Удаление документа из RAG без следов в ответах на практике
Покажем, как провести удаление документа из RAG: очистить индекс, кэш и цитаты, а затем проверить систему контрольными запросами.
Почему следы остаются после удаления
Удалить файл из хранилища недостаточно. В RAG документ почти никогда не существует в одном экземпляре. Система успевает разбить его на чанки, построить эмбеддинги, записать метаданные и сохранить части ответа в кэше. После этого исходный PDF или DOCX уже не единственное место, где живет текст.
Самая частая причина проста: бот ищет не по файлу, а по индексу. Если команда стерла документ из бакета или CMS, старые чанки могут остаться в векторной базе. Этого уже хватает, чтобы поиск продолжал находить фрагменты. Модель видит прежние заголовки и отвечает так, будто документ никто не трогал.
Проблему усиливает задержка обновления индекса. В одних системах удаление проходит по расписанию, в других нужен отдельный job на reindex или purge. Пока он не отработал, поиск продолжает возвращать старые куски. Пользователь видит это как "бот все еще помнит удаленный файл", хотя след остался не в модели, а в слое retrieval.
Кэш дает второй тип следов. Многие команды кэшируют готовые ответы, найденные чанки или результаты rerank, чтобы снизить задержку и цену запроса. Тогда новый вопрос может вообще не дойти до свежего поиска. Система достает старый ответ и отдает его как есть.
Есть и третий слой проблемы - цитаты и названия источников. Их часто хранят рядом с чанком, в таблице метаданных или в логах диалога. Даже если сам текст больше не находится, интерфейс может по-прежнему показывать "Регламент отпусков 2023" или кусок старой цитаты. Для пользователя этого уже достаточно, чтобы понять: след остался.
Обычный пример выглядит так. Компания убрала устаревший регламент, но в понедельник сотрудник спрашивает про отпуск, и бот снова ссылается на старую версию. Так бывает, когда файл удалили только в одном месте, а копии в индексе, кэше и слое цитирования никто не почистил.
Удаление документа из RAG - это не одна операция, а цепочка действий. Иначе система забудет файл только на бумаге.
Где обычно прячутся следы
Следы редко живут в одном месте. Поэтому документ исчезает из хранилища, а фразы из него еще попадают в ответ.
Первый кандидат - основная векторная коллекция. Если документ разбили на чанки, в индексе обычно лежит не один объект, а десятки или сотни. Достаточно пропустить часть чанков, и поиск все еще будет их находить по смыслу.
На этом проблемы обычно не заканчиваются. У многих команд есть запасные индексы: отдельная коллекция для экспериментов, временная копия для миграции, индекс в staging, локальная база у разработчика. Иногда старый индекс остается после смены схемы эмбеддингов и незаметно участвует в поиске через запасной маршрут. В итоге прод уже "чистый", а ответы все равно тянут старый текст из тестовой копии.
Кэш - еще одно частое укрытие. Retrieval cache может вернуть старый набор чанков даже после удаления из базы. Кэш rerank-результатов опасен по той же причине: он хранит уже отсортированный список кандидатов и продолжает подмешивать удаленный источник. Answer cache хуже всего заметен, потому что выглядит как обычный корректный ответ, хотя модель вообще не ходила в свежий индекс.
Обычно стоит проверить:
- основную векторную коллекцию и все чанки документа;
- резервные, тестовые и миграционные индексы;
- retrieval cache, reranker cache и answer cache;
- хранилище цитат и ссылок на источники;
- память сессий и историю диалогов.
Отдельная ловушка - слой цитат. Во многих RAG-системах цитата, ссылка на источник и сам найденный чанк живут в разных таблицах или коллекциях. Чанк можно удалить, а запись с title, source_id или готовой цитатой останется. Тогда ответ уже не опирается на документ напрямую, но интерфейс все еще показывает его как источник.
Сессии тоже сохраняют следы дольше, чем кажется. Если пользователь раньше обсуждал документ, память диалога может нести краткое резюме, extracted facts или старые message attachments. После этого модель отвечает так, будто документ все еще доступен.
Типичный случай такой: устаревший регламент убрали из индекса утром, а днем бот все еще цитирует прежний лимит. Причина часто не в поиске, а в answer cache или в памяти активной сессии. Если не проверить все эти слои, удаление документа из RAG останется незавершенным.
Что собрать перед чисткой
Удаление почти никогда не ломается на шаге delete. Оно ломается раньше, когда команда не знает, что именно удалять и где это лежит. Если у документа нет точного набора идентификаторов, легко убрать один след и оставить три других.
