Приоритетные очереди для LLM-запросов в разных сервисах
Приоритетные очереди для LLM-запросов помогают не смешивать клиентские чаты, внутренние ассистенты и ночные джобы, когда нагрузка растет.
Почему одна очередь ломает сервис
Когда клиентский чат, внутренний ассистент и ночная пакетная обработка стоят в одной очереди, порядок начинает решать случай, а не приоритет. Снаружи все выглядит терпимо: запросы идут, ответы приходят. Но задержка скачет, таймауты растут, а команда долго ищет причину.
Проблема в том, что у этих потоков разная цена ожидания. В клиентском чате лишние 2-3 секунды заметны сразу. Человек смотрит на экран и считает паузу ошибкой. Внутренний ассистент тоже не должен тормозить, но сотрудник обычно терпит чуть дольше. Ночная джоба почти всегда может подождать минуты, а иногда и больше.
Если держать все вместе, фоновые задачи легко давят срочные. Днем приходит пик обращений в чат, а система в этот же момент догоняет отложенную обработку документов, суммаризацию звонков или массовую разметку. Пакетные запросы длиннее, тратят больше токенов и дольше держат соединения. В итоге они съедают лимиты именно тогда, когда бизнесу нужнее всего быстрые ответы клиентам.
Клиенты замечают это первыми. У сотрудника внутри компании обычно есть запас терпения. Ночной процесс вообще не жалуется. А пользователь в чате просто видит, что сервис "тормозит", и уходит.
Часто команду успокаивает средняя задержка. Это ловушка. Среднее значение может выглядеть нормально, пока часть клиентских запросов уже уезжает в p95 или p99 и упирается в таймауты. Для бизнеса такая картина куда хуже, чем кажется по общей цифре на дашборде.
Даже если весь трафик идет через один OpenAI-совместимый endpoint, это не значит, что внутри должна быть одна общая очередь. Единая точка входа удобна для интеграции. Полосы обслуживания внутри нее должны быть разными.
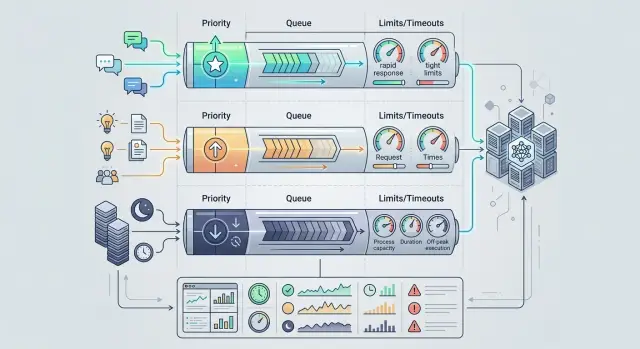
Простое правило здесь такое: срочный трафик не должен ждать рядом с терпимым. Чатам нужен приоритет и короткая очередь. Внутренним ассистентам - свой уровень обслуживания. Пакетным задачам - отдельный коридор, чтобы они не забирали лимиты в часы пик.
Какие полосы обслуживания нужны
Для большинства команд хватает трех или четырех полос. Этого достаточно, чтобы не смешивать живой диалог с фоновыми задачами.
Клиентские чаты ставят в самую быструю полосу. Тут важнее всего время до первого ответа. Даже короткая задержка бьет по опыту пользователя сильнее, чем слегка упрощенный ответ.
Внутренние ассистенты обычно живут в среднем приоритете. У них нередко длиннее промпты, больше документов в контексте и меньше чувствительность к задержке. Сотрудник не рад ждать, но несколько лишних секунд почти всегда лучше, чем деградация клиентского канала.
Ночные джобы и другие пакетные прогоны лучше уводить в отдельную медленную очередь. Даже если они запускаются "после рабочего дня", они легко забирают лимиты провайдера так, что утром команда получает медленные ответы в чатах. Отдельная низкоприоритетная полоса решает это проще, чем постоянная ручная настройка.
Небольшой резерв под ручные и аварийные запросы тоже полезен. Он не должен быть большим. Хватает маленького коридора для проверки гипотезы, восстановления после инцидента или прогона важного сценария перед релизом.
