Prompt caching в продакшене: где он экономит, а где ломает
Разберём, когда prompt caching в продакшене снижает расходы, как выбрать TTL, настроить инвалидацию и смотреть метрики после запуска.
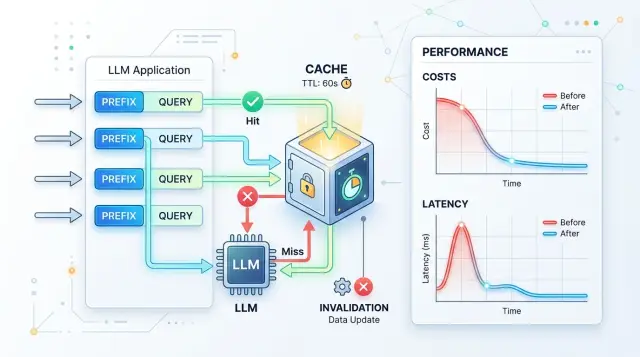
Почему кэш не даёт одинаковую выгоду
У prompt caching нет средней пользы, которая подходит всем. Один тип запросов заметно режет расходы, другой почти ничего не меняет. Причина простая: кэш любит повторяемость, а в живых диалогах её обычно меньше, чем кажется после первого просмотра логов.
Полный пользовательский промпт в чате редко повторяется дословно. Меняются имена, даты, номера заказов, последние реплики, язык ответа и даже мелкие формулировки. Для человека это "тот же вопрос", для кэша - уже другой запрос. Поэтому ожидание вроде "у нас саппорт, значит кэш сработает почти в каждом диалоге" часто не оправдывается.
Зато служебная часть запроса повторяется постоянно. Системная инструкция, правила безопасности, формат ответа, набор инструментов, длинный контекст о продукте - именно здесь кэш чаще всего окупается. Если команда каждый раз отправляет одни и те же 2-5 тысяч токенов перед новым вопросом, разницу в счёте видно почти сразу.
Есть и обратная сторона. Если в кэш попал плохой ответ или устаревшая заготовка, ошибка быстро расходится по потоку запросов. Один неудачный шаблон в базе знаний может испортить десятки одинаковых ответов, пока команда не заметит проблему.
Поэтому смотреть только на цену токенов слишком узко. Кэш может снизить расходы, но ухудшить качество из-за старого контекста. Иногда он даже добавляет задержку, если проверка кэша настроена неудачно или промахов слишком много.
Нормальная оценка всегда тройная: сколько денег вы сэкономили, сколько миллисекунд выиграли или потеряли и как изменилось качество ответа. Для команд с длинными системными инструкциями это особенно заметно. Повторяющаяся служебная часть даёт выгоду, а уникальная часть диалога почти не кэшируется. Если трафик идёт через единый шлюз вроде RU LLM, это обычно видно ещё быстрее, потому что все сценарии проще сравнить в одном месте.
Какие запросы стоит кэшировать
Больше всего экономят не любые повторные запросы, а те, где дорогая часть известна заранее. Лучше всего работают запросы с длинной общей "шапкой": системные инструкции, правила ответа, формат вывода, словари категорий, требования к тону и безопасности. Если такой текст меняется раз в месяц, нет смысла оплачивать его заново при каждом вызове.
Хорошие кандидаты для кэша - шаблонные задачи. Классификация тикетов, извлечение полей из документов, модерация пользовательского текста, проверка на соответствие правилам обычно идут по одной схеме. Меняется входной фрагмент, а основная инструкция остаётся прежней. На этом повторе кэш и даёт заметную экономию.
То же касается RAG-сценариев, но не целиком. Есть смысл кэшировать общие инструкции до подстановки свежих данных: как отвечать, как цитировать, что делать при нехватке фактов. А вот часть с найденными документами часто живёт недолго и быстро устаревает.
Обычно в кэш попадают длинные системные промпты с редкими изменениями, повторяющиеся шаблоны для классификации и извлечения полей, модерация с фиксированными правилами и справочные ответы, которые редакторы обновляют нечасто. Лучше всего работают сценарии без персональных данных или с их предварительным маскированием.
Справочные сценарии часто дают быстрый результат. Служба поддержки снова и снова отвечает на вопросы про возврат, доставку или лимиты по услуге. Если текст политики меняется редко, кэш снижает расходы и обычно не портит ответ.
