Tool calling на русском: схемы функций без хрупких промптов
Практика для команд: Tool calling на русском, схемы функций, проверка аргументов, безопасные повторы и работа с неуверенностью модели.
Где ломается tool calling в русских диалогах
Tool calling на русском чаще ломается не на API и не на формате JSON. Проблема обычно в самой речи пользователя. Русский диалог плотный: люди сокращают фразы, меняют мысль по ходу и часто складывают в одно сообщение сразу две задачи.
Самый частый сбой выглядит буднично. Пользователь пишет: "Закажи пропуск на завтра и предупреди охрану, что приедет курьер". Для человека это обычная просьба. Для модели это уже два разных действия. Если у вас на сообщение предусмотрена только одна функция, модель либо теряет вторую часть, либо пытается упаковать все в один вызов и придумывает аргументы, которых в схеме нет.
Дальше плывет смысл. В следующей реплике пользователь уточняет: "Нет, не на завтра, а на четверг после обеда. И не курьер, а подрядчик". Одни значения нужно заменить, другие оставить, а часть данных уже не нужна. Если система плохо держит состояние диалога, в вызов легко уезжает смесь старых и новых аргументов. Потом команда ищет баг в функции, хотя ошибка сидит в сборке аргументов.
Русский язык отдельно бьет по датам, суммам и формам слов. "В следующий понедельник" зависит от текущей даты. "После обеда" для одного сервиса значит 13:00, для другого 15:00. "Тысяч на три" и "до пяти" звучат просто, но для парсинга это разные ограничения. Падежи тоже мешают: "пропуск для Иванова на Петровке" может содержать и получателя, и адрес, а модель иногда цепляется только за ближайшее существительное.
Еще одна частая поломка - выбор похожей, но не той функции. Если в наборе есть create_pass, extend_pass и check_pass_status, модель иногда берет ближайшую по словам функцию, а не ту, что подходит по смыслу. Это часто случается, когда описания функций похожи, а пользователь пишет коротко: "Посмотри пропуск на пятницу". Проверить статус, создать новый или продлить старый? Без явного сигнала модель начинает угадывать.
Обычно тревожные признаки выглядят так:
- в одном вызове появляются лишние поля из другой задачи
- дата есть, но она в неверном формате или с неверным днем
- сумма выглядит правдоподобно, но теряет ограничение "до" или "около"
- модель выбирает близкую по словам, но чужую по действию функцию
- после уточнения пользователя старые аргументы не исчезают
Именно тут хрупкие промпты быстро сыпятся. Пока диалог простой, все выглядит аккуратно. Как только пользователь пишет по-человечески, схема без четких границ начинает течь.
Как описывать функции без лишних уловок
Когда одна и та же схема уходит в разные модели через OpenAI-совместимый API, трюки в стиле "угадай по контексту" ломаются первыми. Функция должна говорить сама за себя: что она делает, какие данные ждет и в каких случаях ее нельзя вызывать.
Лучше всего работает правило "одна функция - одно действие". Не стоит делать manage_order, которая то создает заказ, то отменяет его, то меняет адрес. Модель чаще ошибается именно на таких широких названиях. Гораздо понятнее create_order, cancel_order, change_delivery_address.
Имя тоже важно. Пишите его по смыслу, а не по внутреннему коду вроде run_op_17 или handler_b2. Такие имена плохо читают и люди, и модель. Если функция проверяет статус счета, так и назовите ее: get_invoice_status.
Описание не должно рекламировать функцию. Оно должно ставить рамки. Полезная формулировка звучит просто: что делает функция, когда ее вызывать и когда не вызывать. Например: "Проверяет статус счета по номеру. Не вызывай, если пользователь не указал номер счета или спрашивает список всех счетов". Эта последняя фраза часто помогает лучше любого системного промпта.
Короткий пример аргументов тоже полезен. Один, максимум два. Этого достаточно.