Сначала соберите паспорт документа. Нужны не только document_id, но и source_id и version_id. Это три разных уровня: сам документ, источник, из которого он приехал, и конкретная версия. Если у вас был регламент в редакции от марта, а в мае его перезалили под тем же именем, без version_id вы рискуете удалить не тот слой данных.
Потом зафиксируйте, как документ разошелся по пайплайну. Один файл редко живет как один объект. После парсинга он распадается на чанки, а дальше попадает в одну или несколько коллекций: векторную, текстовую, таблицу метаданных, а иногда и в индекс цитат. Если не выписать chunk_id и имена коллекций заранее, проверка быстро превращается в ручной разбор логов.
Обычно хватает такого набора:
document_id,source_id,version_idи исходное имя файла;- список
chunk_idили диапазон чанков, если их много; - названия коллекций, индексов и таблиц, куда попал документ;
- признак активной синхронизации: cron, webhook, очередь импорта или ручной job.
Последний пункт часто недооценивают. Если источник продолжает переиндексацию, документ вернется через десять минут, и вы решите, что чистка не сработала. До удаления остановите повторную загрузку: отключите расписание, заморозьте коннектор или поставьте блок по source_id. Иначе вы будете лечить симптом, а не причину.
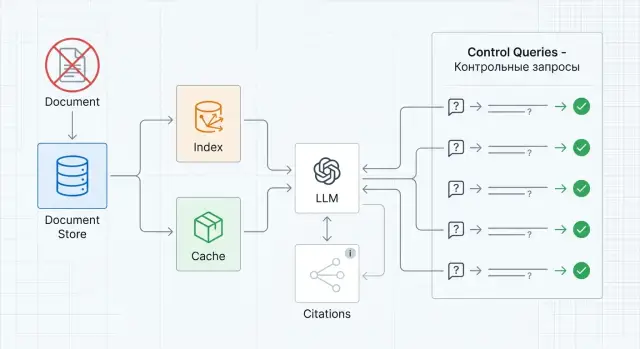
Еще до чистки подготовьте контрольные запросы. Не после, а именно до. Возьмите 5-10 вопросов, на которых документ обычно всплывает: прямое название, редкую формулировку из текста, номер пункта, характерный термин, вопрос на пересказ. Сохраните ответы, найденные чанки и цитаты. Потом у вас будет с чем сравнить результат.
Если система пишет аудит по каждому запросу, сохраните и эти следы: request_id, retriever hits, used citations, cache key. В среде с несколькими моделями и прокси это экономит часы. Если команда отправляет запросы через OpenAI-совместимый шлюз вроде RU LLM, по аудит-трейлам проще понять, какой сервис дал ответ, а какой слой вернул найденные фрагменты. Так быстрее видно, где именно остался хвост: в индексе, в кэше или в логике цитирования.
Как удалить документ без хвостов
Одного удаления файла мало. RAG часто помнит документ сразу в нескольких местах: в карточке источника, в чанках, в эмбеддингах, в кэше поиска и даже в готовых ответах с цитатами. Если убрать только оригинал, система все равно может достать старый фрагмент по внутреннему идентификатору.
Если запросы к моделям идут через RU LLM, это тоже не решает задачу само по себе. Шлюз отвечает за доступ к моделям и маршрутизацию, а следы документа обычно живут в вашем индексе, хранилище метаданных и кэшах приложения.
Рабочий порядок обычно такой:
- Удалите исходный файл и запись о нем в каталоге источников. Проверьте все идентификаторы:
document_id,source_id, версию документа и алиасы имени файла. Если у вас есть переиндексации по версиям, удаляйте всю цепочку, а не только последний объект. - Сотрите все чанки, которые этот документ породил. Лучше искать не только по
document_id, но и поsource_id, хэшу файла, пути загрузки и тегам коллекции. После этого удалите связанные эмбеддинги из векторной базы. - Очистите кэш retrieval-контура. Чаще всего забывают про кэш поисковой выдачи, rerank-результаты, собранный prompt и кэш финального ответа. Если оставить хотя бы один слой, старый текст вернется без повторного поиска.
- Уберите старые цитаты. Это относится к сохраненным ответам в чате, сниппетам в интерфейсе, истории сессий и таблицам, где вы храните
source_titleили ссылку на фрагмент. Иначе пользователь увидит ссылку на уже удаленный документ, даже если сам текст больше не находится. - Перед возвратом системы в работу прогоните короткий тест. Он нужен, чтобы поймать хвосты сразу, а не после жалобы от пользователя.
Есть две частые ошибки. Первая: команда чистит только векторную базу и забывает обычную SQL-таблицу с метаданными. Вторая еще неприятнее: документ удалили, но рядом остался summary, сделанный заранее для быстрого ответа. Тогда модель не найдет чанки, но перескажет старое содержание из подготовленной выжимки.