С персональными данными лучше быть строже. Если в запросе есть ФИО, номер договора, адрес или детали текущего заказа, польза от кэша падает, а риск ошибки растёт. В таких случаях разумнее кэшировать только общую инструкцию, а не весь запрос целиком.
На практике первый эффект чаще всего виден на длинных общих инструкциях и массовых шаблонных вызовах. Это не самые интересные сценарии, зато именно они часто съедают заметную часть бюджета.
Где кэш ломает ответ
Кэш помогает только тогда, когда запрос и правда означает одно и то же. Как только смысл зависит от нового сообщения, свежих данных или профиля пользователя, старый ответ начинает врать. Самый неприятный вариант - когда расходы падают, а качество ответа тихо проседает.
Первыми ломаются диалоги. Пользователь пишет: "Хочу перенести доставку", а через минуту добавляет: "Адрес уже другой". Второе сообщение меняет смысл, тон и набор нужных действий. Если система кэширует ответ по похожему фрагменту переписки, она вернёт совет для старой ситуации.
Плохо работают с кэшем и запросы к живым данным. Цены, остатки, статус заказа, лимиты, курс, дата отгрузки меняются быстро. Ответ, который был верным 10 минут назад, уже может стать ошибкой. Экономия на токенах в таком случае легко превращается в лишний звонок в поддержку или неверное действие клиента.
С персонализацией риск ещё выше. Два человека задают один и тот же вопрос про тариф или возврат, но у них разная история, сегмент, права доступа и ограничения. Если кэш не учитывает эти признаки, система смешивает контекст.
Проблемы бывают и там, где меняется не сам факт, а форма ответа. Маленькая правка в промпте вроде "верни JSON" вместо "объясни простыми словами" уже делает запрос другим. То же самое касается тона, длины, языка, схемы полей и правил форматирования. Для человека это мелочь, для интеграции - другой контракт.
Отдельный случай - ответы с цитатами из базы знаний. Пользователь ждёт свежую формулировку из документа, а база могла обновиться час назад. Если кэш не привязан к версии базы, хешу документа или времени индексации, модель уверенно отдаст старую цитату.
Поэтому обычно не кэшируют ответ целиком там, где есть живые данные, персональный контекст или быстро меняющаяся база знаний. В таких сценариях лучше кэшировать только стабильные части: системный промпт, общие инструкции или результаты, жёстко привязанные к версии источника.
Как выбрать TTL без гадания
Одинаковый TTL для всех запросов почти всегда приводит к лишним ошибкам. Срок жизни кэша стоит выбирать не по удобной цифре вроде "1 час", а по тому, как быстро стареют данные в ответе.
Если ответ зависит от цены, статуса заказа, лимита, остатка на складе или свежих событий, кэш живёт очень недолго или не живёт вовсе. Ошибка здесь дорогая: пользователь получает не просто старый текст, а неверное действие.
Проще всего разбить запросы по типам и дать каждому свой срок. Рабочая схема часто выглядит так:
- 1-5 минут или без кэша для цен, статусов, остатков и персональных расчётов
- 15-30 минут для справки, которая меняется несколько раз в день
- 6-24 часа для стабильных инструкций, шаблонов ответов и системных промптов
- несколько дней для редко меняющихся классификаторов и служебных подсказок
Такой подход легче поддерживать, чем один общий TTL для всей системы. Он ещё и честнее показывает, где вы экономите, а где рискуете качеством.
Смотрите на источник изменений
Если команда часто правит промпт, меняет модель или обновляет базу знаний, TTL надо снижать сразу. Иначе кэш начнёт отдавать ответы, собранные по старым правилам. На практике это выглядит просто: в коде уже новая версия, а пользователи ещё часами получают старую логику.
Полезное правило звучит так: TTL не должен жить дольше, чем интервал между заметными изменениями. Если базу знаний обновляют каждые 20 минут, кэш на 2 часа почти гарантированно начнёт врать.
Небольшой рабочий пример
У бота поддержки есть два класса запросов. Первый - "как сменить пароль" или "где скачать акт". Такие ответы строятся на стабильных инструкциях, и им подойдёт TTL на часы. Второй - "где мой заказ" или "какой у меня тариф". Здесь лучше ставить минуты или отключать кэш совсем.
