Сроки хранения логов LLM по 152-ФЗ: схема для команд
Сроки хранения логов LLM по 152-ФЗ: как разделить логи, бэкапы и выгрузки, назначить сроки и дать юристам, DevOps и ML общие правила.
Где обычно начинается путаница
Путаница редко начинается с закона. Она начинается раньше, когда три команды смотрят на один и тот же запрос разными глазами. Юрист видит цель обработки и срок, на который данные вообще нужны. DevOps видит файл, ротацию, бэкап и дату удаления. ML-команда видит материал для разбора ошибок, оценки качества и дообучения.
Из-за этого разговор о сроках хранения логов LLM быстро превращается в спор о словах. Для одной команды "лог" - это запись в центральном журнале. Для другой - дамп из хранилища, снапшот диска или CSV, который аналитик скачал себе "на пару дней". Формально это разные следы, но в рабочих обсуждениях их часто смешивают.
Один пользовательский запрос обычно оставляет данные сразу в нескольких местах:
- в логах приложения и API-шлюза;
- в мониторинге, трассировке и аудит-записях;
- в бэкапах, временных выгрузках и датасетах для разбора.
Здесь команды чаще всего теряют контроль. Они ставят один срок, например 30 или 90 дней, и считают вопрос закрытым. Но у этих копий разная цель и разный жизненный цикл. Лог в SIEM, резервная копия базы и выгрузка для ML-проверки не должны жить по одной схеме только потому, что везде есть фрагмент текста запроса.
Спор обычно вспыхивает не в день запуска, а позже. Пользователь просит удалить данные. Служба ИБ поднимает расследование. Аудит просит показать, кто и зачем смотрел конкретный диалог. И тут выясняется, что часть следов уже стерли, часть лежит дольше нужного срока, а про локальные выгрузки никто не помнит.
Хороший пример - чат-бот банка. Клиент пишет вопрос в мобильном приложении. Дальше текст может пройти через frontend-логи, API-шлюз, сервис оркестрации, аудит, систему мониторинга, бэкапы и отдельную выгрузку для проверки качества ответов. Даже если команда использует единый шлюз, следов меньше не становится. Один слой просто централизуется. Правила хранения все равно нужны для каждого слоя отдельно.
Проблема не в том, что команды спорят. Проблема в том, что у них нет общей карты следов и общего словаря. Пока "лог", "бэкап" и "выгрузка" значат разное для каждого участника, единое правило не появится.
Что считать логом, бэкапом и выгрузкой
Чтобы сроки хранения не превращались в спор терминов, сначала разделите данные по назначению. Один и тот же запрос пользователя может оказаться в нескольких местах, но это не делает все копии "логами". Удобнее смотреть не на формат файла, а на вопрос: зачем эта копия существует.
Лог - это запись о событии в системе. Обычно в нем есть время запроса, идентификатор операции, статус ответа, маршрут к модели, технический контекст и иногда части prompt или ответа. Если в логе хранится текст пользователя, email, номер договора или другой персональный фрагмент, это уже не "чистая техника", а данные с отдельным учетом.
Бэкап - это копия для восстановления после сбоя, ошибки или удаления. Его задача узкая: поднять систему обратно. Если команда открывает бэкап, чтобы искать поведение пользователей, разбирать prompt или строить отчеты, это уже не просто бэкап. Такой массив данных нужно учитывать отдельно.
Выгрузка - это все, что ушло из основной системы в файл, таблицу, объектное хранилище, почту или на ноутбук сотрудника. CSV с чатами для разметки, архив инцидента для подрядчика, датасет для eval, ZIP с логами для внутренней проверки - все это выгрузки. Их чаще всего и забывают, потому что они лежат вне обычного контура очистки.
На практике полезно держать в голове четыре слоя:
- логи приложений, API-шлюза и аудита;
- бэкапы баз, хранилищ и конфигов;
- выгрузки для анализа, разметки, расследований и обмена;
- временные копии: кэш, очереди, dead letter, tmp-файлы, трейсы.
Последний слой часто пропускают. А зря. Кэш с фрагментом ответа модели, очередь с необработанным сообщением, временный файл после OCR или трассировка ошибки в APM могут хранить те же персональные данные, что и основной лог. Если этого слоя нет в схеме, срок хранения никто не контролирует.
Если запросы идут через шлюз вроде RU LLM, следы обычно появляются как минимум в двух местах: в вашем приложении и в самом шлюзе. Это нормально. Важно не путать централизацию с исчезновением данных. У каждой стороны остаются свои журналы, бэкапы и аудит-следы.
