Статус-страница при сбое LLM: шаблоны сообщений и обновлений
Статус-страница при сбое LLM: как быстро написать ясные сообщения о просадке качества, задержках и частичной недоступности без лишней воды.
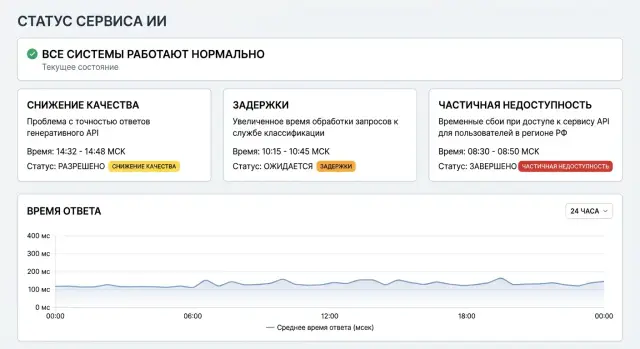
Что нужно показать сразу
Когда LLM-функция ломается, людям не нужна фраза "мы изучаем проблему". Им нужно быстро понять, что именно не работает, касается ли это их, когда все началось и что делать до следующего обновления.
В первом сообщении должны быть четыре вещи:
- какой сбой произошел: рост ошибок, долгие ответы, падение качества, недоступность части маршрутов
- кого это затрагивает: всех пользователей, один регион, часть моделей, только API или еще и личный кабинет
- когда началась проблема: точное время и часовой пояс, например 10:42 МСК
- что делать сейчас: повторить запрос позже, переключить модель, отключить чувствительный сценарий, уйти на запасной маршрут
Лучше писать конкретно, даже если деталей пока мало. Если проблема касается только части моделей через единый OpenAI-совместимый эндпоинт, так и скажите. Если ответы приходят, но качество просело, не называйте это "небольшими затруднениями". Пользователь должен сразу понять, ждать ли таймаутов, неверных ответов или полной ошибки.
Полезный шаблон первого абзаца выглядит так: "С 10:42 МСК часть запросов к LLM-моделям отвечает медленнее обычного. Сбой затрагивает клиентов, которые используют маршрут N или группу моделей X. Остальные запросы обрабатываются штатно. Пока можно переключиться на резервную модель или уменьшить таймаут повторной попытки".
Такой текст снимает лишние вопросы. Команде не придется повторять одно и то же в чате, а пользователи быстрее решат, ждать, переключаться или временно отключать функцию. Это особенно важно там, где LLM встроена в поддержку, поиск, антифрод или внутренние процессы.
Разные сбои требуют разных формулировок
Если смешать несколько симптомов в одном статусе, люди не поймут, что делать: ждать, повторять запрос, переключать модель или откатывать релиз. Для статус-страницы важен не внутренний диагноз, а то, что видит пользователь.
Падение качества и задержки часто путают, хотя это разные проблемы. При деградации качества ответы приходят вовремя, но становятся хуже: модель чаще уходит в сторону, теряет формат, путает факты или слишком сильно сокращает ответ. При задержках содержание обычно не меняется, но запросы висят дольше обычного, растет очередь, а часть клиентов упирается в лимит ожидания.
Таймаут и частичная недоступность - тоже не одно и то же. Таймаут значит, что конкретный запрос не дождался ответа за отведенное время. Частичная недоступность значит, что ломается не весь сервис, а только его часть: одна модель, один провайдер, потоковые ответы или запросы с длинным контекстом. В шлюзе с маршрутизацией к нескольким провайдерам это обычная история: одни маршруты работают нормально, другие возвращают ошибки.
