RAG для табличных регламентов: когда строки, факты, SQL
RAG для табличных регламентов: как выбрать между хранением строк, извлечением фактов и SQL, чтобы не путать цены, пороги, сроки и исключения.
Почему таблицы ломают обычный RAG
Обычный RAG хорошо работает там, где мысль идет подряд: абзац, следующий абзац, вывод. Таблица устроена иначе. Смысл ячейки почти никогда не живет сам по себе. Он зависит от шапки, соседних колонок, единицы измерения, сноски внизу и иногда даже от названия листа.
Если в ячейке стоит "10 500", человек быстро считывает контекст. Модель - нет. Без колонок "Тариф", "Условие", "Период" и примечания мелким шрифтом это число почти пустое: цена, лимит, штраф или минимальный платеж.
Чанкинг ломает картину еще сильнее. Когда документ режут по символам или строкам, легко получить один фрагмент с ценой, второй с условием скидки, третий со сноской "только для новых клиентов". Поиск найдет один кусок, но не всю связку. Дальше модель начнет достраивать пропуски сама, а в таблицах это почти всегда приводит к ошибке.
На прайс-листах промах виден сразу. В одной строке рядом живут цена, порог объема, валюта, НДС и срок действия. Потеряли один столбец - получили неверный ответ. В регламентах проблема другая: правило часто размазано по нескольким строкам, а исключение уходит в примечание. Если RAG достал только основное правило, ответ будет уверенным, но неверным.
Отдельная боль - версии. Таблицы меняются часто: новая цена, новый лимит, новая редакция регламента. Если в индекс попали старая и новая версии, модель охотно смешивает их в одном ответе. Она берет цену из обновленного файла, а условие применения из старого. Для пользователя такой ответ звучит правдоподобно, и в этом его опасность.
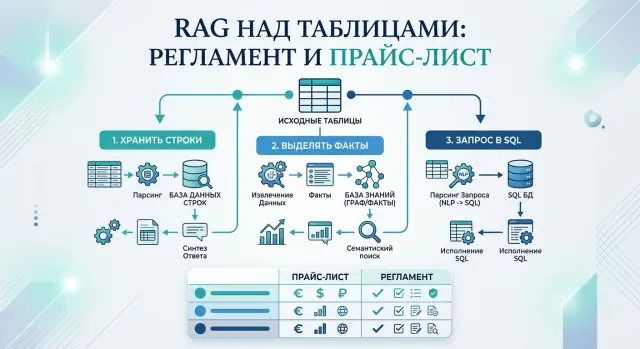
Есть и еще один нюанс: разные таблицы решают разные задачи. Регламент обычно требует точного ответа по правилу, исключению и дате действия. Прайс-лист чаще просит отфильтровать строки, сравнить условия или что-то посчитать. Поэтому RAG для табличных регламентов редко стоит строить как "просто векторный поиск по чанкам". Таблица - это маленькая структура данных, и обращаться с ней лучше как со структурой, а не как с набором абзацев.
Когда хватает хранения строк
Если таблица маленькая или средняя, а вопросы пользователей почти повторяют текст в ячейках, сложная схема не нужна. Часто хватает самого простого варианта: хранить каждую строку как отдельный фрагмент и отдавать ее в RAG вместе с названием таблицы, шапкой колонок, единицами измерения и периодом действия.
Такой подход хорошо работает там, где человек ищет формулировку, правило или конкретное значение, а не расчет. Для RAG для прайс-листов и регламентов это часто самый дешевый старт. Команда быстро собирает индекс, видит первые результаты и не тратит недели на разметку фактов или проектирование SQL-слоя.
Представьте B2B-прайс-лист. В строке указано: пакет "Старт", 500 обращений в месяц, 18 руб. за обращение, подключение 0 руб. Если вопрос звучит как "сколько стоит пакет Старт" или "есть ли плата за подключение", поиск по строкам обычно находит нужный фрагмент без лишней логики. Модель потом просто пересказывает строку или цитирует ее.
