Публичный и внутренний индексы: когда их разделять
Публичный и внутренний индексы стоит разделять, когда сайт, саппорт и база для сотрудников живут по разным правилам доступа, обновления и качества.
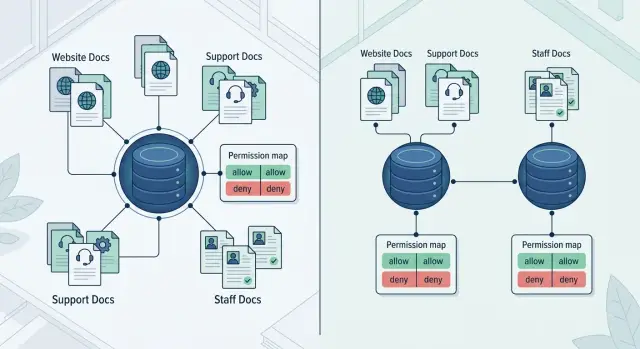
Почему один индекс часто путает ответы
Один общий индекс выглядит логично: все документы лежат в одном месте, поиск проще настроить, а команде не нужно поддерживать лишнюю схему. На практике проблемы начинаются быстро.
Причина проста. Сайт, база саппорта и внутренняя документация отвечают на разные вопросы и написаны для разных людей. Клиенту нужен короткий и понятный ответ без служебных деталей. Сотруднику нужен порядок действий: что проверить, куда эскалировать, какой срок назвать, какой шаблон отправить. Когда все это смешано, поиск начинает путать аудитории.
Даже одинаковый запрос может означать разное. Если менеджер саппорта ищет "как вернуть платеж", ему нужна инструкция с шагами и исключениями. Если тот же текст пишет клиент, лучше показать простое объяснение условий возврата. Смешанный индекс видит одинаковые слова и подтягивает документы из разных слоев доступа.
Проблему усиливает ранжирование. Поиск и RAG часто выбирают текст, который написан гладко и повторяет формулировку запроса. Поэтому маркетинговая страница или публичный FAQ нередко обгоняют сухую внутреннюю инструкцию. Ответ выглядит аккуратно, но сотруднику он не помогает: вместо процесса он получает общий пересказ.
Есть и риск доступа. Даже если система не показывает закрытый документ целиком, сам факт его попадания в выборку уже портит результат. Модель начинает смешивать публичные правила, внутренние оговорки и служебные исключения в одном ответе. В компаниях с жесткими требованиями к доступу это особенно неприятно: оператор колл-центра, инженер и клиент не должны видеть один и тот же контекст.
Единый корпус знаний чаще ломается не на редких вопросах, а на самых обычных. Публичный текст отвечает мягко и широко. Внутренний текст отвечает точно, но узко. Когда они спорят в одном индексе, система нередко выбирает более удобный текст вместо более верного. Поэтому публичный и внутренний индексы часто разделяют еще до того, как база документов сильно вырастет.
Когда хватает единого корпуса
Единый корпус часто работает лучше, чем два раздельных хранилища, если документы спокойные, хорошо размечены и подчиняются одним правилам. Это особенно заметно там, где статьи имеют схожую структуру, одинаковые заголовки, одну терминологию и похожий формат. В такой среде поиск реже путает соседние тексты.
Подход подходит и в ситуации, когда публичные и внутренние материалы почти не противоречат друг другу. На сайте лежат описания продукта и базовые инструкции. Во внутренних документах - регламенты, шаблоны ответов и рабочие заметки. Темы рядом, но задачи разные. Если у источников есть нормальная разметка, модель обычно не смешивает ответы.
Единый корпус удобен и тогда, когда вы уже настроили жесткие фильтры по роли и типу источника. Клиент получает только сайт и публичную справку. Агент саппорта видит еще базу поддержки. Сотрудник бэк-офиса работает со своим набором документов. Физически это одно хранилище, но доступ к внутренней базе остается ограниченным.
Обычно одного корпуса хватает, если соблюдаются четыре условия: редакторы пишут материалы в одном стиле и быстро их обновляют, у документов есть метки роли, источника и уровня доступа, публичные и внутренние тексты редко пересекаются по одним и тем же вопросам, а команда может проверить, откуда именно поиск взял ответ.
Плюс у этого варианта простой: меньше копий и меньше рассинхрона. Если команда обновила инструкцию на сайте, саппорт не живет со старой версией еще несколько дней. Для небольшой или средней команды это заметно снижает число ошибок.