Если нужен быстрый ориентир, можно держать перед глазами простые признаки:
- деградация качества: статус 200 есть, но ответ хуже обычного по смыслу, структуре или точности
- задержки: успешных ответов много, но время ответа заметно выросло
- таймауты: часть запросов обрывается по времени, часто с 504 или клиентской ошибкой ожидания
- частичная недоступность: сбой затрагивает не всех, а только часть моделей, методов или сценариев
Не стоит писать в одном инциденте сразу "падает качество, растут задержки, частично недоступен API", если это три разных пользовательских эффекта. Лучше назвать основной симптом в заголовке, а остальное вынести в обновления как следствие. Тогда поддержка даст точный совет, а пользователи быстрее выберут обходной путь: сменить модель, уменьшить контекст, отключить стриминг или просто подождать.
Как собрать первое сообщение
Первое обновление должно отвечать на три вопроса за 15 секунд: что сломалось, кого это задевает и когда ждать новый статус. Если оставить место для догадок, люди сами придумают худший вариант.
Обычно хватает четырех частей. Сначала - короткий заголовок по факту: "Задержки в ответах модели" или "Часть запросов к /chat/completions завершается с таймаутом". Причину лучше не писать, пока команда ее не подтвердила.
Дальше назовите точную зону сбоя: функцию, модель, маршрут, регион или сегмент клиентов. Чем уже рамка, тем меньше лишних вопросов в поддержку. После этого опишите влияние на пользователя простыми словами. Фраза "ответы приходят на 20-40 секунд позже" полезнее, чем расплывчатое "есть нестабильность".
В конце укажите время следующего сообщения. Лучше писать конкретно: "следующее обновление в 14:30 МСК". Даже если новостей пока нет, фиксированный ритм успокаивает.
Деталей должно быть ровно столько, сколько вы уже проверили. Не вставляйте сырые догадки вроде "похоже, проблема у провайдера" или "вероятно, это нагрузка". Такой текст быстро устаревает и ломает доверие.
Если у вас LLM-шлюз, формулируйте влияние через маршрут и поведение системы. Для RU LLM это может звучать так: "Есть задержки в маршруте Qwen 3 через API. Часть ответов приходит заметно позже обычного, у части запросов срабатывает клиентский таймаут. Следующее обновление - в 14:30 МСК".
Хорошее первое сообщение не обещает лишнего. Оно просто очерчивает границы проблемы и дает людям понятную точку ожидания.
Как публиковать обновления
Первое обновление стоит публиковать не после одной жалобы в чате, а когда проблему видно и в метриках, и в обращениях пользователей. Если выросли таймауты, просел процент успешных ответов, а саппорт получает похожие жалобы, этого уже достаточно для публичного подтверждения. Молчание в такой момент раздражает сильнее, чем короткое честное сообщение.
После этого выберите один тип инцидента. Не пытайтесь в первом тексте описать все сразу. Если люди ждут ответ по 35 секунд, пишите про задержки. Если часть запросов падает с ошибкой, пишите про частичную недоступность. Если модель отвечает хуже обычного, называйте это деградацией качества. Одна ясная формулировка читается лучше, чем набор предположений.
Удобный порядок для каждого обновления простой:
- Назовите затронутую функцию или сценарий.
- Опишите эффект без внутреннего жаргона.
- Коротко скажите, что делает команда.
- Укажите время следующего обновления.
Фраза вроде "наблюдаем рост p95 и деградацию маршрутизации" мало кому помогает. Гораздо понятнее так: "Ответы в чате приходят медленнее обычного. У части пользователей запрос завершается по таймауту". Пользователь сразу понимает, ждать ли, повторять ли запрос и стоит ли переключаться на запасной сценарий.
Если причины еще неясны, не заполняйте сообщение догадками. Лучше честно зафиксировать симптом и назначить время нового апдейта через 15, 30 или 60 минут. Люди спокойно ждут, когда знают, когда вы вернетесь с новой информацией.
Нормальное короткое обновление может выглядеть так: "Мы подтвердили рост задержек в функции генерации ответа. Часть запросов обрабатывается дольше обычного, у части пользователей возможны таймауты. Команда проверяет недавние изменения и перераспределяет трафик. Следующее обновление - в 14:30".
