Порог эскалации модели: как выбрать без лишних затрат
Порог эскалации модели помогает решить, когда переводить запрос на более дорогую LLM. Разберем сигналы, формулу порога и быстрые проверки.
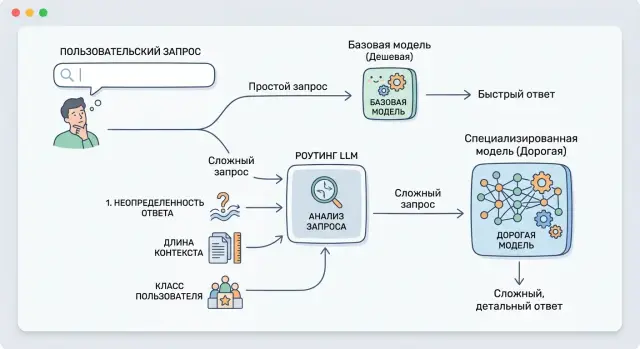
В чем здесь проблема
Идея кажется простой: пустить весь трафик через дешевую модель и снизить расходы. Часто это и правда работает. Короткие вопросы, простые классификации, пересказы и шаблонные ответы базовая модель закрывает без заметной потери качества.
Сбой начинается там, где запрос выглядит обычным, но ошибка в нем стоит дорого. Пользователь прислал длинный контекст, добавил исключения, попросил сверить несколько условий или ждет ответ в строгом формате. Дешевая модель может ответить уверенно и при этом пропустить важную деталь. Это самый неприятный случай: ошибка не бросается в глаза сразу.
Тогда экономия быстро исчезает. Команда тратит время на ручные правки, повторные прогоны и разбор жалоб. Если оператор поддержки потом чинит такой ответ 7-10 минут, дешевый вызов уже не кажется дешевым.
Обратная крайность тоже дорогая. Если слишком рано отправлять запросы на сильную модель, бюджет уходит в первые недели. Особенно это заметно в продуктах с большим потоком однотипных обращений. Пара лишних рублей на запросе выглядит мелочью, пока таких запросов не становится сотни тысяч.
Поэтому порог эскалации - это не поиск "самой умной" модели для всех задач. Это правило, которое отделяет простые запросы от тех, где ошибка обойдется дороже, чем вызов сильной модели. Хороший порог держит понятный баланс: где можно сэкономить без потерь, а где лучше заплатить сразу.
Сложность в том, что один сигнал почти никогда не работает сам по себе. Длина контекста не гарантирует, что запрос трудный. Неопределенность ответа легко прочитать неверно. Даже класс пользователя не всегда означает, что нужен максимальный уровень качества. Нужна комбинация сигналов, проверенная на ваших данных.
Если вы работаете через единый шлюз вроде RU LLM, где можно быстро переключать модели без смены SDK, кода и промптов, соблазн эскалировать шире становится еще сильнее. Технически это просто. Экономически - далеко не всегда. Без ясного порога маршрутизация быстро скатывается либо в лишние траты, либо в поток слабых ответов.
Какие сигналы брать в расчет
Рабочее правило обычно держится на трех-четырех сигналах. Если их становится десять, команда перестает понимать, почему запрос ушел на дорогую модель, а само правило превращается в набор исключений.
Первый сигнал - неопределенность ответа. Смотрите не на один флаг ошибки, а на несколько простых признаков сразу. Базовая модель может не падать с ошибкой, но все равно отвечать слабо: путать факты из контекста, пропускать обязательные поля, противоречить самой себе или писать слишком много оговорок там, где нужен точный ответ.
Второй сигнал - длина и форма контекста. Чем длиннее вход, тем выше шанс, что слабая модель потеряет важную деталь в середине или в конце. Но важен не только объем в токенах. Запрос на 20 тысяч токенов из одного договора и запрос на те же 20 тысяч токенов из восьми источников ведут себя по-разному. Во втором случае риск выше: модели нужно не просто прочитать текст, а связать куски между собой.
