Версионирование моделей и промптов в одном релизе LLM
Версионирование моделей и промптов помогает связать commit, eval-report и rollout в один процесс, чтобы быстро откатывать релизы без долгих разборов.
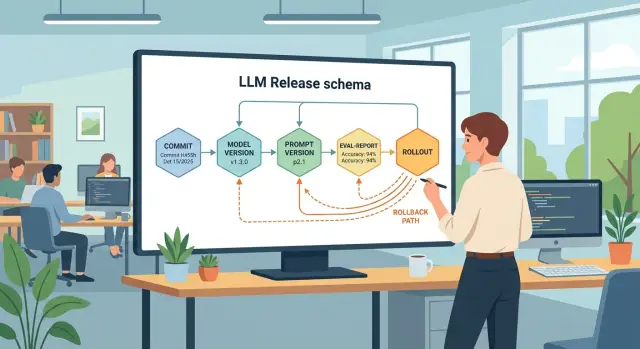
Почему откат превращается в расследование
Проблема обычно начинается не в момент сбоя, а раньше. Команда хранит код, промпт, eval-report и rollout в разных местах и не связывает их одним номером релиза. В результате Git знает про commit, CI знает про оценки, таблица знает про промпт, а прод знает только то, что "что-то выкатили".
Типичная цепочка выглядит безобидно. Разработчик меняет шаблон системного промпта. ML-инженер переключает модель или провайдера. DevOps отдельно выкатывает конфиг. По отдельности это мелкие изменения. Вместе они дают новое поведение, которое потом трудно восстановить по следам.
Связь чаще всего рвется в четырех местах:
- commit не указывает точную версию промпта;
- eval-report лежит отдельно от релиза;
- rollout фиксирует время выката, но не полный набор изменений;
- мониторинг показывает рост ошибок, но не показывает, что именно ушло в прод.
После сбоя команда начинает спорить не о решении, а о фактах. Один человек винит новую модель. Другой уверен, что все сломал обновленный промпт. Третий вспоминает, что в тот же день меняли fallback или маршрутизацию. Если в журнале rollout написано что-то вроде "assistant config updated", такая запись почти бесполезна. По ней нельзя понять, какой commit, какой prompt revision и какой eval-report относились к запуску.
В банке это особенно заметно. Допустим, чат-бот поддержки стал чаще отказывать в ответах на простые запросы. Сервис не падает, ошибок 500 нет, задержка почти не изменилась. Значит, сломалась не инфраструктура, а поведение модели. Но что откатывать: код, промпт, выбор провайдера, temperature или весь релиз? Пока команда это выясняет, инцидент тянется лишние часы.
Даже единый OpenAI-совместимый шлюз сам по себе проблему не решает. Через него удобно менять model id, провайдера и правила маршрутизации без переписывания кода. Но если у релиза нет общей версии, такие изменения становятся еще менее заметными. Тогда откат модели превращается в ручной разбор по чатам, логам и памяти людей.
Самый неприятный эффект простой: команда уже не обсуждает качество решения, она пытается восстановить, что вообще произошло. Если факты не собраны в одном месте, любой rollback становится медленным и рискованным.
Что должно входить в версию релиза
Одна версия релиза для LLM - это не только новый commit. Если в карточке релиза нет точной модели, провайдера и текста промпта, потом никто не поймет, что именно изменило ответ. Один и тот же код с разными настройками может вести себя как два разных продукта.
В релизе нужно фиксировать пять групп данных. Первая - commit из репозитория. Лучше использовать полный SHA или короткий SHA, но в одном формате для всех команд. По нему видно код приложения, шаблоны запросов и изменения в пайплайне.
Вторая - модель и провайдер. Записывайте не только имя модели, но и точный идентификатор, провайдера, регион размещения и способ доступа. Это особенно важно, если команда работает через шлюз вроде RU LLM: одна и та же модель у разных провайдеров может отличаться по задержке, лимитам и доступным параметрам.
Третья - версии системного и пользовательского промпта. Их лучше хранить как отдельные файлы или шаблоны с хешем. Если изменилась даже одна строка в системном промпте, это уже новая версия релиза.
Четвертая - параметры запуска и лимиты. Температура, top_p, max_tokens, timeout, число повторных запросов, размер контекста, правила fallback и лимит стоимости влияют на результат не меньше, чем код.