Шаблоны для деградации качества
Когда модель начинает отвечать хуже, это замечают не сразу. В этом и проблема: интерфейс жив, запросы проходят, а ошибки уже влияют на решения. Поэтому в статусе лучше сразу назвать симптом, время начала и дать понятную инструкцию.
Первое сообщение не должно гадать о причине. Достаточно зафиксировать факт и область влияния:
"С 12:40 МСК видим рост неточных ответов в функции X. Запросы продолжают обрабатываться, но часть результатов может быть неверной, неполной или слишком общей."
Такая формулировка честная. Она не обещает лишнего и не прячет риск за словами "наблюдаем нестабильность". Если у вас несколько функций или маршрутов к разным моделям, назовите затронутый сценарий прямо: суммаризация, поиск по базе знаний, классификация обращений.
Когда команда уже проверяет модели и маршруты, людям нужен не технический отчет, а совет, как снизить риск ошибки:
"Проверяем модель, маршруты и недавние изменения в цепочке обработки. До следующего обновления просим вручную перепроверять ответы, если они влияют на деньги, документы, клиентские сообщения или внутренние решения."
Если причина пока не ясна, не пытайтесь звучать увереннее, чем есть на самом деле. Лучше дать срок следующего апдейта:
"Источник проблемы пока не подтвержден. Продолжаем проверку и опубликуем новое сообщение через 20 минут, даже если к этому моменту причина еще не будет установлена."
Закрывающее сообщение тоже должно быть конкретным. Пользователю мало фразы "инцидент устранен":
"Качество ответов вернулось к обычному уровню. Ограничения сняты, команда продолжает наблюдение и выборочную проверку результатов."
Здесь есть одна важная деталь: пишите, что именно нужно проверять вручную. Для LLM это важнее, чем при обычном сбое API. Если ответ может содержать выдуманные факты, пропущенные поля или неверный тон, скажите это прямо. Тогда статус помогает людям работать дальше, а не просто сообщает о проблеме.
Шаблоны для задержек и таймаутов
Сообщение о задержках должно отвечать на простой вопрос: ждать, повторять или переключаться. Если текст этого не говорит, пользователь сам додумает худший вариант и начнет запускать лишние ретраи, а очередь станет еще длиннее.
Для первого сообщения лучше назвать симптом, а не гадать о причине:
"Сейчас запросы обрабатываются дольше обычного. У части вызовов срабатывает таймаут. Мы проверяем источник задержки и следим за очередью."
Если у пользователя есть обходной путь, скажите об этом прямо:
"Если запрос не срочный, повторите его чуть позже. Для критичных сценариев используйте запасной маршрут: резервную модель, другого провайдера или более короткий промпт, чтобы снизить риск таймаута."
Промежуточное обновление должно показывать движение, даже если сбой еще не снят:
"Нагрузка снижается, очередь уменьшается, но время ответа все еще выше нормы. Часть новых запросов проходит медленно, и таймауты пока сохраняются."
Если у вас есть цифры, добавьте их. Одна конкретная строка вроде "медианное время ответа выросло с 8 до 24 секунд" полезнее, чем общее "наблюдаем повышенную латентность".
Закрывающее сообщение должно фиксировать восстановление, а не просто сообщать, что команда перестала обновлять страницу:
"Работа восстановлена. Время ответа вернулось к обычному уровню, доля таймаутов пришла в норму. Мы продолжаем наблюдение, чтобы убедиться, что проблема не повторяется."
Для команд с маршрутизацией через единый LLM-шлюз запасной сценарий часто реален: можно временно увести трафик на менее загруженную модель или другого провайдера. Если такой путь есть, скажите об этом сразу.
