Prompt template в разных командах: почему он ломается
Разбираем, почему prompt template в разных командах даёт разный результат: входные данные, локаль, даты, инструменты и простая схема проверки.
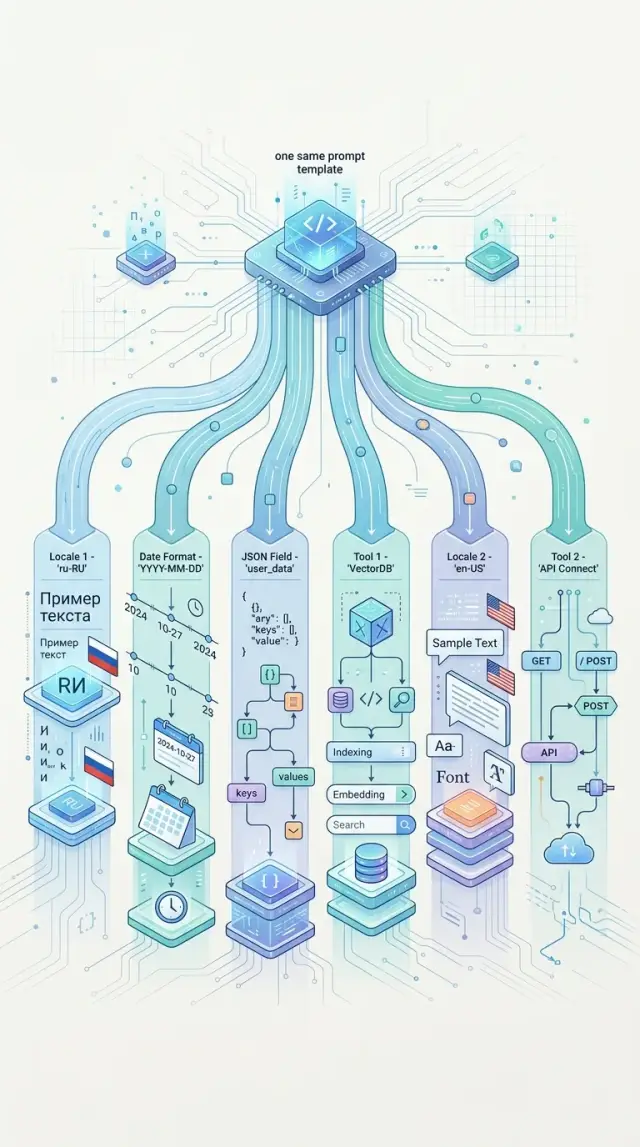
Почему шаблон ломается без видимой причины
Почти никогда шаблон не работает сам по себе. Он живет внутри кода, который собирает итоговый запрос к модели: добавляет system-инструкции, чистит пользовательский ввод, подставляет служебные поля, подключает инструменты и выставляет параметры вызова. На вид шаблон тот же, а запрос уже другой.
Из-за этого команды часто спорят не о той части системы. Одна говорит: шаблон стал хуже. Другая уверена, что ничего не менялось. Обе могут быть правы. Проблема часто не в тексте, а в том, как сервис собирает финальный payload.
Модель читает весь запрос целиком, а не только видимый prompt. Для нее имеет значение порядок сообщений, роли, формат данных, локаль, длина контекста, список tools и даже мелочи вроде пустых строк или скрытых меток. Если один сервис кладет правила в system, а другой вставляет их в user, поведение меняется. Если где-то перед отправкой убрали кусок истории, HTML или markdown-таблицу, ответ тоже уйдет в сторону.
Поэтому перед правкой шаблона стоит сравнивать не только сам текст prompt, а сырой запрос целиком. Обычно расхождение видно именно там.
Что команды по-разному подают на вход
Даже если текст шаблона совпадает символ в символ, модель может отвечать по-разному. Причина часто простая: команды по-разному готовят входные данные.
Самый частый сбой связан с пустыми полями. Одна команда оставляет null, пустую строку или маркер вроде "не указано", а другая просто удаляет поле из JSON. Для модели это разные сигналы. Если в шаблоне есть условная логика, исчезнувшее поле меняет смысл всей инструкции.
Похожая история с JSON. Где-то объект вставляют как объект, а где-то сначала превращают в строку и экранируют кавычки. Внешне данные похожи, но модель видит разную структуру. В одном случае она работает с полями, в другом - читает большой фрагмент текста с фигурными скобками.