Этот способ особенно удобен, когда таблица короткая, похожие строки не путают поиск, пользователи спрашивают почти теми же словами, что и в таблице, а ответ лучше показать как цитату, а не как вычисление. Если структура колонок еще и не меняется каждый месяц, решение живет долго и без лишнего ухода.
Есть одна деталь, которую часто упускают. Не храните голую строку без контекста. Если в таблице есть колонка "Лимит" и рядом нет шапки, модель не поймет, это лимит по запросам, по пользователям или по дням. Поэтому каждая строка должна идти вместе с названием таблицы, названиями колонок, единицами и, по возможности, датой действия версии.
Простой шаблон может выглядеть так: "Прайс-лист. Тариф: Старт. Лимит: 500 обращений/мес. Цена: 18 руб./обращение. Подключение: 0 руб." Такой текст индексируется заметно лучше, чем сырые CSV-ячейки.
Когда этот вариант уместен
Если вам не нужно считать суммы, фильтровать десятки строк и сравнивать условия между несколькими записями, хранение строк часто закрывает задачу. Для регламентов этот вариант особенно удобен, когда сотруднику важно увидеть исходную формулировку, а не пересказ.
Я бы начинал именно с него, если таблица живет спокойно и люди задают простые вопросы. На слайде это выглядит скучно, зато в продакшене часто работает с первой версии.
Когда лучше выделять факты
Факты нужны там, где ответ держится не на формулировке строки, а на точных полях. Если пользователь спрашивает "какая ставка", "какой лимит" или "на какой срок действует условие", хранить таблицу как обычные текстовые куски уже неудобно. Модель может найти нужную строку, но легко перепутает число, пропустит исключение или склеит условия из соседних записей.
Это особенно заметно в табличных регламентах, где одна строка несет сразу несколько смыслов: тариф, сегмент клиента, роль пользователя, срок действия, порог по обороту и сноску с исключением. Для человека такая строка читается нормально. Для поиска по тексту она слишком плотная.
Когда строка уже не справляется
Если в одной записи лежит несколько условий, лучше разложить ее на факты и правила. Вместо одного куска текста вы храните поля вроде segment, tariff, role, price, rate, limit, term, valid_from, valid_to, exception, source_row_id.
Такой слой особенно нужен, когда вы отвечаете по конкретным полям, а не по общему описанию; когда в строке одновременно живут правило и исключение; когда вопросы приходят по сегменту, тарифу или роли; и когда ответ потом надо проверять по JSON-схеме или по набору обязательных полей.
Простой пример: "Для SMB на тарифе Pro ставка 7,5% на 90 дней, лимит до 5 млн руб., кроме партнеров с персональной скидкой". Если оставить это текстом, модель может вернуть ставку верно, но забыть про лимит или исключение. Если выделить факты, вы отдельно фильтруете segment=SMB, tariff=Pro, term=90, а исключение проверяете как отдельное правило.
Что это дает на практике
Главный плюс - ответ можно валидировать машинно. Вы сравниваете не красивую фразу модели, а структуру: нашла ли она цену, срок, лимит и основание из нужной строки. Ошибки становятся заметны сразу.
Еще один плюс - проще собирать ответ из нескольких источников. Цена может лежать в прайсе, лимит - в приложении к договору, а исключения - в регламенте доступа по ролям. Когда все приведено к фактам, модель не пересказывает документы по памяти, а собирает ответ из проверяемых полей.
Но не дробите все подряд. Если сноска двусмысленна или условие зависит от живого текста, сохраните рядом исходную строку и идентификатор источника. Факты дают точность, а исходный текст страхует от потери смысла.
