Российский и внешний контур данных: рабочий шаблон
Российский и внешний контур данных: как развести доступ, логи, интеграции и LLM-запросы, чтобы команды работали без смешения и лишнего риска.
Где компании смешивают контуры по ошибке
Путаница обычно начинается задолго до выбора модели. Компания строит один маршрут для всех запросов, а разделение пытается добавить потом через роли и правила доступа. На схеме это выглядит аккуратно. В работе - быстро ломается. Один и тот же запрос проходит через общий шлюз, попадает в общий лог, сохраняется в общий кэш или бакет, и граница между контурами исчезает.
Самая частая ошибка - смотреть на пользователя, а не на маршрут данных. Если сотрудник находится за пределами России, это само по себе не делает запрос внешним. Контур задает путь данных: через какой шлюз идет запрос, где пишутся логи, где лежат вложения, кэш, дампы и бэкапы.
Чаще всего смешение происходит в трех местах:
- Общий API-шлюз для всех LLM-запросов. Он удобен, пока через него не начинают идти и российские, и внешние данные.
- Общие логи. В них легко оказываются промпты, ответы модели, user ID, trace ID и куски документов.
- Общее хранилище файлов и кэша. Туда складывают данные для RAG, временные выгрузки, eval-наборы и резервные копии.
Проблема почти всегда в маршруте, а не в названии модели. Компания может выбрать модель, которую считает безопасной, но сам запрос по дороге успевает пройти через внешний CDN, прокси, очередь, мониторинг или систему поддержки. Для 152-ФЗ этого уже достаточно, чтобы появились неприятные вопросы.
Хороший пример - российский маршрут для LLM-запросов, где обработка и логи остаются внутри РФ, но application logs при этом по привычке отправляют во внешний сервис наблюдаемости. Формально модельный маршрут разделили. По факту контуры снова смешались, потому что наружу ушли текст запроса и служебные поля.
Такие ошибки долго не видны. Интерфейс работает, ответы приходят, доступы настроены. Но стоит проследить путь одного запроса целиком, и часто оказывается, что два "раздельных" контура сходятся в одном месте.
Что считать российским контуром, а что внешним
Российский контур определяет не отдел и не конкретная стойка в ЦОДе. Его определяют сами данные, их копии и место, где система хранит следы работы. Если набор данных подпадает под 152-ФЗ, содержит коммерческую тайну или позволяет понять, что делал конкретный клиент, его лучше сразу относить к российскому контуру.
Обычно в него входят персональные данные клиентов, сотрудников и подрядчиков, логи запросов с идентификаторами, промпты и ответы модели с документами, заявками, тикетами, медданными или финансовыми деталями, а также любые бэкапы, кэши, дампы и выгрузки для отладки. Даже если такую копию создали "на пару минут", она все равно остается копией данных.
Внешний контур - это любые сервисы и хранилища за пределами РФ или вне ваших правил хранения в РФ. Сюда часто попадают зарубежные LLM API, SaaS для аналитики, баг-трекеры, мониторинг, общие бакеты, ноутбуки исследовательской команды и даже чаты, куда сотрудник вручную вставил кусок данных.
Частая ошибка проста: команда проверяет основную базу, но не смотрит на временные копии. Между тем временная копия ничем не лучше постоянной, если по ней можно понять, кто это, что он делал и с каким продуктом работал.
Простое правило для серых зон
Если вы сомневаетесь, может ли фрагмент данных указать на человека, компанию, договор, счет или внутренний процесс, оставляйте его в российском контуре. Пока команда не доказала обратное, любая копия наследует контур исходных данных.
Это особенно полезно для промптов. Если менеджер вставил в запрос имя клиента, номер договора и историю обращения, весь запрос остается в российском контуре. Если команда заранее убрала идентификаторы, обобщила детали и отключила запись содержимого в логи, такой запрос уже можно разбирать отдельно.
То же относится к временным файлам и кэшу. Если система хранит их дольше одного запроса, использует в ретраях или отправляет в отладку, это уже не мимолетный след, а обычная копия данных.
Даже при работе через российский LLM-шлюз граница проходит там, где запрос с неочищенными данными уходит к зарубежной модели или внешнему SaaS. Контур задает не название сервиса, а содержимое запроса и весь путь его копий.
