Задержка до первого токена: как близость ЦОДа меняет UX
Задержка до первого токена влияет на UX чата: в статье покажем схему маршрута, роль географии ЦОДов и простой способ замерить эффект в РФ.
Почему чат тормозит уже в первые секунды
Задержка до первого токена, или TTFT, - это время между нажатием "Отправить" и появлением первого фрагмента ответа на экране. Пользователь еще ничего не читает по смыслу. Он просто ждет первого сигнала, что чат живой.
Эту паузу люди замечают сильнее, чем полное время ответа. Пока экран молчит, кажется, что система зависла, сеть подвисла или запрос потерялся. Когда текст уже пошел, даже медленный ответ воспринимается спокойнее: диалог начался, значит все работает.
Поэтому два чата с похожим общим временем могут ощущаться совсем по-разному. Если один показывает первые слова через 0,8 секунды, а второй через 1,3, второй почти всегда кажется медленнее, даже если закончит ответ чуть раньше. Пользователь судит по старту.
Лишние 200-500 мс тоже заметны. В чате поддержки это разница между "ответил сразу" и "что-то задумался". На коротких вопросах вроде "Где мой заказ?" или "Почему не проходит платеж?" такая пауза ломает ритм разговора. Человек смотрит на пустой экран, повторно жмет Enter или решает, что чат не сработал.
Полезно разделять три метрики:
- TTFT - пауза до первого токена, то есть до начала ответа.
- Полное время ответа - сколько прошло от отправки запроса до последнего токена.
- Скорость стриминга - как быстро текст появляется после старта.
Это разные ощущения. Чат может быстро начать, но потом печатать вяло. Или, наоборот, долго молчать, а потом выдать почти весь ответ без пауз. Для UX чата первая проблема обычно заметнее.
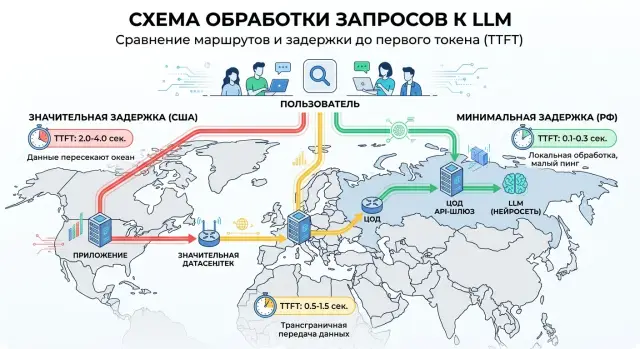
Именно здесь близость ЦОДа быстро дает эффект. Если запрос из России уходит в дальний регион, проходит через несколько сетевых узлов и только потом попадает к модели, задержка до первого токена растет еще до самой генерации. Команды, которые переводят трафик на более короткий маршрут или на российский шлюз вроде RU LLM, часто первым делом замечают не "ускорение модели", а то, что чат раньше начинает говорить.
Откуда берется задержка до первого токена
Задержка начинается раньше, чем модель пишет первое слово. Пользователь нажимает Enter, а запрос проходит через несколько узлов. Даже если сама модель отвечает быстро, сеть, проверки и очереди легко добавляют сотни миллисекунд.
Пользователь -> браузер -> ваш бэкенд -> API-шлюз -> провайдер -> модель -> первый токен обратно
Сначала браузер должен понять, куда идти по доменному имени. Это DNS. Потом он поднимает защищенное соединение. Это TLS. Если соединение уже открыто, этот этап почти незаметен. Если нет, он добавляет еще несколько сетевых обменов. Для пользователя из России путь до удаленного региона почти всегда длиннее, а значит растет время на каждый такой обмен.
Дальше запрос обычно попадает в ваш бэкенд. Там сервер проверяет токен, собирает историю диалога, иногда режет лишний контекст, пишет логи и отправляет запрос дальше. Если между приложением и провайдером стоит отдельный шлюз, это еще один шаг. Сам по себе он не страшен, но каждый дополнительный hop добавляет время, особенно если трафик ходит через другие страны.
На стороне провайдера сеть уже не единственный фактор. Запрос могут поставить в очередь, если модель занята. Провайдер может проверить лимиты, запустить модерацию, выбрать кластер и только потом отдать задачу модели. Если первый вызов не прошел и система делает повторную попытку, пользователь видит паузу, хотя интерфейс просто ждет.
