд в РФ это упрощает разбор спорных случаев и помогает держать процесс в контуре 152 ФЗ.
Когда ручную проверку уже можно убрать?
Снимайте проверку там, где сотрудник почти всегда жмет одобрение без смысловых правок и где ошибка не бьет по деньгам, правам или данным. Проверьте это на живой статистике за пару недель, а не по одному удачному дню.