Еще одна частая причина - сокращение контекста. Одни команды режут вход до лимита: убирают старые сообщения, сжимают логи, выкидывают метаданные. Другие отправляют все подряд. Если шаблон рассчитывает на примеры, пояснение или свежую историю диалога, такое сокращение сразу меняет результат.
Порядок блоков тоже влияет сильнее, чем кажется. Запросы "правила -> данные -> задача" и "задача -> справка -> формат ответа" выглядят похожими только для человека. Для модели это уже разные постановки.
Отдельная ловушка - имена переменных и значения по умолчанию. В одной команде поле называется customer_name, в другой client. Где-то пустой регион подменяют на "Москва", а где-то на "RU". Шаблон общий, но предположения внутри него уже разные.
Нормально переносится только тот шаблон, у которого есть явный договор на вход. Обычно в нем заранее фиксируют:
- какие поля обязательны, а какие можно не передавать
- чем пустое значение отличается от отсутствующего поля
- вставляется JSON объектом или строкой
- в каком порядке идут блоки сообщения
- какие значения подставляются по умолчанию
После этого остается прогнать один и тот же набор тестовых запросов через оба пайплайна и сравнить фактическое тело запроса. Если payload разный, причина уже найдена.
Как локаль, даты и время меняют смысл
Шаблон часто ломается не из-за модели, а из-за локали вокруг него. Модель видит язык полей, формат чисел, даты, часовой пояс и подписи интерфейса. Если у двух команд эти детали разные, смысл меняется еще до генерации ответа.
Самая частая ошибка - даты. Строка 04/03/2025 для одной команды означает 4 марта, для другой - 3 апреля. Если шаблон просит собрать события за прошлую неделю или назначить встречу, ответ может быть аккуратным по форме и неверным по сути.
С числами путаница не меньше. В русской локали 1,5 обычно значит полтора, а в англоязычных данных запятая может разделять тысячи. Строки 1,234 и 1.234 похожи, но смысл у них разный. Если шаблон считает скидку, лимит или средний чек, ошибка сразу попадает в результат.
Сокращения тоже мешают. Русские "пн", "ср" и "май" рядом с английскими "Mon", "Wed" и "May" создают лишний шум. Особенно плохо это работает, когда в том же запросе есть числа, статусы и служебные поля.
Слова "сегодня", "завтра" и "утром" зависят от часов, а не от автора шаблона. Если сервер живет в UTC, а команда работает по Москве, фраза "завтра в 09:00" около полуночи легко сдвигается на день. Без явного часового пояса время почти всегда спорное.
Даже ISO-формат не решает все сам по себе. Запись 2025-02-01 читается однозначно, но если в тексте prompt написано "сегодня", а в метаданных передано current_date=2025-02-01T00:30:00+03:00, у модели уже два источника времени. Если они расходятся, ответы начинают плавать.
Проще всего заранее привести данные к одному виду:
- даты передавать в формате
YYYY-MM-DD - время передавать вместе с часовым поясом
- использовать одно правило для дробной части и тысяч
- не сокращать месяцы и дни недели там, где важна точность
- держать язык служебных полей, интерфейса и примеров в одном стиле
Если шаблон должен жить в нескольких командах, локаль и время лучше считать частью входного договора, а не мелкой настройкой.
Почему инструменты меняют поведение
Модель строит ответ не только по тексту prompt, но и по списку tools, который видит в запросе. Один и тот же шаблон ведет себя по-разному, если в одной команде есть поиск и внутренние функции, а в другой доступна только генерация текста.
Это особенно заметно при переносе между провайдерами или через OpenAI-совместимый шлюз. Формат API может остаться привычным, но набор инструментов, их схемы и ограничения уже будут другими.
Представьте простой сценарий: модель должна проверить свежие данные и собрать ответ для клиента. У команды A есть web_search и get_order_status. У команды B поиска нет, а статус заказа лежит в функции order_lookup с другими параметрами. Текст шаблона тот же, но план у модели ломается уже на первом шаге.
Сильнее всего влияют четыре вещи. Первая - названия функций. Если одна команда зовет функцию search_docs, а другая knowledge_search, модель не всегда выберет нужную без явной подсказки. Вторая - схема аргументов. date и from_date, client_id и user_id, строка и массив выглядят похоже только для разработчика. Третья - порядок tools. Если первым стоит внешний поиск, модель чаще идет туда даже тогда, когда ответ есть во внутренней базе. Четвертая - права доступа. В одном окружении модель может создать тикет, а в другом только читать данные. Значит, и маршрут ответа будет другим.