Быстрый тест лучше делать на 3-5 запросах, которые раньше почти всегда вытаскивали этот документ. Смотрите не только на текст ответа, но и на список источников, внутренние идентификаторы, debug trace и cache hits. Система готова к работе только тогда, когда удаленный документ не всплывает ни в поиске, ни в цитатах, ни в повторно отданном ответе.
Пример с устаревшим регламентом
Внутренний бот банка отвечал сотрудникам по лимитам согласования платежей. Весной юристы отозвали регламент: в старой версии порог был 500 000 рублей, в новой - 300 000 и другой маршрут согласования. PDF удалили из базы знаний, но через день бот все равно цитировал старую цифру и даже показывал фрагмент из отмененного файла.
Такое случается часто. Файл исчезает из хранилища, а его следы живут в нескольких местах: в векторной коллекции, в полнотекстовом индексе, в кэше готовых ответов и в таблице, где хранятся цитаты для интерфейса. Если удалить только исходный PDF, поиск по chunk_id или document_id все еще может вернуть старые куски.
Инженер начал не с полной переиндексации базы, а с точечной чистки по document_id старого регламента. Он прошел по цепочке:
- удалил все чанки документа из векторной коллекции;
- убрал записи из полнотекстового индекса и таблицы метаданных;
- сбросил кэш ответов, где встречался
document_idили заголовок документа; - вычистил блоки цитат и сохраненные сниппеты в интерфейсе;
- пометил документ как withdrawn, чтобы синхронизация не вернула его снова.
После этого он загрузил новый регламент как отдельный документ с новым document_id. Такой шаг обычно безопаснее, чем тихо подменять старую запись. Если оставить прежний идентификатор, команда потом долго разбирается, почему часть логов, кэша и цитат относится к старой версии, а часть - к новой.
Проверка заняла десять минут, зато сняла риск. Инженер прогнал несколько коротких запросов:
- "Какой лимит на согласование платежа без директора?"
- "Покажи регламент по лимитам для внутренних переводов"
- "Цитата из регламента по порогу 500 000 рублей"
- "Какой документ действует вместо отозванного регламента?"
Хороший результат выглядел просто: бот больше не называл старый лимит, не отдавал цитаты из удаленного PDF и не подмешивал старый заголовок в подсказки. Если в базе уже была замена, бот ссылался на новый регламент. Если замены еще не было, он прямо отвечал, что документа в текущей базе нет.
Этот пример показывает главное: удаление документа из RAG редко сводится к одному действию. Нужно убрать все места, где система еще может встретить старый текст.
Как проверить результат на контрольных запросах
После очистки нельзя верить одному удачному ответу. Нужен короткий прогон, который бьет и по явным следам, и по скрытым. Цель простая: модель не должна вспоминать удаленный документ ни по названию, ни по его фактам, ни по старым цитатам.
Сначала спросите прямо по названию документа. Если в базе был файл "Регламент 2023.4", задайте вопрос в лоб: есть ли такой документ, что в нем сказано, какая у него дата и статус. Хороший результат не только молчит о содержимом, но и не выдает старую формулировку вроде "согласно регламенту".
Потом переходите к косвенным вопросам. Они ловят остатки лучше, чем прямой запрос, потому что модель может помнить куски текста, цифры и редкие обороты. Обычно хватает четырех типов запросов:
- вопросы по точным числам, срокам и лимитам из удаленного файла;
- вопросы по редким формулировкам, которые почти не встречаются в других документах;
- вопросы на пересечение фактов, когда ответ раньше собирался из двух источников;
- перефразированные вопросы, чтобы проверить не только одно совпадение слов.
Дальше проверьте разные состояния диалога. Запустите те же запросы в новой сессии, где нет памяти разговора, а потом в старой истории, где этот документ уже мог всплывать раньше. Если следы остались только в старом чате, проблема может быть не в индексе, а в памяти сессии или в кэше ответов.
Отдельно сравните режим с цитатами и режим без цитат. В режиме с цитатами система иногда честно показывает, что тянет удаленный источник. В режиме без цитат она может ответить теми же словами, но спрятать источник. Поэтому смотрите не только на наличие ссылки на документ, но и на сам текст ответа. Если обороты и числа совпадают слишком точно, это уже повод копать дальше.
Спорные ответы сохраняйте сразу. Запишите текст запроса, ответ, ID сессии, режим работы, время прогона и версию индекса, если вы ее ведете. Без этого команда потом спорит по памяти, а не по фактам.
Нормальный итог проверки выглядит скучно: на прямой вопрос система не находит документ, на косвенных вопросах не повторяет его данные, в старой и новой сессии ведет себя одинаково, а режим с цитатами не показывает удаленный источник.