Рабочее правило простое. Если копия нужна для восстановления, это бэкап. Если она описывает событие, это лог. Если она ушла жить отдельно, это выгрузка. Все промежуточные хранилища тоже занесите в схему, даже если они живут несколько часов.
Какие поля учитывать отдельно
Если хранить весь запрос к LLM одним JSON-blob, сроки быстро ломаются. В одном объекте смешиваются персональные данные, бизнес-логика, техническая телеметрия и следы контроля. Потом юристы просят удалить одно, DevOps держит другое для расследований, а ML-команда хочет третье для оценки качества.
Практичнее сразу делить поля по смыслу, а не по месту хранения. Для 152-ФЗ это нужно по простой причине: разные категории данных живут по разным правилам, даже если они приехали в одном API-вызове.
Обычно отдельно учитывают пять групп данных.
Текст prompt и ответ модели - самый рискованный слой. Сюда часто попадают ФИО, номера счетов, адреса, жалобы клиентов и свободный текст операторов.
Идентификаторы человека или клиента - user_id, номер договора, email, телефон, внутренний customer_id. Их лучше хранить отдельно от текста, потому что именно они нужны для поиска, удаления и ответа на запрос субъекта данных.
System prompt тоже легко недооценить. В нем могут лежать внутренние правила, фрагменты бизнес-логики, названия внутренних систем и даже примеры с реальными данными.
Технические поля - модель, провайдер, число токенов, стоимость, задержка, коды ошибок, route id - относятся к другому классу данных. Их часто можно держать дольше, если убрать привязку к человеку.
Метки контроля - факт маскирования PII, AI-Law-метки, audit trail, сведения о том, кто и когда вызвал модель, какая политика сработала - нужны для проверок и разбора инцидентов.
Если поле отвечает на другой вопрос, храните его отдельно. Текст нужен для качества и разбора ответов. Идентификаторы нужны для прав субъектов данных. Метрики нужны для биллинга и эксплуатации. Audit trail нужен для контроля и внутреннего расследования.
На практике это означает не одну таблицу logs, а хотя бы несколько слоев хранения. В первом лежит содержимое запроса и ответа. Во втором - связка с пользователем или договором. В третьем - телеметрия без персональных данных. В четвертом - следы срабатывания политик и маскирования.
Если часть запросов идет через RU LLM, в потоке уже могут появляться PII masking, AI-Law-метки и audit trail. Это упрощает учет, но не отменяет его. Команда все равно должна зафиксировать, что удаляется быстро, что обезличивается, а что остается как доказательство выполнения правил.
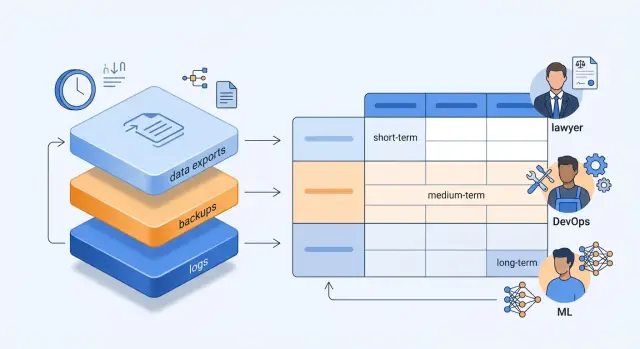
Как собрать матрицу сроков
Один LLM-запрос может оставить след в пяти местах сразу: в приложении, API-шлюзе, системе наблюдения, бэкапе базы и ручной выгрузке для разбора инцидента. Поэтому сроки хранения часто расходятся даже внутри одной компании. Юристы пишут одно, DevOps хранит другое, а ML-команда вообще не знает, что попало в дамп.
Матрицу сроков лучше собирать по всей цепочке, а не только по своему коду. Если в схеме есть шлюз, у запроса могут появиться логи маршрутизации, audit trail, маскированные поля и резервные копии на разных слоях. Их тоже нужно учитывать.
Как ее заполнить
- Перечислите все места, где появляется след запроса. Обычно это access logs, application logs, трассировки, очереди, object storage, дампы БД, тикеты поддержки и ad hoc CSV-выгрузки.
- Для каждого места добавьте три поля: зачем данные нужны, кто отвечает за слой и в каком виде хранится запись. Например: JSON-лог, SQL-таблица, архив, parquet-файл.
