Проверка маскирования PII на русских данных и смешанном тексте
Проверка маскирования PII на русских данных: тесты с ФИО, адресами, латиницей и кириллицей, чтобы находить тихие промахи до продакшена.
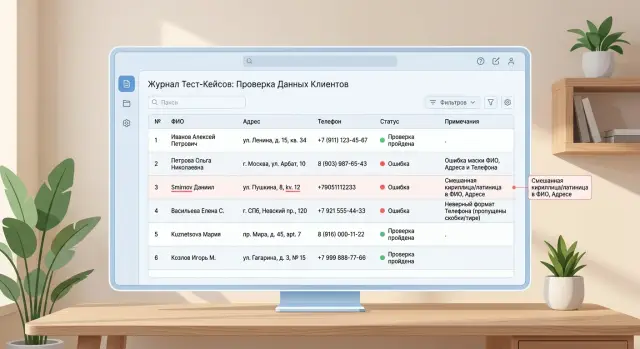
Почему тихие промахи опасны
Самая неприятная утечка выглядит почти безобидно. Маска срабатывает не до конца и оставляет кусок имени, адреса или телефона. На экране все кажется чистым, но одной детали часто хватает, чтобы узнать человека.
Это случается чаще, чем кажется. Строка "Иванов Сергей Петрович" превращается в "[NAME] Сергей П.", а адрес "Москва, ул. Ленина, д. 7, кв. 42" отдает дом и квартиру. Формально маскирование прошло. По факту персональные данные остались.
Быстрый тест такие вещи почти всегда пропускает. В тестах обычно лежат аккуратные примеры без опечаток, лишних пробелов, редких сокращений и смешанных алфавитов. В боевых данных все грязнее: "Сергей Иванов", "Екaтерина" с латинской "a", "ул Ленина д7к2" без удобных разделителей. Правило, которое хорошо выглядит на пяти чистых строках, на реальном потоке ломается тихо и без ошибки.
Проблема еще и в том, что утечка всплывает не только в финальном ответе модели. PII часто остается в логах запросов и ответов, в сообщениях ретраев, в отладочных записях, в аудит-записях и в истории запросов. Если команда смотрит только на ответ пользователю, она замечает промах слишком поздно, когда запись уже попала в разбор, отчет или внутренний чат.
Для команд, которые идут через шлюз вроде RU LLM, это особенно заметно. Проверять надо не только ответ модели, но и весь служебный след запроса, включая логи и аудит-записи.
Один символ из другого алфавита ломает правило чаще, чем кажется. "Алексeй" с латинской "e" почти не отличается от обычного имени. Человек не заметит подмену, а простая регулярка пропустит строку. То же самое происходит с адресами, которые собрали из CRM, формы и письма, когда часть текста идет кириллицей, а часть латиницей.
Цена тихого промаха обычно выше, чем цена явной ошибки. Явный сбой команда видит сразу и чинит в тот же день. Тихий промах живет неделями, пока кто-то не найдет его в логах, жалобе клиента или во внутренней проверке. К этому моменту утечка уже расходится по нескольким системам.
Как собрать рабочий набор тестов
Хороший набор редко начинается с придуманных строк. Лучше брать фрагменты из реальных чатов, CRM, писем и заявок. Именно там появляются лишние пробелы, сокращения, комментарии оператора, переносы строк и странный порядок слов.
Один и тот же тип данных ведет себя по-разному в каждом канале. Телефон в форме выглядит аккуратно, а в чате его пишут как "8 916123 45 67" или "мой номер: 8916...". Адрес в CRM заносят как "Ленина 7к2", а в заявке - "ул. Ленина, д 7, корп 2". Поэтому набор удобно раскладывать не только по сущностям, но и по источнику: ФИО, адреса, телефоны, почта, паспортные данные; чат, CRM, заявка, письмо, выгрузка; чистый ввод, опечатки, сокращения, смешанный алфавит; одна строка, абзац, JSON, CSV и комментарий оператора.
Шум убирать не надо. Наоборот, он и показывает, где правило или модель дает тихий промах. Оставляйте "Ивaнов" с латинской "a", "С.-Петербург", "Мария Ивановна" с двойным пробелом, "пр-т Мира", "дом 12/1", "кв5" без пробела. Если тесты слишком чистые, релиз проходит спокойно только на бумаге.
Для каждого примера сразу фиксируйте ожидаемый результат. Не "данные должны скрыться", а точное правило: фамилию и имя скрыть полностью, дом и квартиру в адресе скрыть, город оставить, номер заказа не трогать. Тогда команда не спорит на глаз и быстрее ловит расхождения.
