Задержка в LLM-запросе: куда уходит время по шагам
Задержка в LLM-запросе складывается не только из времени модели. Разберем сеть, токенизацию, очередь, вызовы инструментов и постобработку.
Что пользователь считает медленным ответом
Почти всегда все решает первая пауза. Если интерфейс молчит 2-3 секунды, пользователь считает ответ медленным, даже когда дальше текст идет быстро. Обратная ситуация переносится легче: первый токен пришел сразу, а длинный ответ допечатывается еще несколько секунд.
Из-за этого команды часто ищут проблему не там. В логах модель уложилась в норму, а жалобы все равно идут. Значит, задержка сидит в другом месте: в сети, в tool-вызове, в повторном запросе после таймаута или в постобработке перед показом текста.
Медленным обычно кажется один из четырех сценариев: индикатор печати долго висит до первого символа, ответ стартует быстро и замирает на внешнем инструменте, один и тот же промпт то работает мгновенно, то внезапно тормозит, или в логах модели все чисто, а пользовательский путь все равно ощущается тяжелым.
Самый неприятный случай - долгий вызов tool. Модель может собрать план за 400 мс, но один запрос в поиск, CRM или внутреннюю базу легко добавит 2-5 секунд и испортит диалог. Пользователю не важно, где именно возникла пауза. Он видит одно: ассистент завис.
Сеть тоже часто маскирует причину. Короткий ретрай на клиенте, прокси или балансировщике добавляет секунду-другую, а в логах самой модели этого нет. В итоге разработчики спорят о выборе модели, хотя она вообще не главный источник задержки.
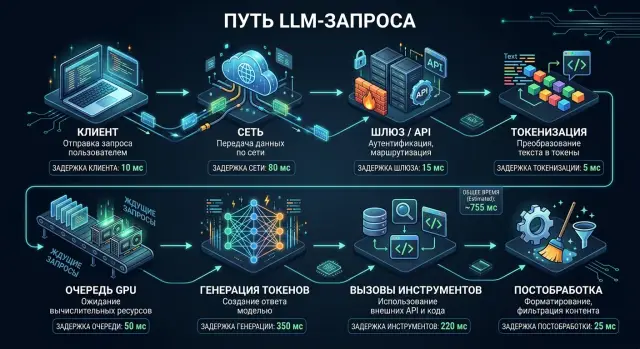
Поэтому полезно размечать путь запроса по этапам: прием на входе, токенизация, время первого токена, tool-вызовы, постобработка и отправка ответа клиенту. Без такой разбивки команда почти всегда чинит не то. Для стека с единым шлюзом, вроде RU LLM, это особенно заметно: маршрут запроса, выбранного провайдера и внешние инструменты лучше смотреть отдельно, иначе общая цифра мало что объясняет.
Из чего состоит бюджет задержки
Общее время ответа почти всегда вводит в заблуждение. Пользователь видит один ответ, но миллисекунды теряются в разных местах, и каждый участок ломается по-своему.
Обычно бюджет задержки состоит из клиентской сети и установки соединения, API-шлюза или reverse proxy, сборки промпта и токенизации, очереди на инференс, prefill, генерации выходных токенов, tool-вызовов, поиска по базе и финальной постобработки. Если держать все это в одной строке latency, половина картины просто исчезает.
TTFT и полный ответ
Одной метрики мало. Нужны как минимум две: время до первого токена и время до полного ответа.
Время до первого токена включает сеть, шлюз, токенизацию, очередь и prefill. Если первый токен приходит за 600 мс, а весь ответ заканчивается через 5 секунд, сеть обычно ни при чем. Значит, тормозит длинная генерация, медленный tool или поиск по базе.
Полное время считают отдельно, потому что после первого токена работа не заканчивается. Модель продолжает генерировать текст, может сходить во внешний инструмент, дождаться SQL-запроса или поиска по векторной базе, а затем пройти финальные проверки.
Tools и retrieval лучше выносить в свои строки бюджета. Один вызов CRM на 1.8 секунды легко съедает больше времени, чем сама модель. Если прятать его внутри общей цифры, команда начинает "ускорять LLM", хотя проблема живет в backend.