{
"name": "get_invoice_status",
"description": "Показывает статус счета по его номеру. Не вызывай функцию, если номера счета нет в сообщении пользователя.",
"parameters": {
"type": "object",
"properties": {
"invoice_id": {
"type": "string",
"description": "Номер счета. Пример: INV-2025-00421"
}
},
"required": ["invoice_id"]
}
}
Смешанный язык почти всегда мешает. Если диалог идет на русском, не пишите описание вроде "Создает пропуск for visitor and returns request id". Модель начинает путать термины, а команда потом спорит, что именно имелось в виду. Лучше выбрать один язык для имени, описания и примеров. Для tool calling на русском это особенно заметно в полях дат, ФИО и служебных статусов.
Хорошая схема не должна быть умной. Она должна быть скучной и ясной. Именно такие схемы функций для LLM нормально переживают смену модели, провайдера и версии SDK.
Как собирать схемы аргументов
Схема аргументов должна помогать модели выбрать действие без догадок. Если поле можно понять по-разному, модель начнет заполнять его по памяти из диалога, а не по правилам. В tool calling на русском это видно особенно быстро: естественная фраза часто длинная, с уточнениями, сокращениями и разговорными датами вроде "на завтра к девяти".
Составные поля лучше разбирать на простые части. Не делайте customer_info или delivery_details, если бэкенд все равно ждет отдельные значения. Модели проще собрать full_name, phone, date, time_slot, чем один большой объект с расплывчатым смыслом.
Там, где набор вариантов известен заранее, задайте его прямо в схеме. Если пропуск бывает только guest, employee или courier, не оставляйте строку в свободной форме. Свободный ввод нужен редко. Почти всегда он приносит мусор вроде "гость, но скорее подрядчик" вместо одного понятного значения.
Форматы тоже стоит закреплять жестко. Дата - YYYY-MM-DD, время - HH:MM, телефон - в одном выбранном виде, валюта - кодом вроде RUB, а не словами. Тогда валидатор ловит ошибки сразу, и модель быстрее начинает отвечать одинаково в похожих диалогах.
Отдельно решите, что обязательно, а что может быть пустым. Это разные вещи. Поле может быть обязательным, но принимать null, если пользователь еще не назвал значение и ваш сценарий допускает уточнение позже. А может быть необязательным совсем, если без него действие все равно выполнится.
Поле comment добавляйте только тогда, когда без него правда нельзя. Иначе модель начнет складывать туда все, что не поместилось в остальные поля: домофон, шутки пользователя, служебные заметки и случайные пояснения.
Нормальная схема выглядит скучно, и это хорошо:
{
"type": "object",
"properties": {
"visitor_name": {"type": "string"},
"visit_date": {"type": "string", "format": "date"},
"visit_time": {"type": "string", "pattern": "^([01]\\d|2[0-3]):[0-5]\\d$"},
"pass_type": {"type": "string", "enum": ["guest", "employee", "courier"]},
"phone": {"type": ["string", "null"]}
},
"required": ["visitor_name", "visit_date", "visit_time", "pass_type"]
}
Если вы гоняете такие вызовы через OpenAI-совместимый API, схема должна быть одинаково понятна и модели, и вашему сервису. Чем меньше в ней "умных" полей, тем реже вызов ломается на ровном месте.
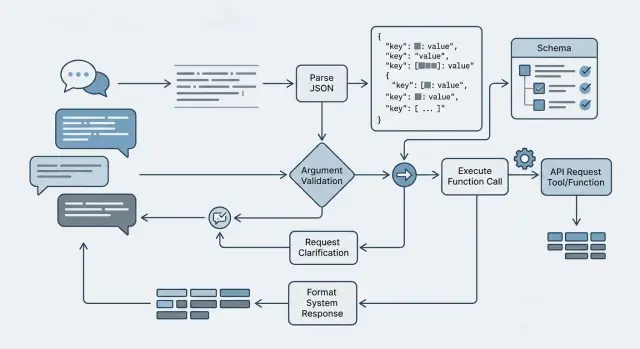
Пошаговый поток вызова
Рабочий поток для tool calling на русском лучше строить как короткий конвейер, а не как "магический" ответ модели. Сначала вы отделяете намерение пользователя от деталей запроса. Потом модель выбирает функцию по схеме. И только после этого ваш код решает, можно ли делать реальный вызов.
