DLP перед вызовом модели: как отрезать чувствительные данные
DLP перед вызовом модели помогает убрать паспортные данные, номера карт и мединформацию до отправки в LLM. Разберем схему фильтров и проверки.
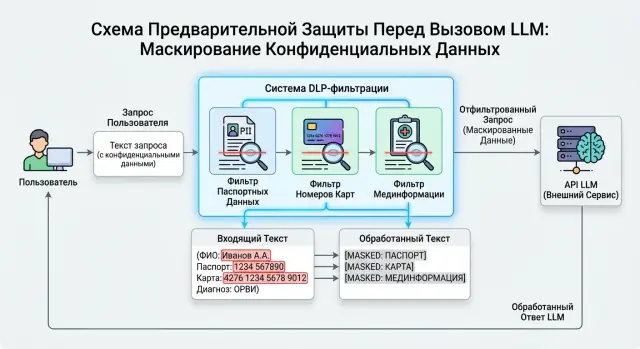
Почему фильтр нужен до API-вызова
Одна политика доступа не решает проблему, если сотрудник уже работает в разрешенном интерфейсе и сам вставляет в промпт лишнее. У него может быть полный доступ к чату, базе заявок и CRM, но это не значит, что паспорт, номер карты или результаты анализов можно отправлять в модель без проверки.
Обычно проблема не в злом умысле, а в привычке копировать все подряд. Оператор поддержки берет обращение клиента, вставляет историю переписки целиком, и вместе с ней в запрос уходят серия и номер паспорта, адрес, кусок банковской выписки или текст из медицинского документа после OCR. Такое случается чаще, чем кажется.
Если фильтра нет, прямой вызов модели делает утечку дешевой и быстрой. Данные покидают исходную систему еще до того, как кто-то успеет спросить, нужны ли они модели вообще. Потом они оседают в логах приложения, трассировке, отладочных дампах, очередях, кешах и у внешнего провайдера, если запрос выходит за пределы вашего контура.
Даже если команда работает через шлюз и держит обработку внутри российского контура, лишние данные все равно лучше отрезать заранее. Это уменьшает объем чувствительной информации в запросах, упрощает аудит и снижает шанс, что в журнал попадет то, чего там быть не должно.
Что ломается без предварительной проверки
Проблему редко замечают в момент отправки. Обычно все начинается позже: кто-то находит паспорт в логах, безопасники видят номера карт в промптах, а затем юристы или внутренний аудит спрашивают, зачем модель вообще получила мединформацию, если задача была простой - сделать короткое резюме обращения.
У прямого API-вызова без фильтра есть еще одна неприятная особенность. Модель не отличает нужный контекст от лишних персональных данных. Она обработает все, что ей дали. В итоге появляются сразу три риска: можно нарушить правила работы с ПДн, оставить больше следов в логах и системах наблюдения, а еще увеличить цену ошибки, потому что инцидент затронет не один сервис, а всю цепочку запроса.
Фильтр перед вызовом модели закрывает эту дыру на входе. Он не заменяет права доступа, журналирование и обучение сотрудников, но хорошо ловит самый частый сценарий утечки: обычную вставку текста без разбора.
Какие данные нужно ловить в первую очередь
DLP перед вызовом модели должен искать не "секретные" слова, а фрагменты, по которым можно узнать человека, его финансовое состояние или здоровье. На практике это не один тип данных, а несколько слоев: прямые идентификаторы, платежные реквизиты, медданные и обычные поля, которые по отдельности выглядят безобидно, а вместе раскрывают личность.
Паспортные данные лучше ставить в верхний приоритет. Серия и номер часто попадают в промпт целиком, особенно когда сотрудник копирует текст из анкеты, письма или CRM. Ловить нужно не только чистый шаблон из цифр, но и варианты с пробелами, дефисами, переносами строк и ошибками после OCR. Если рядом есть дата выдачи, код подразделения или фраза "кем выдан", риск выше.
С карточными данными нужна аккуратность. Номер карты можно найти по длине и контрольной сумме, но этого мало: похожие строки встречаются в заказах, треках и внутренних ID. Поэтому фильтр должен смотреть на контекст рядом - слова "карта", "оплата", "CVV", "срок", "держатель". Если строка похожа на PAN и рядом есть такие маркеры, ее лучше скрывать сразу.