Если вы ведёте трафик через единый шлюз, TTL удобно держать в правилах маршрутизации по типам запросов, а не пытаться угадать одно число для всей системы. Так проще менять политику без правок в каждом сервисе.
Что включать в идентификатор запроса
Если в идентификаторе есть только текст вопроса, кэш быстро начинает путать ответы. Один и тот же запрос может дать разный результат из-за другой модели, новой системной инструкции или даже другого канала общения.
Хороший идентификатор собирают из нескольких частей:
- версии системного промпта и шаблона
- имени модели
- параметров генерации, если они влияют на ответ
- ожидаемого формата вывода, например plain text или JSON
- нормализованного пользовательского ввода
- версии базы знаний или источника данных, если ответ от них зависит
Версию системного промпта лучше менять даже при маленькой правке. Одна новая фраза в инструкции уже может сделать старый кэш опасным. То же касается шаблона, который добавляет контекст, поля профиля клиента или правила ответа.
Пользовательский ввод и общую инструкцию лучше разделять явно. Тогда видно, что именно дало совпадение: сам вопрос или вся сборка промпта. Это полезно и для отладки, и для инвалидации. Если шаблон обновился, вы сбросите один слой кэша, а не всё подряд.
Нормализация тоже сильно влияет на долю попаданий. Уберите лишние пробелы, приведите даты к одному виду, очистите служебные поля, которые меняются каждый раз: request_id, trace_id, timestamp. Но не трогайте данные, которые меняют смысл запроса. Иначе кэш начнёт склеивать разные ситуации.
Не смешивайте роли и каналы. Ответ для оператора поддержки, клиента в веб-чате и внутреннего сотрудника может строиться на одном вопросе, но тон, ограничения и набор данных у них разные. В B2B-сценариях это особенно заметно: один и тот же запрос может идти в разные продукты с разными правилами вывода.
Идентификатор должен описывать не только вопрос, но и условия, в которых модель на него отвечает. Только тогда кэш экономит деньги, а не создаёт тихие ошибки.
Как запускать кэш по шагам
Начинать лучше с потока, где повторы видны сразу и где ошибка не слишком дорогая. Обычно это типовые вопросы поддержки, короткие классификаторы или разбор стандартных документов. Если неверный ответ может повлиять на деньги, договор или юридическую позицию, для пилота лучше взять другой сценарий.
Осторожный запуск почти всегда лучше быстрого. Рабочая последовательность обычно такая:
- Сначала отделите шаблонную часть промпта от переменной. Кэшируйте системные инструкции, справочные блоки, few-shot примеры и другие куски, которые редко меняются. Текст пользователя, ID заказа, даты и суммы оставьте вне кэша.
- Сразу договоритесь, как вы помечаете промахи кэша. Обычно хватает трёх-четырёх причин: пришёл новый текст, истёк TTL, сменилась версия шаблона, запись не прошла проверку валидности. Без этих меток вы увидите только общий miss rate, но не поймёте, что чинить.
- Запускайте кэш не на всём трафике, а рядом с контрольной группой. На одинаковых запросах сравните расходы, задержку и качество ответа. Если счёт за токены упал, но операторы стали чаще переписывать ответы, пилот ещё не готов.
- Логируйте версию промпта, TTL, хеш шаблонной части и флаг hit или miss. Если трафик идёт через RU LLM, такие метки удобно хранить рядом с аудит-трейлом запроса.
- Не расширяйте покрытие в первый же день. Дайте пилоту прожить хотя бы неделю, включая будни, пики нагрузки и обычные обновления контента.
Если команда может по логам объяснить любой hit и любой miss, кэш готов к следующему этапу.
Пример: поддержка по типовым вопросам
Интернет-магазин запускает бота первой линии. Чаще всего люди спрашивают одно и то же: где заказ, сколько идёт доставка, как оформить возврат. В таком сценарии кэш обычно даёт заметный эффект, потому что большая часть входа повторяется почти без изменений.