Хороший пример - SaaS-сервис с аккуратной документацией. У него есть сайт с FAQ, база для саппорта и короткие инструкции для сотрудников. Все тексты собирают по одному шаблону, редакторы быстро вносят правки, а права доступа настроены строго. В такой ситуации публичный и внутренний индексы не обязательно разводить по разным хранилищам. Один индекс проще поддерживать, и он не мешает разным ролям получать свой ответ.
Когда лучше держать два хранилища
Два хранилища нужны не тогда, когда документов стало много, а когда у них разная роль. Текст на сайте объясняет продукт клиенту. Внутренняя база помогает сотруднику решить задачу: назвать лимит, проверить цену, открыть нужный скрипт, увидеть служебное поле или понять порядок эскалации.
Если все это попадает в единый корпус знаний, поиск начинает путать контекст. Публичный ответ может подтянуть фразу из заметки для саппорта, а внутренняя подсказка - опереться на маркетинговый текст с сайта, где детали специально упрощены.
Хуже всего не просто неточный ответ, а ответ с лишними деталями. Внутренние инструкции часто содержат цены для отдельных сегментов, ручные обходы, лимиты, причины блокировок, внутренние теги и черновые формулировки. Ошибочный ответ из такой базы легко превращается в утечку, даже если сотрудник или бот не показал весь документ целиком.
Пример простой: клиент спрашивает в чате, почему не проходит заявка. Единый индекс находит заметку для оператора с внутренним кодом причины, допустимым лимитом и фразой для перевода на вторую линию. Для сотрудника это полезно. Для клиента это лишняя информация, а иногда и причина для жалобы.
Отдельные хранилища обычно нужны, если сайт и внутренняя база пишут для разных людей и разным языком, команды обновляют контент в разном темпе, срок жизни документов сильно отличается, а цена ошибки тоже разная. Ошибка в публичном ответе бьет по доверию. Ошибка с доступом к внутренней базе бьет по безопасности.
Есть и более приземленная причина: ответственность. За сайт часто отвечает маркетинг или продуктовая команда. За поиск для саппорта - операционный блок. За инструкции для сотрудников - владельцы процессов. Когда все лежит вместе, быстро теряется ответ на простой вопрос: кто должен поправить устаревший фрагмент и за сколько часов.
Да, публичный и внутренний индексы можно разделять правами доступа и фильтрами. Но если риск утечки высокий, простая схема обычно надежнее сложной. Два отдельных хранилища легче проверять, тестировать и обновлять без страха, что клиент увидит внутреннюю кухню компании.
Как выбрать схему шаг за шагом
Если спор идет на уровне мнений, команда быстро застревает. Один человек хочет единый корпус знаний, потому что так проще поддержка. Другой боится, что поиск начнет путать публичные ответы и внутренние инструкции. Решение лучше принимать не по ощущению, а по короткой проверке на своих данных.
Сначала выпишите источники, которые реально участвуют в поиске: сайт, help center, CRM, база тикетов, внутренняя wiki, заметки команды. Не тащите в тест все подряд. Берите только то, что люди действительно открывают в работе.
Потом рядом с каждым источником отметьте, кто его читает. Клиент, агент саппорта, менеджер, бухгалтерия, инженер - у всех разный доступ к внутренней базе. Часто проблема не в самих документах, а в том, что у двух аудиторий разные права и разные задачи.
После этого найдите темы, которые повторяются в нескольких местах. Обычно это возвраты, тарифы, статусы заказов, лимиты, SLA, правила эскалации. Если тема есть и на сайте, и во внутренней wiki, риск путаницы уже высокий.
Дальше соберите 20-30 живых запросов. Половину возьмите из клиентских обращений, половину - из работы саппорта. Не переписывайте их в "правильный" вид. Люди пишут "почему деньги списались два раза", а не "политика двойного списания".
Затем прогоните этот набор в двух вариантах: через один общий индекс и через два отдельных хранилища. Смотрите не только на ответ, но и на то, откуда система его взяла. Если общий индекс тянет служебные шаги в ответ клиенту или сотруднику отдает слишком общий текст с сайта, разделение уже оправдано.
После такого теста картина обычно проясняется. Если публичные и внутренние темы почти не пересекаются, два хранилища дают чище результат. Если пересечение большое, а различия сводятся к нескольким служебным блокам, можно оставить один индекс и жестко управлять доступом на уровне документов.
Есть простой признак. Вы открываете ответы и сразу понимаете, кому они подходят. Если это приходится долго обсуждать, публичный и внутренний индексы, скорее всего, уже пора разводить.