Пятая - автор и причина изменения. Имя, дата, номер задачи и короткое описание ожидаемого эффекта сильно упрощают откат.
Полезно добавить еще два поля: ссылку или идентификатор eval-report и метку среды, где релиз проверяли. Тогда по одной записи видно, что команда сравнивала, какие тесты прошли и куда ушел rollout.
Простой пример: чат-бот банка начал отвечать короче и чаще просить уточнения. Если в релизе записан только commit, поиск причины затянется. Если там есть модель, провайдер, версия системного промпта и температура, ответ находится быстро. Код могли вообще не трогать. Команда просто подняла температуру с 0.2 до 0.7 и одновременно сократила системный промпт.
Версионирование моделей и промптов работает только тогда, когда релиз читается как паспорт изменения. В этом случае откат - это возврат к предыдущему набору значений, а не поиск по чатам, тикетам и чужой памяти.
Как дать релизу один ID
У релиза LLM должен быть один ID, а не набор разрозненных версий в чате, CI и таблице с оценками. Иначе после сбоя команда видит один commit, другое имя модели, третью версию промпта и тратит полдня на сверку. Один ID не решает все сам, но он сразу связывает код, оценку и rollout.
На практике это удобно делать через небольшой manifest в JSON или YAML. Его кладут рядом с кодом и меняют в том же pull request, где обновляют prompt, маршрут модели или логику вызова. Тогда релиз можно найти по одному артефакту, а не собирать вручную из нескольких систем.
Что должно быть в manifest
Минимальный набор полей лучше держать коротким:
release_idcommitmodelprompt_versioneval_report_idrolloutenvironment
Пример простой структуры:
{
"release_id": "chat-assistant-2026-04-27.3",
"commit": "8f3c2ab",
"model": "qwen-3-32b",
"prompt_version": "support-v17",
"eval_report_id": "eval-2026-04-27-142",
"rollout": 3,
"environment": "prod"
}
Формат ID не так важен. Важнее другое: он должен быть один и тот же во всех инструментах. На практике удобно включать в release_id имя сервиса, дату и номер попытки. Тогда chat-assistant-2026-04-27.3 уже сам по себе дает контекст.
Manifest полезно хранить рядом с кодом по простой причине. Откат тогда сводится к выбору предыдущего файла и commit, а не к разбору логов. Если промпт живет в репозитории, модель выбирается через конфиг, а eval-report хранится в отдельной системе, manifest становится общей точкой правды.
Логи тоже должны знать этот ID. Печатайте его в каждом запросе рядом с request_id, именем модели и окружением. Если команда работает через единый шлюз и может менять маршрут до модели без изменения клиентского кода, release_id становится еще важнее. Иначе один и тот же сервис может ходить по разным маршрутам, а причина сбоя быстро теряется.
Хорошее правило простое: если по одному ID нельзя за две минуты найти commit, eval-report и текущий rollout, это не ID релиза, а просто наклейка.
Как собирать eval-report до выката
Eval-report нужен не для формальности. Он должен отвечать на один вопрос: новый релиз лучше текущего или нет на одном и том же наборе задач. Если вчера команда тестировала на одних примерах, а сегодня на других, итоговые цифры почти ничего не значат.
Набор задач стоит зафиксировать заранее. Обычно туда входят частые запросы, длинные диалоги, сложные случаи и сценарии с высоким риском, где ошибка дорого обходится. Прогонять нужно и текущий продовый релиз, и кандидата на выкат, причем с одинаковыми настройками: температура, лимиты токенов, tool calling, версия системного промпта и маршрут к модели.
Не сводите все к одному среднему баллу. Один релиз может отвечать точнее, но стать заметно дороже. Другой снизит цену, но сорвет SLA из-за задержки. Поэтому качество, стоимость и задержку лучше хранить отдельно.
По качеству смотрят долю успешных ответов, точность по эталону и соблюдение внутренних правил. По стоимости - входные и выходные токены, цену одного запроса и цену полного набора задач. По задержке - p50, p95, time to first token и долю таймаутов.
Средние значения скрывают неприятные сюрпризы. Сохраняйте примеры провалов: исходный запрос, ожидаемый результат, ответ старого релиза, ответ нового и короткую пометку причины. Десять плохих примеров часто дают больше пользы, чем одна красивая таблица. По ним сразу видно, что именно сломалось: извлечение реквизитов, тон ответа, классификация обращения или работа с длинным контекстом.