Повторяющаяся часть промпта хранит общие правила: тон ответа, запрет на выдуманные обещания, формат коротких шагов для клиента, условия эскалации на оператора. Этот префикс меняется редко, поэтому его удобно кэшировать. Бот не пересчитывает один и тот же длинный ввод на каждом запросе, и команда быстро видит снижение входных токенов на повторных обращениях.
Данные по конкретному заказу в кэш не кладут. Статус, дата доставки, номер отправления и доступность возврата живут отдельно и подтягиваются перед ответом из CRM или OMS. Иначе бот начнёт отвечать вчерашним статусом, а это уже не экономия, а лишние жалобы.
Запрос в таком случае состоит из трёх частей: кэшируемый префикс с правилами и общими политиками, свежие поля по заказу клиента и короткий вопрос пользователя. Такой разрез работает лучше, чем попытка кэшировать всё целиком. Если два клиента спрашивают "Где мой заказ?", общая часть совпадает, но факты по заказам у них разные.
Хороший сигнал после запуска - падение входных токенов на запрос и рост доли попаданий на типовых интентах. Если раньше бот каждый раз отправлял 2000 входных токенов, а после включения кэша на повторных вопросах уходит 500-700, разницу видно и в счёте, и в задержке.
Есть и простое правило обновлений. Как только меняется политика возврата, команда не ждёт истечения TTL, а сразу сбрасывает старую версию префикса. Часто для этого хватает новой версии шаблона, например support_policy_v18. Тогда бот сразу отвечает по новым правилам, даже если остальные части запроса не изменились.
Какие метрики смотреть после запуска
После включения кэша смотрят не на одну цифру, а на связку метрик. Нужно понимать, сколько запросов попало в кэш, сколько денег это сэкономило, не выросла ли задержка и не просело ли качество. Общая доля попаданий часто обманывает: она может расти даже тогда, когда пользователи получают устаревший текст.
Что проверять каждый день
Сначала разбейте трафик по типам запросов. Отдельно считайте FAQ, поиск по базе знаний, шаблонные системные промпты, внутренние инструменты и диалоги с персональными данными. Доля попаданий нужна по каждому типу, а не одной общей строкой. Общие 40% могут выглядеть хорошо, но легко скрывают неприятную картину: FAQ даёт 80%, а персональные кейсы почти не кэшируются.
Рядом держите экономику по дням: сколько входных токенов не ушло в модель и сколько рублей это сохранило. Полезно смотреть две линии сразу - токены и деньги. Если токены падают, а счёт почти не меняется, значит вы кэшируете дешёвые запросы, а не те, что действительно давят на бюджет.
Скорость тоже сравнивают с базой до запуска. Смотрите среднюю задержку и p95 отдельно. Среднее число часто успокаивает, а p95 быстро показывает хвост медленных ответов. Если средняя задержка снизилась на 200 мс, но p95 вырос из-за лишних проверок и промахов, пользователи это заметят.
К качеству лучше привязать простые операционные сигналы: долю ручных правок, число повторных вопросов по той же теме, эскалации на оператора, жалобы на устаревший ответ. Эти метрики не идеальны, зато их легко объяснить команде и бизнесу.
Что показывает, что кэш уже мешает
Тревожный сигнал - жалобы на устаревшие ответы или на слишком похожие формулировки в разных диалогах. Даже редкие жалобы здесь неприятны, потому что бьют по доверию сильнее, чем экономия радует финансы.
Ещё один обязательный срез - промахи по причинам. Обычно хватает пяти категорий:
- истёк TTL
- изменилась версия промпта
- запрос попал в ветку с персональными данными
- поменялись входные параметры
- запись не прошла проверку валидности
Так видно, что именно нужно чинить: менять TTL, пересобирать идентификатор запроса или вообще убирать кэш из чувствительных сценариев. Если вы работаете через RU LLM, причины hit, miss и bypass удобно хранить рядом с аудитом запроса. Через неделю у команды будет не ощущение, а понятная картина: где кэш реально экономит, а где его стоит ограничить.
Частые ошибки
Самая частая ошибка - кэшировать весь диалог целиком. В реальной переписке меняются последние реплики, тон, уточнения и свежие данные. Кэш почти всегда лучше работает на стабильном префиксе: системном промпте, правилах ответа, шаблоне роли, общей инструкции.