Мединформация часто уходит в модель почти незаметно. Жалоба вроде "болит грудь третью неделю", диагноз, результат анализа, назначение препарата или текст врачебной выписки - это уже чувствительные данные. Даже короткая фраза "назначили инсулин" говорит о человеке больше, чем кажется. Для таких случаев одних словарей мало. Фильтр должен понимать медицинский контекст, а не просто искать названия болезней.
Телефон, адрес, дата рождения, email и ФИО по отдельности не всегда выглядят опасно. Но в связке они почти всегда позволяют понять, о ком идет речь. Фраза "Позвоните Марии, 8 9ХХ..., живет на Лесной, дом 14, подъезд 2" выглядит как обычный текст, хотя по смыслу это уже персональные данные.
Контекст вообще меняет оценку даже для нейтральных слов. Набор "Иван Петров, 12.04.1987, жалуется на давление" чувствительнее, чем каждое поле по отдельности. То же самое с фразами из поддержки: "клиент прислал фото паспорта" или "вставляю номер карты для проверки платежа". Если вы используете RU LLM, где уже есть маскирование PII и аудит-трейлы, правила все равно стоит настроить заранее. Сначала нужно определить, что именно считается риском, и только потом отправлять текст в модель.
Где поставить фильтр в цепочке запроса
Проверку лучше ставить в точке, где приложение уже собрало промпт, но еще не отправило его в модель. В этот момент виден весь реальный запрос: служебные инструкции, текст пользователя и данные, которые добавил ваш код. Если ловить чувствительные данные позже, часть текста уже уйдет за пределы системы.
Обычно используют два варианта. Первый - отдельный сервис фильтрации перед LLM-шлюзом. Второй - middleware внутри API или backend, который собирает запрос. Отдельный сервис проще обновлять и тестировать. Middleware быстрее внедрить, если трафик пока небольшой и схема не слишком сложная.
Даже если команда работает через единый OpenAI-совместимый шлюз, фильтр лучше держать до внешнего вызова. Шлюз решает маршрутизацию и доступ к моделям, а DLP должен останавливать лишние данные еще на вашем периметре.
Проверяйте весь пакет сообщения
Частая ошибка - смотреть только на user message и пропускать остальное. Но паспортные данные, номер карты или диагноз могут попасть в запрос из самых разных мест: system message, история чата, tool message, результаты функций, комментарии оператора и сырой JSON в metadata.
Иногда самый рискованный фрагмент приходит не от пользователя, а из внутреннего инструмента. Например, CRM вернула полную карточку клиента, а бот без сокращения добавил ее в контекст. Формально пользователь этого не писал, но в модель эти данные все равно уходят.
Вложение тоже становится текстом
Файл нельзя считать безопасным только потому, что он не текстовый. Фото паспорта, скан анкеты, выписка из клиники и PDF с реквизитами после OCR превращаются в обычный текст и дальше едут в промпт. Поэтому фильтр нужен и до OCR, и после него.
Рабочая цепочка обычно выглядит так: файл загружают, проверяют тип и источник, прогоняют OCR, получают текст, снова проверяют его правилами и только потом решают, что делать дальше. Если правило сработало, система либо маскирует фрагмент, либо останавливает запрос и просит убрать лишние данные.
Полезный минимум - два слоя проверки. Первый смотрит на сырой ввод, второй анализирует уже собранный prompt. Это спасает от ситуации, когда безопасные по отдельности куски вместе дают полный номер паспорта, карты или медицинскую историю.
Как проходит проверка шаг за шагом
Проверка лучше всего работает как короткий конвейер перед отправкой текста в модель. Цель простая: не дать сырому запросу с паспортом, номером карты или диагнозом уйти во внешний API, если это можно остановить заранее.
Сначала система принимает запрос и присваивает ему внутренний ID. По нему потом удобно собрать весь путь запроса: кто отправил текст, какое правило сработало и ушел ли запрос в модель.
Дальше фильтр прогоняет текст по наборам правил. Сначала идут дешевые проверки по шаблонам: серия и номер паспорта, номера карт, СНИЛС, полис, типовые маркеры мединформации. Потом можно подключить словари и простую проверку контекста, чтобы отличать, например, номер договора от номера карты.
Если система находит чувствительный фрагмент, у нее обычно два варианта. Первый - маскирование. Так строка "4111 1111 1111 1111" превращается в "[CARD_MASKED]". Второй - полная блокировка запроса. Ее лучше включать для полных паспортных данных, выписок и текстов, где смешаны сразу несколько типов ПДн.