Шаблоны для частичной недоступности
При частичной недоступности людей сильнее всего раздражает расплывчатый текст. Если часть запросов проходит, а часть падает, так и напишите. Пользователю нужно сразу увидеть границы проблемы: что именно не работает, что работает и кого это затрагивает.
Самая частая ошибка проста: команда пишет "сервис недоступен", хотя сбой затронул только часть моделей, один метод API или один внешний маршрут. Такой текст мешает клиентам быстро решить, ждать, переключать модель или временно отключать функцию.
Подойдут короткие формулировки:
- "Наблюдаем частичную недоступность: часть моделей и маршрутов сейчас не отвечает, остальные запросы продолжают обрабатываться."
- "Проблема затрагивает только генерацию текста. Остальные методы API, включая незатронутые маршруты, продолжают работать штатно."
- "Недоступна часть внешних маршрутов у одного провайдера. Доступные маршруты продолжают отвечать, переключение на альтернативные модели может временно снизить влияние сбоя."
- "Доступность восстановили по всем затронутым маршрутам. Запросы проходят в обычном режиме, команда продолжает следить за метриками."
Если у вас единый шлюз на много провайдеров, как в RU LLM, такая точность особенно важна. Пользователю мало знать, что "есть инцидент". Ему нужно понять, можно ли остаться на том же эндпоинте и просто выбрать другой маршрут, или стоит отключить только одну функцию в продукте.
Хорошее первое сообщение отвечает на три вопроса: что сломалось, что не сломалось и что делать прямо сейчас. Если упала только генерация, так и скажите, без общих слов про "нестабильную работу платформы". Если недоступен один провайдер, не создавайте лишнюю панику у тех, кто идет через другие маршруты.
Ошибки, которые раздражают пользователей
Людей злит не сам сбой, а туман вокруг него. Если в статусе написано "все работает нестабильно", пользователь не понимает главное: что сломалось, кого это задело и что делать прямо сейчас. Такая фраза звучит как попытка закрыть тему без ответа.
Лучше писать конкретно. Укажите симптом, зону влияния и текущее поведение сервиса. Например: "У части запросов выросло время ответа до 40-60 секунд" или "Ответы приходят, но качество просело: модель чаще игнорирует формат и путает поля в JSON". Даже неприятная правда успокаивает лучше, чем общий шум.
Еще одна частая ошибка - обещать срок, которого у команды нет. Фраза "починим за 15 минут" быстро превращается в лишний повод для злости, если инцидент затянется на час. Намного честнее написать: "Команда проверяет источник ошибки. Следующее обновление дадим через 15 минут". Пользователи ждут не магии, а нормального ритма обновлений.
Плохо работают и сообщения, написанные внутренним жаргоном. Если вы пишете "деградировал upstream на одном маршруте после фейловера провайдера", часть аудитории поймет, но многим это ничего не скажет. Лучше перевести это на язык последствий: "Часть запросов к одной группе моделей сейчас завершается с таймаутом. Мы переключаем трафик на другой маршрут".
Отдельно раздражают сообщения, которые спорят друг с другом. В 10:05 вы пишете "ошибка только у API", а в 10:20 уже говорите, что проблема затрагивает и веб-интерфейс, не объясняя, почему оценка изменилась. Это выглядит не как развитие расследования, а как хаос.
Нормальное обновление держится на одной логике:
- что видит пользователь сейчас
- кого затронула проблема
- что делает команда
- когда будет следующее сообщение
Если детали поменялись, скажите это прямо: "Сначала мы считали, что сбой затронул только один маршрут. Проверка показала, что проблема шире и касается части запросов к нескольким моделям". Такая честность вызывает больше доверия, чем попытка скрыть нестыковки.
Быстрая проверка перед публикацией
Пользователь должен понять сообщение почти сразу. Если на это уходит больше 10 секунд, текст слишком общий. Фразы вроде "наблюдаем нестабильность" мало помогают. Лучше назвать проблему прямо: ответы приходят медленнее обычного, часть запросов к summarization не проходит, качество генерации просело на коротких промптах.