Когда нужен SQL
SQL нужен, когда вопрос просит не просто найти строку, а отфильтровать данные, сравнить записи или что-то посчитать. Обычный RAG хорошо находит похожий фрагмент, но плохо отвечает на запросы вроде "какая минимальная цена действует в Казани для тарифа Business с 1 июля". Тут мало найти нужный кусок таблицы. Нужно применить условия и вернуть точный результат.
Это особенно заметно в прайс-листах и регламентах, где ответ зависит сразу от нескольких полей: суммы заказа, даты начала действия, региона, тарифа, типа клиента. Если модель сама читает строки и пытается считать в тексте, она часто путает диапазоны, берет старую запись или пропускает исключение в одной из колонок.
SQL почти неизбежен, когда пользователь задает фильтры по нескольким полям, когда ответ требует сортировки или выбора по диапазону, когда таблица часто меняется и представление для поиска быстро стареет, и когда нужно посчитать минимум, максимум, остаток, сумму или количество.
Есть простой тест. Если человек, открыв таблицу, первым делом включил бы фильтр, а не поиск по словам, значит, вам нужен SQL. Если он бы еще отсортировал колонку по цене или дате, тем более.
Небольшой пример. В таблице есть колонки "регион", "тариф", "дата действия", "цена", "скидка от суммы". Пользователь спрашивает: "Какая итоговая цена для клиента из Самары при заказе на 1,2 млн рублей в августе?" RAG найдет похожие строки, но итог зависит от даты и порога скидки. SQL быстро выберет записи по региону и периоду, проверит диапазон суммы и вернет нужную строку или набор строк для расчета.
Для больших таблиц это почти всегда надежнее. Когда прайс обновляют каждый день, векторный индекс быстро стареет. SQL работает по свежим данным и не заставляет модель гадать, какая версия актуальна.
Лучше всего работает связка: LLM переводит вопрос в понятный запрос, SQL достает точные строки и агрегаты, а модель потом объясняет результат простым языком. Сам расчет не стоит отдавать модели, если цена зависит от даты, региона, остатка на складе или тарифной сетки.
Как выбрать схему за пять шагов
Выбор схемы лучше начинать не с индекса и не с модели, а с реальных вопросов. Уже на первых двух десятках обращений обычно видно, что одна и та же таблица используется по-разному: где-то нужна точная цитата из примечания, где-то - одно поле без лишнего текста, а где-то - выборка по фильтрам.
- Соберите около 30 реальных вопросов. Подойдут тикеты, письма, сообщения в чатах, запросы от продаж и операций. Чем ближе они к повседневной работе, тем меньше шанс построить схему для демо, а не для жизни.
- Пометьте каждый вопрос одним типом: "цитата", "факт" или "выборка". Вопрос "как это написано в регламенте?" обычно ведет к хранению строк. Вопрос "какой лимит у тарифа B?" уже тянет к фактам.
- Отдельно вынесите все случаи, где нужен точный расчет. Скидки по объему, НДС, сроки оплаты, пороги и суммирование по диапазонам лучше не оставлять на догадку модели.
- Проверьте схему на 10-20 живых таблицах, а не на одной аккуратной тестовой. Нужны прайс-листы со сносками, пустыми ячейками, разными названиями колонок и несколькими версиями одного документа.
- Если один способ не закрывает все вопросы, оставьте смешанный подход. Это нормально: строки дают точную цитату, факты держат структуру, SQL отвечает за фильтры и расчеты.
На простом примере это видно сразу. Если менеджер спрашивает: "Есть ли скидка для партнера при заказе от 500 единиц?", поиск по строкам может найти нужный абзац, но не всегда правильно посчитает итог. Если вопрос звучит так: "Покажи все позиции дороже 50 000 рублей, кроме архивных", здесь уже нужен SQL.
Хорошая схема не обязана выглядеть изящно. Она должна стабильно отвечать на ваши реальные вопросы и не разваливаться на грязных таблицах из продакшена.