Есть и менее заметные различия: сколько вызовов подряд разрешено, сколько секунд сервис ждет ответ, включены ли ретраи, возвращает ли инструмент полный JSON или только часть полей. Из-за этого шаблон иногда ломается не в словах, а в поведении. В первой системе модель успевает найти данные и собрать ответ. Во второй она упирается в таймаут или неполный ответ от инструмента и начинает импровизировать.
Если переносите шаблон между командами, переносите и договор на инструменты: список tools, имена функций, JSON schema, порядок, права и лимиты.
Короткий пример с двумя командами
Хорошо видно проблему на простом примере. Допустим, у компании есть общий шаблон для ответа клиенту: назвать дату заказа, сумму, статус и при необходимости уточнить правила возврата.
Поддержка и продажи используют один и тот же prompt template, но подключают его к разным данным. У поддержки дата приходит как 2025-02-03, сумма - как число 14990, а модель может сходить в базу знаний за правилами возврата. У продаж дата приходит строкой "3 февраля 2025 года", сумма - строкой "14 990 руб.", а из инструментов доступна только CRM.
Дальше модель начинает вести себя по-разному. В потоке поддержки она легко читает дату, понимает сумму как число и при спорном вопросе идет в базу знаний. Ответ выходит точным и коротким.
В потоке продаж та же модель спотыкается сразу в нескольких местах. Текстовая дата зависит от формата записи. Сумма уже содержит пробелы и валюту, поэтому модель то копирует ее как есть, то пытается нормализовать. CRM знает историю сделки, но не всегда знает актуальные правила возврата, и ответ становится более общим.
На вид шаблон один. По факту контекст разный: разные типы полей, разная локаль, разные форматы даты и разный набор инструментов.
Как проверять шаблон без долгих споров
Самый быстрый способ найти проблему - заморозить один реальный кейс и сравнить сырой запрос, который каждая команда отправляет в модель. Нужен именно тот объект, который ушел в API, без сокращений в логах и без "улучшений" в интерфейсе.
Проверка обычно занимает несколько шагов:
- Возьмите один и тот же кейс и один и тот же набор входных данных.
- Снимите полный payload:
system,user, tool definitions, параметры вызова, metadata. - Сверьте локаль, формат чисел, даты, часовой пояс и язык служебных полей.
- Сверьте список tools, их названия, аргументы, лимиты и права.
- Сравните не только финальный ответ, но и все промежуточные вызовы инструментов.
Обычно после такого сравнения спор быстро заканчивается. Видно, где именно запросы разошлись: в пустом поле, в формате даты, в другой схеме функции или в обрезанном контексте.
Если команды работают через RU LLM, общий OpenAI-совместимый эндпоинт сам по себе не делает интеграции одинаковыми. Зато по audit trail и сырым запросам проще увидеть, где разошлись локаль, tool schema или служебные поля. Это особенно полезно, когда несколько сервисов работают в одном российском контуре и кажется, что у них все настроено одинаково.
Частые ошибки при переносе
Одна из самых скучных, но дорогих ошибок - менять шаблон и не сохранять старую версию входа целиком. Потом ответ стал хуже, а сравнивать уже не с чем. Нужен не только текст шаблона, но и снимок всего запроса: сообщения, переменные, локаль, часовой пояс, tool schema и служебные поля.
Еще одна ошибка - складывать в одну переменную и обычный текст, и структурированные данные. Сегодня в context лежит абзац для оператора, завтра туда же попадает JSON клиента, а послезавтра массив событий. Модель читает это как один поток текста и начинает путать роли, границы и приоритеты.
Проще держать данные раздельно. Текст - в текстовых полях. JSON, даты, числа и флаги - в отдельных структурах. Чем меньше склейки перед отправкой, тем меньше сюрпризов.
Отдельно стоит следить за временем. Часто одна команда подставляет "сегодня" по времени браузера, а другая берет дату с сервера. В итоге для одного и того же запроса модель видит разные сутки. Для задач с дедлайнами, отчетами и фильтрами это быстро превращается в ошибку по смыслу.
Еще одна ловушка - проверять перенос на одном удачном кейсе. Так легко получить ложное чувство стабильности. Шаблон нужно гонять хотя бы на нескольких сценариях: пустые поля, длинный ввод, другой язык, спорный формат даты, отсутствие нужного инструмента.
И наконец, команды слишком часто смотрят только на финальный ответ. Но сравнивать надо весь запрос. Если одна команда отправляет tool definitions, а другая нет, если порядок сообщений разный или вход по-разному чистится перед отправкой, одинаковый шаблон уже работает в разных условиях.