Постобработку тоже не стоит смешивать с моделью. Валидация JSON, маскирование PII, аудит-трейлы, запись логов и рендер в интерфейсе добавляют десятки, а иногда и сотни миллисекунд. В сценариях с российскими требованиями это заметно особенно хорошо. Например, в RU LLM маскирование PII, AI-Law метки и хранение логов внутри РФ встроены в путь запроса, поэтому эти шаги лучше считать отдельно, а не списывать на модель.
Как измерить путь запроса по шагам
Если смотреть только на общее время ответа, причину роста задержки вы не увидите. Нужна трассировка по этапам: кто принял запрос, когда модель начала генерацию, сколько заняли tools и что произошло после ответа модели.
Самый практичный подход - ставить метки времени в трех местах: на клиенте, на шлюзе и после каждого внешнего шага. На клиенте видно полное время глазами пользователя. На шлюзе понятно, сколько ушло на прием, маршрутизацию, ретраи и отправку к модели. Метки после каждого tool сразу показывают, кто тормозит на самом деле: база, поиск, RAG-сервис, OCR или сама модель.
Для каждого запроса полезно писать один и тот же набор полей:
- время отправки запроса, время первого токена и полное время ответа
- размер промпта, число входных токенов и число выходных токенов
- длительность каждого tool-вызова отдельно
Эти данные быстро показывают перекосы. Два запроса могут длиться по 8 секунд, но в одном случае модель долго стартует, а в другом 6 секунд уходит на поиск по внутренней базе.
Среднее значение почти всегда приукрашивает картину. Смотрите p50, p95 и самые длинные хвосты отдельно. p50 показывает обычный день, p95 - плохой, но еще рабочий сценарий. А самые медленные запросы часто вскрывают таймауты, повторные попытки и тяжелые промпты, которые среднее просто прячет.
Сравнивать модели тоже нужно аккуратно. Берите один и тот же промпт, один регион, одинаковые параметры генерации и тот же набор tools. Иначе вы сравните не модели, а условия. Если команда использует API-шлюз вроде RU LLM, полезно держать одну схему логов на уровне шлюза. Так проще увидеть разницу между провайдерами и понять, где утекает бюджет задержки: в маршрутизации, в длинном контексте или во внешних вызовах.
Минимальная схема событий может быть совсем простой: request_started, gateway_received, model_request_sent, first_token_received, tool_started, tool_finished, last_token_received, response_sent. Уже этого хватает, чтобы перестать спорить по ощущениям и начать чинить конкретный этап.
Где сеть съедает миллисекунды
Сеть часто тормозит запрос еще до того, как модель получила промпт. Когда команда видит "медленный LLM", время нередко ушло на DNS, TCP, TLS и цепочку промежуточных узлов, а не на генерацию.
Одна из самых частых ошибок - открывать новое TCP/TLS-соединение на каждый запрос. На стенде это почти незаметно. В проде лишние рукопожатия легко добавляют сотни миллисекунд, особенно если запрос проходит через несколько сетевых слоев.
Если в пути стоят прокси, WAF и балансировщик, не складывайте все в одну цифру network. Смотрите путь по частям: сколько занял выход из клиента, сколько добавил региональный маршрут, что дал прокси, сколько времени ушло на WAF и балансировщик. Иначе легко обвинить модель, хотя она начала отвечать быстро.
В инфраструктуре вроде RU LLM это тоже важно. Команда меняет base_url на api.rullm.com, сохраняет тот же SDK, код и промпты, но сетевой путь становится другим. Это нормально. Ненормально, когда никто не видит, на каком узле появилась лишняя задержка.
Что мерить отдельно
Хорошая трассировка обычно делит сетевую часть так:
- время до установки соединения
- время TLS-рукопожатия
- время до первого байта от шлюза
- время до первого токена от модели
- общее время стрима до конца ответа
Это не бюрократия, а способ не путать разные проблемы. Сетевой таймаут и время модели нельзя писать в одно поле. Если соединение зависло на входе, это сеть. Если первый токен пришел поздно после быстрого TTFB, причину нужно искать уже в модели, маршрутизации или tools.