Первый шаг простой: понять, хочет ли пользователь вызвать инструмент вообще. Фраза "оформи доставку на завтра" похожа на действие, а "как обычно работает доставка" - это уже вопрос без вызова. На этом же шаге полезно собрать недостающие поля. Если для функции нужны дата, адрес и контакт, а пользователь дал только дату, не пытайтесь угадать остальное.
Дальше дайте модели строгую схему функции и попросите вернуть только JSON-аргументы. Хорошая практика - держать описание функции коротким, а названия полей делать однозначными. Для русского это особенно важно: модель может смешать "номер офиса", "кабинет" и "локацию", если схема расплывчатая.
Где ставить проверки
После ответа модели не вызывайте внешний сервис сразу. Сначала проверьте синтаксис JSON: типы, обязательные поля, enum, формат даты, длину строк. Потом проверьте бизнес-правила. Например, схема может принять дату, но ваша система не должна создавать заявку на прошедший день или на человека без нужного отдела.
Если данных не хватает, задайте один уточняющий вопрос. Один, а не три подряд. "Укажите дату визита" работает лучше, чем длинная анкета в одном сообщении. Так диалог не ломается, а модель не начинает заполнять пустоты догадками.
Неуверенные вызовы тоже лучше ловить отдельно. Если модель выбрала функцию с низкой уверенностью, вернула спорное значение или сама пометила поле как предположение, безопаснее остановиться и переспросить пользователя. Ошибка на этом этапе почти всегда дешевле, чем неверный вызов во внешнюю систему.
И еще одна вещь, которую часто откладывают: сохраняйте причину каждого отказа, повтора и уточнения. Не в виде общего текста, а в виде понятных кодов вроде missing_required_field, json_parse_error, business_rule_failed, low_confidence_tool_choice. По этим меткам быстро видно, где именно ломается поток: в схеме, в промпте или уже в логике сервиса.
Если вы работаете через OpenAI-совместимый API, например через шлюз вроде RU LLM, сам конвейер не меняется. Меняются модели и маршрутизация, а порядок шагов должен оставаться жестким. Именно он делает вызовы предсказуемыми.
Как обрабатывать неуверенные вызовы
Самая частая ошибка проста: команда считает, что модель либо знает ответ, либо "галлюцинирует". На деле есть два разных случая. Иногда в запросе не хватает данных. Иногда данные есть, но модель не понимает, какой инструмент выбрать или какое значение подставить. Эти случаи нельзя смешивать, иначе вы получите лишние вызовы и странные уточнения.
Разделяйте нехватку данных и сомнение
Если пользователь пишет: "Оформи пропуск на завтра", системе не хватает имени гостя и времени. Это не неуверенность. Это пустые поля, и модель должна честно вернуть режим "нужно уточнение" с перечнем недостающих аргументов.
Другой случай: пользователь пишет "закажи пропуск для Алексея на утро", а у вас есть два инструмента - разовый пропуск и заявка на доступ подрядчика. Тут поля почти заполнены, но выбор инструмента спорный. Запускать запись рано. Сначала нужно спросить только то, что снимает спор: "Алексей - гость на один день или подрядчик с доступом на срок?"
Останавливайте рискованные действия раньше
Для действий с записью, отправкой, оплатой или удалением задайте порог. Если модель не дотягивает до него, она не вызывает инструмент, а просит уточнение. Порог можно сделать разным: для чтения статуса ниже, для создания заявки выше.