Пример с B2B-прайс-листом
У дистрибьютора техники прайс живет в Excel и меняется почти каждую неделю. В таблице есть SKU, базовая цена, пороги по объему, региональные коэффициенты и тип клиента. Отдельный регламент хранит сноски: где скидка не действует, кто согласует спеццену и до какой даты работает исключение.
Менеджер спрашивает: "Сколько будет стоить 1200 единиц модели XR-24 для клиента из Урала?" Юрист задает другой вопрос: "Есть ли исключение для госкомпаний и когда оно заканчивается?" Документы одни и те же, но способ получения ответа разный.
Если сделать только RAG по строкам, модель часто найдет нужную строку и подтянет сноску про регион. Ошибка всплывает на пороге скидки. В прайсе могут стоять очень похожие записи: скидка 7% от 1000 штук и скидка 9% от 1500. Модель видит похожий текст, берет соседнюю строку и уверенно называет не ту цену. Для прайс-листа это плохой сценарий: менеджер отправит КП, а потом придется его переделывать.
В таком случае роли лучше разделить. SQL считает цену по SKU, объему закупки, региону и типу клиента. Слой фактов хранит исключения из регламента, сроки действия и статусы. RAG по строкам ищет редкие формулировки и сноски, которые трудно уложить в поля.
Тогда ответ собирается честно. SQL возвращает: базовая цена 12 400 рублей, порог 1000+ достигнут, региональный коэффициент 1.03, итоговая цена 11 879. Слой фактов добавляет, что для клиента со статусом "госзакупка" скидка не применяется до конца квартала, если нет отдельного согласования. RAG достает текст сноски, чтобы юрист видел точную формулировку, а не пересказ.
Есть и обратная сторона. SQL сам не поймет фразу вроде "для Калининграда цена фиксируется на 5 рабочих дней после подтверждения заказа". Такое правило проще найти по строкам или хранить как отдельный факт с датой начала и конца. Поэтому извлечение фактов из таблиц полезно там, где правило должно жить отдельно от ячейки и меняться без пересборки всей схемы.
Именно так табличный RAG обычно работает лучше всего: таблица отвечает за вычисление, факты держат исключения и статусы, а поиск по строкам закрывает хвосты, где нужен исходный текст. Если смешать все в один индекс, модель начнет гадать там, где цена должна считаться точно.
Где команды ошибаются чаще всего
Ошибки обычно начинаются еще до выбора модели. Команда режет таблицу на куски как обычный текст и теряет шапку. После этого строка "от 100 шт., скидка 7%, регион B" уже почти ничего не значит, потому что названия колонок исчезли.
Вторая частая проблема - смешение версий. В одном индексе лежат прайс-лист за январь, обновление за март и отдельная вкладка с акцией на квартал. Пользователь спрашивает текущую цену, а система собирает ответ из разных дат и выдает уверенный, но неверный результат.
С датами лучше быть скучным и строгим. Храните период действия рядом с каждой строкой или фактом и фильтруйте по нему до поиска. Если в ответе нельзя показать, из какой версии файла пришли данные, спор с бизнесом вы почти наверняка проиграете.
Еще один промах - просить модель считать то, что должен считать SQL. LLM может пересказать правило скидки, но плохо подходит для расчета ступеней, порогов, округления, НДС и исключений. Если менеджер спрашивает цену для заказа на 240 единиц, запрос должен идти в SQL или в код с явной формулой.
Есть и обратная крайность. Команда превращает в отдельный факт каждую ячейку: цену, валюту, единицу измерения, пометку, сноску, цвет ячейки. Такая схема быстро начинает жить своей жизнью. Стоит бизнесу переименовать колонку или добавить одно новое условие, и поддержка схемы станет дороже самой пользы от нее.
Обычно работает более простое правило: стабильные поля, по которым вы фильтруете и сравниваете, выносите в факты. Все, что зависит от контекста строки, шапки, примечаний и соседних колонок, храните вместе.
