Резервные копии LLM-логов для аудита: схема и тесты
Резервные копии LLM-логов для аудита: как описать хранение, сроки, роли, тесты восстановления и доказательства, которые примет внутренняя проверка.
Почему одних бэкапов мало
Фраза "у нас есть резервные копии LLM-логов" для аудита почти ничего не доказывает. Аудитор проверяет не намерение, а процесс: где лежат рабочие логи, куда уходят копии, кто отвечает за них и можно ли восстановить данные без ручной импровизации.
Проблема обычно всплывает в деталях. Копия вроде есть, но команда не знает, за какой день она полная, сколько займет восстановление и можно ли поднять только нужный фрагмент, а не весь архив за месяц. В этот момент становится ясно: бэкап существует формально, но как контроль не работает.
Обычно аудит просит не общие слова, а несколько понятных артефактов:
- схему хранения рабочих логов и резервных копий;
- расписание бэкапов и сроки хранения;
- журнал операций с понятной ответственностью;
- результат хотя бы одного теста восстановления.
Рабочий контур и контур копий лучше разделять жестко. Если логи и их бэкапы лежат в одном хранилище, на одной учетной записи или в одном сегменте доступа, один сбой или одна ошибка сотрудника затронут все сразу. Для аудита это слабое место, даже если серверы находятся в российском ЦОДе.
То же самое с восстановлением. Пока вы не подняли архив в отдельной среде и не проверили его, нельзя уверенно сказать, что копия читается, индексы собираются заново, а нужный период логов поднимется в разумный срок. Для сервисов с чат-ботами это особенно заметно: инциденты почти всегда разбирают по окну времени, например 14:00-16:00, а не по принципу "давайте развернем весь месяц и потом поищем".
Отдельный вопрос - персональные данные. Если в логах есть промпты, ответы, user ID, IP-адреса, номера заявок или другие идентификаторы, аудит ждет простого и прямого описания: что маскируется до записи, что попадает в копию, кто имеет доступ, где физически лежат данные и как это связано с 152-ФЗ и внутренними сроками удаления.
Для российской команды этого мало проговорить на встрече. Нужны схема хранения в российских ЦОДах, журнал операций и короткий протокол восстановления с датой, временем и результатом. Тогда у аудита есть что проверять, а у команды - что показывать и защищать по фактам.
Что должно попадать в копии
В резервной копии нужен не один файл с событиями, а набор данных, по которому можно собрать историю запроса без догадок. Аудитор обычно смотрит не только на наличие архива, но и на его состав: хватит ли этого набора, чтобы восстановить запись, проверить удаление и объяснить спорный инцидент.
Чаще всего в копии входят четыре слоя. Первый - основные таблицы или коллекции с событиями запросов и ответов. Второй - выгрузки в object storage, например JSONL, CSV или Parquet. Третий - архивные бакеты с дневными или часовыми срезами и служебными манифестами. Четвертый - журналы задач, которые запускают бэкап, проверку целостности и удаление по сроку хранения.
Одного текста промпта и ответа почти никогда не хватает. Чтобы запись имела смысл, нужны метаданные: точное время, request_id или trace_id, модель, провайдер, статус ответа, коды ошибок, токены и стоимость. Если у вас есть маршрутизация между несколькими моделями или провайдерами, добавьте поле маршрута, policy version или другой признак, по которому можно понять, почему запрос пошел именно туда.
Полезно сохранять и связующие данные. Это логи очередей, записи о ретраях, результаты асинхронной обработки, манифесты архивов и контрольные суммы. Без них восстановление быстро превращается в ручной разбор по кускам, а такие разборы аудиторы не любят по одной причине: их трудно повторить и трудно проверить.
Служебные журналы тоже должны попадать в копии. По ним видно, когда задача стартовала, чем закончилась, сколько объектов обработала и были ли пропуски. Это касается и удаления: кто запустил задачу, что попало под удаление, что действительно стерлось и что осталось по исключению.
Если после маскирования в наборе все равно остаются персональные данные, такие архивы лучше помечать отдельно. Чаще всего это фрагменты промптов, вложения, customer notes и диагностические дампы. Простая метка класса данных в каталоге копий уже сильно помогает: она показывает, что команда понимает, какие архивы несут повышенный риск, и не смешивает их с обычной телеметрией.