Клиентский чат лучше защищать жестче остальных. Для него ставят короткие таймауты, небольшую глубину очереди и понятный лимит на пользователя или сессию. Если полоса забита, честный упрощенный ответ или быстрый переход на более быструю модель обычно лучше, чем ожидание в полминуты.
Если вы уже ведете весь LLM-трафик через один шлюз, разделять потоки удобнее именно на его уровне. Так проще держать один SDK и одну интеграцию, но разные лимиты, таймауты и правила маршрутизации для каждого типа нагрузки. В случае с RU LLM это можно сделать без переписывания кода и промптов, потому что интеграция остается OpenAI-совместимой.
Как назначать приоритет
Приоритет лучше считать не от "важности сервиса" на словах, а от того, сколько пользователь или процесс может ждать без ощутимого вреда. Один и тот же ответ полезен через 2 секунды и почти бесполезен через 20.
Поэтому первый вопрос простой: какой максимум ожидания допустим для каждого потока. У клиентского чата терпимость к задержке самая низкая. Если ответ не начался быстро, человек закрывает окно или отправляет тот же вопрос еще раз. Внутренний ассистент обычно терпит дольше. Ночная пакетная задача почти всегда может уступить.
Приоритет полезно ставить до выбора модели и провайдера. Сначала вы решаете, кто может ждать, а кто нет. Потом выбираете, на какой модели и через какого провайдера этот запрос лучше выполнить.
Для каждого потока заранее зафиксируйте четыре вещи:
- максимальное ожидание в очереди
- общий таймаут запроса
- предел параллельности или длины очереди
- правило деградации при перегрузе
Для чата обычно нужен короткий общий таймаут и жесткий лимит очереди. Это кажется суровым, но длинное ожидание хуже честного отказа или быстрого ответа от более простой модели. На практике часто задают 1-2 секунды ожидания в очереди и 8-12 секунд на весь запрос.
Для пакетного потока логика обратная. Ему редко нужен приоритет, зато почти всегда нужен потолок по параллельности и скорости отправки. Иначе ночная джоба легко съедает весь запас токенов, соединений или слотов у провайдера и ломает утренний чат. Самое рабочее правило здесь простое: ограничивать и число одновременных задач, и частоту отправки запросов.
В пиковой нагрузке порядок уступки должен быть известен заранее, а не придуман в момент аварии. Обычно сначала замедляют пакетные задачи, потом урезают внутренние ассистенты, а клиентский чат держат до последнего. Если ресурсов все равно не хватает, сначала снижают качество у низкого приоритета: выбирают более дешевую модель, уменьшают max tokens, делают паузу между повторами длиннее.
Нормальная схема выглядит так: срочный трафик получает зарезервированную емкость, фоновый доедает остаток. Не наоборот.
Как внедрить схему без лишней боли
Начните не с настроек, а с карты трафика хотя бы за последнюю неделю. Сведите в одну таблицу все типы запросов: клиентские чаты, внутренние ассистенты, ночные пакетные задачи, повторы после ошибок, оценку ответов, служебные проверки. Делите их не по командам, а по поведению: сколько токенов они тратят, как долго могут ждать и что ломается, если ответ опоздал.
Смотрите не на среднюю нагрузку, а на пики. Сколько запросов приходит в минуту, сколько соединений висит одновременно, как часто идут длинные промпты, где бывают всплески на 10-15 минут. Именно короткие пики чаще всего смешивают все потоки в один затор.
Дальше помогает простой порядок:
- Пометьте каждый запрос по типу и источнику. Если меток нет, добавьте их в шлюз, API или очередь задач.
- Задайте для каждого типа свою очередь и свой предел параллельности.
- Выставьте разные таймауты и правила повторов. Чат не должен жить по тем же правилам, что и фоновая обработка.
- Заранее решите, что делать при перегрузе: где уместен повтор, где нужен отказ, где можно перейти на более быструю или дешевую модель.
- Включайте схему поэтапно, а не одним релизом на весь трафик.
Отдельные очереди полезны сами по себе, но без лимитов быстро теряют смысл. Если ночная задача может открыть сотни параллельных запросов, она все равно забьет канал. Поэтому очередь, лимит и таймаут нужно задавать как единый набор правил.