При стриминге особенно полезно разделять первый байт и первый токен. Первый байт показывает, что серверная цепочка жива и начала отдавать ответ. Первый токен показывает, когда модель реально начала генерацию. Между ними иногда и прячется вся причина задержки.
Простой пример: пользователь ждет 2.2 секунды. До первого байта прошло 450 мс, до первого токена - 1.4 с. Значит, сеть и входной слой съели часть бюджета, но основная пауза появилась уже после приема запроса.
Что происходит до первого токена
Пока пользователь ждет, модель еще ничего не сгенерировала. Сервер сначала собирает весь пакет: системный промпт, историю диалога, фрагменты из RAG, инструкции для tools и формат ответа. Потом он токенизирует этот текст. Если системный промпт разросся до нескольких страниц, а поиск подставил 6-8 больших чанков, время первого токена вырастет еще до обращения к модели.
Многие смотрят только на длину ответа и пропускают длину входа. Это типичная ошибка. Модель читает весь вход целиком на этапе prefill, и именно он часто съедает больше времени, чем генерация короткого ответа. Вопрос на одну строку может ждать дольше, чем абзац вывода, если перед ним стоит тяжелый контекст.
Строгий JSON тоже добавляет задержку. Когда вы требуете точную схему с вложенными полями, перечислениями и длинными описаниями, сервер передает модели больше служебного текста. Модель сначала обрабатывает этот контракт, и только потом выдает первый символ. Поэтому короткий ответ вида {"status":"ok"} не означает быстрый старт.
Отдельная статья расходов - очередь на GPU. Если провайдер перегружен, запрос сотни миллисекунд или дольше просто ждет свободный слот. Снаружи это выглядит как "медленная модель", хотя проблема не в генерации. В системах с маршрутизацией разница особенно заметна: две модели с похожим качеством могут сильно отличаться именно по старту ответа.
Обычно до первого токена время уходит на сбор сообщений и служебных инструкций, токенизацию входа, prefill по длинному контексту, ожидание очереди на GPU и разбор схемы ответа, если включен строгий JSON.
Если TTFT внезапно вырос, сначала режьте вход. Сократите системный промпт, уменьшите число чанков из RAG, упростите JSON-схему. Эти меры нередко дают больше, чем переход на "более быструю" модель.
Почему tools тормозят сильнее модели
Модель часто выглядит виноватой, но задержку нередко создают tools. Сам вызов модели может занять меньше секунды до первого токена, а поиск, SQL-запрос или внешний API легко добавляют еще 1-3 секунды. На p95 разница обычно становится еще заметнее.
Причина простая: tool почти всегда зависит от сети, чужой системы и очередей вне вашего контроля. Модель работает в одном более предсказуемом контуре, а tools тянут за собой DNS, TLS, прокси, базу, кеш, авторизацию и повторные попытки. Если таких вызовов несколько, задержка быстро складывается.
Частая ошибка - запускать tools последовательно, хотя они не зависят друг от друга. Если ассистент отдельно идет в поиск по базе знаний, потом в SQL, а потом во внешний API, вы платите суммой всех задержек. Когда эти шаги можно пустить параллельно, общий ответ часто сокращается почти до времени самого медленного вызова, а не всей цепочки.
Пример простой. Модель думает 700 мс, поиск по индексу занимает 1.8 с, SQL - 900 мс, внешний API - 2.4 с. При последовательном запуске пользователь ждет почти 6 секунд еще до нормального ответа. При параллельном - около 3 секунд, если оркестрация не вставляет новые паузы.
Отдельная проблема - ретраи и длинные таймауты. Один нестабильный сервис может растянуть весь ответ вдвое. Лучше заранее задать жесткие пределы и решить, что система делает при сбое: отвечает с неполными данными, пропускает источник или просит уточнить запрос.