Пример: сайт, саппорт и сотрудники в одной компании
Представьте компанию с тремя слоями знаний. На сайте лежат публичные правила возврата. У саппорта есть своя база с лимитами, исключениями и шаблонами ответов. У сотрудников есть внутренние инструкции: кому передавать спорный случай, что проверять в CRM и когда звать старшего смены.
Клиент пишет в чат: "Как сделать возврат?" Ему нужен короткий и понятный ответ без служебных пометок, внутренних кодов причин и длинного сценария разговора. Обычно хватает пары шагов: срок возврата, где оставить заявку, какие документы нужны.
Оператор видит тот же вопрос иначе. Ему мало общей статьи с сайта. Он ищет детали: какие есть лимиты по сумме, что делать с частичным возвратом, какие исключения действуют для акционных товаров, как объяснить отказ без конфликта и в каких случаях можно предложить ручное решение.
Если все сложить в единый корпус знаний, поиск быстро начинает путать роли. Клиентский ассистент может вытащить фразу вроде "если сумма выше порога, переведите кейс на вторую линию". Для клиента это лишняя и странная деталь. Оператор, наоборот, может получить красивый текст с сайта про "простой возврат" и не увидеть нужный внутренний сценарий.
После разделения схема становится чище. Индекс сайта отвечает клиентам и берет только публичные материалы. Внутренний индекс помогает саппорту и сотрудникам и хранит процедуры, исключения и служебные заметки.
Тогда один и тот же вопрос обрабатывается по-разному, как и должен. Клиент получает короткий безопасный ответ. Оператор получает рабочую инструкцию, а не рекламный абзац.
Это особенно заметно на спорных запросах. Например, клиент спрашивает про возврат после истечения срока. Публичный индекс скажет, действует ли возврат по правилам компании и куда обратиться. Внутренний индекс покажет оператору, какие есть исключения, когда можно согласовать ручное решение и что нужно зафиксировать в карточке обращения.
Для сотрудников вне саппорта разделение тоже удобно. Новичок из бэк-офиса не копается в публичных FAQ, если ему нужен внутренний порядок действий. Он идет во второй индекс и сразу находит нужную инструкцию. В такой схеме поиск перестает быть общим для всех и начинает отвечать по роли и задаче.
Как провести границу между индексами
Граница проходит не по типу файла, а по риску ошибки. Если документ можно без вреда показать клиенту, он попадает в публичный индекс. Если текст помогает сотруднику работать, но клиенту его видеть не нужно, держите его отдельно.
В публичном индексе обычно остаются статьи базы знаний, описания тарифов, инструкции по настройке, статусные сообщения и ответы на частые вопросы. Туда не стоит класть внутренние лимиты, служебные пометки, скидочные правила, эскалации, черновики и заготовки для операторов. Даже хороший поиск начинает путаться, когда рядом лежат клиентский FAQ и служебный скрипт с фразой "если пользователь настаивает".
Внутренний индекс лучше собирать вокруг рабочих задач команды. Туда входят регламенты, условия компенсаций, правила ручной проверки, шаблоны ответов саппорта, заметки после инцидентов и документы в работе. Черновики особенно часто ломают выдачу: модель видит свежий, но неутвержденный текст и отвечает увереннее, чем стоит.
Есть одно исключение: термины и названия не стоит дублировать вручную в двух местах. Название тарифа, имя функции, статус заказа или формулировку ошибки лучше хранить в одном справочнике и подтягивать в оба индекса. Иначе саппорт пишет "Премиум Плюс", сайт показывает "Premium+", а поиск отвечает третьим вариантом.
Полезно ввести для каждого документа простые метки: источник, роль, статус и дату последней проверки. Такая разметка дает больше пользы, чем кажется. Поиск может сразу отсечь внутренние материалы для клиентского чата, а саппорт, наоборот, видеть только рабочие инструкции. В компаниях, где есть требования по 152-ФЗ и аудит запросов, это еще и упрощает контроль доступа.
Есть быстрый тест. Возьмите любой документ и ответьте на два вопроса: можно ли показать его клиенту без ручной проверки и потеряет ли команда что-то важное, если клиент его прочитает. Если на второй вопрос ответ "да", документу не место в публичном индексе.
Лучше провести границу чуть строже, чем потом чистить выдачу после первых ошибок. Пара лишних документов во внутреннем индексе обычно не страшна. Один служебный регламент в публичной выдаче уже создает проблему.
Ошибки, которые ломают поиск
Поиск начинает врать не из-за модели, а из-за беспорядка в данных. Даже точная система путается, если в одном месте лежат черновики, старые инструкции и опубликованные тексты без явной метки статуса.