Третий сигнал - класс пользователя или, точнее, цена ошибки. Если человек просит пересказать статью из базы знаний, промах обычно дешев. Если тот же канал обрабатывает вопросы по платежам, персональным данным или условиям договора, промах уже стоит заметно дороже. Для банка, телекома и госсектора это чувствуется особенно быстро.
Обычно хватает простого правила: эскалировать, если неопределенность выше порога, если контекст длиннее заданного лимита или если запрос пришел из группы с высокой ценой ошибки. Такое правило легко объяснить команде, проверить по логам и поправить без долгой настройки. Если трафик идет через RU LLM, разбор становится проще еще и потому, что маршрут и служебные метки можно смотреть в одном месте.
Как читать неопределенность ответа
Неопределенность редко выглядит как одно число. Чаще она прячется в самом ответе. Модель пишет слишком осторожно, меняет версию на ходу или уходит в общие слова вместо ясного вывода.
Для порога эскалации это удобный сигнал. Если ответ выглядит шатким, не стоит дожимать дешевую модель. Проще сразу передать запрос на более сильную.
Что искать в тексте ответа
Сначала смотрите на явные оговорки. Слова вроде "возможно", "похоже", "не уверен", "скорее всего" не всегда означают ошибку, но часто показывают, что модель не держит ответ твердо. То же относится к мягким отказам: "у меня нет полного контекста", "могу ошибаться", "нужно уточнить".
Потом оцените форму ответа. Короткий и пустой текст, повторы, лишние самоисправления вроде "хотя нет" или "точнее" часто говорят о слабой уверенности. Если модель сначала утверждает одно, а через пару строк сама себя поправляет, это плохой знак.
Отдельно проверьте устойчивость. Возьмите один и тот же запрос и прогоните его 2-3 раза с короткими настройками. Если смысл заметно прыгает, модель колеблется. Полезно и слегка менять формулировку: переставить слова, убрать одно уточнение, сделать вопрос короче. Хороший ответ обычно переживает такие правки спокойно.
- Ловите оговорки и мягкие отказы.
- Сравнивайте 2-3 коротких прогона одного запроса.
- Проверяйте, ломается ли ответ после небольшой правки текста.
- Отмечайте повторы, резкую смену версии и самоисправления.
При этом не стоит путать честное "не знаю" со слабым ответом. Если модель прямо говорит, что ей не хватает данных, и не выдумывает детали, это нормальное поведение. Такой ответ можно оставить на той же модели и просто запросить недостающий факт у пользователя.
Хуже другой сценарий: модель звучит уверенно, но отвечает размыто и каждый раз по-разному. Именно такие ответы чаще всего и стоит эскалировать.
Полезно дать каждому сигналу вес. Один маркер осторожности еще не повод поднимать запрос выше. А вот два-три сигнала вместе уже дают понятный триггер.
Как длина контекста меняет выбор модели
Длина контекста влияет и на цену, и на точность. Базовая модель часто уверенно отвечает на короткий вопрос, но начинает терять детали, когда получает длинную переписку, несколько документов или большой кусок регламента.
Поэтому порог лучше задавать по диапазонам, а не одним числом. Простой старт выглядит так: до 2 тысяч токенов - короткий запрос, который обычно можно оставлять на базовой модели; от 2 до 10 тысяч - средний запрос, где уже стоит смотреть на другие сигналы; больше 10 тысяч - длинный запрос, где шанс эскалации заметно растет.
Но сама длина не все объясняет. Сообщение на 4 тысячи токенов с одной простой инструкцией легче, чем запрос на 3 тысячи токенов, где есть таблица, цепочка условий, цитаты из писем и кусок договора. Такие элементы лучше учитывать как штраф к базовому порогу.
Полезно отдельно учитывать сложную форму текста. Таблица, несколько длинных цитат или две-три вложенные инструкции уже повышают риск ошибки. Модель тратит часть внимания на разметку и сопоставление частей текста, а не на сам ответ.
Частый источник проблем - несколько документов в одном запросе. Если ответ собирается из трех-четырех фрагментов поиска, вероятность путаницы растет даже при умеренном объеме токенов. Модель должна сверить даты, термины, исключения и возможные противоречия. Это сильный сигнал в пользу более сильной модели.