Порог остановки rollout LLM нужно задавать до выката, а не после первой жалобы. Например, если качество падает больше чем на 1 п.п. на наборе комплаенса, p95 растет больше чем на 20% или цена запроса выходит за лимит, rollout останавливается автоматически. Тогда поводов для спора почти не остается: релиз не прошел порог и уходит на доработку.
Привязывайте отчет к тому же ID релиза, что и commit, конфиг, версия промпта и тег модели. Один ID должен открывать всю картину. Если команда использует шлюз вроде RU LLM, в отчете стоит фиксировать и точный provider/model route. Один и тот же промпт на разных маршрутах может дать разную цену, задержку и поведение.
Как проводить rollout без ручного расследования
Rollout ломается не в момент выката, а раньше, когда артефакты не связаны в одну версию. Если commit живет отдельно, eval-report лежит в другом месте, а в прод уходит "примерно тот же" промпт, откат модели быстро превращается в спор.
Рабочая схема проста: у каждого релиза есть один ID, и этот ID проходит через весь путь запроса. Для команд, которые ходят к моделям через единый OpenAI-совместимый эндпоинт, это особенно удобно: ID релиза можно протянуть в логи, метрики и аудит-трейлы без смены клиентского кода.
Сначала соберите manifest новой версии. Включите в него commit SHA, версию промпта, модель, параметры генерации, шаблон системного сообщения, флаги безопасности и все, что влияет на ответ. Если какой-то параметр не попал в manifest, потом именно он и сломает разбор инцидента.
Потом прогоните eval на этом manifest, а не на отдельных кусках. Отчет должен ссылаться на тот же ID релиза и тот же набор артефактов. Рядом сохраните метрики качества ответов, долю отказов, стоимость, задержку и ошибки на тестовых сценариях.
После этого дайте релизу малую долю трафика. Часто хватает 1-5%, если поток запросов стабильный. Не смешивайте canary с ручными правками в проде. Иначе потом не получится понять, что именно дало просадку: новая модель, новый промпт или чья-то срочная правка.
Во время rollout смотрите не только на общие графики, но и на ошибки по ID релиза. Сравнивайте долю таймаутов, пустых ответов, отказов по policy, среднюю длину ответа и бизнес-метрику сценария. Для банковского чат-бота это может быть доля запросов, где бот верно распознал продукт и не отправил клиента в тупик.
Если метрики просели, возвращайте прошлый manifest целиком. Не пытайтесь чинить релиз на ходу. Быстрый rollback почти всегда лучше длинного расследования, где команда вспоминает, какой именно промпт ушел в прод и на какой модели он работал.
В нормальном релизном процессе rollback занимает минуты. Команда открывает ID релиза, видит связанный commit, отчет eval и текущий rollout, а потом возвращает предыдущий manifest одним действием.
Пример для чат-бота банка
У банка есть чат-бот в мобильном приложении. Пользователи спрашивают про лимиты, перевыпуск карты, спорные списания и условия кэшбэка. Команда решила улучшить ответы по карточным FAQ и выпустила не только новую модель, но и весь связанный набор изменений.
В один релиз вошли четыре вещи: commit с кодом маршрутизации, версия модели, новый системный промпт и лимит токенов. Это оформили под одним release_id, например cards-bot-2026-04-27-17. Тот же ID попал в tag, в eval-report и в метаданные rollout.
Системный промпт переписали так, чтобы бот реже уходил в общие советы и чаще отвечал по базе банка. Лимит токенов немного подняли, потому что старая настройка обрезала длинные ответы про комиссии и сроки оспаривания операций. Заодно команда сменила модель на более точную для русскоязычных диалогов.
Eval до выката дал смешанный результат. На наборе из 800 банковских вопросов пропуски по FAQ снизились с 11% до 4%, но медианная задержка выросла с 1,8 до 2,4 секунды. Это не повод отменять релиз, но уже ясно, что команда меняет не один параметр, а поведение сервиса целиком.
Поэтому rollout шел по одному ID, а не по частям. Сначала новый набор пустили на 10% трафика в сегменте вопросов по картам. Команда смотрела на три сигнала: долю эскалаций на оператора, среднюю длину ответа и жалобы операторов первой линии.