Полезно хранить версию набора и короткую причину появления кейса. Если тест добавили после сбоя в проде, так и пишите: "чат, пропустили ФИО с латинской буквой". Через месяц такая пометка экономит много времени и помогает не потерять старую ошибку после следующего обновления правил, модели или маршрутизации.
Русские ФИО, которые часто проскальзывают
Обычный тест на ФИО слишком чистый: "Иван Иванов" без ошибок, без сокращений, без падежей. В проде такие строки редки. Люди пишут фамилии через дефис, ставят инициалы, пропускают отчество или путают буквы. Именно на этом маскирование чаще всего дает промах.
Начните с фамилий, которые ломают простые шаблоны: "Анна Петрова-Соколова", "Илья Кузнецов-Орлов", "Смирнова-Лебедева А. Н.". Если система уверенно маскирует "Иванов Иван", но оставляет вторую часть двойной фамилии, тест уже сделал свою работу.
Отдельно проверьте полную фамилию рядом с инициалами. В документах постоянно встречаются формы "Сергеев А.В.", "Николаева Е. П." и "Крылов Д.В" без последней точки. Полезно и сочетание полного имени с сокращением в одной строке: "Алексей Крылов, Крылов А. В.". Один и тот же человек часто появляется сразу в двух форматах.
С отчеством тоже не все просто. Возьмите несколько почти одинаковых строк: "Ольга Сергеевна Миронова", "Ольга Миронова", "Миронова О. С.", "обсудили с Ольгой Сергеевной Мироновой", "для Мироновой Ольги Сергеевны". Так быстрее видно, где правило распознает только именительный падеж и начинает пропускать текст из писем или CRM-заметок.
Буквы "Ё" и "Е" лучше гонять отдельно. "Семёнов" и "Семенов" часто живут как два разных значения, хотя для человека это одна фамилия. То же относится к мелким опечаткам и вариантам записи. Маскирование не обязано угадывать все ошибки, но тест должен показать, где проходит реальная граница.
Еще один частый источник утечек - мусорный ввод: "И.И. Иванов", "Иванов А..В.", "Cергeй Петров" с ошибкой раскладки в одной букве, "Петрова , Мария" с лишней запятой или пробелом. Такие мелочи выглядят безобидно, но именно они потом остаются в логах и тикетах, если проверка видела только аккуратный текст.
Адреса, телефоны и почта без удобного шаблона
Адрес, телефон и email ломают маскирование чаще, чем хочется. Причина простая: люди пишут их как попало. Один клиент вставляет полный адрес в одну строку, другой разбивает его на три, а оператор в конце дописывает "подъезд 2, домофон 58". Если проверять только красивые записи из формы, вы пропустите самые неприятные утечки.
Хороший набор должен повторять живой ввод. Возьмите один и тот же адрес в двух видах: одной строкой и кусками по строкам. Не ограничивайтесь "ул. Пушкина, д. 1". Добавляйте сокращения, которые люди реально используют: "ул", "просп", "корп", "стр", "кв". После основного адреса полезно дописать индекс, подъезд и домофон. Многие маскировщики закрывают улицу и дом, но оставляют хвост сообщения, а там часто лежит самая точная часть адреса.
119021, Москва, ул. Льва Толстого, д. 16, корп. 2, стр. 3, кв. 48, подъезд 4, домофон 481
Адрес доставки:
г. Казань
просп. Победы, д 141
кв 87, индекс 420140
С телефонами история похожая. Один и тот же номер стоит прогонять в нескольких форматах: с пробелами, со скобками, через дефисы, с добавочным. Частая ошибка такая: система скрывает "+7 (495) 123-45-67", но оставляет "доб. 203" или последние цифры после нестандартного разделителя. Для команд под 152-ФЗ это неприятный сюрприз, потому что такой кусок потом уходит в логи и аудит.
С почтой тоже не стоит брать только простые адреса вроде "ivanov@mail.ru". Нужны варианты с цифрами, точками и служебными именами ящиков, где PII спрятан внутри адреса, например "maria.ivanova.92@company.ru" или "отдел.закупок.77@пример.рф". Если система допускает кириллицу в локальной части, такие кейсы тоже надо положить в набор.
Хороший тест здесь работает одинаково для одной строки и многострочного ввода. Он закрывает все части адреса, не оставляет читаемый хвост в email и не разваливает телефон на "номер скрыт, добавочный виден". Если после прогона у вас остались квартира, индекс, добавочный или фамилия в почте, тест сработал не зря. Именно такие остатки потом становятся утечкой.