Правило для каждого запроса и каждой интеграции
Разделение контуров ломается не на уровне общей схемы, а в одном конкретном запросе. Поэтому правило должно быть простым: каждый запрос получает маршрут до запуска, а не после инцидента.
Для любой интеграции команда должна ответить на четыре вопроса:
- Откуда пришли данные: из системы в РФ, из внешнего сервиса или из смешанного потока.
- Что именно уходит в запрос: персональные данные, служебный текст, коммерческие данные или уже обезличенный фрагмент.
- Где система пишет логи, трассировку, кэш и отладочные события.
- Где потом хранятся исходные запросы, ответы, эмбеддинги, бэкапы и другие артефакты обработки.
Если хотя бы на один вопрос нет точного ответа, внешний маршрут лучше закрыть. Это не бюрократия, а защита от случайной утечки. Компании часто проверяют только payload и забывают про логи и временное хранилище. А лишняя копия данных обычно появляется именно там.
Для 152-ФЗ рабочее правило звучит так: неизвестный или спорный запрос считается российским, пока владелец интеграции не докажет обратное. Это особенно важно для смешанных сценариев, где в одном потоке идут и публичные тексты, и клиентские данные из CRM, тикетов или чатов.
Спорные случаи лучше не обсуждать заново в каждой переписке. Вынесите их в простую таблицу: название интеграции, владелец, тип данных, разрешенный маршрут и причина решения. Через месяц такая таблица сэкономит часы и снимет часть споров между безопасностью, разработкой и продуктом.
Внешний контур не должен быть маршрутом по умолчанию. Нужен явный список разрешений. Маркетинг может отправлять наружу обезличенные публичные тексты для черновиков. Поддержка не должна выводить туда историю обращений клиентов. Если для российского маршрута вы используете совместимый с OpenAI API шлюз, например RU LLM, можно сохранить текущий SDK и код, но само правило маршрутизации все равно должно жить отдельно от удобства интеграции.
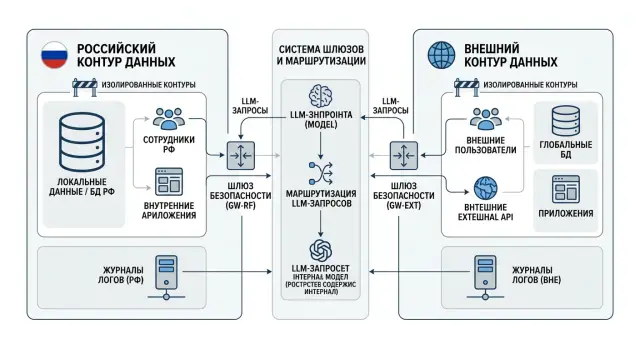
Базовый шаблон архитектуры
Рабочая схема проста: делите систему не по командам и не по продуктам, а по пути данных. Если запрос несет персональные данные, клиентские тексты, логи действий или внутренние документы, он сразу попадает в российский контур. Внешний контур получает только те данные, которым это явно разрешено.
Сбой чаще всего происходит не в базе, а на входе и выходе. Команда хранит данные в РФ, но один SDK обращается во внешний API, общий логгер пишет события в зарубежный сервис, а секреты лежат в одном хранилище для обоих контуров.
Как разложить поток
Начните с двух независимых точек входа: одной для российского контура и одной для внешнего. На входе сервис или API gateway должен ставить метки данным: источник, тип данных, наличие PII, разрешен ли внешний выход и где должны храниться логи.
После этого запрос идет не сразу в модель, а через маршрутизатор правил. Он читает метки и выбирает допустимый путь. Если запрос помечен как RU-only, он должен попасть только во внутренние очереди, внутренние сервисы и в отдельный LLM-эндпоинт российского контура.
Для LLM лучше сразу держать два разных base_url на уровне платформы: один для внешнего контура, второй для российского. Это снимает массу случайных ошибок. Для российского контура особенно удобен шлюз, совместимый с OpenAI API, потому что команде не нужно переписывать SDK, промпты и существующий код.
Что изолировать отдельно
Изоляция должна быть полной, а не "почти полной". На практике это значит следующее:
- секреты хранятся в разных хранилищах и выдаются разным сервисным аккаунтам;
- очереди и фоновые воркеры не пересекаются между контурами;
- логи, трассировки и бэкапы российского контура остаются в РФ;
- исходящий доступ из российского контура закрыт по умолчанию;
- прямой выход из российского контура во внешние API запрещен на уровне сети.