Сама модель тоже тратит время до первого токена. Она не начинает ответ с пустого листа. Сначала ей нужно прочитать весь вход: системный промпт, историю чата, последний вопрос и служебные инструкции. Чем длиннее системный промпт и чем больше переписка, тем позже стартует ответ. Это особенно заметно в поддержке, где в промпт часто добавляют правила, базу знаний и формат ответа.
Обычно время уходит в пять мест:
- DNS и открытие TLS-соединения
- путь между браузером, бэкендом, шлюзом и провайдером
- очередь у провайдера или у самой модели
- чтение длинного промпта перед генерацией
- повторные попытки после таймаута или сетевой ошибки
Поэтому близость ЦОДа влияет только на часть задержки. Она срезает сетевые раунды и делает старт живее. Но если модель перегружена, а промпт раздут до нескольких страниц, быстрый канал сам по себе не спасет UX чата.
Схема пути запроса из России
Пауза перед первым символом не появляется в одной точке. Она складывается по дороге: запрос уходит из браузера в приложение, потом в шлюз, потом в модель, и только после этого начинается стрим первого токена. Если самый длинный участок находится далеко от пользователя, TTFT растет даже при нормальной скорости самой модели.
Ниже - упрощенная схема для пользователя из России. Числа условные, но порядок обычно такой.
Вариант 1. ЦОД с моделью в РФ
Пользователь в РФ
-> приложение в РФ RTT ~ 20 мс
-> шлюз в РФ RTT ~ 5 мс
-> модель в РФ RTT ~ 10 мс
-> очередь + префилл модели ~ 80-150 мс
<- первый токен обратно ~ 35 мс по сети суммарно
Итого до старта стрима: примерно 150-220 мс + время генерации первого токена
Вариант 2. Модель в Европе
Пользователь в РФ
-> приложение в РФ RTT ~ 20 мс
-> шлюз в РФ RTT ~ 5 мс
-> модель в Европе RTT ~ 70-110 мс
-> очередь + префилл модели ~ 80-150 мс
<- первый токен обратно ~ 95-135 мс по сети суммарно
Итого до старта стрима: примерно 270-390 мс + время генерации первого токена
Вариант 3. Модель в США
Пользователь в РФ
-> приложение в РФ RTT ~ 20 мс
-> шлюз в РФ RTT ~ 5 мс
-> модель в США RTT ~ 160-220 мс
-> очередь + префилл модели ~ 80-150 мс
<- первый токен обратно ~ 185-245 мс по сети суммарно
Итого до старта стрима: примерно 430-620 мс + время генерации первого токена
Где копится пауза
Самая неприятная часть обычно находится не между пользователем и приложением, а между шлюзом и моделью. Когда этот участок уходит в Европу или США, каждый запрос получает лишние десятки или сотни миллисекунд еще до того, как модель начала отвечать.
Потом появляется вторая задержка: первый кусок стрима должен вернуться тем же путем назад. Пользователь не видит ни очередь у провайдера, ни сетевые прыжки. Он просто чувствует, что чат "думает" слишком долго.
Для UX чата разница между 180 мс и 500 мс ощущается сразу. В первом случае интерфейс выглядит живым. Во втором человек часто успевает решить, что система подвисла.
Если приложение работает в РФ, а шлюз и модель тоже находятся близко, путь короче и стабильнее. Для российского контура это один из самых заметных способов снизить TTFT без переписывания логики чата. У RU LLM такой сценарий возможен: запросы идут через единый шлюз внутри РФ, а часть моделей размещена в российских ЦОДах. Это убирает длинный международный участок из схемы и делает старт ответа ровнее.
Что меняется, когда ЦОД ближе
Когда сервер ближе к пользователю, чат начинает отвечать раньше даже при том же интерфейсе, том же промпте и той же модели. Причина простая: сети нужно меньше времени на каждый круг между браузером, бэкендом и шлюзом LLM, поэтому TTFT падает еще до того, как модель успела выдать заметный кусок текста.
До старта ответа запрос почти никогда не идет "в один конец". Клиент открывает соединение, проходит TLS, отправляет запрос, получает первые байты стрима. Если RTT не 80-100 мс, а 15-25 мс, эти короткие обмены заметно сжимаются. Для человека разница между 0,8 и 1,4 секунды ощущается очень сильно.
Для российской команды это часто можно улучшить без переделки самого чата. Если шлюз LLM находится ближе к пользователю, приложение может работать с теми же SDK и тем же UI. Например, в сценарии с RU LLM команды обычно меняют только base_url, а путь до API становится короче для российских пользователей.