После срабатывания правила в журнал стоит писать не исходный текст, а причину: какой класс данных найден, какое правило сработало и что система сделала дальше. Это полезно и для разбора ложных срабатываний, и для аудита. Если запросы идут через RU LLM, такой след удобно держать рядом с идентификатором запроса и остальными записями по маршруту обработки.
Только после этого в модель должна уходить очищенная версия текста. Модель получает смысл запроса, но не видит лишнего. Например, вместо "Проверь обращение клиента Иванова, паспорт 4510..." она получает "Проверь обращение клиента [NAME_MASKED], паспорт [PASSPORT_MASKED]".
Вся цепочка обычно занимает доли секунды, если сначала поставить быстрые проверки, а более тяжелые включать только при подозрении. Это не ломает обычные сценарии поддержки, где ответ нужен быстро.
Пример из обычной поддержки
Клиент пишет в чат поддержки: карта не проходит оплату, нужен перевыпуск. Чтобы ускорить ответ, он сразу добавляет номер карты, серию и номер паспорта, а иногда еще и дату рождения. Для человека это выглядит логично. Для системы это уже лишние данные в промпте.
Оператор хочет сэкономить время и вставляет обращение в помощник, который готовит черновик ответа. Если отправить текст как есть, модель получит то, что ей не нужно для задачи. Полный номер карты не нужен, чтобы объяснить порядок перевыпуска. Паспорт тоже не нужен, чтобы составить вежливый и точный ответ.
Здесь и срабатывает DLP перед вызовом модели. Фильтр проверяет текст до API-запроса, находит шаблон карточного номера и паспортные реквизиты, а затем скрывает только чувствительные фрагменты. Остальная часть обращения остается нетронутой.
Например, исходный текст может выглядеть так:
"Не могу оплатить покупки. Перевыпустите карту 5489 4000 1234 5678. Паспорт 4510 123456. Подскажите, что делать дальше?"
После маскирования в модель уходит уже другой вариант:
"Не могу оплатить покупки. Перевыпустите карту [CARD_MASKED]. Паспорт [PASSPORT_MASKED]. Подскажите, что делать дальше?"
Смысл обращения не теряется. Помощник по-прежнему видит, что клиенту нужен перевыпуск карты и инструкция по следующим шагам. Этого обычно достаточно, чтобы подготовить нормальный ответ: объяснить порядок перевыпуска, перечислить, какие данные и документы запросит банк, и подсказать, где клиент увидит статус заявки.
Этот сценарий хорошо показывает простую вещь: модель должна получать задачу, а не весь сырой текст из поддержки. Чем меньше лишних персональных данных уходит в API, тем ниже риск утечки и тем проще жить с внутренними правилами и требованиями 152-ФЗ.
Для оператора почти ничего не меняется. Он работает в том же окне, копирует обращение и получает черновик ответа. Разница только в том, что номер карты и паспорт не покидают контур в открытом виде.
Что делать после срабатывания правила
После срабатывания фильтра нельзя отправлять запрос в модель как есть. Дальше система должна выбрать понятное действие в зависимости от того, можно ли убрать чувствительные данные без потери смысла.
Если данные не нужны для ответа, их лучше скрыть до вызова модели. Например, в обращении клиента можно заменить номер паспорта на метку вроде "[паспорт скрыт]" и оставить остальной текст. Оператор или бот все равно поймут суть проблемы, а лишние данные не уйдут во внешний контур.
Если очистка ломает смысл, запрос лучше остановить полностью. Так бывает, когда весь текст состоит из выписки, фото документа после OCR или подробного описания диагноза. В таком случае модель не должна видеть исходный текст вообще.
Когда правило не уверено, не стоит угадывать. Такой случай лучше передать человеку. Лишняя ручная проверка неприятна, но один пропущенный номер карты или фрагмент медкарты обойдется дороже.
Пользователю нужно показывать короткое и спокойное сообщение без лишних технических деталей. Подходят простые формулировки: "Мы скрыли часть личных данных и обработали ваш запрос" или "Мы не можем обработать это сообщение автоматически. Его посмотрит сотрудник". Человек должен понять, что произошло, без ощущения, что система его наказала.
Журнал тоже нужен не для формальности. В нем стоит хранить тип правила, время, канал, результат обработки и короткую причину вроде "обнаружен номер карты" или "найден фрагмент мединформации". В контуре с требованиями 152-ФЗ такой след помогает разбирать инциденты, отвечать на внутренние проверки и править слишком жесткие правила по фактам, а не по ощущениям.