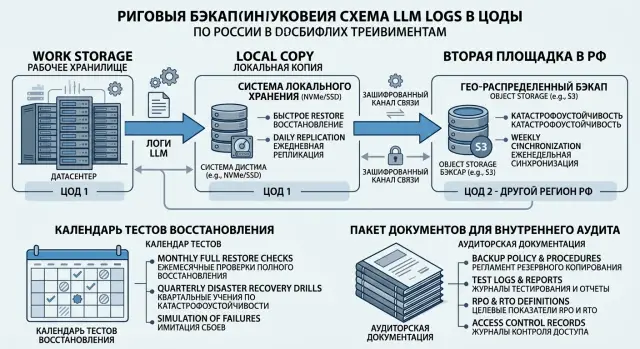
Как описать схему хранения в российских ЦОДах
Схема хранения для аудита должна читаться за пару минут. Никому не нужна красивая диаграмма без смысла. Нужен короткий ответ на четыре вопроса: где лежат рабочие логи, где лежат копии, кто может к ним получить доступ и что мешает удалить их по ошибке.
Базовая схема для LLM-сервиса обычно выглядит так: рабочие логи хранятся в основном российском ЦОДе, рядом есть локальная копия для быстрого восстановления, а еще одна копия уходит на вторую площадку в РФ. Такая раскладка закрывает сразу два обычных риска - сбой на одном узле и потерю целой площадки.
Если сервис обрабатывает обращения клиентов, лучше писать совсем конкретно. Например: логи запросов, audit trail и служебные метаданные сохраняются в основном контуре; инкрементные копии создаются каждые N часов; ежедневная полная копия отправляется во второй российский ЦОД; доступ к обеим копиям идет только через выделенные сервисные роли.
В описании обычно хватает пяти пунктов:
- где находится рабочее хранилище;
- где лежит локальная копия для быстрого восстановления;
- где хранится вторая копия на другой площадке в РФ;
- как разделены учетные записи, проекты и сетевые сегменты;
- какие сроки хранения, правила шифрования и удаления действуют для каждого набора.
Фразу "копии изолированы" лучше не использовать без деталей. Гораздо полезнее написать, что продакшен и бэкапы живут в разных аккаунтах, доступ к ним идет через разные роли, а сеть между сегментами ограничена правилами. Тогда видно, что один скомпрометированный токен или одна ошибка администратора не откроют сразу все хранилища.
Шифрование тоже стоит описывать прямо: при передаче и при хранении. Для LLM-логов это не формальность. Даже после маскирования в них остаются чувствительные поля: идентификаторы запросов, трассировка, служебные теги, отметки AI-Law. Рядом стоит указать, кто управляет ключами и кто может читать расшифрованные данные.
Защиту от случайного удаления лучше вынести отдельной строкой. Обычно для этого включают immutable-период, версионирование объектов и запрет на прямую перезапись архивов. Это простая мера, но она хорошо смотрится на аудите, потому что показывает: архив нельзя "почистить" одной командой в спешке.
Какие сроки и роли закрепить
На практике аудит почти всегда упирается не в сам факт бэкапов, а в цифры и ответственность. Если в регламенте написано "копии выполняются регулярно", это ничего не значит. Нужны точные интервалы, допустимая потеря данных и конкретные люди или роли.
Сначала зафиксируйте частоту копирования. Для LLM-логов одной ночной полной копии обычно мало. Если вы храните запросы, ответы, audit trail, метки AI-Law и записи о маскировании PII, разумнее описать режим так: полная копия раз в сутки, добавочная - каждый час или чаще. Интервал зависит от нагрузки. Если сервис обрабатывает тысячи запросов в час, потеря даже двух часов логов ломает расследование.
Дальше нужен понятный порог потерь. В технических документах это называют RPO, но для внутреннего аудита лучше писать по-человечески: "при сбое допустима потеря не более 60 минут логов". Если требования строже, укажите 15 минут или другой интервал, но только если инфраструктура действительно выдерживает такой режим.
Отдельно зафиксируйте срок возврата доступа к логам. Это уже про восстановление: за сколько часов команда должна поднять архив или хотя бы минимально рабочий поиск. Полезно разделить две цели. Например, доступ к архиву восстанавливается за 4 часа, а поиск по критичным логам - за 2 часа. Это понятнее и честнее, чем одна общая цифра.
С ролями тоже не стоит расплываться. Должно быть ясно, кто запускает процесс, кто проверяет результат и кто подменяет основного сотрудника ночью, в отпуске или во время инцидента. Обычно хватает трех ролей. Владелец бэкапов следит за расписанием, ошибками и местом хранения. Проверяющий смотрит отчеты, выборочно сверяет копии и подтверждает тесты восстановления. Замещающий сотрудник получает те же инструкции и минимально нужные доступы, чтобы процесс не останавливался.