Обратная ситуация тоже помогает экономить. Если запрос короткий, повторяющийся и с одним понятным намерением, эскалация часто не нужна. Вопрос вроде "какой статус у заказа" или "как сменить пароль" редко требует длинного контекста и сложного рассуждения.
В RU LLM такое правило удобно держать на уровне единого OpenAI-совместимого эндпоинта: сначала оценить число токенов, потом добавить штраф за таблицы, цитаты и вложенные инструкции, а затем повысить балл, если модель читает несколько документов. Это обычно работает лучше, чем грубое правило "все длинное отправлять на старшую модель".
Как учитывать класс пользователя
Одинаковый порог для всех запросов почти всегда дает плохой результат. Где-то вы зря платите за дорогую модель, а где-то пропускаете ошибку, которая потом стоит намного дороже токенов.
Поэтому правило эскалации лучше привязывать не только к качеству ответа, но и к тому, для кого этот ответ готовится. Две заявки могут дать одинаковую неопределенность, но решение по ним будет разным.
Смотрите сначала на цену промаха. Если ошибка ведет к жалобе, потере продажи, неверному действию сотрудника или ручной проверке на 20 минут, порог нужно снижать. Если ответ нужен для внутреннего черновика, заметки или быстрой прикидки, порог можно держать выше.
На старте обычно хватает трех классов. Высокий риск - ответы клиентам по деньгам, тарифам, срокам, персональным данным и спорным ситуациям. Средний риск - подсказки сотруднику, черновики писем и сводки для команды. Низкий риск - внутренние заметки, теги, краткие пересказы и идеи без прямого действия.
Этого достаточно, чтобы не утонуть в правилах. Десять сегментов редко помогают. Зато команда потом долго спорит, чем класс 6 отличается от класса 7.
Для высокого риска ставьте более низкий порог. Если модель сомневается даже умеренно, лучше сразу отправить запрос на более сильную модель. Для среднего риска порог можно оставить нейтральным. Для низкого риска, особенно для внутренних черновиков, разумно дать дешевой модели больше свободы.
Полезно считать это не в абстрактном "качестве", а в рублях или минутах. Жалоба клиента, сорванная продажа и ручная проверка - понятные потери. Когда риск переведен в деньги или время, спор о том, нужен ли дорогой маршрут, становится намного проще.
Если у вас есть единый шлюз вроде RU LLM, класс пользователя удобно определять до отправки запроса. Тогда одно и то же приложение может направлять VIP-диалог, обычный вопрос и внутренний черновик по разным правилам без смены SDK и без отдельной интеграции на каждый сценарий.
Как собрать правило по шагам
Рабочее правило почти никогда не рождается из теории. Его лучше собирать на реальных запросах, где видно, когда базовая модель справляется сама, а когда ошибка стоит слишком дорого.
Начните с небольшой выборки. Обычно хватает 100-200 запросов, если в них есть разные типы задач: короткие вопросы, длинные диалоги, сложные случаи с большим контекстом и обращения от разных групп пользователей. Если взять только один тип, порог быстро сломается в продакшене.
Дальше удобно идти так:
- Возьмите реальные запросы за последнюю неделю или две и разложите их по 3-5 понятным категориям.
- Прогоните их через базовую модель и вручную отметьте, где ответ можно принять, а где нужен более сильный вариант.
- Для каждого запроса посчитайте три сигнала: неопределенность, длину контекста и класс пользователя. Рядом зафиксируйте цену ошибки.
- Сложите сигналы в простую формулу, например
score = 0.5 * uncertainty + 0.3 * context + 0.2 * user_class. - Проверьте правило на свежей выборке, которую вы не использовали при настройке, и поправьте порог.
Цена ошибки почти всегда нужна. Один и тот же слабый ответ на внутренний черновик и на клиентский запрос - это разные ситуации. Если ошибка бьет по деньгам, жалобам или рискам, правило должно быстрее отправлять запрос на более сильную модель.
Сигналы лучше привести к одной шкале, например от 0 до 1. Так их проще сравнивать. Неопределенность можно брать из self-check, длину контекста - как долю от окна модели, класс пользователя - как фиксированный коэффициент риска. Для обычного пользователя это может быть 0.2, для критичного процесса - 0.8.