При диагностике стоит проверить четыре вещи:
- какие tools идут друг за другом без реальной причины
- у каких вызовов самый высокий p95 и p99
- где ретраи срабатывают слишком часто
- какие таймауты длиннее, чем польза от этого tool
И еще одно правило, которое часто игнорируют: не пишите все в одну строку как model latency. Логируйте время каждого tool отдельно - старт, завершение, таймаут, число ретраев, размер ответа. Иначе команда будет "ускорять модель", хотя миллисекунды уходят в поиск, SQL или внешний сервис. Даже при быстрой маршрутизации через один gateway узким местом обычно оказывается не модель, а цепочка tools вокруг нее.
Что добавляет постобработка
Модель может уже закончить генерацию, а пользователь все еще ждет. Часто последние 50-300 мс уходят не на инференс, а на код после него.
Самый частый скрытый расход - проверка формата. Если вы просите строгий JSON, сервис обычно валидирует ответ, ловит сломанные поля и иногда отправляет запрос на повторную генерацию. Один такой повтор быстро съедает весь выигрыш от быстрой модели, особенно когда время первого токена и так низкое.
Отдельно стоит считать шаги, связанные с безопасностью и учетом. Маскирование PII, запись логов, аудит и добавление служебных меток дают небольшую, но заметную прибавку. В RU LLM эти этапы встроены в путь запроса, поэтому их лучше видеть как отдельную строку бюджета, а не относить к "медленной модели".
На длинных ответах начинает тормозить и форматирование. Когда код превращает сырой текст в Markdown, HTML или таблицу, он часто делает лишние проходы по строке, экранирует символы, чинит разметку и проверяет структуру. На ответе в пару абзацев это почти незаметно. На большом отчете или сводной таблице разница уже видна.
После модели чаще всего прячутся валидация JSON и повторный запрос после ошибки, маскирование чувствительных данных, запись логов и аудит-трейлов, форматирование ответа для UI или API, а также обрезка, склейка и очистка текста.
Последний пункт команды нередко вообще не считают. Например, модель вернула 12 тысяч символов, а приложение потом режет ответ до лимита, склеивает куски из нескольких вызовов или удаляет служебные блоки. Пользователь видит только финальный текст, но в бюджет задержки это уже добавило свои миллисекунды.
Практика простая: ставьте таймер не только вокруг вызова модели, но и вокруг каждого шага после нее. Иначе вы будете "ускорять" маршрутизацию или выбор провайдера, хотя задержка сидит в JSON-парсере, фильтрах и форматтере.
Пример: чат-ассистент с поиском по базе
Клиент банка пишет в чат: "Где завис мой перевод?" Снаружи это выглядит как медленный ответ модели. Но если разложить путь по шагам, картина быстро меняется.
Допустим, запрос идет через API-шлюз, потом модель читает историю диалога, затем ассистент ищет данные по переводу и дергает внутренний tool со статусом операции. По таймингам получается так:
- сеть и шлюз - 120 мс
- prefill модели - 700 мс
- поиск по базе - 350 мс
- tool статуса перевода - 1.4 с
- генерация ответа после tool - около 250 мс
Итого пользователь ждет почти 3 секунды. При этом сама модель не выглядит главной проблемой. До вызова tool она уже потратила заметное время на prefill, но самый длинный участок сидит во внутреннем backend.
Это и есть частая ловушка. Команда видит долгий ответ и первым делом хочет менять модель, ужимать промпт или перенастраивать маршрутизацию. Иногда это помогает, но не здесь. Даже если вы срежете у модели 300 мс, клиент все равно будет ждать дольше 2.5 секунды. Разница почти не ощущается.
А вот ускорение backend меняет опыт сразу. Если сервис статуса отвечает не за 1.4 секунды, а за 300-400 мс, общий отклик падает почти вдвое. Пользователь замечает это без графиков и дашбордов.
Такой разбор полезен еще и потому, что переводит разговор из спора в измерение. Для банка это особенно удобно: можно отдельно смотреть сеть, отдельно LLM, отдельно поиск и отдельно внутренние сервисы. Тогда понятно, где нужен prompt caching, где стоит уменьшить контекст, а где пора чинить старый сервис статусов.
Ошибки, которые искажают замеры
Самая частая ошибка проста: команды сравнивают разные запросы так, будто это один и тот же тест. Один прогон идет с коротким промптом, другой - с длинным контекстом. Где-то температура 0, где-то 0.7. Потом меняют max_tokens и удивляются, почему "модель стала медленнее". На деле вы уже сравниваете разные нагрузки.