Если логи и копии хранятся в российских ЦОДах, это лучше указать в том же документе, а не выносить в отдельную презентацию. Так аудитору проще связать хранение, доступ и восстановление в одну рабочую схему.
Как провести тест восстановления
Фраза "резервные копии делаются по расписанию" не убеждает. Нужен повторяемый сценарий: какой набор вы берете, куда его поднимаете, что именно проверяете и чем подтверждаете результат.
Сначала выберите свежий, но уже закрытый по записи набор. Обычно это сутки или несколько часов с понятной контрольной датой, например 10 марта с 00:00 до 23:59 по Москве. Эту дату нужно зафиксировать в заявке или акте, чтобы потом не спорить, что именно команда восстанавливала.
Поднимать копию лучше в отдельном тестовом контуре. Не рядом с рабочей базой и не в том же хранилище. Иначе можно смешать боевые данные с проверкой или случайно затереть текущие записи. Для логов с идентификаторами запросов, AI-Law метками и PII это особенно неприятный сценарий.
После восстановления мало проверить, что архив просто открылся. Лучше пройтись по короткому набору признаков:
- совпадает ли число записей в исходном наборе и в восстановленной копии;
- нет ли дыр по времени и по интервалам;
- сохранились ли обязательные поля вроде request_id, provider, model и технических меток;
- осталось ли маскирование персональных данных;
- работает ли поиск и стандартная выгрузка для разбора инцидентов.
Хорошая практика - поручать тест не тому же инженеру, который настраивал бэкап. Тогда видно, можно ли выполнить восстановление по инструкции, а не по памяти. Это мелочь, но она быстро показывает, живой у вас процесс или он держится на одном человеке.
В конце нужен короткий акт. Обычно достаточно пяти полей: кто запускал тест, какой набор восстановили, в какой контур, сколько занял процесс и какие расхождения нашли. Добавьте время старта и окончания, выгрузку сверки или скриншоты, а если были ошибки - решение по ним.
Нормальный результат выглядит без украшений: тест запустил дежурный инженер, восстановили 24 часа логов, сверили 1 248 317 записей, поиск по request_id работает, маскирование сохранилось, полный цикл занял 47 минут. Такая запись полезнее длинного описания политики хранения.
Что показать внутреннему аудиту
Аудитор обычно не ждет идеальную систему. Он смотрит, контролирует ли команда путь лога, умеет ли восстановить данные и понимает ли, кто за что отвечает. Поэтому пакет материалов должен быть коротким, но проверяемым.
На практике хватает одной схемы на одну страницу и нескольких приложений. На схеме должен быть виден путь от боевого лога до второй копии: где запись создается, где проходит маскирование PII, в какое основное хранилище попадает, когда уходит в резервную копию и на какой площадке лежит дублирующий архив.
К схеме обычно прикладывают:
- выгрузку расписания задач резервного копирования с частотой, окном запуска и статусом последних прогонов;
- протокол последнего теста восстановления;
- матрицу доступа по ролям;
- журнал сбоев и пропусков бэкапов за выбранный период;
- выписку по срокам хранения для рабочих логов, копий и удаленных архивов.
Этого достаточно, чтобы разговор быстро перешел от общих слов к фактам.
Дальше аудитор почти всегда делает несколько ручных сверок. Он смотрит дату последнего успешного бэкапа и дату последнего теста восстановления. Если копии делаются каждый день, а тест был полгода назад, это плохой знак. Он может попросить показать, что вы восстанавливали не абстрактный архив, а конкретный набор логов за один день, проверяли полноту записей и сравнивали хэши, число строк или другой понятный признак целостности.
Хорошо работает и простой живой пример. Допустим, сервис с чат-ботом хранит журналы запросов, маскирует персональные данные, держит основную копию в одном российском ЦОДе и ночной бэкап во втором. Для проверки достаточно показать последний успешный запуск, один неуспешный прогон с объяснением причины и акт восстановления в тестовую среду. Такой набор выглядит убедительнее, чем объемная политика без следов реальной работы.
Если какого-то документа нет, лучше сказать об этом прямо и назвать срок подготовки. Аудиторы обычно спокойно относятся к пробелам, если команда не пытается их спрятать.
Где команды ошибаются чаще всего
Первая типичная ошибка - копировать только текст запросов и ответов. На проверке быстро выясняется, что восстановить полную картину невозможно. Без request_id, времени, версии схемы, маршрута на модель, признака маскирования PII и аудиторских записей лог перестает быть полезным и для расследования, и для аудита.