Первая частая ошибка - складывать в индекс черновики рядом с тем, что уже вышло на сайт или в базу знаний. Тогда специалист саппорта задает обычный вопрос, а система приносит абзац из незавершенной статьи, где еще не согласованы цены, сроки или условия. Ответ выглядит уверенно, но источник у него сырой.
Вторая проблема кажется мелочью: один и тот же текст копируют на сайт, в wiki и в справку для команды. Через месяц одна версия обновляется, две другие остаются старыми, и поиск выдает почти одинаковые документы с разными фактами. Если у текста нет владельца, никто не знает, какая версия главная и кто должен ее править.
Еще опаснее надеяться, что права доступа можно проверить уже после того, как система нашла документы и составила ответ. Если поиск сначала прочитал внутренний регламент, а потом вы просто скрыли ссылку на него, утечка уже произошла. Модель может пересказать внутренний факт своими словами. Для внутренних цен, инцидентов, персональных данных и служебных инструкций доступ нужно отсекать до поиска, а не после ответа.
Тихая, но частая поломка - забытые удаления и старые версии. Документ убрали из wiki, но он остался в индексе. Страницу переписали, а старая запись все еще участвует в поиске. В итоге система тащит "призраков": удаленные тексты, старые правила, архивные ответы. Для компаний, где важны 152-ФЗ, аудит и сроки хранения, это очень неприятно.
Еще одна ошибка - оценивать схему на придуманных запросах. Тест вроде "как вернуть товар" почти всегда проходит хорошо. Настоящие запросы хуже: с опечатками, жаргоном, обрывками мысли и ссылками на старые названия процессов. Когда вы решаете, нужны ли единый корпус знаний или два отдельных хранилища, проверяйте публичный и внутренний индексы на живых вопросах с сайта, из саппорта и от сотрудников.
Хороший тест простой: берите последние реальные обращения, смотрите, какие документы попали в ответ, и отмечайте не только точность, но и риск ошибки. Неверный ответ на сайте неприятен. Внутренний ответ, который ушел наружу, обходится намного дороже.
Быстрая проверка перед запуском
Перед запуском не нужен большой аудит. Нужна короткая проверка, которая ловит самые дорогие ошибки: утечки, устаревшие ответы и путаницу между сайтом, саппортом и внутренней базой.
Сначала проверьте, есть ли у каждого документа владелец. Не абстрактный отдел, а конкретная команда или человек. Если карточка тарифа лежит в индексе без владельца, никто не заметит, что условия давно изменились. То же касается базы саппорта и внутренних инструкций.
Затем убедитесь, что каждый индекс знает свою аудиторию. Публичный индекс отвечает клиентам и не тянет служебные регламенты. Внутренний индекс помогает сотрудникам и может опираться на материалы, которые нельзя показывать наружу. Если у индекса нет ясной аудитории, поиск почти всегда начинает смешивать тон, уровень деталей и сами источники.
Перед релизом достаточно проверить пять вещей:
- у каждого документа есть владелец и понятный срок пересмотра
- для каждого индекса задана аудитория: клиент, саппорт или сотрудник
- фильтры по роли срабатывают до генерации ответа
- в интерфейсе видны дата обновления и источник ответа
- есть набор тестовых запросов на утечки и пустые ответы
Особенно часто ошибаются с фильтрами доступа. Если модель сначала читает весь корпус, а потом приложение пытается спрятать лишнее, проблема уже случилась. Проверка прав должна стоять до поиска и до генерации. Иначе сотрудник колл-центра может случайно получить выдержку из внутренней инструкции для финансового отдела, а внешний пользователь - кусок ответа из базы саппорта.
Дата обновления и источник нужны не для красоты. Они помогают команде быстро понять, можно ли доверять ответу. Когда саппорт видит, что фрагмент взят из статьи двухлетней давности, спор заканчивается за минуту.
Тестовые запросы лучше писать как живые вопросы: как вернуть товар, где посмотреть внутренний SLA, что делать при сбое авторизации, какие скидки доступны сотрудникам. Хороший прогон должен ловить два типа проблем: модель раскрывает лишнее или не находит ничего там, где ответ точно есть.
Если на любой из этих проверок начинается спор, запускать систему рано. Сначала поправьте границы доступа и ответственность за контент.
Что делать дальше
Споры о схеме поиска лучше остановить на одном простом шаге: разложите все источники по риску. Публичные страницы сайта, открытый FAQ и статьи для клиентов обычно можно держать вместе. Регламенты саппорта, заметки из тикетов, внутренние инструкции, договорные условия и служебные таблицы лучше сразу вынести в отдельный слой.