Минимум, который стоит сохранять для каждой найденной записи, выглядит так: идентификатор файла или выгрузки, лист или раздел таблицы, диапазон строки, дата действия версии и текст строки вместе с шапкой. Если этого нет, отладка быстро превращается в мучение.
Быстрая проверка перед запуском
Если система ошибается на пороге скидки или на дате действия, доверие к ней пропадает после первого ответа. Перед запуском полезно пройти короткую проверку. Она занимает меньше дня, зато сразу показывает, где у вас поиск, где слой фактов, а где нужен SQL.
- В каждом ответе показывайте источник: название таблицы, версию, дату обновления и, если нужно, номер строки или диапазон.
- Прогоните тесты на самые неприятные вопросы: пороги скидок, исключения по сегментам, даты начала и конца действия, пересечения правил и устаревшие строки.
- Все расчеты отдайте SQL или коду с явной формулой. Если вопрос звучит как "сколько", "какая сумма", "какая минимальная цена" или "какие позиции попадают под условие", модель не должна считать в тексте.
- В слой фактов кладите только то, что реально нужно для ответа: код товара, диапазон цены, регион, срок действия, тип клиента, признак исключения.
- Назначьте владельца таблицы. Команда должна понимать, кто обновляет данные, как помечает новую версию и по какому правилу старые записи перестают участвовать в ответах.
На практике сбой часто выглядит очень буднично. Менеджер спрашивает: "Действует ли скидка 7% для дилеров в апреле при заказе от 500 тысяч?" Поиск находит похожий абзац, но в соседней вкладке лежит исключение для одного региона, а итоговую сумму надо считать по формуле из SQL. Если вы заранее развели эти роли, ответ получается нормальным: модель формулирует текст, SQL считает числа, а слой фактов проверяет ограничения.
Что делать дальше
Не пытайтесь сразу перестроить весь контур. Возьмите одну таблицу, на которой обычный RAG уже дает странные ответы: путает пороги скидок, не видит исключения по регионам или берет цену из старой версии.
Потом прогоните на ней три варианта: хранение строк как есть, извлечение фактов и запросы через SQL. Набор вопросов нужен реальный, не демонстрационный. Лучше 20-30 вопросов из саппорта, продаж или внутренней эксплуатации, где ошибка заметна сразу.
Смотрите не только на качество ответа. Для табличных регламентов почти всегда всплывают еще две вещи: сколько стоит один ответ и как быстро вы обновляете данные после новой выгрузки. На практике удобно свести сравнение к четырем метрикам: точность на реальных вопросах, цена одного ответа, задержка ответа и время обновления после изменения таблицы.
Если строки дают хороший результат на описательных вопросах, не усложняйте схему раньше времени. Если модель часто теряет числовые условия, диапазоны и оговорки, переводите таблицу в факты. Если люди спрашивают с фильтрами, сортировкой, суммами и сравнением по столбцам, подключайте SQL.
Отдельно проверьте слой данных. Если в таблицах есть ПДн, не откладывайте это на потом. Сразу смотрите, где лежат логи, как маскируются поля и можно ли поднять аудит по каждому запросу. Иначе пилот пройдет нормально, а на согласовании с безопасностью все остановится.
Если вы уже сравниваете несколько моделей или маршрутизируете запросы между провайдерами, такой контур удобно держать за единым шлюзом вроде RU LLM. Он дает OpenAI-совместимый эндпоинт, так что SDK, код и промпты можно не менять, а для команд с 152-ФЗ полезно, что логи и бэкапы хранятся в РФ и в запросах есть аудит-трейлы.
Обычно хватает одного спринта, чтобы понять, какая схема подходит именно вашей таблице. После этого уже можно расширять подход на соседние наборы данных - без долгих споров о том, какой вариант "правильный" в общем случае.
Часто задаваемые вопросы
Почему обычный RAG часто ошибается на таблицах?