Схему лучше проверять на искусственном перегрузе. Смоделируйте вечерний пик чатов и одновременно запустите тяжелую пакетную обработку. Потом посмотрите не только на среднюю задержку, но и на хвост: сколько запросов ушло за 10 секунд, сколько получили таймаут, сколько было отменено и сколько пришло повторно.
Резкий релиз здесь обычно только мешает. Сначала можно включить новые правила для внутренних ассистентов, потом для части клиентских чатов, затем для пакетных задач. Если трафик проходит через единый шлюз, например RU LLM, такое разделение удобно вводить на уровне маршрутизации, не меняя SDK и не трогая клиентские приложения.
Хороший признак после запуска очень скучный: ночные задачи стали ждать дольше, но пользователь этого не заметил.
Простой пример для трех потоков
Представьте один LLM-шлюз для трех типов нагрузки: клиентский чат на сайте, внутренний ассистент для сотрудников и ночная задача, которая после полуночи разбирает пачки документов. Если пустить все в одну очередь, пакетная обработка легко забьет канал, и чат начнет отвечать по 15-20 секунд. Для пользователя это уже почти поломка.
Рабочая схема проще, чем кажется. Вы делите трафик на три полосы и сразу задаете для каждой свои лимиты, таймауты и глубину очереди.
Клиентский чат получает самый высокий приоритет. Ему дают больше параллельных слотов и короткий таймаут, например 6-8 секунд. Если модель не уложилась, сервис быстро уходит на более быструю модель или отвечает по упрощенному сценарию.
Внутренний ассистент живет во второй полосе. Сотрудник может подождать 15-30 секунд, если взамен получит более точный ответ или более длинный разбор.
Ночная джоба идет в третьей полосе. Она может ждать минуты, брать меньше слотов и спокойно растягиваться во времени, если днем нагрузка выросла.
Теперь представьте всплеск в 10 утра: пользователи массово открыли чат, а внутри компании пошли запросы от сотрудников. В этот момент система не трогает полосу чата, слегка режет пропуск для внутреннего ассистента и первой замедляет пакетную обработку. Документы не исчезают. Они просто обрабатываются позже, когда пик проходит.
Такую схему можно задать и без сложной логики. У каждого потока есть свой тег, свой лимит параллельности и свой бюджет на ожидание в очереди. Если все идет через единый OpenAI-совместимый endpoint, это удобнее всего делать на уровне шлюза, а не в каждом промпте отдельно.
Что измерять после запуска
После разделения трафика проблемы почти никогда не видны по одной средней задержке. Общая цифра может выглядеть нормально, пока клиентский чат уже стоит в очереди, а пакетные задачи забирают свободные слоты. Поэтому метрики нужно смотреть по полосам, а не одной суммой.
Первый сигнал - время ожидания в очереди по каждой полосе. Смотрите не только на среднее, но и на p95. Для чата именно длинный хвост чаще всего портит опыт: пользователь ждет пару секунд, жмет "повторить", и вы сами создаете лишнюю нагрузку. Для ночных задач ожидание в 10-20 секунд может быть нормой, если они укладываются в свое окно обработки.
Отмены по таймауту и ручные повторы лучше считать вместе. По отдельности эти метрики часто обманывают. Таймаут выглядит как единичный сбой, но через секунду тот же запрос приходит снова, и очередь растет еще быстрее. Если ручных повторов стало больше после смены лимитов или таймаутов, правило сработало хуже, чем кажется по дашборду.
У клиентского чата должна быть своя метрика отказов. Не смешивайте ее с внутренними ассистентами и фоновыми задачами. Внутренний бот переживет лишний повтор. Внешний чат теряет пользователя сразу.
После каждой правки полезно сверять и стоимость по типам нагрузки. Частая ошибка выглядит так: чат стал отвечать быстрее, но пакетные задачи ушли на более дорогую модель, и общий счет вырос в полтора раза. Смотрите расходы отдельно по клиентским диалогам, внутренним ассистентам и пакетной обработке.