Вторая ошибка еще неприятнее: резервные копии лежат в том же контуре, где живет продакшен. Один сбой в хранилище, одна ошибка в правах или одна неудачная автоматизация - и вы теряете и рабочие данные, и архив. Разнесение по площадкам внутри РФ здесь выглядит не как бюрократия, а как здравый минимум.
Третья проблема всплывает после небольших изменений. Команда добавила новое поле, поменяла JSON-схему, перешла на другой формат логов или подключила нового провайдера моделей, но тест восстановления не повторила. Через месяц бэкап формально есть, а парсер не читает часть записей. Это очень частый и очень скучный сбой, поэтому про него забывают до первой проверки.
Четвертая ошибка - слишком широкий доступ. Архивы видят администраторы, аналитики, разработчики, иногда подрядчики. Для логов с персональными данными это лишний риск. Лучше заранее держать короткий список ролей, вести журнал доступа и отдельно описать временные выгрузки на период расследования.
Еще один частый промах - отсутствие описанного удаления старых копий. Тогда архивы копятся бесконечно, сроки хранения разъезжаются, а ответ на вопрос аудитора зависит от памяти сотрудников. Гораздо лучше работает короткий регламент: что хранится, сколько хранится, кто удаляет, чем подтверждает удаление и где остается запись об этой операции.
Пример простой схемы для сервиса с чат-ботом
Для сервиса с чат-ботом не нужна схема на десять страниц. Обычно хватает понятной цепочки: где лежат рабочие логи, как создаются резервные копии, куда уходит вторая копия и как команда проверяет восстановление.
Рабочий контур пишет в основное хранилище три группы данных: запросы пользователей, ответы модели и технические ошибки. Если бот работает через LLM API-шлюз, в логах часто есть еще модель, провайдер, время ответа, код ошибки и идентификатор запроса. Этого уже хватает, чтобы разбирать инциденты, споры по биллингу и жалобы пользователей.
Дальше схема может быть совсем простой. Каждый час система сохраняет изменения из рабочего хранилища в инкрементную копию. Ночью делает полную копию за сутки. Вторая копия уходит в другой российский ЦОД. Раз в месяц команда восстанавливает выбранный день логов в тестовый контур.
Такой режим легко объяснить и поддерживать. Часовые копии закрывают свежие изменения, ночная полная копия упрощает сбор архива, а вторая площадка снижает риск, если на основной стороне сломается хранилище или доступ к нему.
Для аудита, конечно, мало самой схемы на словах. Нужны следы того, что процесс живой: схема хранения, журнал задач резервного копирования и протокол последнего теста восстановления. В журнале должны быть время запуска, статус, размер копии и информация о том, кто получил алерт при сбое. В протоколе - какой день восстанавливали, сколько длился процесс, сколько записей вернулось и совпало ли их число с исходным набором.
Если сервис работает в российском контуре и хранит данные по требованиям 152-ФЗ, обе копии и тестовую среду тоже лучше держать в российских ЦОДах. Это обычно снимает лишние вопросы еще до начала подробной проверки.
Быстрая проверка перед встречей с аудитором
Перед встречей полезно сделать короткий прогон по документам. Аудитор смотрит не на размер папки с бэкапами, а на порядок. Если команда за пять минут не может показать схему хранения, список систем и свежий результат восстановления, разговор сразу уходит в детали, которые трудно быстро подтвердить.
Удобно держать один лист со схемой и простой таблицей. На нем должно быть видно, где рождаются логи, куда они пишутся, где лежат резервные копии, в каком российском ЦОДе хранится основная копия и где находится вторая. Рядом перечислите системы из цепочки: приложение, API-шлюз, хранилище логов, сервер резервного копирования, архив и журнал удаления.
Перед самой встречей проверьте пять вещей:
- у каждой копии есть срок хранения, владелец и понятное имя системы;
- последний тест восстановления прошел недавно и без ручной правки файлов;
- в отчете есть время начала, время окончания и список восстановленных объектов;
- можно показать пример удаления просроченной копии по правилу;
- для логов с персональными данными описаны хранение, маскирование и доступ.
Особенно часто проваливается пункт с владельцем. Копия есть, но никто не может быстро сказать, кто отвечает за срок, кто запускает тест и кто подписывает результат. Для аудита это плохой сигнал.
Сценарий восстановления лучше не усложнять. Проверяющему не нужен красивый стенд. Ему нужен понятный и повторяемый процесс: взяли архив за выбранную дату, развернули его в чистую среду, сверили число записей, проверили читаемость полей и права доступа. Если во время теста команда вручную исправляла пути, формат или метаданные, такой прогон лучше не считать успешным.