Смешанная кириллица и латиница
Тихие промахи часто прячутся не в редких форматах, а в строках, которые выглядят обычными. Человек читает "Петров", а система видит смесь двух алфавитов, лишний невидимый символ и кусок транслита. Из-за этого команда получает ложное чувство безопасности.
Для такого набора не нужны сотни примеров. Нужны строки, которые похожи на живой ввод из CRM, почты, PDF и чатов. Самые полезные случаи - те, где один и тот же текст выглядит нормально для глаза, но иначе читается парсером: "Иваноv Сергей", "Sergei Петров", "г. Mосква, ул. Лeсная, d. 5", "Счeт направить на ivаn.petrov@company.ru" или "Аndrеy Реtrоv" после копирования из PDF. В таких строках часть букв латинская, часть кириллическая, а иногда внутрь попадают невидимые символы или неразрывные пробелы.
Отдельно полезно положить в тесты текст после неудачной смены раскладки. Пользователь набирает "Ghbdtn, z jnrhsdfk rfhne", потом правит только часть строки, и в одном сообщении живут русские слова, латиница и обрывки транслита. Правила, которые ждут "чистый" русский или "чистый" английский, такие куски часто пропускают.
Если вы гоняете запросы через шлюз вроде RU LLM, сравнивайте результат в двух видах: как строка пришла из приложения и как она выглядит после нормализации Unicode, удаления невидимых символов и выравнивания пробелов. Если маскирование сработало только во втором случае, это уже сигнал. В проде пользователь пришлет первый вариант.
Хорошая проверка тут очень простая: берите одну строку, делайте несколько грязных копий и смотрите, остается ли результат маскирования одинаковым. Если на третьей копии фамилия или адрес внезапно остаются открытыми, это не мелочь, а реальный риск.
Как проверять по шагам
Хаос начинается там, где команда проверяет маскирование на глаз. Если заранее не зафиксировать, какие поля и фрагменты текста должны скрываться, спор начинается уже на первом кейсе: фамилию закрываем полностью или оставляем инициал, номер квартиры считаем PII или нет, что делать с почтой вида ivan.petrov+bank@example.com.
Сначала соберите короткую спецификацию. Не общие слова, а точные правила: что маскируется, в каком виде остается текст после замены, какие исключения допустимы. Для проверки PII это важнее самой модели, потому что без правил вы не отличите баг от "ну вроде нормально".
Рабочий порядок обычно такой:
- Для каждого кейса задайте входной текст и один ожидаемый результат.
- Зафиксируйте формат замены: [MASK], звездочки, частичное скрытие или удаление.
- Прогоните один и тот же набор через всю цепочку, а не только через детектор.
- Сравните ответ пользователю, служебные логи и сохраненные трассировки.
- Пометьте промах типом ошибки и верните кейс в набор повторных проверок.
Один и тот же текст часто ведет себя по-разному на разных этапах. Детектор может скрыть "Иванов Сергей Петрович", но в лог запроса уйдет исходная строка. Или приложение замаскирует телефон в ответе, а прокси сохранит его в метаданных. Если вы используете шлюз с аудит-записями, например RU LLM, смотрите всю цепочку: вход, промежуточную обработку, ответ модели, логи и бэкапы тестовой среды.
Промахи лучше размечать не одной меткой "не сработало", а по типу. Обычно хватает четырех классов: пропуск, ложное срабатывание, частичное маскирование и утечка в логах. Частичная маска часто хуже, чем кажется. Строка вроде "Петро* Сергей" уже может позволить узнать человека.
После каждой правки гоняйте не только упавшие тесты, но и весь набор. Тихие промахи любят возвращаться. Сегодня вы починили адреса, а завтра сломали смешанную запись вроде "Сергeй Ivanov" и заметите это только в проде.
Один реальный сценарий
Хорошая проверка ломается не на явных примерах, а на обычной переписке. Допустим, в первой заявке клиент пишет: "Иванова Анна Сергеевна, Москва, ул. Лесная, д. 7, кв. 14". Маска закрывает имя и часть адреса, и на быстрый взгляд все выглядит нормально.
Проблема начинается во втором сообщении. Клиент уже не повторяет полные данные и пишет просто: "Анна с Лесной". Если пайплайн проверяет каждую реплику отдельно, он может решить, что фраза слишком размытая. Но в контексте это та же заявка, тот же адрес и тот же человек.
Дальше появляется тихий промах. В первой реплике система скрыла "Анна", но оставила "кв. 14". Фамилию она нашла только в форме "Иванова", а в служебном комментарии сотрудник позже написал "созвон с Ивановой согласован". Склоненная форма не попала под правило, и кусок личности остался в логе.