Если у вас единый шлюз с логами по моделям и провайдерам, проверять это заметно проще. В RU LLM, например, удобно смотреть запросы, маршрутизацию и биллинг в одном месте. Тогда видно не только итоговую цену, но и какая полоса начала съедать бюджет после новой схемы.
Плохой набор сигналов обычно выглядит так: в часы пик растет очередь в чате, таймаутов мало, но повторов становится больше, доля отказов у внешнего канала выше, чем у остальных, а экономия видна только в общей сводке, но не в реальных сценариях. Когда эти метрики расходятся между собой, проблема обычно в правилах очереди, а не в самой модели.
Ошибки, которые быстро ломают схему
Одна из самых частых ошибок - одинаковый приоритет для всех чатов. Клиентский диалог, чат сотрудника и тестовый бот живут по разным правилам. Если смешать их в одну полосу, очередь быстро начинает вести себя странно: пользователь ждет ответ, а менее срочный трафик спокойно занимает слот.
Та же история начинается, когда продовый трафик и пакетные задачи делят общий лимит. Ночные джобы любят забирать все доступные запросы сразу. Утром система вроде работает, но первые живые пользователи уже попадают в хвост очереди.
Длинные задачи без таймаута тоже ломают картину. Один запрос на большой контекст, суммаризацию архива или массовую классификацию может висеть минутами и держать воркер занятым. Потом вся очередь выглядит перегруженной, хотя реальная причина в нескольких зависших задачах.
Еще одна плохая привычка - ручное повышение приоритета без жестких правил. Сначала это кажется удобным: попросил менеджер, задачу подняли выше. Через неделю "срочным" становится почти все. После этого очередь теряет смысл, а команда спорит уже не о SLA, а о том, чей запрос громче.
Отдельно стоит следить за повторами. Повторный запрос - это такой же новый запрос для очереди. Если клиент делает повтор через 2 секунды, потом SDK повторяет его еще раз, а сверху подключается ваш прокси, нагрузка растет в разы. Одна ошибка на стороне модели быстро превращается в маленький шторм.
Базовые правила здесь довольно приземленные: разделяйте хотя бы клиентские чаты, внутренние ассистенты и пакетные задачи; держите отдельные лимиты для живого трафика и фона; ставьте таймауты по типу запроса, а не один общий; разрешайте повышенный приоритет только по понятным условиям; считайте повторы отдельно от новых запросов. Даже хороший шлюз не спасет, если все типы нагрузки вы сложили в одну очередь и назвали это простотой.
Проверка перед релизом
Перед запуском полезно пройти короткий тест на здравый смысл. Такие схемы чаще ломаются не из-за сложной логики, а из-за пары пропущенных настроек.
Проверьте четыре вещи:
- у каждого типа нагрузки есть своя очередь
- для каждой очереди заранее понятен сценарий перегруза
- таймауты и повторы не конфликтуют между собой
- дежурный инженер видит длину очередей, отмены, всплески и долю отказов в одном месте
Есть и быстрый практический тест. Запустите короткий искусственный пик от пакетных задач и проверьте, что клиентские чаты не проседают по задержке. Потом смоделируйте таймаут у провайдера и посмотрите, не начинают ли повторы забивать очередь еще сильнее. Такие проверки занимают меньше часа, но часто экономят день разбора после релиза.
Если вы работаете через единый шлюз, лучше собрать очереди, лимиты, таймауты и маршруты моделей в одной схеме. Тогда дежурный видит картину сразу, а не собирает ее по логам и чужим панелям.
Что делать дальше
Не усложняйте схему с первого дня. Для большинства команд хватает трех полос: клиентские чаты, внутренние ассистенты и фоновые задачи. Это скучный старт, но он работает.
Дальше нужна не только настройка сервиса, но и договоренность между продуктом, поддержкой и инженерами. В пике система должна вести себя предсказуемо. Обычно команда сначала замедляет или останавливает ночные задачи, потом ужимает лимиты для внутренних сценариев, а клиентский чат оставляет на самой быстрой полосе. Поддержка должна знать, что говорить пользователю, когда обещать ответ и в какой момент звать инженеров.