Вторая типичная проблема - один TTL для всего. Инструкцию по онбордингу можно держать дольше, а цены, остатки, новости и статус заявки устаревают быстро. Если команда ставит одинаковый срок на все запросы, она либо теряет деньги из-за слишком короткого TTL, либо отдаёт старые ответы там, где это уже риск.
Проблемы обычно начинаются после правки системного промпта без сброса кэша, при работе с живыми данными без отдельной маркировки, когда в ключе нет версии шаблона или источника данных и когда команда смотрит только на hit rate и экономию. Этого мало. Если после запуска выросли жалобы, ручные эскалации или доля исправленных ответов, кэш настроен плохо, даже если счёт за токены стал меньше.
Инвалидация должна идти вместе с версией промпта, а не по памяти команды в конце недели. Отдельно стоит помечать запросы, где модель тянет живые данные: цены, баланс, статус доставки, расписание, новости. Для них кэш либо не нужен, либо нужен очень короткий срок и явный контроль источника.
Быстрый чек-лист перед релизом
Перед включением кэша в проде лучше проверить не только код, но и правила. Большая часть проблем начинается не с Redis, а с того, что команда кэширует слишком разные вещи одним способом.
- Для каждого сценария должен быть свой срок жизни данных. Статья из базы знаний может жить 12 или 24 часа, остаток на счёте - минуты или вообще не должен попадать в кэш.
- У каждого шаблона промпта нужна версия в ключе кэша. Поменяли системную инструкцию, модель, набор инструментов или формат ответа - старая запись больше не подходит.
- Логи должны отдельно считать hit, miss и bypass, а ещё хранить причину промаха.
- Команда заранее решает, кто отключает кэш при инциденте. Нужен понятный owner, флаг для быстрого выключения и простой порядок отката.
- PII не должен попадать в общий кэш. Персональные поля лучше маскировать до записи или вообще держать такие ответы вне shared-cache слоя.
Это особенно важно в саппорте и внутренних помощниках. Ответ на вопрос "как сменить тариф" можно отдавать из кэша, а запрос "покажи мой последний платёж" уже требует другой логики и чаще всего не должен попадать в общий кэш.
Если вы работаете в российском контуре, проверка на PII и аудит нужны не для отчёта. В среде с требованиями 152-ФЗ политика кэша должна совпадать с правилами логирования и маскирования. Для команд, которые используют RU LLM, это особенно удобно держать в одной схеме: маскирование PII, аудит-трейлы и маршрутизация запросов уже не размазаны по разным сервисам.
Если на любой пункт нет точного ответа, не включайте кэш на весь трафик. Начните с одного стабильного сценария и небольшой доли запросов.
Что делать после пилота
После пилота не стоит оставлять кэш "как получилось". Обычно уже за первую неделю видно, где он действительно режет расход, а где начинает портить ответы. Оставляйте кэш только для тех сценариев, где доля попаданий держится на хорошем уровне и при этом не растут жалобы, ручные правки и число повторных запросов.
Дальше разделите правила по типам трафика. Шаблонные запросы вроде типовых вопросов поддержки часто живут с длинным TTL и редкой инвалидацией. RAG-запросы требуют осторожности: если обновилась база знаний, старый ответ может стать неверным. Запросы с живыми бизнес-данными, например статусом заказа, остатками или лимитами, лучше кэшировать очень коротко или не кэшировать вообще.
После пилота полезно зафиксировать рабочие решения в одном месте: версию промпта, где кэш включён и где выключен, TTL для каждого типа запроса, причины инвалидации и метрики, за которыми команда следит после релиза. Такая таблица спасает от путаницы через месяц, когда кто-то меняет промпт, но забывает сократить TTL.
Если трафик уже идёт через единый OpenAI-совместимый шлюз, довести пилот до рабочего режима проще. Например, в RU LLM можно оставить привычные SDK и промпты, а сравнение моделей, маршрутизации и политики кэша держать в одном контуре. Это удобно не само по себе, а потому что быстрее видно источник эффекта: экономию дал кэш, другая модель или сочетание обоих факторов.
Для систем под 152-ФЗ не откладывайте проверку на потом. Сразу убедитесь, что маскирование PII срабатывает до записи в логи, а сами логи и бэкапы хранятся там, где это допускают ваши правила и договоры.