- Затем пометьте, где есть персональные данные, а где уже сработало маскирование PII. Лучше делать это по полям, а не по файлу целиком. В одном логе может быть безопасный request_id и рядом рискованное user_message.
- После этого разведите сроки по трем колонкам: рабочий срок, срок в бэкапе и срок для архивной выгрузки. Они почти никогда не совпадают, и это нормально.
- В конце зафиксируйте, что происходит после окончания срока: удаление, анонимизация или удержание на время расследования. У режима удержания должен быть владелец и дата пересмотра. Иначе он станет вечным.
Хорошая матрица не пытается описать все сразу. Ей хватает 8-10 колонок: система, набор данных, цель, владелец, наличие ПД, маскирование, рабочий срок, срок в бэкапе, срок выгрузки, действие после окончания срока.
Простой пример: application logs хранят 30 дней для разбора сбоев, бэкапы этой же системы живут 35 дней, а выгрузка для службы безопасности хранится 90 дней в отдельном контуре. Это уже три разных правила, и каждое нужно оформить отдельно.
Собирайте такую таблицу по реальным данным за последние пару недель. Тогда сразу видно, где команда пишет в лог лишнее, где маскирование не сработало и какие выгрузки никто не учитывал.
Как назначить срок для каждого слоя
Срок нельзя брать "по умолчанию". Один запрос к LLM оставляет несколько следов: рабочий лог, журнал безопасности, бэкап, выгрузку для разбора и иногда датасет для ML. У каждого слоя своя цель, значит, и срок хранения у него свой.
Начинайте не с числа дней, а с причины хранения. Если данные нужны для отладки, держите их столько, сколько команда реально смотрит такие записи. Если они нужны для расчетов, сверок или закрытия инцидентов, срок будет другим. Для аудита срок часто длиннее, но хранить стоит только то, без чего аудит нельзя собрать.
Бэкап не равен рабочему логу. Бэкап нужен, чтобы восстановить сервис, а не читать старые prompt в обычной поддержке. Поэтому ему не нужен тот же статус доступа и тот же порядок продления. Иначе резервная копия незаметно превращается во второй архив персональных данных.
Удобно держать одну таблицу, где рядом стоят цель, срок и действие после окончания срока.
| Слой | Зачем хранится | Кто утверждает срок | Что делать после срока |
|---|---|---|---|
| Рабочий лог запросов | Отладка, разбор ошибок, support | DevOps + владелец сервиса + юрист | Удалить или обезличить |
| Лог безопасности | Расследование инцидентов, контроль доступа | ИБ + юрист | Удалить по регламенту ИБ |
| Бэкап | Восстановление после сбоя | DevOps + ИБ | Автоудаление по политике бэкапов |
| Выгрузка | Разовый разбор кейса, ответ на запрос, проверка | Владелец выгрузки + юрист | Удалить в дату истечения |
| ML-датасет | Оценка, дообучение, тесты | ML-лид + DPO или юрист | Пересобрать без PII или удалить |
У выгрузок дата истечения должна появляться в момент создания файла, а не потом в чате или тикете. Иначе файл уезжает в почту, на ноутбук аналитика или в общий бакет и живет там месяцами. Минимум, который нужен для любой выгрузки: владелец, причина, дата удаления и место хранения.
С датасетами для ML правило еще строже. Если команде нужен набор диалогов или prompt, сначала уберите PII, проверьте поля, которые могут заново идентифицировать человека, и только потом задавайте отдельный срок хранения. Нельзя просто взять продовый лог и назвать его датасетом. Для 152-ФЗ это уже другой объект учета.
Если в архитектуре есть шлюз, где уже встроены маскирование PII и audit trail, разделить слои проще. Но срок и действие после него все равно нужно закрепить в одной таблице, доступной юристам, DevOps и ML-команде.
Пример для чат-бота банка
Если банк подключил чат-бота к LLM через единый API-шлюз, поток данных лучше делить не по командам, а по слоям хранения. Так проще убрать вечный спор о том, что считать логом, что считать копией, а что уже отдельной выгрузкой.
Клиент пишет вопрос в чат банка. Шлюз принимает запрос, передает его в модель и возвращает ответ в интерфейс. На этом одном действии обычно появляются четыре разных следа: техлог запроса, текст диалога, запись в audit trail и резервная копия хранилища.