Частые ошибки при внедрении
DLP перед вызовом модели чаще спотыкается не о сложные атаки, а о простые ошибки в интеграции. Команда ставит фильтр, видит несколько удачных срабатываний и считает задачу закрытой. Через неделю в модель уходит текст из CRM с паспортом или выписка врача из tool response.
Первая частая ошибка - проверять только user message. Чувствительные данные живут не только там. Их добавляют system prompt, история диалога, результаты tools, OCR из вложений и служебные поля, которые приложение склеивает перед отправкой. Пользователь может написать "помогите с заказом", а CRM подставит в контекст полные ФИО, дату рождения и серию паспорта.
Вторая ошибка - ловить только номера по regex. Такой подход находит карту или СНИЛС, но пропускает обычный текст врача: "пациент принимает инсулин", "жалобы после операции", "беременность 22 недели". Для медданных и части ПДн одного шаблона мало. Нужны словари, проверка контекста и отдельные правила для свободного текста.
Проблемы чаще всего прячутся в нескольких местах: в system prompt и скрытых полях запроса, в выводе tools и данных из CRM, в логах приложения, очередях и трассировке, в OCR-тексте из сканов и фото, а еще в тестовых наборах, где нет реальных документов и обращений.
Еще один промах - маскировать данные только перед отправкой в модель, но оставлять исходный текст в логах. Тогда фильтр почти теряет смысл. Разработчик не увидит паспорт в промпте, зато он останется в access log, в ошибке ретрая или в отладочной записи. Даже если шлюз умеет маскировать PII на своей стороне, приложение все равно должно чистить собственные логи до записи.
Слишком жесткие правила тоже мешают. Если фильтр режет любой 16-значный номер, он заденет номер заказа. Если блокирует любое упоминание симптомов, бот перестанет работать в страховании и медтехе. Обычно разумнее начать с трех действий: блокировать явные секреты, маскировать спорные фрагменты и отправлять часть случаев на ручную проверку.
Плохое тестирование ломает даже хороший набор правил. Проверять фильтр только на придуманных строках вроде "4111 1111 1111 1111" бесполезно. Нужны реальные шаблоны заявок, переписки поддержки, фрагменты анкет, сканы документов после OCR и обезличенные заметки операторов. На таких данных сразу видно, где фильтр молчит, а где мешает работе.
Быстрый чек-лист перед запуском
Перед первым запуском зафиксируйте словарь чувствительных данных. Для DLP перед вызовом модели мало одного правила на номер карты. Команда должна отдельно описать паспортные реквизиты, данные банковских карт, мединформацию, номера полисов, ФИО в связке с датой рождения, адреса и другие поля, которые нельзя отправлять в модель как есть.
Проверьте не только текст промпта. Люди часто вставляют CSV, PDF, скриншоты, письма из почты и заметки из CRM. Если правила смотрят только на строку input, утечка спокойно пройдет через вложение или через OCR, который распознал текст на скане паспорта.
До релиза стоит заранее решить, что делать с каждым типом данных. Карточные данные и паспорт почти всегда лучше блокировать или сокращать до безопасного шаблона. С мединформацией часто нужен другой режим: убрать имя, номер полиса, дату рождения и оставить только тот фрагмент, без которого модель не сможет помочь.
Отдельно проверьте логи. Они часто ломают всю схему защиты, даже если фильтр сработал правильно. В журнале должны остаться тип срабатывания, время, источник запроса и технический идентификатор, но не исходный кусок с номером карты, паспортом или диагнозом. Если вы отправляете запросы через RU LLM, принцип не меняется: очищайте данные и до исходящего вызова, и до внутреннего логирования.
Еще один обязательный шаг - тестовый набор. В нем нужны не только явные нарушения, но и похожие на них безопасные примеры, иначе команда утонет в ложных срабатываниях. Полезный минимум простой: явный номер карты, невинная последовательность из 16 цифр в заказе и замаскированный номер вроде 4111 **** **** 1111.
Если на этом этапе правила режут лишнее, не спешите расширять блокировку на все подряд. Сначала разберите, где именно фильтр ошибается: в регулярном выражении, в OCR, в контексте вокруг найденного фрагмента или в порядке проверок. Такой разбор экономит много времени после запуска и заметно снижает риск реальной утечки.
С чего начать команде
Начните не с полной карты всех рисков, а с узкого пилота. DLP перед вызовом модели чаще всего ломают не сложные правила, а попытка закрыть все случаи сразу. На старте обычно хватает трех типов данных, которые чаще всего попадают в промпты случайно и создают самый неприятный риск: паспортные данные, данные карты и мединформация.