Проверять это нужно не только в проде. Временные скрипты, агенты мониторинга и отладочные сервисы ломают схему быстрее, чем основная бизнес-логика.
Хороший признак здоровой архитектуры такой: если разработчик случайно подставил внешний API-ключ в сервис российского контура, запрос все равно не уйдет наружу. Его остановят сетевые правила, отдельные секреты и маршрутизация по меткам. Только так разделение переживает обычные человеческие ошибки.
Как внедрить схему по шагам
Начинайте не с красивой схемы, а с инвентаризации. Пока команда не выписала все системы, людей и типы данных, разделение почти всегда ломается на мелочах: тестовом боте, старом ETL-скрипте или общем сервисном аккаунте.
Удобный порядок такой:
- Составьте таблицу всех источников данных, интеграций, сервисных аккаунтов и моделей, к которым они обращаются. Отдельно отметьте персональные данные, коммерческие документы, логи диалогов и обезличенные наборы.
- Проставьте метки на каждый набор данных и на каждую точку доступа. Обычно хватает трех вариантов: "только РФ", "можно наружу после очистки" и "внешний контур". Те же метки нужны очередям, бакетам, CI-пайплайнам и сервисным аккаунтам.
- Разведите эндпоинты, ключи и правила логирования на уровне конфигурации. Российский контур должен обращаться только в свой маршрут и писать логи только туда, где разрешено хранение в РФ. Внешний контур живет отдельно, со своими ключами, бюджетами и журналами.
- Проверьте отказ по закрытому сценарию. Если метка не определена, запрос не должен "как-нибудь пройти" во внешний сервис. Он должен остановиться, вернуть ошибку и оставить запись в аудите.
- Запустите пилот на одном процессе. Подойдет внутренний чат, суммаризация звонков или помощник для сотрудников. Так вы увидите, где ломаются права, кэши, ретраи и мониторинг, не трогая всю компанию.
Хороший пилот занимает пару недель, а не квартал. Если после него вы можете по любому запросу ответить, какие данные он использовал, через какой маршрут прошел и где сохранились логи, схема уже работает.
Пример для компании с двумя командами
Возьмем федеральный ритейл. У него есть команда клиентской поддержки в РФ и продуктовая команда, которая изучает воронку, поиск и рекомендации через внешние аналитические сервисы. Если контуры не развести заранее, смешение начинается с мелочей: один и тот же текст обращения уходит и в рабочую систему оператора, и в исследовательскую песочницу.
Как идет запрос поддержки
Поддержка работает только в российском контуре. Оператор открывает карточку клиента, где есть имя, телефон, адрес доставки, история заказов и текст жалобы. Это персональные данные, и выпускать их наружу ради удобства анализа не стоит.
Маршрут выглядит просто. Оператор задает вопрос помощнику по кейсу. Внутренний сервис вырезает или маскирует PII: телефон, email, адрес, номер карты лояльности. Затем запрос уходит в LLM через российский шлюз, где логи, бэкапы и аудит хранятся в РФ. Ответ возвращается в рабочую систему, а отдельная запись фиксирует, кто отправил запрос, какая маска сработала и какая модель ответила.
Если компания использует RU LLM, она может оставить привычный SDK и текущую интеграцию, но направить такие запросы в российский маршрут. Это удобно, но само по себе не отменяет изоляцию логов, ключей и сетевых правил.
Где работает внешняя аналитика
У продуктовой команды другая задача. Ей не нужен живой диалог клиента с адресом и номером телефона. Ей нужны обезличенные события: просмотр товара, клик по фильтру, брошенная корзина, время до покупки.
Для исследований лучше создать отдельную песочницу с копией схемы данных, но без реальных профилей и без сырых текстов поддержки. Туда попадают анонимные идентификаторы, агрегаты по сессиям, очищенные тексты без PII и синтетические примеры для тестов.
Граница здесь очень простая: все, что помогает обслужить конкретного человека прямо сейчас, идет только в российский контур. Все, что нужно для исследований, сначала обезличивают и только потом выносят во внешний.