DevOps почти никогда не нужен сам диалог, чтобы разбирать сбои. Обычно хватает техлогов: время запроса, код ответа, маршрут модели, задержка, размер payload, идентификатор сервиса, trace id. Текст сообщения и ответ модели лучше не держать в этих логах вообще. Тогда техлоги можно хранить столько, сколько они действительно нужны для инцидентов и разбора ошибок.
Для текста диалога срок задают юристы и владелец процесса. Он зависит не от удобства команды, а от цели обслуживания. Если чат помогает по банковскому продукту, срок привязывают к сценарию поддержки, претензиям клиента и внутренним правилам по обращениям. Один и тот же текст нельзя оставлять просто потому, что "вдруг пригодится".
ML-команде почти никогда не нужен полный массив диалогов из продакшена. Для оценки качества и дообучения лучше выдавать очищенную выборку без ФИО, телефонов, номеров договоров, адресов и других прямых идентификаторов. Если у шлюза уже есть PII masking и audit trail, такой контур собрать проще, но сам срок хранения датасета все равно нужно утверждать отдельно.
Для банка обычно работает такая схема:
- техлоги живут отдельно от текста диалога;
- срок для текста утверждает владелец процесса вместе с юристами;
- ML получает только обезличенный датасет под конкретную задачу;
- бэкап живет по своему циклу и не становится складом старых диалогов.
С бэкапами ошибаются чаще всего. Команда удаляет диалог из рабочей базы, но забывает, что его копия еще лежит в резервном контуре. Это нормально, если у бэкапа есть свой срок, свой порядок доступа и понятное правило восстановления. Ненормально, когда резервная копия фактически заменяет архив и в ней начинают искать старые переписки по запросу сотрудников.
Такой подход удобен тем, что у юристов, DevOps и ML-команды появляются разные, но согласованные сроки. И на аудите каждый слой можно объяснить без длинных оговорок.
Кто за что отвечает
Сроки хранения редко ломаются из-за одной большой ошибки. Чаще у каждой команды своя логика: юристы пишут про цели обработки, DevOps думает в TTL и бакетах, ML-команда сохраняет выборки "на потом", а продукт живет от релиза к релизу. В итоге правила есть, но общего порядка нет.
Рабочая схема одна: роли разделены заранее, а спорные случаи не решают в день инцидента.
Юристы фиксируют цель обработки, правовое основание, срок и событие удаления. Они отвечают на вопрос, почему лог хранится 30 дней, а выгрузка по обращению клиента живет дольше или удаляется сразу после разбора.
DevOps переводит эти правила в настройки систем. Команда ставит TTL, настраивает архивы, шифрование, удаление из основных хранилищ и бэкапов. Если копии лежат в трех местах, удаление должно пройти во всех трех.
ML-команда отвечает за датасеты для оценки, тестов и дообучения. У каждого набора должен быть владелец, цель и срок. Временный датасет без хозяина почти всегда остается навсегда.
ИБ управляет доступом к логам и выгрузкам, проверяет audit trail и ведет расследования. Команда должна видеть, кто открыл данные, кто сделал экспорт и кто поменял правило хранения.
Владелец продукта утверждает итоговую матрицу сроков и решает исключения. Если юристы просят хранить дольше, а инженеры хотят быстрее удалять, финальное решение не должно зависеть от того, кто громче в переписке.
На практике больше всего споров вызывает граница между логом и рабочей выгрузкой. Например, ML-инженер сохраняет диалоги для проверки качества, а DevOps считает это временным файлом. Если продукт заранее не назначил владельца, такой файл выпадает из общей схемы.
Если компания работает через RU LLM, часть контроля уже можно опереть на встроенные audit trail, PII masking и хранение в российском контуре. Но сроки и удаление для внутренних витрин, бэкапов и ручных выгрузок компания все равно задает сама.
Где команды чаще ошибаются
Больше всего проблем создают не сами сроки, а копии данных, про которые все забывают через неделю. Юристы думают про основания хранения, DevOps - про бэкапы, ML-команда - про качество и отладку. А персональные данные в это время живут сразу в нескольких местах.
Первая частая ошибка - считать, что маскирование решает вопрос навсегда. Не решает. Если команда один раз записала исходный запрос в сырой лог, потом замаскировала его в витрине и успокоилась, исходные данные все равно могут лежать в трассировке, дампе или временном файле. Маскирование снижает риск, но не отменяет срок хранения и удаление исходников.