Что сделать дальше
Сначала зафиксируйте среду вокруг шаблона. Для этого обычно хватает одной таблицы различий между командами: источник данных, предобработка, локаль, формат даты и времени, часовой пояс, system prompt, список tools и модель. Уже на этом шаге часто видно, что команды тестировали не один сценарий, а два похожих.
После этого соберите небольшой набор эталонных кейсов для регрессии. Пусть там будут обычные запросы, пустые поля, смешанная локаль, разные даты, спорные числа и хотя бы один сценарий без нужного инструмента. Для каждого кейса лучше заранее описать ожидаемый результат. Иначе команды будут сравнивать не поведение системы, а свои ожидания.
Если нужно быстро прогнать один и тот же сценарий на нескольких моделях в OpenAI-совместимой интеграции, это удобно делать через RU LLM: можно оставить текущие SDK и промпты, сменить base_url и сравнить поведение моделей в одном контуре. Но даже в таком случае сначала стоит выровнять вход, локаль и инструменты. Иначе вы сравниваете не модели, а разные условия запуска.
Когда у вас есть request snapshot до и после изменений, спор про "капризную модель" обычно исчезает. Остается конкретный список причин: пропущенное поле, другой часовой пояс, обрезанный контекст или несовпадающая схема tool calling. С этим уже можно работать спокойно и по шагам.
Часто задаваемые вопросы
Почему один и тот же prompt template дает разные ответы в разных командах?
Потому что шаблон живет не отдельно, а внутри всего запроса. Один сервис может класть правила в system, другой — в user, по-разному чистить ввод, резать историю, менять локаль и подключать разные инструменты. На вид prompt один и тот же, а модель читает уже другой контекст.
Что проверять первым делом: сам шаблон или весь запрос?
Смотрите на сырой payload целиком. Сравните system, user, историю сообщений, параметры вызова, metadata, список tools и порядок блоков. В большинстве случаев расхождение видно там, а не в тексте шаблона.
Чем пустое поле отличается от отсутствующего поля?
Для модели это разные сигналы. Пустая строка, null, маркер вроде «не указано» и полностью пропущенное поле меняют смысл условия внутри шаблона. Если хотите стабильный результат, заранее договоритесь, как передавать пустые значения.
Почему JSON объектом и JSON строкой работают по-разному?
Объект сохраняет структуру, и модель видит поля отдельно. Строка с экранированными кавычками выглядит как большой кусок текста, где смысл полей уже размыт. Если шаблон опирается на данные внутри JSON, передавайте их в одном формате во всех командах.
Как локаль влияет на работу шаблона?
Локаль меняет смысл еще до генерации ответа. Числа, даты, язык служебных полей и подписи интерфейса могут расходиться между командами, и модель начинает трактовать одинаковые данные по-разному. Лучше держать один язык и один формат для всех служебных частей запроса.
Почему даты и время так часто портят результат?
Чаще всего ломается трактовка дат вроде 04/03/2025 и слов вроде «сегодня» или «завтра». Если сервер живет в одной зоне, а команда работает в другой, модель легко сдвигает день или время. Передавайте даты в YYYY-MM-DD, а время — вместе с часовым поясом.
Зачем сравнивать tools при переносе шаблона?
Модель строит ответ с учетом доступных функций. Если в одной среде есть поиск и база знаний, а в другой только CRM, она выберет другой маршрут или начнет отвечать общо. При переносе важно сверять не только названия tools, но и схему аргументов, порядок, лимиты и права.
Как быстро найти причину расхождения без долгих споров?
Возьмите один реальный кейс и прогоните его через оба пайплайна без изменений. Потом снимите полный запрос, сравните поля, локаль, даты, tools и промежуточные вызовы функций. Такой разбор быстро показывает, где именно системы разошлись.
На каких кейсах лучше тестировать перенос prompt template?
Не ограничивайтесь одним удачным примером. Проверьте пустые поля, длинный ввод, смешанный язык, спорные даты, числа с разными разделителями и сценарий без нужного инструмента. Тогда вы увидите не случайный успех, а реальную устойчивость шаблона.
Чем RU LLM может помочь при проверке таких проблем?
RU LLM не делает интеграции одинаковыми сам по себе, но упрощает сравнение. Через один OpenAI-совместимый эндпоинт и audit trail легче увидеть, где команды разошлись в payload, локали, схемах tools или служебных полях. Это удобно, когда несколько сервисов работают в одном контуре и нужно быстро найти разницу.