Правило тут простое:
- если не хватает обязательного поля, запросите именно это поле
- если модель колеблется между двумя близкими инструментами, не запускайте ни один
- если спор идет вокруг одного аргумента, спрашивайте только про него
- если действие меняет данные, проверяйте его строже
Такой подход экономит много ручной разборки. Пользователь не получает длинную анкету, а команда не чинит неверные записи в базе.
После отказа не просите повторить весь запрос. Это раздражает и ломает диалог. Исправляйте только спорное место. Если дата уже ясна, не спрашивайте ее снова. Если имя распознано, оставьте его как есть и уточните только тип пропуска.
В OpenAI-совместимом API эту логику лучше держать вне промпта: схема функции описывает обязательные поля, а оркестратор решает, когда звать инструмент, а когда вернуть "нужно уточнение". На практике это надежнее, чем длинная текстовая инструкция.
Проверка аргументов до запуска
Схема функции сама по себе не спасает. Модель может вернуть аргументы, которые формально похожи на JSON, но не годятся для реального запуска. В tool calling на русском это видно особенно часто: даты приходят как "завтра утром", суммы как "15к", города как "СПб", а в строках остаются лишние пробелы, скобки и разговорные сокращения.
Поэтому перед вызовом инструмента нужен отдельный слой проверки. Сначала нормализуйте данные: приводите даты к одному формату, номера телефонов к одному шаблону, суммы к числу, сокращения к допустимому значению из словаря. Если пользователь написал "понедельник после обеда", не отправляйте это в бэкенд как есть. Либо преобразуйте в точный слот времени, либо верните модели ошибку и запрос на уточнение.
Обычно хватает нескольких простых проверок: диапазоны для сумм, дат, количества и времени; длина строк и обязательные поля; сверка со списком допустимых значений для города, типа документа или статуса заявки; сравнение аргументов с контекстом пользователя, сессии и прав доступа; отказ по лишним полям, которых нет в схеме.
Последний пункт часто недооценивают. Если схема не знает поле priority или internal_comment, приложение не должно молча его игнорировать. Лучше сразу вернуть ошибку валидации. Иначе модель начнет "учить" ваш API несуществующим параметрам, а вы получите странные случаи в проде.
Сверка с контекстом тоже нужна. Если пользователь авторизован для одного офиса, а модель подставила другой, вызов лучше остановить. Если лимит заявки до 100000 рублей, сумма 300000 должна отсеяться до запуска инструмента, а не после записи в систему.
Логи и тестовые данные стоит чистить отдельно. Маскируйте телефон, почту, ФИО и номера документов до записи в логи. Для отладки обычно хватает вида +7******12 или ivan***@mail.ru. В системах с требованиями 152-ФЗ это не формальность. Даже если вы используете шлюз вроде RU LLM, где маскирование PII и аудит-трейлы встроены в запросы, проверку на уровне приложения все равно лучше держать у себя.
Если аргумент нельзя уверенно привести к нужному виду, не запускайте функцию. Один уточняющий вопрос почти всегда дешевле, чем неверное действие в боевой системе.
Пример: заявка на пропуск в офис
Фраза "Оформи пропуск на завтра для Ирины после обеда" выглядит простой, но для tool calling на русском в ней сразу есть несколько скользких мест. "Завтра" нужно превратить в точную дату, "Ирина" может быть только именем, а "после обеда" - это не время, а расплывчатый интервал.
Если модель сразу вызовет функцию создания пропуска, она легко отправит сырой и неполный набор аргументов. Лучше разделить работу на два шага: сначала выделить то, что уже понятно, потом спросить только то, без чего заявку нельзя создать.
В первом проходе система может собрать черновик аргументов: имя посетителя, предполагаемую дату и примерный слот. Например, сервер нормализует "завтра" в формат YYYY-MM-DD, а фразу "после обеда" переводит во внутренний интервал, скажем 14:00-18:00. Но такой черновик еще не готов к запуску инструмента.