Через несколько часов метрики выглядели нормально, и релиз пошел на весь поток. Позже операторы заметили другую проблему: бот стал отвечать слишком подробно в простых сценариях и дольше держал диалог там, где раньше быстро переводил клиента на человека. Если бы модель, промпт и лимит токенов жили как отдельные сущности, началось бы долгое расследование.
Вместо этого команда откатила весь набор сразу по тому же release_id. За десять минут она вернула прошлую модель, старый системный промпт и прежний лимит токенов. Уже после этого можно спокойно разбирать, что дало выигрыш в FAQ, а что добавило лишнюю задержку и трение для операторов.
Если трафик идет через RU LLM, release_id удобно прокинуть в каждый запрос и потом видеть его в аудит-трейле. Это особенно полезно там, где маршрут до модели можно поменять без изменений в SDK и прикладном коде: по логу сразу видно, какой commit, какой eval-report и какой rollout стояли за конкретным ответом.
Где команды чаще всего ошибаются
Чаще всего релиз ломается не из-за модели, а из-за отсутствия следов. Команда видит просадку по качеству, открывает логи и понимает: видно только имя модели, а что именно ушло в прод, уже никто не помнит.
Первая частая ошибка - менять промпт прямо в панели или в админке, без commit. Это кажется быстрым ходом, пока не нужен откат. Потом в репозитории лежит один текст, в проде работал другой, а eval-report собран вообще на третьем варианте.
Вторая ошибка - сравнивать модели на разных тестовых наборах. В понедельник команда гоняет один набор кейсов, в среду другой, а потом пишет, что новая модель лучше. На самом деле она сравнила разные эксперименты. Нормальный eval-report получается только тогда, когда модель A и модель B проходят одну и ту же проверку.
Третья ошибка - писать в журнале только имя модели. Запись вроде "qwen" или "gpt-4.1" почти бесполезна. Нужны точная версия, провайдер, параметры вызова, версия промпта и дата rollout. Для версионирования моделей и промптов это не бюрократия, а базовая дисциплина.
Еще одна распространенная ошибка - прятать решение о rollout в чатах. Там можно найти фразы вроде "катим после обеда" или "оставляем 50% трафика", но чат не связывает commit, eval-report и факт выката. А когда инцидент уже идет, искать по переписке особенно неудобно.
Самый неприятный вариант выглядит так: модель откатили, а старый промпт не вернули. Снаружи кажется, что rollback не помог. На деле команда вернула только половину релиза. Если модель и промпт менялись вместе, откатывать их тоже нужно вместе, одним ID.
Минимум для нормального процесса простой: каждый промпт меняется только через commit, eval-report хранит хеш датасета и версию промпта, журнал rollout фиксирует точную модель, провайдера и параметры, решение о выкате живет в системе релизов, а rollback возвращает полный комплект - модель, промпт и конфиг.
Даже если у вас есть аудит на уровне LLM-шлюза, этого мало. Например, RU LLM хранит логи и аудит-трейлы внутри РФ и помогает отследить маршрут запроса, но это не замена нормальному релизному процессу. Если команда не связала commit, eval-report и rollout одним идентификатором, откат все равно превращается в расследование.
Проверки перед релизом
Перед выкладкой команда должна быстро ответить на пять вопросов, без поиска по чатам и старым тикетам. Если хотя бы на один из них ответ звучит как "сейчас уточню", релиз лучше притормозить.
- Есть ли у релиза один понятный ID, который связывает commit приложения, версию модели, шаблон промпта, параметры вызова и конфиг маршрутизации?
- Лежит ли предыдущий manifest рядом с текущим, и можно ли откатиться за несколько минут?
- Показывает ли eval-report не только средний балл, но и проблемные хвосты: просадки по точности, рост отказов, слишком длинные ответы, небезопасный тон и сбои формата?
- Есть ли у дежурного и владельца релиза заранее записанный порог остановки rollout?
- Фильтруются ли логи, трассировки и дашборды по
release_id, чтобы быстро сравнить старую и новую версию на одном типе трафика?
Обычно ломается именно связка между этими точками. Commit есть, eval-report есть, rollout тоже был, но они живут в разных местах и не бьются между собой. В такой схеме даже небольшой рост жалоб тянет за собой длинную ручную проверку.
Если команда ведет трафик через RU LLM, удобно передавать release_id в метаданных запроса и тем же ID помечать отчеты, алерты и выборки логов. Тогда откат выглядит скучно: взяли прошлый manifest, вернули его в rollout и сразу увидели в дашборде, что новая версия больше не обслуживает запросы. Именно такой скучный процесс и нужен в проде.