Ситуацию добивает подпись. После двух сообщений система склеивает диалог для передачи в следующую модель или в CRM, и внизу внезапно появляется строка вроде "С уважением, Анна, +7 9XX...". Телефона не было в тексте заявки, поэтому детектор, который смотрел только входящие сообщения клиента, его просто не видел.
Такой сбой редко живет в одной точке. Обычно ломается сразу несколько мест: маскирование прошло по сообщениям по отдельности, без общей сборки диалога; детектор имен не проверил склонения; адресное правило сочло квартиру "нечувствительной" частью записи; подпись обработали после маскирования; финальный склеенный текст никто не прогнал через повторную проверку.
Для такого кейса мало смотреть, скрыла ли система полное ФИО. Нужен тест на восстановимость личности по кускам. Если в логе остались "Анна", "Лесная", "кв. 14" и телефон из подписи, оператор или модель легко соберут профиль обратно.
На практике этот сценарий хорошо работает как базовый тест для повторной проверки. Он быстро показывает, умеет ли система держать контекст, понимать русские формы слов и повторно сканировать уже собранный диалог целиком.
Ошибки, которые портят проверку
Слабые тесты дают приятную картинку и плохую защиту. Чаще всего команда гоняет по пайплайну аккуратные строки вроде "Иванов Иван Иванович, Москва, ул. Пушкина, д. 10" и получает почти идеальный результат. В проде так не пишут. Там есть опечатки, лишние пробелы, переносы строк, сокращения, старые поля из CRM и куски текста, где кириллица перемешана с латиницей.
Из-за этого проверка чаще ломается не на сложных кейсах, а на грязных. Система скрыла фамилию, но оставила инициалы; закрыла телефон, но пропустила добавочный; убрала улицу, но оставила дом и квартиру. Если набор слишком чистый, таких промахов просто не видно.
Еще одна частая ошибка - смотреть только на финальный ответ модели. Этого мало. Проверяйте весь путь данных: входной текст, предобработку, промежуточную нормализацию, логи и то, что реально ушло в модель. Иначе легко пропустить ситуацию, когда маскирование сработало в интерфейсе, но сырой PII остался в служебных полях или трассировке.
Помогает простой набор правил. Частичная маска не считается успехом, если по остатку можно узнать человека. Старые кейсы для повторной проверки надо хранить отдельно и помечать версией правил. Новые находки из инцидентов лучше складывать в отдельный слой, чтобы было видно, откуда они взялись. После любого изменения модели, промпта или маршрутизации тесты стоит прогонять заново.
Последний пункт часто недооценивают. Команда меняет промпт "чуть строже" или переключает модель через тот же эндпоинт, совместимый с OpenAI, и кажется, что риск нулевой. На практике новая модель иначе режет текст, по-другому понимает сокращения и может пропустить "Смирнова А.В." там, где старая версия маскировала все.
Хорошая привычка простая: фиксируйте, какой кейс сломался, где он сломался и что считать правильным результатом. Тогда проверка не превращается в спор "вроде нормально", а остается обычным прогоном с понятным порогом ошибки.
Что проверить перед релизом
Перед релизом мало прогнать десять красивых примеров и успокоиться. Проверка маскирования ломается на мелочах: одна буква "Ё", сокращение в адресе или латинская "a" внутри русского слова, и чувствительные данные проходят дальше без шума.
Если у команды нет короткого набора обязательных проверок, она почти всегда пропускает именно такие случаи. Хуже всего, что промах может не всплыть в интерфейсе, но остаться в логах или трассировке.
Перед выпуском стоит проверить хотя бы пять вещей:
- Пары с "Е" и "Ё" в именах и фамилиях.
- Адреса с сокращениями вроде "корп.", "стр.", "кв.", "лит.", "д.".
- Строки со смешанными алфавитами: "Сергеи Ivanov", "Mосква", "Аlексandr".
- Один и тот же кейс в трех слоях: запрос, ответ и логи.
- Кто разбирает промахи после прогона и кто добавляет новый тест.
Если вы работаете через RU LLM, полезно отдельно посмотреть служебный след каждого запроса. У сервиса маскирование PII, метки AI-Law и аудит-записи встроены в поток обработки, но свою проверку это не отменяет: важно видеть, что сохранилось в логах, бэкапах и разборе инцидента внутри вашего контура.
Хороший признак перед релизом простой: команда может показать набор тестов, объяснить каждый провал и назвать дату повторной проверки после фикса. Если этого нет, релиз лучше притормозить на день, чем потом разбирать утечку неделями.