Как выглядит хороший ход
Если в схеме функции обязательны фамилия и офис, модель не должна гадать. Она задает один короткий вопрос: "Уточните фамилию Ирины и офис, куда она идет. Подойдет интервал с 14:00 до 18:00?"
Это лучше, чем длинный допрос из пяти пунктов. Пользователь отвечает одной репликой, и система добирает недостающие поля без лишнего шума.
Перед вызовом инструмента backend проверяет несколько вещей:
- дата пришла в нужном формате
- слот не прошел и не попадает в закрытое окно
- офис существует в справочнике
- у посетителя есть полное имя
- в очереди нет дубля на тот же день
Только после этих проверок система делает один вызов create_office_pass. Если проверка не проходит, инструмент не запускается. Вместо этого пользователь получает понятное уточнение или ошибку, например: "На завтра после 16:00 свободных слотов нет, могу оформить на 14:00-16:00".
В рабочем процессе это сильно снижает шум. Модель не придумывает фамилию, не шлет пустой office_id и не создает две заявки подряд. Для сценариев вроде пропуска это важнее любой "умной" формулировки промпта: хорошая схема, валидация аргументов и один аккуратный вызов дают предсказуемый результат.
Ошибки, которые часто ломают вызовы
Самая дорогая ошибка выглядит безобидно: команда делает одну функцию на все случаи. Модель видит что-то вроде manage_order или handle_request, а внутри там и поиск, и создание записи, и оплата. В русском диалоге это ломается быстро. Пользователь пишет: "Проверь, есть ли свободное окно", а модель уже пытается оформить заказ. Чем уже действие функции, тем меньше она гадает.
Плохо работает и другая вещь: текстовое описание обещает одно, а схема аргументов требует другое. В описании написано "город можно указать в любом виде", а схема ждет enum из трех значений. Или описание просит дату в свободной форме, а поле объявлено как date-time. Модель читает оба источника сразу и начинает смешивать правила. Потом вы получаете аргументы, которые выглядят правдоподобно, но не проходят проверку.
Часто проблему создает свободный текст там, где нужен выбор из фиксированного набора. Для человека фраза "срочно, сегодня после обеда" понятна. Для вызова функции это шум. Если поле отвечает за тип пропуска, тариф, способ доставки или статус заявки, лучше дать список значений. Свободный текст оставляйте только там, где правда нужны детали, например комментарий для охраны или пояснение к заявке.
После деплоя ломаются даже хорошие схемы. Бэкенд уже ждет новое поле, а модель по-прежнему получает старую версию описания функции из кэша, SDK или промежуточного слоя. В системах с единым OpenAI-совместимым API это особенно неприятно: код вроде не менялся, base_url тот же, а вызовы начинают падать только на части трафика. Если вы обновили схему, обновите ее везде сразу и проверяйте версию в логах запроса.
Еще один тихий источник потерь - повторный вызов. Модель не получила ответ вовремя, решила повторить запрос и создала дубль заявки. Пользователь тоже мог переформулировать ту же просьбу через десять секунд. Если операция меняет состояние, ей нужен idempotency key или другой явный способ понять: это новая команда или повтор.
Тут обычно хватает пяти правил:
- одна функция делает одно действие
- описание функции не спорит со схемой
- enum используют там, где выбор заранее известен
- схема версии N не живет рядом со схемой версии N-1
- повторный вызов не создает вторую запись
Если вызовы ломаются "иногда", ищите не магию модели, а расхождение между текстом, схемой и реальным поведением сервиса. Почти всегда проблема там.
Быстрый чек-лист перед продом
Самая частая ошибка перед запуском - проверять только хороший сценарий. Для tool calling на русском этого мало: люди пишут с опечатками, сокращают слова, меняют порядок полей и часто не договаривают важные детали.