Если нужен честный замер, фиксируйте входные условия. Один и тот же промпт, одна и та же модель, одинаковые параметры генерации, одинаковый набор tool-вызовов. Иначе цифры выглядят точными, но не объясняют ничего.
Средняя задержка тоже часто врет. В нее любят складывать холодный старт, ретраи, fallback на другую модель и обычные быстрые запросы. Получается красивая цифра, которая скрывает реальное поведение системы. Пользователь не живет в среднем. Он попадает либо в быстрый путь, либо в медленный.
Поэтому полезно разделять хотя бы такие случаи:
- теплый и холодный старт
- запрос без ретрая и запрос с ретраем
- ответ основной модели и ответ после fallback
- время до первого токена и полное время ответа
Еще одна ловушка - мерить только сервер. Если вы смотрите лишь на backend span, вы не видите DNS, TLS, задержку мобильной сети, буферизацию в браузере и поведение SDK. Иногда сервер отдал первый токен за 700 мс, а пользователь увидел его через 1.4 секунды. Для продукта это две разные истории.
Путает картину и общий график latency без разбиения по этапам. В одном числе смешиваются маршрутизация, работа модели, tool-вызовы и постобработка. После такого графика команда спорит уже не о причине, а о том, кому что кажется более вероятным.
Если вы используете шлюз вроде RU LLM, записывайте отдельно время выбора маршрута, выбранного провайдера, время модели и время внешних инструментов. Иначе легко решить, что тормозит сам gateway, хотя большую часть задержки дал поиск по базе или fallback на другого провайдера.
Хороший замер не сводится к одному числу. Он показывает, где именно ушли миллисекунды и можно ли их вернуть.
Проверка перед релизом
Перед релизом лучше смотреть не на среднюю задержку, а на путь запроса целиком. Если команда видит только фразу "ответ пришел за 7 секунд", она не поймет, где ушло время: в сети, в модели, во внешнем tool или уже после генерации.
Минимальный набор метрик стоит держать раздельно. Первый байт показывает, когда сервер начал отвечать. Время первого токена помогает понять, как быстро модель дошла до генерации. Полный ответ нужен отдельно, потому что длинный вывод может казаться медленным даже при хорошем старте.
Перед выкладкой полезно проверить несколько вещей:
- для каждого сценария есть свой бюджет задержки по этапам
- в логи попадают размер промпта, число входных и выходных токенов, а не только статус и общее время
- команда знает самые медленные tools и смотрит их p95
- на дашборде видно, где растет задержка: до модели, до первого токена или на хвосте ответа
Такой разрез быстро отрезвляет. Поиск по базе может занимать 1.8 с на p95, rerank - еще 600 мс, а модель давать первый токен за 900 мс. Если смотреть только на полный ответ, очень легко обвинить модель и потратить неделю не туда.
Если вы используете единый OpenAI-совместимый шлюз, как RU LLM, полезно сохранять один и тот же набор полей в логах для всех провайдеров. Тогда бюджет задержки можно сравнивать честно, без ручной сверки и догадок.
Нормальная проверка перед релизом отвечает на простой вопрос: где именно ломается ожидаемое время для каждого сценария. Когда это видно по шагам, оптимизация превращается в обычную инженерную задачу, а не в спор по ощущениям.
Что делать дальше
Не пытайтесь ускорить все сразу. Возьмите один частый сценарий, который люди запускают каждый день, и снимите полный таймлайн: клиент, сеть, токенизация, модель, tools, постобработка и отдача ответа. Если смотреть только на среднее время, вы почти всегда чините не то.
Лучше взять реальный запрос, а не синтетический тест. Например, вопрос к чат-ассистенту с поиском по базе и коротким итогом для пользователя. У такого сценария сразу видно, где растет задержка: до первого токена, на вызове инструмента или уже после генерации.