Потому что смысл ячейки зависит от шапки, соседних колонок, единиц измерения, сносок и даты действия. Если поиск вытаскивает только кусок строки, модель сама достраивает пропуски и часто ошибается.
В таблицах это особенно заметно на ценах, лимитах, скидках и исключениях. Один потерянный столбец уже меняет ответ.
Когда можно просто хранить строки таблицы?
Если таблица небольшая, вопросы повторяют текст ячеек, а людям нужна цитата или одно значение, этого обычно хватает. Такой вариант быстро запускается и редко требует сложной схемы.
Он хорошо работает для коротких прайс-листов и регламентов, где пользователь спрашивает что-то вроде цены, лимита или платы за подключение без расчетов и фильтров по десяткам строк.
Что нужно хранить вместе со строкой?
Добавьте к каждой строке название таблицы, названия колонок, единицы измерения, лист или раздел и период действия версии. Голая строка без этого контекста почти всегда двусмысленна.
Лучше индексировать не сырой CSV, а нормальный текст вроде: тариф, лимит, цена, валюта, срок. Так поиск находит нужное точнее.
Когда строк уже мало и нужны факты?
Переходите к фактам, когда вопрос упирается в конкретные поля, а не в формулировку строки. Это видно по запросам про ставку, срок, лимит, исключение, сегмент клиента или роль пользователя.
Если в одной записи живут правило и оговорка, текстовый кусок начинает путать модель. Поля в явном виде дают более ровный результат.
Какие поля стоит выносить в факты, а что лучше оставить текстом?
Выносите в факты стабильные поля, по которым вы фильтруете и сравниваете записи: тариф, сегмент, роль, цена, лимит, срок действия, исключение, идентификатор источника. Их легко проверить машинно.
Не дробите все подряд. Сноски, двусмысленные примечания и куски живого текста лучше хранить рядом с исходной строкой, чтобы не потерять смысл.
Когда без SQL не обойтись?
Подключайте SQL, когда человек просит отфильтровать строки, отсортировать их, выбрать минимум или максимум, посчитать сумму или итоговую цену. В таких вопросах мало найти похожий кусок таблицы, нужно применить условия.
Простой тест такой: если человек в Excel первым делом включил бы фильтр или сортировку, вам нужен SQL. Считать скидки, НДС, пороги и диапазоны моделью не стоит.
Нормально ли смешивать строки, факты и SQL в одной системе?
Да, и для таблиц это часто лучший вариант. Строки дают точную цитату, факты держат структуру, а SQL считает и фильтрует там, где текстовый поиск уже слаб.
Такой разбор ролей снижает число ошибок. Модель не гадает по цене, а объясняет результат на основе строк, фактов и выборки из базы.
Как не смешать старую и новую версию прайса или регламента?
Храните у каждой записи версию файла, дату действия, лист или раздел и диапазон строки. Перед поиском отсекайте неактуальные данные по дате, а в ответе всегда показывайте источник.
Если вы держите старые и новые версии без фильтра, модель легко склеит цену из нового файла с условием из старого. Пользователь увидит правдоподобный, но неверный ответ.
Что делать, если в таблицах есть ПДн?
Сразу решите, где лежат логи, кто видит исходные таблицы и как вы маскируете поля с персональными данными. Для российского контура обычно нужен трафик и хранение в РФ, понятный аудит по запросам и срок хранения логов.
Лучше закрыть это на старте, чем после пилота. Иначе система может ответить нормально, а согласование с безопасностью остановит запуск.
С чего начать пилот и что проверить перед запуском?
Возьмите одну проблемную таблицу и прогоните на ней три схемы: строки, факты и SQL. Для проверки соберите 20–30 живых вопросов из саппорта, продаж или операций, где ошибка заметна сразу.
Перед запуском проверьте пороги скидок, даты действия, исключения и источник ответа. Если система не показывает версию и строку, отлаживать ее будет тяжело.