Этого достаточно, чтобы проверить механику без лишнего шума. Если команда видит, что правила ловят явные случаи и не мешают обычной работе, дальше расширять покрытие уже проще.
Хороший пилот лучше запускать на одном канале. Например, только в чате поддержки, где операторы часто вставляют клиентские сообщения в LLM для черновика ответа. За одну-две недели вы соберете и ложные блокировки, и пропущенные случаи. Обе категории полезны: первая показывает, где правило слишком грубое, вторая - где шаблонов мало и нужны новые проверки.
Без аудита пилот быстро превращается в спор на уровне ощущений. Каждый блок должен оставлять понятный след: что сработало, какой фрагмент попал под правило, было ли маскирование или полный запрет, кто отправил запрос и в какой системе это произошло. Пользователю тоже нужна ясная причина. Фраза вроде "обнаружены паспортные данные" полезнее, чем сухая ошибка 400.
Если команде нужен единый LLM-эндпоинт в РФ, можно смотреть на схему, где маршрутизация запросов сочетается с маскированием PII и аудитом. У RU LLM это собрано в одном контуре, что удобно для команд, которым важно не разносить управление моделями и контроль персональных данных по разным слоям.
После пилота не раскатывайте правила на всю компанию за один день. Возьмите еще один-два сценария: внутренний copilot, разбор писем, помощник для продаж. Для каждого добавьте свои шаблоны и исключения. Через месяц у команды будет не набор догадок, а журнал реальных срабатываний и понятный список того, что блокировать, что маскировать, а что можно пропускать.
Часто задаваемые вопросы
Зачем ставить DLP до вызова модели, если доступ уже настроен?
Потому что права доступа не мешают сотруднику вставить в промпт лишнее. Если текст уйдет в модель без проверки, паспорт, карта или медданные попадут не только в API, но и в логи, трассировку и кеши. Проще остановить это на входе, чем потом чистить весь след запроса.
Какие данные нужно проверять в первую очередь?
Сначала ловите паспортные данные, номера карт и мединформацию. Сразу после них проверьте связки вроде ФИО, даты рождения, телефона, адреса и email, потому что вместе они тоже раскрывают личность.
Хватит ли одних регулярных выражений?
Нет, одних regex мало. Они хорошо находят паспорт по шаблону или номер карты, но плохо понимают обычный текст вроде жалоб, диагнозов или OCR с ошибками. Нужны и шаблоны, и словари, и проверка соседнего контекста.
Где лучше поставить фильтр в цепочке запроса?
Ставьте проверку там, где приложение уже собрало полный prompt, но еще не отправило его в модель. В этот момент видно все: инструкции, историю, данные из CRM и текст пользователя. Так вы режете лишнее до выхода за ваш контур.
Нужно ли проверять только user message?
Нет, этого мало. Чувствительные данные часто приезжают из system message, истории чата, tool response, metadata и внутренних полей, которые код добавляет сам. Проверяйте весь пакет сообщения целиком, иначе пропустите самый неприятный сценарий.
Нужно ли фильтровать файлы и OCR?
Да, потому что вложение быстро превращается в текст. Фото паспорта, PDF с реквизитами или выписка после OCR дальше едут в prompt как обычные строки. Проверяйте и сам файл, и текст после распознавания.
Когда лучше маскировать данные, а когда блокировать запрос?
Если модель может решить задачу без чувствительного фрагмента, лучше замаскировать его и пропустить запрос дальше. Когда весь смысл держится на документе, выписке или подробном диагнозе, безопаснее остановить запрос и отправить его на ручную проверку.
Как уменьшить число ложных срабатываний?
Начните с простого режима: явные секреты блокируйте, спорные случаи маскируйте, неуверенные отправляйте человеку. Потом прогоните правила на реальных обращениях, OCR и данных из CRM. Так вы быстро увидите, где фильтр режет лишнее, а где молчит.
Что сохранять в логах после срабатывания правила?
Не пишите в журнал исходный текст с паспортом, картой или диагнозом. Храните тип найденных данных, время, канал, ID запроса и действие системы. Этого хватает для разбора инцидента и настройки правил без лишнего риска.
С чего начать внедрение DLP перед вызовом модели?
Начните с узкого пилота на одном канале, например в чате поддержки. Возьмите три класса данных: паспорт, карта и мединформация. Если трафик идет через шлюз вроде RU LLM, это не отменяет локальную проверку перед отправкой и до записи логов.