Где чаще всего ошибаются
Самая частая ошибка - удалить исходный PDF и считать задачу закрытой. На деле RAG часто держит документ в нескольких местах: в основной коллекции, в резервной коллекции для переиндексации и в тестовом индексе, который кто-то поднял месяц назад и забыл. Если хотя бы один набор чанков жив, поиск может снова вытащить старый фрагмент.
Вторая ошибка связана с кэшем. Многие очищают только answer cache, потому что его видно первым по повторяющимся ответам. Но retrieval cache, кэш rerank-результатов и сохраненные цитаты живут дольше, чем кажется. Из-за этого модель уже не находит документ в индексе, а ответ все равно опирается на старую выборку.
Еще одна проблема - слишком узкая проверка. Запрос вроде "покажи регламент отпусков" может ничего не вернуть, и кажется, что все чисто. Но косвенная формулировка, старая аббревиатура, точная цитата или даже запрос с опечаткой легко достают тот же документ обходным путем.
Отдельный промах - забытая история диалогов тестовых аккаунтов. Если QA или разработчик уже обсуждал этот документ с ассистентом, модель может опираться на старый контекст беседы, а не на текущий индекс. Тогда кажется, что удаление не сработало, хотя след остался не в базе знаний, а в сохраненной сессии.
Самая дорогая ошибка - не зафиксировать состояние до и после чистки. Без снимка по doc_id, числу чанков, идентификаторам цитат и состоянию кэша спор быстро превращается в догадки. Один инженер говорит, что индекс пустой, другой показывает ответ со старой ссылкой, и никто не может доказать, где именно остался хвост.
Хорошая практика проста: перед удалением сохранить короткий отчет, после удаления снять такой же и затем прогнать набор контрольных запросов на чистой сессии. Это скучная работа, но она экономит часы разбора, особенно когда у команды несколько индексов и окружений.
Короткий чек-лист перед выпуском
Перед повторным запуском не стоит верить одному признаку вроде "документ удален из индекса". Старый источник часто остается в другом месте: в соседней коллекции, в кэше ответа, в таблице цитат или в сохраненном результате rerank. Поэтому выпускать изменения лучше только после короткой ручной проверки.
Проверьте по списку:
- сверьте все идентификаторы удаленного документа:
document_id, внешние ID, путь к файлу, версию, хэш и алиасы; - убедитесь, что чанков больше нет нигде, включая тестовые коллекции, архивы, запасные хранилища и таблицы метаданных;
- очистите кэш шире, чем кажется нужным: по ID документа, похожим вопросам, готовым ответам, цитатам и промежуточным результатам поиска;
- проверьте выдачу цитат: интерфейс не должен показывать старый файл ни по названию, ни по внутреннему ID, ни по кускам текста;
- прогоните контрольные запросы и убедитесь, что ответ либо молчит об удаленном факте, либо опирается на новый источник.
Если у вас продакшен-схема сложнее одного индекса, добавьте еще один шаг: посмотрите логи реальных запросов за последние дни. Так проще заметить забытый маршрут, где старый документ все еще участвует в ответе. В командах с российским контуром это особенно полезно: аудит-трейлы RU LLM помогают быстро понять, какой именно сервис вернул след удаленного источника.
Хороший признак готовности простой: система не находит старый документ ни по ID, ни по текстовому фрагменту, ни по цитате, ни по вопросу-ловушке. Если хотя бы один тест провалился, выпуск лучше отложить на час, чем потом искать причину в боевом трафике.
Что сделать после чистки
Если команда один раз убрала документ и не закрепила шаги, та же ошибка вернется при следующем инциденте. Удаление документа из RAG лучше считать не разовой операцией, а рабочей процедурой с проверкой и короткой историей изменений.
Закрепите процедуру в runbook
Runbook нужен не для формальности. Он экономит часы, когда через месяц никто не помнит, где именно лежали чанки, какой кэш вы чистили и почему старые цитаты еще всплывали в ответах.
Обычно хватает одного короткого шаблона:
- где хранится источник и его внутренний ID;
- какие индексы, кэши и таблицы цитат связаны с ним;
- кто запускает удаление и кто проверяет результат;
- какие контрольные запросы команда обязана прогнать;
- когда проверку нужно повторить.
Рядом с каждым значимым источником держите свой набор контрольных запросов. Не в отдельной папке, которую никто не открывает, а там, где команда реально работает: в репозитории, wiki или карточке сервиса. Тогда при следующем удалении вы не будете вспоминать по памяти, как именно ловить хвосты.
Если процедура описана, а контрольные запросы сохранены, повторная чистка занимает часы, а не дни. Для RAG это и есть нормальный уровень надежности: документ удалили один раз, и он действительно перестал всплывать в ответах.