После этого закрепите правила там, где команда ими пользуется каждый день. Приоритет, таймаут, число повторов, резервная модель и порог очереди лучше хранить в конфиге или коде, а не в заметке после встречи. Те же правила нужны и в операционных инструкциях: кто отключает пакетные джобы, кто меняет лимиты, кто смотрит на рост ошибок и задержки.
На ближайший спринт обычно хватает простого плана: завести три очереди и назначить владельца для каждой, зафиксировать порядок деградации, поставить алерты на длину очереди и долю таймаутов, а потом провести одну учебную перегрузку в рабочее время.
Если команде нужен единый OpenAI-совместимый endpoint в РФ, чтобы держать маршрутизацию, биллинг и аудит в одном месте, такую схему удобно собирать на RU LLM. Там можно оставить привычные SDK и код, сменить только base_url и при этом хранить логи внутри РФ.
Хороший результат выглядит скучно. В обычный день очередь почти незаметна. В плохой день клиентские чаты продолжают отвечать, внутренние ассистенты не мешают продакшену, а ночные задачи просто заканчиваются позже.
Часто задаваемые вопросы
Зачем вообще делить LLM-трафик на разные очереди?
Потому что у запросов разная цена ожидания. Пользователь в чате замечает даже пару лишних секунд, а ночная обработка часто может подождать минуты. Если держать всё в одной очереди, длинные пакетные задачи забирают слоты и портят ответ там, где задержка бьёт по бизнесу сильнее всего.
Сколько очередей нужно на старте?
Обычно хватает трёх полос: клиентские чаты, внутренние ассистенты и фоновые джобы. Если у команды часто бывают ручные проверки или срочные прогоны, добавьте маленький резервный коридор отдельно от остальных.
Как понять, кому дать самый высокий приоритет?
Смотрите не на название сервиса, а на то, сколько он может ждать. Чат на сайте почти всегда получает самый высокий приоритет. Внутренний ассистент идёт следом, а пакетные задачи уступают всем, если начинается пик.
Какие таймауты и лимиты лучше задать для разных потоков?
Для чата ставьте короткое ожидание в очереди и короткий общий таймаут. На практике часто хватает 1–2 секунд в очереди и 8–12 секунд на весь запрос. Внутреннему ассистенту можно дать больше времени, а фоновые джобы лучше жёстко ограничить по параллельности и скорости отправки.
Что делать, если очередь клиентского чата забита?
Не держите пользователя в длинном ожидании. Проще быстро переключиться на более быструю модель, урезать ответ по простому сценарию или честно вернуть отказ, чем заставить человека ждать полминуты и получить повторный запрос сверху.
Почему средней задержки мало для контроля?
Среднее сглаживает проблему. Пока общая цифра выглядит терпимо, часть чатовых запросов уже уезжает в p95 или p99, ловит таймауты и вызывает повторы. Для живого трафика именно хвост задержки чаще всего ломает опыт, а не среднее число на дашборде.
Как внедрить такую схему без тяжёлого релиза?
Начните с меток трафика. Пометьте запросы по типу и источнику, задайте каждой группе свою очередь, лимит параллельности, таймаут и правило деградации. Потом включайте схему по частям: сначала внутренние сценарии, потом часть чатов, и только после этого фоновые задачи.
Какие метрики проверять после запуска?
Смотрите на ожидание в очереди по каждой полосе, p95 задержки, таймауты, отмены и повторы. Отдельно считайте долю отказов во внешнем чате и расходы по типам нагрузки. Если чат стал быстрее, но пакетные задачи резко подорожали, схема требует правки.
Как не сломать очередь автоматическими повторами?
Повторы легко раздувают нагрузку. Если пользователь жмёт повтор, SDK повторяет запрос, а сверху ещё и прокси делает retry, одна ошибка превращается в волну новых запросов. Задайте понятные правила повторов и считайте их отдельно от новых обращений.
Можно ли разделить потоки через один endpoint и не менять код?
Да, это удобный вариант. Оставьте один OpenAI-совместимый endpoint для интеграции, а приоритеты, лимиты и маршрутизацию задайте внутри шлюза. В RU LLM можно сохранить привычные SDK и код, сменить base_url и развести потоки по разным правилам без переписывания промптов.