Что видно в метриках
Среднее значение редко показывает реальную картину. Смотрите хотя бы на p50 и p95. p50 показывает обычный опыт, а p95 - те сессии, где пользователь уже думает, что чат завис.
Когда ЦОД ближе, p50 обычно снижается заметно, но p95 выигрывает еще сильнее. Простой пример: среднее время до первого токена может упасть с 1,6 до 1,2 секунды, а p95 - с 4,0 до 2,1 секунды. По среднему разница выглядит умеренной. По хвостам она меняет ощущение от продукта.
Длинный маршрут чаще ловит джиттер, потери пакетов и паузы на промежуточных узлах. Из-за этого мобильный клиент, корпоративный прокси или SDK может сделать повторную попытку. Пользователь не видит техническую причину. Он просто ждет лишнюю секунду, а иногда нажимает "Отправить" еще раз. Ближний ЦОД снижает риск таких срывов, а вместе с ними и шанс таймаутов в начале ответа.
В интерфейсе это обычно выглядит так:
- индикатор печати горит меньше времени
- первые токены появляются без длинной паузы
- стрим идет ровнее, без резких стартов и остановок
- поведение чата меньше гуляет в часы нагрузки
Ближний ЦОД не делает модель умнее и не всегда ускоряет генерацию каждого следующего токена. Но он убирает лишнюю дорогу в самом чувствительном месте - перед началом ответа. Для UX чата этого уже достаточно, чтобы сервис казался быстрым и предсказуемым, а не "задумчивым".
Пример: чат поддержки для российского сервиса
Возьмем простой сценарий: пользователь пишет в чат поддержки интернет-сервиса "Почему у меня не проходит оплата?" Интерфейс один и тот же, текст вопроса один и тот же, промпт один и тот же. Меняется только место, где работает модель.
Вариант А: модель отвечает из московского ЦОДа. Вариант Б: тот же чат ходит к удаленному провайдеру за пределами России. Для пользователя разница часто ощущается раньше, чем он успевает прочитать первое предложение.
Пользователь в РФ -> веб-чат -> backend сервиса -> модель в Москве -> первые токены
Пользователь в РФ -> веб-чат -> backend сервиса -> удаленный провайдер -> первые токены
Если ответ начинает приходить почти сразу, человек остается в диалоге. Если курсор мигает 3-4 секунды без текста, чат кажется сломанным, даже когда полный ответ потом приходит всего на пару секунд позже.
Для наглядности можно взять условные числа для одного и того же ответа длиной около 180 токенов:
| Сценарий | TTFT | Полный ответ | Что чувствует пользователь |
|---|---|---|---|
| Модель в московском ЦОДе | 0.8 с | 6.7 с | Чат "ожил" сразу, ответ уже можно читать |
| Удаленный провайдер | 3.4 с | 8.9 с | Сначала пауза, потом текст; часть пользователей думает, что все зависло |
На бумаге разница в полном времени не выглядит огромной: 6.7 против 8.9 секунды. Но UX ломается не на последних двух секундах, а в самом начале. В первом случае человек уже читает ответ с первой секунды. Во втором он три с лишним секунды просто ждет.
В поддержке это быстро бьет по поведению:
- пользователь отправляет тот же вопрос второй раз
- перебивает чат новым сообщением
- закрывает окно и идет к оператору
- считает сервис медленным, даже если проблема не в интерфейсе
Есть и эффект доверия. Когда первый токен приходит за 0.8 секунды, человек воспринимает чат как живой инструмент. Когда первый токен приходит за 3.4 секунды, он начинает сомневаться: запрос ушел или нет, понял ли чат вопрос, не сломалась ли оплата еще сильнее.
Поэтому близость ЦОДа влияет не только на метрику. Она меняет сам ритм разговора. Для российского сервиса это особенно заметно в поддержке, где пользователь редко терпелив и почти всегда ждет мгновенной реакции. Если команда использует шлюз с моделями в российских ЦОДах, меняется не логика чата, а длина сетевого пути. Этого уже хватает, чтобы диалог ощущался быстрее и спокойнее.
Как замерить это у себя
Если чат кажется "тяжелым", не смотрите только на общее время ответа. Для UX важнее момент, когда пользователь увидел первый символ. Именно так можно понять, где растет задержка: в сети, на вашем бэкенде, у провайдера модели или уже в интерфейсе.