Хороший финал пилота выглядит скучно, и это нормально. У команды есть понятные правила, видно экономию по сценариям, а качество не проседает там, где ошибка бьёт по пользователю или по деньгам.
Часто задаваемые вопросы
Когда prompt caching реально снижает расходы?
Быстрее всего он окупается там, где запросы каждый раз несут длинную одинаковую часть. Обычно это системный промпт, правила ответа, формат вывода, few-shot примеры и справочный контекст, который команда меняет редко.
Если у вас почти весь смысл сидит в свежих данных пользователя, выгода будет слабой. В таких сценариях кэшируйте общий префикс, а не весь запрос целиком.
Что лучше кэшировать в первую очередь?
Начните с стабильной "шапки" запроса: системной инструкции, правил безопасности, шаблона ответа и общих справочных блоков. Ещё хорошо заходят шаблонные задачи вроде классификации, модерации и извлечения полей.
Не пытайтесь сразу кэшировать весь диалог. Сначала вынесите повторяющиеся куски и проверьте, как они влияют на счёт и задержку.
Какие запросы лучше не кэшировать?
Не кладите в общий кэш то, что быстро стареет или зависит от конкретного человека. Сюда попадают статусы заказов, цены, остатки, лимиты, персональные расчёты и ответы по свежим документам.
Плохо работают и живые диалоги, где каждое новое сообщение меняет смысл. Там старый ответ легко выглядит правдоподобно, но даёт неверный совет.
Как выбрать TTL без гадания?
Берите TTL не из удобной цифры, а из скорости изменений в источнике. Если данные живут минуты, ставьте минуты или отключайте кэш. Если инструкция меняется раз в неделю, срок можно делать длиннее.
Простое правило такое: TTL не должен жить дольше, чем интервал между заметными обновлениями. Иначе кэш начнёт возвращать старую логику или старые факты.
Что включать в идентификатор запроса?
Одного текста вопроса мало. В идентификатор обычно кладут версию системного промпта, шаблона, имя модели, формат ответа, нормализованный пользовательский ввод и версию базы знаний, если ответ от неё зависит.
Сразу убирайте служебный шум вроде timestamp и trace_id, но не трогайте поля, которые меняют смысл. Иначе кэш начнёт склеивать разные ситуации.
Есть ли смысл кэшировать RAG-запросы?
Да, но только частично. В RAG есть смысл кэшировать общие инструкции: как отвечать, как цитировать и что делать при нехватке фактов.
Сами найденные документы и ответ по ним лучше привязывать к версии базы, хешу документа или времени индексации. Иначе модель начнёт уверенно цитировать то, что база уже обновила.
Что делать после обновления промпта или шаблона?
Как только вы правите системный промпт, шаблон или правила вывода, сразу меняйте версию в ключе и сбрасывайте старые записи. Не ждите, пока TTL сам всё почистит.
Это особенно важно для саппорта и интеграций с JSON. Даже маленькая правка в инструкции может сломать формат или логику ответа.
Какие метрики стоит смотреть после запуска?
Смотрите не на одну цифру, а на связку: hit rate, экономию на входных токенах, среднюю задержку, p95 и простые сигналы по качеству. Для качества подойдут ручные правки, повторные вопросы, эскалации и жалобы на устаревшие ответы.
Разбивайте метрики по типам трафика. Общая доля попаданий легко маскирует проблему, когда FAQ кэшируется хорошо, а персональные кейсы только создают риск.
Как работать с PII и требованиями 152-ФЗ?
С персональными данными лучше держать строгие правила. Маскируйте PII до записи в лог и не складывайте ФИО, адреса, номера договоров и похожие поля в общий кэш.
Для команд под 152-ФЗ это не формальность. Политика кэша должна совпадать с правилами логирования, хранения и аудита, иначе вы получите не только техническую, но и организационную проблему.
Как безопасно запустить кэш в продакшене?
Запускайте пилот на простом сценарии, где много повторов и ошибка не бьёт по деньгам или договору. Держите рядом контрольную группу, логируйте hit, miss, bypass, версию промпта и причину промаха.
Если команда может объяснить каждый hit и каждый miss, тогда расширяйте покрытие. Если нет, не включайте кэш на весь трафик, даже если счёт за токены уже пошёл вниз.