Что сделать в ближайшем спринте
Если релиз LLM нельзя описать одной записью, откат почти всегда затягивается. Команда спорит, какой промпт стоял в проде, какой маршрут вел на модель и к какому commit относится свежий eval-report. В ближайшем спринте лучше исправить именно это.
Начните с одного manifest-файла на каждый релиз. Это может быть простой YAML или JSON в репозитории. В нем стоит хранить commit приложения, версию промпта, маршрут до модели, параметры вызова, идентификатор eval-report и версию, на которую команда откатывается при сбое.
Следующий шаг - вынести промпты из таблиц и документов в тот же репозиторий, где живет код. Тогда review проходит через pull request, а diff показывает, что именно изменилось: системная инструкция, few-shot пример или формат ответа. Для версионирования моделей и промптов это намного надежнее, чем ручные пометки в wiki.
Дальше пробросьте один release_id в логи, eval-job и rollout-скрипты. Он должен проходить через весь путь запроса. Если идентификатор есть только в CI, пользы мало: во время инцидента люди смотрят в логи, алерты и дашборды.
И наконец, добавьте команду rollback, которая принимает тот же release_id и возвращает прошлую связку целиком. Не только модель. Не только промпт. Весь набор.
Если команда уже работает через единую точку доступа к моделям, собрать такой процесс проще. В случае RU LLM это удобно еще и потому, что можно менять base_url на шлюз и продолжать использовать тот же SDK, код и промпты, а сам release_id передавать в запросах и аудит-трейлах. Но даже в таком случае порядок остается тем же: одна версия релиза, один manifest и один способ отката.
Хороший результат спринта выглядит просто: по одному release_id любой инженер за пять минут понимает, что выкатили, как это проверили и куда откатиться.
Часто задаваемые вопросы
Зачем вообще нужен один release_id для LLM-релиза?
Один release_id связывает код, промпт, модель, eval и rollout в одну запись. Когда что-то пошло не так, команда сразу видит, что именно ушло в прод, и возвращает прошлую версию без разбора по чатам.
Что обязательно включить в версию релиза?
Минимум такой: commit, точная модель, провайдер, версия промпта, параметры генерации, eval_report_id, окружение и номер rollout. Если любой из этих кусков выпал, потом станет трудно понять, что изменило поведение.
Где хранить manifest релиза?
Лучше держать manifest рядом с кодом и менять его в том же pull request, что и промпт или конфиг модели. Тогда diff показывает весь релиз целиком, а откат сводится к возврату предыдущего файла и commit.
Как правильно версионировать промпты?
Не храните промпт только в админке, таблице или документе. Положите его в репозиторий как файл или шаблон, дайте версию или хеш и считайте даже одну правку новой версией релиза.
Зачем привязывать eval-report к тому же ID, что и rollout?
Потому что цифры без привязки к релизу мало что дают. Отчет должен ссылаться на тот же release_id и тот же набор артефактов, чтобы команда могла сравнить текущий прод и кандидата на одном наборе задач.
Как понять, когда нужно остановить rollout?
Порог лучше задать заранее, до выката. Если качество падает выше допустимого уровня, p95 заметно растет или цена запроса выходит за лимит, rollout останавливают сразу, а не после споров в чате.
Что именно откатывать при сбое — модель или весь релиз?
Откатывайте весь набор: модель, промпт, параметры и конфиг маршрута. Частичный rollback часто не помогает, потому что команда возвращает только половину изменений и получает ту же проблему.
Если я меняю модель через шлюз, нужен новый релиз?
Можно, но без нового релиза это опасно. Если вы сменили маршрут, провайдера или model id, зафиксируйте это в manifest и логах как новую версию, даже если код клиента не менялся.
Какие ошибки команды делают чаще всего?
Часто команды правят промпт вне Git, сравнивают модели на разных датасетах и пишут в журнале только имя модели. После этого никто уже не может быстро ответить, какой промпт, какой провайдер и какой eval относились к продовой версии.
Что стоит внедрить в ближайшем спринте?
Начните с малого: добавьте один manifest, перенесите промпты в репозиторий и протяните release_id в логи, eval-job и rollout-скрипт. После этого сделайте команду rollback, которая возвращает предыдущую связку целиком за одно действие.