Если у вас уже есть единый LLM-шлюз, такой тест проще провести на живом трафике без смены SDK и клиентского кода. Но само правило все равно должно оставаться простым. Слишком хитрая формула редко живет долго.
Нормальный первый результат не обязан быть идеальным. Если правило эскалирует слишком много дешевых запросов, немного поднимите порог. Если оно пропускает опасные ошибки, увеличьте вес неопределенности или класса пользователя и проверьте выборку еще раз.
Пример для поддержки банка
В поддержке банка цена ошибки выше обычного. Если бот неверно объяснит списание по карте, клиент может пропустить срок оспаривания или решить, что вопрос уже закрыт.
Представим простой запрос: клиент пишет "Почему вчера списали 990 рублей по карте?" В истории нет вложений, длинной переписки и признаков мошенничества. Такой запрос разумно оставить на базовой модели. Она может проверить типовые причины: подписка, офлайн-списание, холд или повторное подтверждение операции.
Ситуация быстро меняется, если растет объем и сложность контекста. Клиент прикладывает выписку, копирует переписку с магазином и добавляет, что операция спорная. Теперь модели нужно сопоставить несколько источников, не потерять даты, суммы и статусы. Тут экономия на слабой модели часто выходит дороже, чем один точный ответ сильной.
В таком кейсе правило может быть очень простым. Короткий вопрос без документов и без истории спора остается на базовой модели. Если в запросе есть выписка, длинная переписка или спорная операция, диалог поднимается выше. Если клиент входит в группу высокого риска, порог снижается. Если модель пишет неуверенно, путает версии событий или просит слишком много уточнений подряд, запрос лучше эскалировать сразу.
Класс пользователя тоже меняет решение. Для обычного клиента ошибка неприятна. Для клиента с флагом fraud-risk, VIP-сегмента или активного спора цена ошибки уже другая. В этих сегментах лучше платить за более сильную модель раньше. Один лишний апгрейд обычно дешевле, чем жалоба в ЦБ, повторный контакт с оператором или неверное решение по спорной транзакции.
Хороший рабочий сценарий выглядит так: базовая модель делает первый проход, оценивает, хватает ли ей данных, и выставляет уровень неопределенности. Если ответ короткий, уверенный и опирается на один понятный сценарий, система оставляет его как есть. Если модель колеблется между несколькими причинами списания, видит длинный контекст или получает запрос от клиента высокого риска, диалог уходит на более сильную модель.
Если вы используете RU LLM, такое правило удобно держать в одном месте и менять без переписывания клиентского кода. Для банка это практичнее, чем вручную разводить трафик по нескольким API и потом искать, где именно порог сработал неправильно.
Где чаще всего ошибаются
Самая частая ошибка - один общий порог для всех запросов. На старте это кажется удобным: одно число, одно правило, меньше споров. Но вопрос про возврат денег, короткий FAQ и жалоба VIP-клиента несут разный риск, даже если выглядят похоже.
Из-за этого команда либо переплачивает на простых задачах, либо слишком долго держит сложные запросы на дешевой модели. Рабочее правило почти всегда учитывает хотя бы тип задачи, класс пользователя и цену ошибки.
Вторая ошибка - смотреть только на длину контекста. Да, длинный диалог или большой фрагмент документа повышает шанс ошибки. Но сама длина не говорит, насколько опасен промах. Если модель перепутает дату доставки, это неприятно. Если она неверно ответит по лимиту карты или статусу спорной операции, цена ошибки совсем другая.
Третья проблема - слишком сложная маршрутизация. Команда добавляет десять сигналов: длину истории, число сущностей, язык, канал, время суток, прошлые эскалации, тип клиента. Через месяц никто уже не может объяснить, почему почти одинаковые запросы пошли в разные модели. Такое правило трудно отлаживать, и ему перестают доверять.
Обычно хватает четырех вещей: неопределенности ответа, длины контекста, класса пользователя и цены ошибки для сценария. Если правило нельзя объяснить в двух-трех фразах, поддерживать его будет тяжело.