Перед публикацией полезно быстро проверить пять вещей:
- в первом абзаце есть ясный эффект для пользователя, а не внутренний диагноз команды
- затронутые функции названы по именам: чат, embeddings, rerank, batch-задачи, конкретный API-метод
- указано время следующего обновления, даже если новых данных пока нет
- текст не перекладывает вину на клиента, интеграцию или "некорректные запросы" без проверки
- в сообщении нет догадок о причине, если команда еще их не подтвердила
Отдельно посмотрите на тон. Людей раздражают обороты, в которых компания как будто спорит с пользователем: "проблема затронула ограниченное число клиентов", "серьезного влияния нет", "рекомендуем повторить позже". Если у человека выросли таймауты и ошибки 5xx, он уже знает, что влияние есть. Лучше писать спокойно и прямо.
Есть и простой редакторский тест: можно ли вырезать половину слов без потери смысла. Например, вместо "мы видим отдельные признаки возможной деградации" напишите "качество ответов снизилось, часть результатов неточна". Вместо "команда продолжает анализ" напишите, когда будет следующее сообщение: 14:30 МСК.
Для LLM-сервисов это особенно важно, потому что сбой не всегда выглядит как полная остановка. Иногда API отвечает, но ответы стали хуже, медленнее или ломаются только на части моделей. Если это не сказать прямо, статус-страница только добавит путаницы.
Один реалистичный сценарий
В 12:40 у чат-функции падает качество ответов. Запросы не исчезли, но бот чаще путает факты, обрывает длинные сообщения и теряет контекст после 2-3 реплик. Часть пользователей видит нормальный результат, часть - заметно слабее обычного.
Первое сообщение должно появиться быстро, даже если причина пока не ясна:
"[12:47] Исследуем ухудшение качества ответов в чат-функции. Проблема наблюдается с 12:40 по московскому времени. У части пользователей ответы стали короче, менее точными или теряют контекст. Запросы продолжают обрабатываться. Следующее обновление - через 15 минут."
Пока команда разбирается, дайте людям короткий обходной путь. Он не обязан решать все, но должен снижать боль прямо сейчас: попросите повторить запрос в новом чате, сократить длинный промпт или временно перейти на более простой сценарий без длинной истории диалога.
Второе обновление уже должно показать движение:
"[13:05] Нашли источник проблемы: часть чат-запросов уходит в конфигурацию с нестабильным качеством генерации. Ограничили этот маршрут и переводим трафик на резервный. Качество ответов восстанавливается не у всех сразу. Если чат теряет контекст, начните новый диалог и отправьте последний вопрос заново."
Закрытие инцидента тоже должно быть конкретным:
"[13:28] Инцидент закрыт. С 13:22 качество ответов вернулось к обычному уровню. Причина - ошибочная маршрутизация части чат-запросов. Мы убрали проблемный маршрут и продолжаем наблюдение. Если вы получили слабый ответ с 12:40 до 13:22, повторите запрос."
Разница между плохой и нормальной формулировкой здесь особенно заметна:
- плохо: "Есть отдельные проблемы с сервисом. Команда уже работает"
- нормально: "С 12:40 чат у части пользователей отвечает хуже: теряет контекст, сокращает ответы и чаще ошибается. Запросы проходят, следующее обновление - в 13:05"
Во втором варианте есть время начала, масштаб и понятный эффект для пользователя. Этого обычно достаточно, чтобы люди не теряли время на догадки.
Что подготовить заранее
Во время инцидента команда почти всегда пишет хуже, чем в спокойный день. Люди спешат, спорят о формулировках и теряют время на согласование. Поэтому нормальная статус-страница начинается до аварии, а не после первого алерта.