Вторая ошибка выглядит буднично, поэтому ее долго не замечают. Инженер берет кусок боевых логов, чтобы проверить prompt или сравнить модели, а потом файл остается на ноутбуке или в тестовом хранилище без срока удаления. Через месяц про него никто не помнит. Через полгода этот же файл попадает в новую выборку для обучения или в архив команды.
Отдельная беда - дампы БД, object storage и почтовые вложения. Их редко включают в общую политику хранения, хотя там лежат те же идентификаторы, тексты запросов, номера заявок и служебные метки. CSV и Parquet особенно опасны: файл легко скачать, легко переслать дальше, а дату удаления и владельца обычно никто не указывает.
Тревожные признаки почти всегда одинаковые:
- у выгрузки нет владельца;
- у файла нет даты удаления;
- тестовое хранилище живет дольше основного;
- дампы БД не попали в матрицу сроков;
- удаление в системе считают удалением из бэкапов.
Последняя ошибка съедает больше всего времени. Команда удаляет запись из рабочей базы и считает задачу закрытой, хотя та же запись остается в резервных копиях до конца цикла хранения. Это не значит, что бэкапы нужно чистить вручную по одному объекту. Это значит, что нужен понятный срок жизни копий, запрет на свободные выгрузки из резервного контура и правило, кто проверяет восстановление после истечения срока.
Короткий чек-лист перед релизом
Перед релизом лучше поймать спорные места на одной странице, чем разбирать их после инцидента. Для сроков хранения логов LLM это особенно полезно: юрист смотрит на основание и срок, DevOps - на хранилище и удаление, ML-команда - на полезность данных для отладки и оценки.
Проверьте хотя бы пять вещей:
- для каждого следа назначен владелец;
- для каждого хранилища записан срок хранения и способ удаления;
- команда знает, кто имеет право делать выгрузки персональных данных;
- маскирование PII включено до записи в лог;
- для расследований есть отдельное правило удержания.
Мало написать "30 дней" или "90 дней". Нужно понять, чем срок заканчивается: автоочисткой, удалением по job, ротацией снапшотов или ручной процедурой с подтверждением.
Отдельно проверьте маршрут файла после выгрузки: где он создается, куда попадает, как шифруется, сколько живет и кто его удаляет. Если сначала сохранить сырой prompt, а потом чистить его отдельным скриптом, это уже лишний риск. Такую схему лучше убрать до релиза.
Быстрый тест выглядит просто. Возьмите один реальный пользовательский запрос и пройдите его путь до конца: приложение, LLM-шлюз, логи, бэкап, выгрузка для разбора, удаление. Если на любом шаге никто не может назвать владельца, срок или место хранения, релиз лучше остановить и дописать схему.
Что делать дальше
Начните с одной таблицы, которую читают все: юристы, DevOps, ML и ИБ. Если у каждой команды свой файл со сроками, спор начнется на первом же запросе на удаление. В общей таблице обычно хватает шести колонок: что хранится, где хранится, зачем хранится, сколько хранится, кто отвечает, как удаляется.
Потом проверьте реальный маршрут данных, а не схему в голове. LLM-запрос почти всегда оставляет следы в нескольких местах: в логах приложения, в логах шлюза, в бэкапах, во временных выгрузках для анализа и в audit trail. Команды обычно хорошо знают основной контур, но забывают про отладочные дампы, S3-архивы, CSV для аналитиков или тестовые копии в отдельном бакете.
Дальше полезно пройти короткий рабочий цикл:
- Зафиксируйте все точки записи для одного тестового запроса с персональными данными.
- Сверьте для каждой точки срок, основание хранения и владельца.
- Запустите удаление этого запроса по всей цепочке, включая бэкапы и ручные выгрузки.
- Сохраните результат в регламенте и добавьте эту проверку в релизный чек-лист.
Тестовое удаление лучше делать заранее, а не в день инцидента или запроса от субъекта ПДн. На таком прогоне быстро видно слабые места: лог удалили, а бэкап остался; запись исчезла из основной БД, но сохранилась в выгрузке для ML-команды; срок в политике один, а TTL в хранилище другой.
Если вам нужен единый OpenAI-совместимый слой в РФ, стоит отдельно проверить, как в нем устроены маршрутизация, логи, бэкапы, PII masking и audit trail. Например, в RU LLM на rullm.com это уже собрано в одном контуре с хранением внутри РФ. Это не заменяет вашу внутреннюю политику хранения, но уменьшает число разрозненных точек учета.