Еще одна ошибка всплывает позже: порог калибруют на старых логах и считают задачу закрытой. Потом приходят новые темы, меняются формулировки, сезонно растет доля нестандартных вопросов, и старое значение начинает врать. В поддержке это видно быстро: вчера правило держало нужную точность, сегодня уже пропускает сложные случаи. Поэтому порог нужно проверять на свежих данных, а не только на красивой исторической выборке.
Плохо работает и запоздалая эскалация. Сначала дешевая модель отвечает пользователю, потом система понимает, что ответ шаткий, и только после этого отправляет запрос в более дорогую модель. Пользователь уже увидел слабый ответ. Для чувствительных сценариев эскалацию лучше делать до показа ответа, когда признаки риска уже видны в запросе или в черновом выводе.
На практике полезнее простое правило, чем умное, но мутное. Например: если неопределенность высокая, контекст длиннее порога или пишет приоритетный клиент, запрос сразу уходит выше. В системах вроде RU LLM такую логику удобно пересматривать по свежим логам и аудит-трейлам, не меняя весь прикладной код.
Чек-лист перед запуском
Если правило эскалации нельзя объяснить за пару минут продукту, поддержке и инженеру on-call, оно слишком сложное. Порог должен жить не только в коде, но и в коротком описании: какой сигнал смотрим, какой вес даем, при каком суммарном балле поднимаем запрос на более дорогую модель.
Перед запуском проверьте несколько вещей:
- Правило записано простыми словами, а не только формулой.
- Все сигналы считаются до ответа пользователю.
- У правила есть владелец, который меняет веса по расписанию, а не после каждого инцидента.
- Логи объясняют каждую эскалацию: длину контекста, уровень неопределенности, класс пользователя и итоговый балл.
- Вы смотрите не только на цену, но и на то, где дорогая модель реально исправила ошибку или сняла риск.
Отдельно проверьте, не смешали ли вы сигналы разной природы. Неопределенность, длина контекста и класс пользователя - это разные вещи. Лучше, когда у каждого сигнала свой вес и понятный диапазон. Иначе правило быстро превращается в черный ящик, который никто не хочет трогать.
Хороший признак - команда может взять любой спорный запрос и восстановить цепочку решения без чтения исходников. Для этого нужны нормальные поля в логах и понятные причины эскалации. Если вы работаете через RU LLM, такой разбор проще встроить в общий контур аудита: по каждому запросу можно хранить маршрут, выбранную модель и служебные метки без отдельного набора интеграций.
И еще одно. Смотрите на метрики по сегментам, а не по одной средней цифре. Дешевая модель может хорошо держаться на коротких FAQ-вопросах и часто ошибаться на длинных обращениях премиум-клиентов. Средняя стоимость запроса при этом выглядит отлично, а качество в самом чувствительном сегменте уже просело.
Что делать дальше
Не стройте сложную схему с первого дня. Для старта хватит одного правила на три сигнала: насколько модель уверена в ответе, сколько контекста пришло в запросе и кто перед вами - обычный пользователь, VIP-клиент или внутренний сотрудник. Такой порог проще проверить на реальном трафике и проще объяснить команде.
Хороший первый вариант выглядит приземленно. Если ответ шаткий или контекст уже близок к пределу, запрос уходит на уровень выше. Если запрос простой и риск ошибки низкий, остается базовая модель. Этого достаточно, чтобы увидеть и первые деньги, и первые промахи.
Раз в неделю полезно разбирать не только случаи, где дешевая модель ошиблась. Смотрите и на обратную сторону: где дорогая модель тоже не помогла. Обычно там прячутся плохие промпты, лишний контекст, слабая разметка интентов или задачи, где эскалация вообще не нужна.
Отдельный фильтр нужен для запросов с персональными данными и для длинных диалогов. В таких кейсах цена ошибки выше обычной. Если вы работаете в банке, телекоме или госсекторе, лучше сразу вынести такие запросы в отдельную группу и проверять их отдельно, а не смешивать со всем трафиком.