Сначала подготовьте 6-8 коротких шаблонов под самые частые случаи: деградация качества ответов, рост задержки, таймауты, частичная недоступность, сбой одной модели, сбой провайдера, ошибка маршрутизации и сообщение о восстановлении. Не делайте один общий текст на все случаи. Он почти всегда звучит расплывчато.
Потом привяжите каждый шаблон к тому, что реально ломается у вас в системе: к функции, к модели, к провайдеру, к маршруту и к аудитории, которую это затрагивает. Тогда сообщение получается точным, и пользователь сразу видит, сломан весь API или только один сценарий.
Отдельно назначьте двух людей на время сбоя: один публикует, второй быстро проверяет факты и текст. Этого обычно достаточно. Если согласующих больше, первое обновление часто выходит слишком поздно.
Если вы работаете через единый шлюз вроде RU LLM, заранее разнесите статусы по моделям и маршрутам. Это особенно полезно там, где часть трафика идет к внешним провайдерам, а часть - к моделям на собственной инфраструктуре в российских ЦОДах. Один общий статус "есть сбой" в такой системе только мешает.
На практике это и есть главный вывод: хорошая статус-страница не объясняет все, а быстро отвечает на нужные вопросы. Что сломалось, кого это затронуло, что делать сейчас и когда будет следующее обновление. Если этот минимум есть, даже неприятный инцидент выглядит управляемо.
Часто задаваемые вопросы
Что обязательно написать в первом сообщении об инциденте?
Сразу напишите, что именно сломалось, кого это затрагивает, когда началась проблема и что делать прямо сейчас. Например: часть запросов отвечает медленно, сбой идет с 10:42 МСК, затронут маршрут или группа моделей, временно можно переключиться на запасную модель.
Когда уже пора публиковать статус, а не ждать?
Публикуйте статус, когда видите проблему и в метриках, и в обращениях пользователей. Не ждите полного разбора причины: короткое честное сообщение полезнее, чем молчание.
Как понять, это просадка качества или просто задержки?
Разница простая: при просадке качества ответы приходят, но становятся хуже по смыслу, формату или точности. При задержках смысл ответа обычно не меняется, но ждать приходится дольше, и часть запросов упирается в таймаут.
Что писать, если сломалась только часть моделей или маршрутов?
Напишите границы сбоя без общих слов. Скажите, какие модели, методы или маршруты не работают, и отдельно укажите, что осталось доступно. Тогда пользователи быстрее решат, ждать или сразу переключаться.
Нужно ли указывать точное время начала и часовой пояс?
Да, точное время с часовым поясом лучше ставить всегда. Пользователь сразу поймет, какие запросы могли попасть в окно сбоя, и не будет гадать, речь про локальное время или UTC.
Как часто обновлять статус во время сбоя?
Лучше назвать конкретное время следующего апдейта, а не писать расплывчато, что команда работает. Даже если новых фактов пока нет, понятный ритм обновлений снижает лишние вопросы.
Что делать, если причина инцидента еще не ясна?
Не стройте догадки. Зафиксируйте проверенный симптом, область влияния и время следующего сообщения. Если причина пока не ясна, так и напишите — это выглядит честнее, чем поспешная версия, которую потом придется менять.
Какой обходной путь лучше предложить пользователям?
Дайте один понятный обходной путь. Можно предложить повторить запрос позже, переключиться на резервную модель, сократить длинный промпт, отключить стриминг или временно убрать чувствительный сценарий, где ошибка дорого стоит.
Что написать, когда инцидент уже закрыт?
В закрывающем сообщении напишите, что именно восстановилось и с какого времени. Если есть риск, что часть ответов во время сбоя оказалась слабой или неверной, прямо попросите перепроверить или повторить такие запросы.
Какие ошибки в статусе сильнее всего злят пользователей?
Чаще всего раздражают три вещи: туманные формулировки, пустые обещания по срокам и внутренний жаргон. Вместо «есть нестабильность» лучше сказать, что у части запросов таймаут или что ответы стали хуже и теряют формат.