Что сделать дальше
Соберите один рабочий документ, который аудитор сможет понять без устных пояснений. Если схема разбросана по тикетам, таблицам и переписке, пользоваться ей неудобно. Для резервных копий LLM-логов это особенно заметно: копии могут работать, но доказать порядок хранения и восстановления все равно сложно.
В таком документе обычно достаточно четырех блоков: какие логи входят в копии и какие поля маскируются; где лежат основные и резервные наборы и кто имеет к ним доступ; как часто делается бэкап, сколько хранятся версии и по какому правилу они удаляются; кто запускает восстановление, кто проверяет результат и кто подписывает отчет.
После этого поставьте в календарь несколько тестов восстановления хотя бы на полгода вперед. Лучше сразу указать даты, контуры и ответственных. Один тест можно делать на сутки логов, второй - на выборку за неделю, третий - на восстановление вместе с журналом доступа и аудит-трейлом.
После каждого прогона делайте короткий разбор на 15-20 минут. Запишите, сколько заняло восстановление, какие шаги были лишними, где не хватило прав и какие проверки пропустили. Исправления лучше вносить в регламент сразу, пока команда помнит детали.
Если часть трафика идет через RU LLM, это тоже стоит коротко отметить в пакете для аудита: платформа хранит логи и бэкапы на серверах в РФ, маскирует PII и пишет audit trails по каждому запросу. Для команд, которым нужен единый OpenAI-совместимый эндпоинт внутри российского контура, такая пометка помогает быстрее связать схему хранения, маршрутизацию запросов и требования 152-ФЗ.
Если полного пакета пока нет, не ждите большой ревизии. Сделайте черновик на пару страниц, назначьте первый тест на ближайшие две недели и после него доведите документ до рабочего состояния.
Часто задаваемые вопросы
Почему одних бэкапов логов недостаточно для аудита?
Потому что сама копия ничего не доказывает. Аудит смотрит на весь процесс: где лежат рабочие логи, куда уходят копии, кто за них отвечает и можно ли поднять нужный период без ручной сборки архива.
Что показать внутреннему аудиту в первую очередь?
Обычно хватает схемы хранения, расписания бэкапов, журнала операций и протокола хотя бы одного теста восстановления. Если эти документы свежие и в них есть даты, роли и результат проверки, разговор сразу идет по фактам.
Какие данные должны попадать в резервную копию LLM-логов?
Минимум — сами события запросов и ответов вместе с метаданными. Добавьте точное время, request_id или trace_id, модель, провайдера, статус, коды ошибок, токены, стоимость и признак маршрута, если запросы идут через несколько моделей или провайдеров.
Как лучше разнести рабочие логи и резервные копии?
Рабочее хранилище и копии лучше разнести по разным аккаунтам, ролям и площадкам. Для внутреннего аудита в РФ обычно ждут схему, где основное хранилище, локальная копия для быстрого подъема и вторая копия находятся в российских ЦОДах и не делят один и тот же доступ.
Какой график бэкапов считать нормальным?
Для LLM-логов одной ночной полной копии чаще всего мало. Нормальный базовый режим — полная копия раз в сутки и добавочная каждый час или чаще, если сервис теряет слишком много данных даже за короткий сбой.
Как провести тест восстановления так, чтобы аудит его принял?
Берите закрытый по записи набор за конкретный день или несколько часов и поднимайте его в отдельный тестовый контур. Потом сверяйте число записей, дыры по времени, наличие обязательных полей, сохранность маскирования и работу поиска по request_id.
Как оформить ответственность за бэкапы и восстановление?
Закрепите не абстрактную команду, а конкретные роли. Один человек или роль следит за расписанием и ошибками, второй проверяет отчеты и тесты, третий подменяет основного сотрудника ночью, в отпуске или во время инцидента.
Что делать, если в логах есть персональные данные?
Сначала маскируйте лишние данные до записи в лог, а потом отдельно опишите, что все же попадает в архив. В документе укажите, где физически лежат копии, кто имеет доступ, как идет удаление по сроку хранения и как это связано с требованиями 152-ФЗ.
Где команды ошибаются чаще всего?
Чаще всего команды копируют только текст промптов и ответов, держат архив рядом с продакшеном и месяцами не проверяют восстановление после смены схемы логов. Еще один частый промах — слишком широкий доступ к архивам и отсутствие понятного правила удаления старых копий.
Как быстро подготовиться к встрече с аудитором?
Соберите один короткий пакет: схему хранения на одной странице, свежий статус последних бэкапов, протокол последнего восстановления и матрицу доступа. Перед встречей проверьте, что вы можете быстро показать владельца каждой копии, срок хранения и пример удаления просроченного архива.