Если трафик идет через единый OpenAI-совместимый эндпоинт, тесты обычно идут быстрее. В RU LLM можно менять модельный маршрут без переделки SDK, кода и промптов, что удобно для пилота. Команда тратит меньше времени на переподключение и быстрее сравнивает сами пороги.
После пилота зафиксируйте рабочие значения по классам пользователей. Один общий порог для всех почти никогда не нужен. Для массовых запросов допустим более строгий контроль затрат. Для премиум-сегмента и чувствительных сценариев лучше раньше отправлять запрос на более сильную модель.
Перед тем как закрепить правило, проверьте четыре вещи: сколько запросов уходит на эскалацию каждый день, где дорогая модель реально поднимает качество, какие классы запросов чаще всего ломают правило и как ведут себя длинные диалоги и запросы с ПДн.
Если через две-три недели правило почти не меняется, его уже можно считать рабочим и переносить из пилота в прод.
Часто задаваемые вопросы
С чего начать настройку порога эскалации?
Начните с простого правила на трех сигналах: неуверенность ответа, длина контекста и цена ошибки для этого сценария. Возьмите 100–200 реальных запросов, прогоните их через базовую модель и руками отметьте, где слабый ответ уже слишком дорог.
Какие сигналы лучше брать в первую очередь?
Обычно хватает трех вещей. Первая — модель путается, противоречит себе или пишет слишком осторожно. Вторая — запрос стал длинным или собран из нескольких документов. Третья — ошибка бьет по деньгам, жалобам или ручной работе.
Как понять, что базовая модель не уверена в ответе?
Смотрите на сам текст ответа. Плохой знак, если модель пишет размыто, меняет версию по ходу ответа, пропускает обязательные поля или каждый раз отвечает по-разному на один и тот же запрос. Если ей честно не хватает данных и она прямо об этом говорит, это не всегда повод для эскалации.
Когда длина контекста уже требует более сильную модель?
Ориентируйтесь не на одно число, а на диапазоны. Короткие запросы до пары тысяч токенов часто можно оставлять на базовой модели, средние уже стоит проверять по другим сигналам, а длинные лучше считать зоной риска. Если в запросе есть таблицы, цитаты, вложенные условия или несколько источников, поднимайте риск даже при умеренной длине.
Почему один общий порог почти всегда работает плохо?
Потому что цена промаха разная. Короткий FAQ, внутренний черновик и спор по платежу выглядят похоже только снаружи. Если держать один порог для всех, вы либо переплатите на простых задачах, либо пропустите дорогую ошибку там, где лучше было эскалировать раньше.
Как учитывать цену ошибки в правиле?
Переведите риск в деньги или время. Если слабый ответ ведет к жалобе, повторному контакту или ручной проверке на 20 минут, снижайте порог и отправляйте такие запросы выше раньше. Для черновиков и внутренних заметок можно дать дешевой модели больше свободы.
Нужно ли эскалировать до того, как пользователь увидит ответ?
Да, и лучше делать это до показа ответа. Если запрос уже выглядит рискованным из-за длинного контекста, ПДн, спорной темы или клиента из чувствительного сегмента, не стоит сначала показывать сырой ответ, а потом исправлять его дорогой моделью.
Сколько запросов нужно, чтобы собрать первый рабочий порог?
Для первого варианта обычно хватает 100–200 живых запросов, если в выборке есть разные типы задач. Берите не только простые обращения, но и длинные диалоги, случаи с документами и запросы от разных групп пользователей. Иначе порог сломается сразу после запуска.
Как протестировать порог и не переплатить на пилоте?
Не расширяйте правило без нужды. Если у вас уже есть единый OpenAI-совместимый шлюз вроде RU LLM, меняйте маршрут модели, а не приложение: так проще тестировать порог на живом трафике и смотреть, где дорогая модель правда снимает риск, а где только увеличивает счет.
Как понять, что порог уже пора пересматривать?
Смотрите на свежие логи хотя бы раз в неделю. Если выросла доля длинных диалогов, появились новые темы или модель стала чаще ошибаться в одном сегменте, старый порог уже врет. Хороший сигнал к пересмотру — когда почти одинаковые запросы слишком часто уходят по разным маршрутам или когда жалобы растут без явной причины.