Если документ трудно отнести к одной группе, задайте короткий вопрос: что случится, если этот текст увидит клиент? Если даже редкий сценарий выглядит неприятно, не кладите документ в общий индекс. Так быстрее становится понятно, где публичный и внутренний индексы действительно нужно разделять, а где это только усложнит работу.
После этого проверьте, нужен ли вам общий словарь. У многих компаний названия тарифов, коды ошибок, имена продуктов и правила терминов должны совпадать везде. Такой справочник удобно держать отдельно и давать его обоим контурам. Тогда бот на сайте, агент саппорта и сотрудник внутри компании говорят на одном языке, но не получают лишние инструкции.
Дальше нужен короткий пилот на живых запросах саппорта. Не берите только придуманные примеры. Возьмите 50-100 реальных обращений: возврат денег, смена тарифа, ошибка в личном кабинете, вопрос по срокам. Сравните два варианта: единый корпус и разделенные хранилища. Смотрите не только на качество ответа, но и на риск утечки.
Во время пилота хватит четырех метрик: ответил ли бот по делу, сослался ли он на правильный класс источника, отказался ли раскрывать внутренние инструкции и сократилось ли время разбора обращения у агента.
Ради теста не стоит переписывать весь стек. Проще оставить одно приложение и добавить маршрутизацию по роли пользователя и типу запроса. Если команде нужен единый OpenAI-совместимый доступ к нескольким моделям в РФ, для такого пилота может подойти RU LLM от rullm.com: сервис дает один совместимый эндпоинт, помогает сохранить аудит запросов внутри РФ и не требует менять текущие SDK, код и промпты.
Через пару недель у вас будет не абстрактное мнение, а понятная картина: где единый корпус помогает, где мешает и какие документы давно пора вынести в отдельный индекс.
Часто задаваемые вопросы
Когда уже точно пора разделять публичный и внутренний индексы?
Разделяйте индексы, когда один и тот же вопрос требует разных ответов для клиента и сотрудника. Если во внутренних материалах есть лимиты, коды причин, обходы, эскалации или черновики, держите их отдельно от сайта и публичной справки.
В каких случаях одного общего корпуса хватает?
Оставляйте один корпус, если тексты пишут в одном стиле, быстро обновляют и хорошо размечают по роли, источнику и доступу. Такой вариант чаще подходит небольшой или средней команде, где публичные и внутренние статьи почти не спорят друг с другом.
Что хуже в едином индексе: неточный ответ или утечка лишних деталей?
Обычно опаснее утечка. Неточный публичный ответ злит пользователя, а внутренняя деталь в клиентском ответе может создать жалобу, спор или проблему с доступом.
Можно ли решить проблему только правами доступа и фильтрами?
Нет, одних фильтров мало, если поиск сначала читает весь корпус. Отсекайте доступ до поиска и до генерации ответа, иначе модель успеет пересказать внутренний факт своими словами.
Как быстро проверить, какая схема подойдет именно нам?
Соберите 20–30 живых запросов: часть от клиентов, часть от саппорта. Потом сравните два режима — общий индекс и раздельные хранилища — и посмотрите не только на ответ, но и на источник каждого фрагмента.
Какие документы не стоит добавлять в публичный индекс?
Не кладите туда внутренние лимиты, служебные пометки, шаблоны для операторов, причины блокировок, ручные обходы и черновики. Клиенту нужен понятный ответ по правилам, а не внутренняя кухня команды.
Нужно ли дублировать названия тарифов и коды ошибок в двух индексах?
Нет, лучше держать общие термины в одном справочнике и отдавать его обоим индексам. Так сайт, саппорт и сотрудники используют одни названия тарифов, статусов и ошибок без ручной копии в каждом месте.
Какие ошибки чаще всего портят выдачу?
Чаще всего поиск ломают черновики рядом с опубликованными текстами, старые версии в индексе и копии одной статьи в разных местах. Еще одна частая ошибка — хранить документы без владельца, когда никто не правит устаревшие условия.
Как понять, что система взяла ответ не из того места?
Смотрите на источник, дату обновления и роль документа. Если клиентский ответ опирается на заметку для саппорта или сотрудник получает общий текст с сайта вместо инструкции, схема уже смешивает аудитории.
С чего начать пилот, если не хочется переделывать весь стек?
Начните с пилота на одном приложении и добавьте маршрутизацию по роли пользователя и типу запроса. Если вам нужен единый OpenAI-совместимый доступ к разным моделям внутри РФ, RU LLM позволяет провести такой тест без смены SDK, кода и промптов.