Что делать после первой волны тестов
После первого прогона набор нельзя считать закрытым. Самые полезные кейсы приходят не из таблицы, а из живых сбоев: письмо с адресом без номера квартиры, ФИО с редкой фамилией, строка вроде "Ceргeй Ivanov" с подменой части букв. Каждый такой инцидент сразу добавляйте в набор повторных проверок, иначе ошибка вернется через неделю в другом месте.
Для проверки маскирования PII лучше держать две метрики отдельно. Первая - тихие промахи, когда чувствительные данные прошли дальше как обычный текст. Вторая - ложные срабатывания, когда система скрыла то, что трогать не надо. Если смешать их в один процент, получится "средняя температура", а реальный риск потеряется.
Раз в спринт полезно прогонять весь набор заново, даже если в коде менялся только один фильтр. Детекторы PII часто ломаются не там, где их правили. Новая нормализация текста может улучшить поиск телефонов и одновременно испортить редкие русские адреса с корпусом, строением и литерой.
Рабочая схема здесь простая: после каждого инцидента добавлять новый тест и коротко записывать, что именно ускользнуло; раз в спринт прогонять полный набор, а не только свежие кейсы; считать промахи и ложные срабатывания в разных отчетах; заранее записать порог выпуска и имя владельца набора.
Порог выпуска лучше формулировать жестко. Например, ноль тихих промахов на чувствительных полях и не больше 2% ложных срабатываний на архиве реальных сообщений. Если порог не пройден, релиз не идет дальше, даже если общая точность выглядит прилично.
Если вы строите контур с LLM в РФ и используете RU LLM, отдельно проверьте, что попадает в логи, бэкапы и аудит-записи в каждом запросе. Платформа позволяет работать через единый эндпоинт, совместимый с OpenAI, но для безопасности этого мало: важно понимать, какие поля скрылись, какие остались и можно ли потом разобрать спорный случай без утечки исходных данных.
У такого набора должен быть один ответственный. Иначе тесты быстро копятся, дублируются и теряют смысл.
Часто задаваемые вопросы
С чего начать проверку маскирования PII?
Начните не с придуманных строк, а с кусков реальных чатов, CRM, писем и заявок. Там есть опечатки, лишние пробелы, сокращения и смешанный алфавит — именно на таком вводе маскирование чаще всего дает тихий промах.
Хватит ли чистых тестовых примеров для проверки?
Нет, на чистых примерах система почти всегда выглядит лучше, чем в бою. Оставляйте шум: двойные пробелы, кривые сокращения, разные раскладки и странный порядок слов.
Какие русские ФИО чаще всего проскальзывают?
Проверьте двойные фамилии, инициалы, падежи, формы с отчеством и пары с «Е» и «Ё». Полезны строки вроде «Смирнова-Лебедева А. Н.», «для Мироновой Ольги Сергеевны» и «И.И. Иванов».
Как правильно тестировать адреса и телефоны?
Смотрите не только на улицу и дом, но и на хвост адреса: квартиру, корпус, строение, индекс, подъезд и домофон. С телефонами отдельно гоняйте пробелы, скобки, дефисы и добавочные, иначе часть номера может остаться открытой.
Что делать со смешанной кириллицей и латиницей?
Берите одну нормальную строку и делайте из нее грязные копии: меняйте часть букв на латиницу, вставляйте неразрывные пробелы, ломайте раскладку. Если маскирование срабатывает только после нормализации, в проде это уже риск.
Как понять, что считать правильным результатом?
Сразу записывайте точный результат для каждого кейса. Не «скрыть адрес», а «город оставить, дом и квартиру скрыть, номер заказа не трогать» — тогда команда не спорит на глаз.
Почему нельзя смотреть только на ответ модели?
Этого мало, потому что PII часто утекает не в ответе, а в служебном следе. Проверяйте входной текст, предобработку, ретраи, логи, трассировки и аудит-записи; для потока через RU LLM это тоже обязательно.
Как лучше размечать ошибки после прогона?
Обычно хватает четырех типов: пропуск, ложное срабатывание, частичная маска и утечка в логах. Частичную маску не считайте успехом, если по остатку можно узнать человека.
Что делать после первого найденного промаха?
После любого реального сбоя сразу добавляйте этот пример в набор повторных проверок и помечайте, где он сломался. Иначе вы почините один случай, а через неделю та же дыра вернется в другой форме.
Что обязательно проверить перед релизом?
Перед выпуском проверьте хотя бы ФИО с «Е» и «Ё», адреса с сокращениями, смешанные алфавиты и один и тот же кейс в запросе, ответе и логах. Если работаете через RU LLM, отдельно посмотрите, что осталось в логах, бэкапах и аудит-записях внутри вашего контура.