Сначала поставьте отметки времени в трех точках: на клиенте, на бэкенде и на стороне маршрута к модели. Если вы ходите к моделям через шлюз вроде RU LLM, логируйте не только входящий запрос, но и выбранный апстрим. Иначе вы увидите усредненную картину, а не проблемный маршрут.
t0 - клиент отправил запрос
t1 - бэкенд принял запрос
t2 - бэкенд отправил запрос LLM
t3 - пришел старт стрима
t4 - клиент показал первый токен
t5 - ответ завершился
Эти точки дают несколько разных метрик. t3 показывает, когда провайдер открыл стрим. t4 показывает реальный first token latency глазами пользователя. Разница между ними часто вскрывает неожиданную вещь: фронтенд копит токены в буфере и показывает текст пачкой раз в 300-500 мс.
Что сравнивать
Не меняйте все сразу. Возьмите один и тот же промпт, одну модель, одинаковую температуру и одинаковый размер контекста. Прогоните серию хотя бы по 30-50 запросов из нескольких городов России, например из Москвы, Екатеринбурга, Новосибирска и Владивостока.
Снимайте по каждому маршруту:
- p50 для старта стрима
- p50 и p95 для первого токена
- p95 для полного ответа
- долю таймаутов и обрывов стрима
- разницу между t3 и t4
Если p50 хороший, а p95 резко хуже, пользователь будет видеть картину "то быстро, то мучительно долго". Это типично для длинных сетевых маршрутов и перегруженных апстримов.
Как не испортить замер
Частая ошибка - тестировать из офиса в Москве и делать вывод за всю страну. Для чата поддержки это особенно опасно: пользователи из Сибири и Дальнего Востока могут ждать первый токен заметно дольше даже при той же модели.
Еще одна ошибка - смотреть только на серверные логи. Бэкенд может честно получить стрим вовремя, а браузер задержит показ из-за буферизации, рендера или прокси между фронтендом и API. Если хотите проверить это быстро, откройте DevTools и сравните время первого байта, начало SSE-стрима и момент, когда текст реально появился на экране.
После такого замера у вас будет не спор о "быстром" и "медленном" чате, а таблица с маршрутами, городами и цифрами. По ней уже легко решить, где менять провайдера, где переносить трафик ближе к пользователю, а где чинить сам интерфейс.
Где команды ошибаются
Самая частая ошибка проста: команда смотрит на общее время ответа и считает, что этого достаточно. Но пользователь чувствует не весь ответ, а паузу до начала ответа. Если бот молчит 2 секунды, а потом быстро печатает, UX уже кажется тяжелым. Поэтому TTFT часто важнее, чем полное время генерации.
Вторая ошибка появляется еще до замеров. Многие гоняют тесты из офиса в Москве, из одного ЦОДа или через одного провайдера, а потом делают выводы для всей страны. Так картина ломается. Пользователь в Новосибирске, Екатеринбурге или Владивостоке идет по другому сетевому пути и получает другую паузу до первого символа.
Обычно сравнение портят сразу несколько мелочей:
- одна команда меняет модель и одновременно меняет маршрут запроса
- в одном тесте короткий промпт, в другом длинная история чата
- один сценарий идет с RAG, другой без него
- модерация и прокси включены только в части запросов
- фронтенд показывает текст кусками и скрывает реальный TTFT
Из-за этого получается ложный вывод: кажется, что проблема в географии серверов, хотя лишние секунды лежат между сервисами. Часто запрос сначала идет в API-шлюз, потом в модерацию, потом в поиск по базе знаний, потом в оркестратор моделей, и только потом в модель. Каждый шаг добавляет сеть и обработку. Если не мерить время на каждом участке, команда спорит о ЦОДе, хотя тормозит RAG или фильтр безопасности.
Есть и более тихая ошибка. Фронтенд иногда буферизует токены и рисует ответ пачкой, чтобы текст выглядел ровнее. Пользователь видит красивую анимацию, а команда думает, что все быстро. На деле модель могла отдать первый токен давно, просто интерфейс его придержал. Для диагностики это вредно.
Нормальное сравнение требует дисциплины. Берите один и тот же промпт, одну модель, одинаковый размер контекста и несколько точек запуска по РФ. Если вы тестируете через единый OpenAI-совместимый эндпоинт, например api.rullm.com, это упрощает сравнение: SDK и код можно не менять, а различия по маршруту видны чище. После этого уже понятно, где теряется время - в сети, в промежуточных сервисах или в самой модели.