Ошибки, которые ломают разделение
Даже аккуратная схема распадается из-за бытовых мелочей. Обычно проблема не в архитектуре, а в привычках команды: один общий секрет, одно хранилище логов, один временный обход для отладки. Через месяц уже никто не помнит, где российский контур, а где внешний.
Самая частая ошибка - один и тот же API-ключ для двух контуров. Так проще только в первый день. Потом вы теряете границу доступа, смешиваете биллинг и не можете быстро доказать, какой запрос куда ушел.
Не лучше и общее хранилище логов. Команда может честно отправлять прод-запросы в РФ, а затем складывать трассировки, сырые промпты и ответы в общий стек наблюдения за пределами контура. Формально маршрут был правильный. Фактически данные все равно ушли не туда. То же самое касается бэкапов: если резервная копия общего лог-хранилища лежит вне РФ, разделение уже сломано.
Ручное копирование данных ломает схему еще быстрее. Разработчик берет фрагмент клиентского диалога, вставляет его во внешний чат, пересылает по почте или загружает на тестовый стенд. Обычно это называют быстрой проверкой. На деле это теневой канал вывода данных.
Особенно опасен внешний fallback без явного правила. Если внутренняя модель не ответила, система не должна молча отправлять тот же запрос зарубежному провайдеру. Для каждого класса данных нужен жесткий маршрут: можно ли выйти во внешний контур, при каких условиях и кто это одобрил.
Часто забывают и про вспомогательные наборы: eval-датасеты, примеры для разметки, экспорт для расследований, отладочные дампы, снимки очередей. Если прод-контур российский, эти артефакты тоже должны жить по тем же правилам.
Признаки того, что схема уже трещит, обычно видны быстро:
- у двух контуров общие секреты или общий сервисный аккаунт;
- логи и трассировки открываются в одном интерфейсе без отдельного хранения;
- разработчики руками переносят реальные данные в тест;
- fallback включен по умолчанию и не проверяет тип данных;
- бэкапы и eval-наборы не описаны в схеме доступа.
Если в системе уже есть хотя бы два таких признака, граница между контурами существует только на словах.
Быстрая проверка перед запуском
Перед стартом полезно пройтись не по схеме на доске, а по реальным настройкам. Большая часть ошибок возникает в мелочах: общий API-ключ, тестовый бот без ограничений, резервные копии в чужом облаке.
Проверка должна отвечать на несколько простых вопросов. Можно ли за минуту понять, куда уйдет конкретный запрос? Понятно ли, где останутся логи? Есть ли конкретный владелец спорного случая?
Минимальный список такой:
- У каждого контура свой эндпоинт, свой набор секретов и свой способ выдачи доступов.
- Логи, трассировки и бэкапы российского контура хранятся в РФ, включая очереди, дампы и объектные хранилища.
- Для каждого LLM-запроса можно быстро ответить, какие данные он получил, через какой маршрут пошел и где сохранился его след.
- Сотрудник не может обойти правила через тестовый сервис, личный токен или временную интеграцию.
- В спорных случаях решение принимает конкретный владелец правила, а не абстрактная "безопасность в целом".
Хороший быстрый тест выглядит скучно, и это нормально. Возьмите два сценария: запрос с персональными данными клиента и запрос с обезличенным текстом для внешней команды. Прогоните оба по цепочке и проверьте журналы, секреты, маршрут и место хранения следов. Если хотя бы на одном шаге инженер отвечает "скорее всего", запуск лучше отложить.
Если для российского маршрута нужен единый LLM-шлюз, имеет смысл смотреть на вариант, который не требует переписывать текущие SDK и код. У RU LLM этот сценарий как раз есть: совместимый с OpenAI API эндпоинт, хранение логов и бэкапов внутри РФ, биллинг внутри РФ. Но даже в таком случае разделять нужно не только модели, а весь маршрут целиком - эндпоинты, секреты, логи и правила доступа.
Что делать дальше
Не пытайтесь сразу переделать весь стек. Лучше выбрать один процесс, где смешение контуров случается чаще всего и обходится дороже всего. Обычно это чат с клиентскими данными, внутренняя аналитика с выгрузкой во внешние сервисы или генерация документов из CRM.
Такой старт быстро показывает реальные точки утечки: где запрос уходит не туда, кто хранит логи, какая команда меняет интеграции без согласования. Это полезнее, чем строить идеальную схему на все случаи сразу.