Практический порядок простой:
- зафиксируйте один промпт, один размер контекста и один ожидаемый формат ответа
- снимите тайминг по шагам, а не только общее число в конце
- найдите самый длинный этап и сокращайте сначала его
- потом прогоните тот же запрос через несколько моделей и провайдеров
Обычно команды тратят недели на обсуждение сети или модели, хотя больше всего времени уходит в tools или в медленный поиск по базе. Если tool забирает 1800 мс, а модель - 700 мс, нет смысла спорить о 50 мс на токенизации. Сначала уберите то, что дает заметный выигрыш.
Полезно сравнивать не только модели, но и маршрут до них. Один и тот же запрос может давать разное время первого токена у разных провайдеров, даже если модель формально одна и та же. Поэтому тест стоит повторять на одинаковой нагрузке и с одинаковыми параметрами.
Если вам нужен единый OpenAI-совместимый endpoint в РФ, такой прогон удобно делать через RU LLM. Достаточно сменить base_url на api.rullm.com и оставить те же SDK, код и промпты. Так проще сравнить задержку, провайдеров и маршрутизацию без лишнего шума в тесте.
Хороший результат на этом этапе выглядит просто: у вас есть таблица по шагам, понятный самый дорогой участок и следующий эксперимент, который можно сделать сегодня.
Часто задаваемые вопросы
Что пользователь обычно считает медленным ответом?
Обычно пользователь считает ответ медленным, если интерфейс молчит дольше 2–3 секунд до первого символа. Если первый токен приходит быстро, люди легче терпят даже длинный стрим до конца.
С чего лучше начинать разбор задержки?
Начните с разметки пути запроса по этапам, а не с замены модели. Отдельно померьте клиент, сеть, шлюз, время до первого токена, каждый tool и шаги после модели. Тогда сразу видно, где пропадают миллисекунды.
Какие метрики нужно смотреть кроме общего времени?
Одного общего latency мало. Смотрите хотя бы TTFT — время до первого токена — и полное время ответа. Если используете внешние инструменты, пишите их длительность отдельно, иначе backend легко спрячется внутри общей цифры.
Почему в логах модель быстрая, а пользователи все равно жалуются?
Так бывает часто. Модель могла ответить быстро, а паузу дали ретрай на клиенте, медленный tool, поиск по базе, валидация JSON или рендер в интерфейсе. Пользователь видит весь путь целиком, а не только время инференса.
Что сильнее всего влияет на время до первого токена?
Чаще всего TTFT растет из-за длинного входа. Раздутый системный промпт, много чанков из RAG, строгая JSON-схема и очередь на GPU дают паузу еще до генерации ответа. Поэтому сначала режьте вход, а не только выход.
Как понять, что тормозит сеть, а не модель?
Проверьте путь до модели по частям. Если много времени уходит на DNS, TCP, TLS или до первого байта от шлюза, причина в сети или промежуточных узлах. Если сеть быстрая, а первый токен приходит поздно, ищите проблему в маршруте, модели или tools.
Почему tools часто тормозят сильнее самой модели?
Внешние инструменты зависят не только от вас. Они тянут сеть, авторизацию, базу, кеш и повторные попытки, поэтому один вызов CRM или SQL легко съедает больше времени, чем сама модель. Еще хуже, когда система запускает такие вызовы друг за другом без нужды.
Что можно ускорить быстро, не меняя модель?
Обычно помогает простая гигиена. Сократите системный промпт, уменьшите контекст из RAG, упростите JSON-схему, держите соединения открытыми и запускайте независимые tools параллельно. Еще задайте короткие таймауты, чтобы один медленный сервис не тянул весь ответ вниз.
Почему среднего времени ответа недостаточно?
Среднее прячет неприятные хвосты. Один и тот же сервис может выглядеть нормальным по avg, но ломать опыт на p95 и p99 из-за ретраев, fallback или тяжелых промптов. Для продукта полезнее видеть обычный запрос и плохой, но реальный сценарий отдельно.
Что стоит проверить перед релизом LLM-сценария?
Перед релизом прогоните один реальный сценарий и снимите полный таймлайн. Убедитесь, что логи пишут размер промпта, число входных и выходных токенов, TTFT, полное время, выбранного провайдера и длительность каждого tool. После такой проверки вы чините конкретный этап, а не спорите по ощущениям.