Когда близость ЦОДа не решает проблему
Близкий ЦОД почти всегда снижает сетевую задержку. Но TTFT - это не только RTT между пользователем и сервером. Если сеть экономит 80-150 мс, а остальные этапы добавляют 2-3 секунды, пользователь все равно видит, что чат "задумался".
Частая причина - слишком длинный системный промпт. Модели нужно обработать весь вход до того, как она начнет отдавать первый токен. Если в запросе длинные инструкции, история диалога, блок с политиками и большой RAG-контекст, выигрыш от близости ЦОДа быстро тает. На практике короткий и чистый промпт нередко дает больше пользы, чем перенос сервера на пару тысяч километров ближе.
Есть и другая ловушка: очередь у провайдера. RTT может быть низким, маршрут коротким, а запрос все равно висит секунду или две, потому что у провайдера заняты GPU. Команды часто смотрят на ping и решают, что с сетью все в порядке. Это правда, но пользователь ждет не ping, а первый символ ответа.
Иногда тормозит сама модель. Большая reasoning-модель может долго считать даже на локальной инфраструктуре. Для UX чата это важный момент: медленная модель с близким ЦОДом нередко проигрывает более быстрой модели, которая стоит дальше. Особенно это заметно в поддержке, где человек ждет быстрый первый ответ, а не самый глубокий анализ.
Еще один скрытый источник задержки - промежуточные сервисы на стороне приложения. Запрос может пройти через API gateway, проверку авторизации, поиск по базе знаний, маскирование PII, логирование и только потом уйти в LLM. Если каждый шаг добавляет по 100-300 мс, суммарный маршрут внутри вашего стека становится длиннее, чем путь до удаленного ЦОДа.
Здесь полезно мерить части отдельно:
- время до отправки запроса из приложения
- ожидание в очереди у провайдера
- prefill и старт генерации у модели
- дополнительные hop между вашими сервисами
Для российских команд это особенно заметно в сложных схемах, где вызов LLM идет через несколько внутренних систем. Даже если вы используете шлюз вроде RU LLM с инфраструктурой в РФ, длинный промпт, перегруженный провайдер или тяжелая цепочка сервисов могут съесть весь выигрыш по сети.
Что сделать дальше
Если чат уже кажется медленным, не начинайте с замены модели. Сначала соберите простую карту маршрута: от пользователя до вашего бэкенда, потом до провайдера LLM, и отдельно обратный путь первого токена. На этом шаге часто видно, что проблема не в самой модели, а в том, что запрос из Новосибирска или Екатеринбурга уходит слишком длинным кругом.
Потом замерьте TTFT по регионам РФ, а не только из одного офиса или из московского облака. Полезно сравнить хотя бы Москву, Санкт-Петербург, Екатеринбург, Новосибирск и Владивосток. Если в одном регионе чат отвечает живо, а в другом пользователь уже думает, что интерфейс завис, у вас не один UX, а несколько.
Дальше нужен свой порог терпения. Для чата поддержки и внутреннего помощника цифры обычно разные. Где-то 1 секунда до первого токена ощущается нормально, а где-то уже раздражает. Лучше принять рабочее правило заранее: например, все, что выше вашего лимита для интерактивного сценария, уходит в разбор, даже если среднее значение по системе выглядит приемлемо.
После этого стоит развести маршруты и модели по типу задачи:
- интерактивный чат отправлять по самому короткому пути с упором на TTFT
- длинные фоновые задачи пускать через более медленные, но дешевые модели
- суммарную стоимость считать отдельно от пользовательского отклика
- правила маршрутизации проверять после каждого изменения провайдера или сети
Если вы работаете с данными из РФ, проверьте не только сам инференс, но и то, где лежат логи, бэкапы и технические следы запросов. Команды часто смотрят на время ответа и забывают про хранение данных. Потом это всплывает уже на согласовании с безопасностью или юристами.
Когда нужен единый OpenAI-совместимый эндпоинт внутри РФ, без переписывания SDK и промптов, логично смотреть на решения, которые дают короткий маршрут и российский контур хранения. В этом месте RU LLM может быть удобным вариантом: достаточно поменять base_url на api.rullm.com, а биллинг, логи и бэкапы остаются внутри РФ.
Хороший итог этой работы очень приземленный: таблица регионов, TTFT по каждому маршруту, ваш лимит для живого чата и список задач, которые не должны идти тем же путем, что и диалог с пользователем.