После этого заведите простую рабочую таблицу. В ней должны быть перечислены системы, модели и интеграции для каждого сценария, указан контур - РФ или внешний, назначен владелец и отдельно зафиксировано, кто утверждает изменения маршрута и кто разбирает инциденты.
Таблица нужна не для отчета, а для одного практического вопроса: куда идет каждый запрос и кто за это отвечает. Если ответа нет за минуту, схема еще сырая.
Дальше проверьте не только основной маршрут, но и все следы вокруг него. Компании часто аккуратно разводят трафик, а потом снова смешивают контуры в логах, резервных копиях и отладочных дампах. Для сценариев с персональными данными достаточно задать три вопроса: есть ли аудит по запросам, маскируется ли PII до отправки и где физически лежат логи.
Хороший пилот обычно выглядит очень прозаично: один процесс, одна таблица маршрутов, назначенные владельцы, проверенные логи. Если это работает месяц без сюрпризов, остальные сценарии переносить уже намного проще.
Часто задаваемые вопросы
Что считать российским контуром данных?
Российский контур задает не команда и не название модели, а путь данных. Если запрос, логи, кэш, вложения и резервные копии остаются в РФ, это российский контур.
Если в запросе есть персональные данные, договоры, обращения клиентов или внутренние документы, такой поток сразу относите туда.
Когда запрос можно пускать во внешний контур?
Отправляйте наружу только то, что вы уже очистили и явно разрешили для внешнего маршрута. Если в тексте остались имя, номер договора, история обращения или другие следы конкретного человека или компании, такой запрос должен остаться в РФ.
Когда есть сомнение, считайте запрос российским, пока владелец интеграции не подтвердит обратное.
Почему мало просто выбрать безопасную модель?
Потому что риск обычно возникает не в самой модели, а по дороге к ней. Запрос может пройти через внешний прокси, мониторинг, очередь или логирование, и этого уже хватит для проблем.
Смотрите на весь маршрут целиком: от входа запроса до места, где лежат его следы.
Где контуры смешиваются чаще всего?
Чаще всего контуры смешиваются в общем API-шлюзе, в логах и в общем хранилище файлов или кэша. Туда быстро попадают промпты, ответы модели, user ID, trace ID и куски документов.
Еще одна частая точка риска — внешний сервис наблюдаемости, куда по привычке уходит текст запроса.
Что делать с логами, кэшем и бэкапами?
Держите логи, трассировку, кэш и резервные копии российского контура внутри РФ. Не пишите сырые промпты и ответы туда, где ими пользуются оба контура сразу.
Если временный файл живет дольше одного запроса или участвует в повторах и отладке, считайте его обычной копией данных.
Нужно ли разводить эндпоинты и секреты?
Да, и это сильно снижает число ошибок. Для российского и внешнего контура нужны разные base_url, разные секреты, разные сервисные аккаунты и отдельные правила сети.
Тогда даже если разработчик перепутает настройку, сеть и маршрутизация остановят запрос.
Что делать, если непонятно, есть ли в запросе персональные данные?
Не спорьте о таком запросе в каждом чате заново. Введите простое правило: все спорные и неизвестные случаи остаются в российском контуре.
Потом занесите решение в таблицу с владельцем интеграции, типом данных и разрешенным маршрутом.
Можно ли оставить один и тот же SDK для двух контуров?
Можно, если у вас два отдельных маршрута на уровне платформы. Команда оставляет привычный код, но система направляет запрос либо в российский, либо во внешний контур по меткам и правилам.
Такой подход удобен, но он не заменяет изоляцию логов, секретов и исходящего доступа.
Как быстро проверить схему перед запуском?
Возьмите два сценария: запрос с данными клиента и запрос с обезличенным текстом. Прогоните оба по всей цепочке и проверьте, куда они ушли, где сохранились логи и кто видит эти записи.
Если на любом шаге команда отвечает «наверное» или «скорее всего», запуск рано делать.
С чего начать внедрение такой схемы?
Начните с одного процесса, где ошибка стоит дорого: чат поддержки, суммаризация звонков или генерация документов из CRM. Это даст живую картину без переделки всего стека.
Сразу соберите таблицу источников данных, интеграций, сервисных аккаунтов и маршрутов. После этого станет видно, где контуры уже пересекаются.