Нормальный результат на этом этапе выглядит просто: у вас есть одна матрица сроков, один владелец на каждый слой и один проверенный сценарий удаления. Если этого еще нет, не пишите новую политику на 20 страниц. Сначала найдите все места, где запрос живет дольше, чем вы думаете.
Часто задаваемые вопросы
С чего начать, если у юристов, DevOps и ML свои сроки хранения?
Начните с одной таблицы на всю цепочку запроса. Впишите в нее каждое место, где появляется след: приложение, шлюз, аудит, мониторинг, бэкапы, ручные выгрузки и временные файлы.
Для каждой точки сразу укажите цель хранения, владельца, наличие персональных данных, срок и действие после срока. Когда все смотрят на одну схему, спор про термины быстро уходит.
Чем лог отличается от бэкапа и выгрузки?
Лог описывает событие: время запроса, код ответа, route id, trace id, ошибки. Бэкап нужен только для восстановления системы после сбоя или удаления.
Выгрузка живет отдельно от основной системы: CSV, архив, parquet, файл на ноутбуке, объект в бакете. Если копия ушла в отдельное место для разбора, разметки или отчета, считайте ее выгрузкой и задайте ей свой срок.
Можно ли поставить один срок на все следы LLM-запроса?
Нет, так делать рискованно. У техлога, резервной копии и выгрузки разная цель, поэтому и срок у них обычно разный.
Если поставить одно число на все, часть данных вы удалите слишком рано, а часть будете держать дольше нужного. Лучше развести рабочий срок, срок в бэкапе и срок для выгрузок.
Какие поля в запросах к LLM лучше учитывать отдельно?
Разделите хотя бы пять групп: текст prompt и ответа, идентификаторы пользователя, system prompt, техметрики и audit trail. Тогда вы сможете удалять или обезличивать только то, что реально нужно убрать.
Особенно полезно хранить отдельно user_id, email, номер договора и другие идентификаторы. Они нужны для поиска и удаления, а техметрики вроде токенов, модели и задержки часто можно держать дольше без привязки к человеку.
Что делать с бэкапами, если пользователь просит удалить данные?
Удаление из рабочей базы не равно удалению из бэкапа. Для резервных копий нужен свой срок жизни, свой порядок доступа и запрет на свободный поиск старых диалогов.
Обычно команда не чистит бэкап по одному объекту вручную. Она задает понятный цикл хранения, ждет его окончания и контролирует, чтобы после срока копия исчезла автоматически.
Нужен ли отдельный срок хранения для датасетов ML-команды?
Да, нужен. Продовый лог и ML-датасет решают разные задачи, поэтому их нельзя учитывать как один и тот же массив.
Сначала уберите PII и проверьте поля, которые могут снова вывести на человека. Потом назначьте владельца датасета, цель и дату удаления, иначе временная выборка останется навсегда.
Кто должен утверждать сроки хранения и следить за ними?
Юрист или DPO задает основание, цель и событие удаления. DevOps переводит это в TTL, ротацию, автоудаление и правила для бэкапов.
ML-лид отвечает за выборки и датасеты, ИБ контролирует доступ и экспорт, а владелец продукта утверждает итоговую матрицу. Если одного владельца нет, правило быстро разваливается.
Достаточно ли включить маскирование PII и успокоиться?
Маскирование заметно снижает риск, но не закрывает вопрос само по себе. Если сырой текст уже попал в лог, трассировку, дамп или временный файл, он там и останется, пока вы не удалите исходную копию.
Ставьте маскирование до записи в лог и отдельно проверяйте все места, где система пишет сырой запрос. Иначе вы защитите витрину, а не источник.
Какие копии данных команды чаще всего забывают включить в матрицу сроков?
Чаще всего забывают про временные файлы, очереди, dead letter, APM-трейсы, дампы БД, object storage и ad hoc CSV для разбора. Еще часто выпадают почтовые вложения и файлы на ноутбуках сотрудников.
Простой признак риска такой: у файла нет владельца и даты удаления. Если это так, копия почти наверняка живет дольше, чем вы планировали.
Как быстро проверить схему хранения перед релизом?
Возьмите один реальный запрос и пройдите весь его путь от приложения до удаления. Проверьте, кто владеет каждым слоем, где лежат данные, сколько они живут и что именно система удаляет в конце срока.
Если на любом шаге команда не может назвать срок, место хранения или ответственного, релиз лучше притормозить. Такая проверка быстро находит лишние логи, забытые выгрузки и расхождения между политикой и настройками.