Перед релизом проверьте несколько вещей. У каждой функции должна быть версия схемы, например create_pass_v3, и конкретный владелец. Если команда меняет обязательное поле или список допустимых значений без новой версии, старые вызовы начнут ломаться тихо.
Тесты должны гонять живые русские фразы, а не только аккуратные примеры из документации. Добавьте сокращения, разговорные формулировки и опечатки: "пропуск на завтра к 9", "нужен пропуск для Саши", "в оффис", "к Петрову в четверг".
Разделите два класса ошибок. Сначала ловите плохой JSON: сломанные кавычки, неверный тип, пропущенное поле. Потом отдельно проверяйте плохие значения: дата в прошлом, неизвестный офис, пустое имя, номер телефона не того формата.
Повтор запроса не должен создавать вторую операцию. Если сеть оборвалась после вызова функции, повтор с тем же идентификатором должен вернуть уже созданный результат, а не оформить второй пропуск.
И еще одно правило стоит договорить заранее: когда бот останавливается и передает диалог человеку. Нормальный простой вариант - после двух неудачных попыток собрать обязательные поля или при сомнении между двумя функциями.
Есть и быстрый практический тест. Возьмите 20-30 реальных фраз из поддержки или внутренних чатов и прогоните их целиком через ваш контур. Такой прогон быстро показывает, где схемы функций для LLM слишком строгие, а где модель начинает угадывать вместо того, чтобы уточнять.
Если вы работаете через OpenAI-совместимый API, проверьте этот набор хотя бы на двух моделях. Один и тот же SDK не значит одинаковое поведение: одна модель вернет чистые аргументы, другая добавит лишний текст, третья слишком уверенно вызовет не ту функцию. Лучше поймать это на стенде, чем потом разбирать дубли и ручные исправления.
Что сделать дальше
Начните не с новых промптов, а с набора живых запросов. Соберите 30-50 реальных фраз на русском из чатов, тикетов или внутренних демо. Берите не только аккуратные формулировки, но и короткие реплики, опечатки, разговорные варианты и запросы с пропущенными полями. Именно на них tool calling на русском обычно и ломается.
Потом превратите этот набор в постоянный тест. Каждый раз, когда вы меняете схему функции, правила валидации или поведение модели при сомнении, гоняйте один и тот же пакет запросов и сравнивайте результат. Так вы быстро увидите, стало лучше или вы просто сдвинули ошибку в другое место.
Смотреть можно на четыре простые категории:
- модель вызвала нужную функцию с корректными аргументами
- модель запросила уточнение, когда данных не хватало
- модель отказалась от вызова, когда действие нельзя выполнять
- модель сделала лишний вызов или собрала аргументы в неверном формате
Этого уже хватает, чтобы понять, где у вас слабое место: в описании функции, в схеме аргументов или в логике до запуска. Я бы еще отдельно смотрел на долю ошибок в коротких запросах. Они часто ломают систему сильнее, чем длинные и подробные.
Не разводите эксперименты и прод по разным контурам. Если вы тестируете на одном OpenAI-совместимом API, а в проде меняете эндпоинт, формат ошибок или способ маршрутизации моделей, вы получите лишний шум и потратите время на поиск несуществующих причин. Проще выбрать один контур и держать в нем и тесты, и боевой трафик.
Если вам нужен единый OpenAI-совместимый API с маршрутизацией моделей и хранением логов в РФ, такой сценарий удобно проверить через RU LLM. В этом случае команда меняет только base_url на api.rullm.com и продолжает использовать те же SDK, код и промпты. Это особенно удобно, когда нужно сравнить несколько моделей на одном наборе русских запросов и при этом держать логи и биллинг внутри РФ.
Когда увидите первые цифры, не спешите переписывать все заново. Сначала исправьте две-три самые частые ошибки в схеме и валидации, потом снова прогоните тесты. Такой цикл обычно дает больше пользы, чем еще один длинный инструктивный промпт.