План восстановления LLM-сервиса: RTO, RPO и переключение
План восстановления LLM-сервиса нужен там, где чат влияет на заявки, поддержку и продажи. Разберем RTO, RPO, роли, проверки и порядок переключения.
Что ломается, когда площадка падает
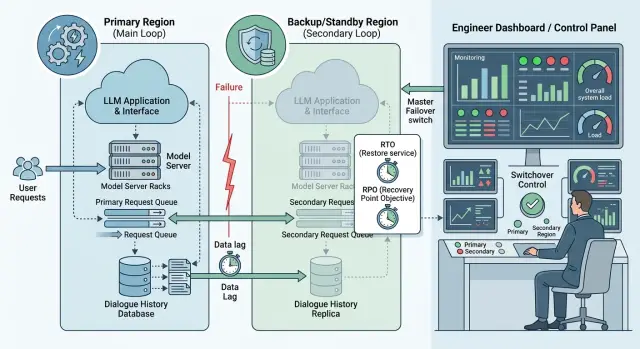
Проблема редко сводится к тому, что пользователь не видит ответ в чате. Если LLM встроена в рабочий процесс, сбой сразу бьет по операциям. Чат принимает обращение, собирает данные, присваивает тему, создает заявку в CRM и передает ее в нужную очередь. Когда площадка падает, цепочка рвется уже на первом или втором шаге.
Сильнее всего страдают процессы, где чат не просто помогает, а двигает работу дальше. Это поддержка, внутренний сервис-деск, онбординг клиентов, разбор претензий, сверка документов. Пока модель отвечает, все выглядит гладко. Как только ответы пропадают, сотрудники теряют входной поток, а система перестает понимать, что делать с новыми обращениями.
Полный отказ и медленная работа ломают сервис по-разному. При полном отказе запросы сразу возвращают ошибку или зависают до тайм-аута. Это видно быстро, и команда включает аварийный режим. Медленная работа опаснее. Первые 10-15 минут все выглядит терпимо, пользователи жмут "отправить" повторно, интеграции дублируют вызовы, а очередь растет почти незаметно.
Обычно первым встает не сам чат, а узлы вокруг него. Новые заявки не доходят до нужной очереди, операторы получают сырой текст без резюме и меток, CRM не видит заполненные поля или черновик ответа, SLA начинает гореть еще до того, как команда признает инцидент.
Дальше начинается ручной обход. На бумаге он выглядит просто: оператор сам читает диалог, сам выбирает категорию, сам переносит данные в CRM. На практике очередь растет очень быстро. Если на одну заявку уходит хотя бы на 4 минуты больше, то при 600 обращениях в день это уже 40 лишних часов ручной работы.
Проблема не только в задержке. Ручной режим дает ошибки, а они обходятся дороже. Один оператор назовет тему "возврат", другой "доставка", третий забудет поставить приоритет. Кто-то не перенесет номер заказа, кто-то отправит клиента не в ту линию. Потом команда разбирает не только хвост очереди, но и хаос в данных.
Если LLM влияет на операционные процессы, отказ площадки почти всегда выглядит как сбой сразу в нескольких системах. Пользователь видит молчащий чат. Оператор видит пустую или кривую карточку. Руководитель видит рост времени ответа, дубли и просадку по SLA. Поэтому подход в духе "перезапустим позже" почти никогда не работает.
С чего начать план
Рабочий план восстановления начинается не с красивой таблицы RTO, а со списка сценариев, где простой сразу бьет по деньгам, SLA или ручной нагрузке команды. Если чат помогает оператору закрывать обращения, подсказывает агенту колл-центра или запускает внутренний процесс, это нужно фиксировать отдельно. Один и тот же сбой по-разному влияет на клиентский интерфейс и на внутренний инструмент сотрудников.
Полезно пройтись по каждому сценарию и ответить на четыре вопроса: кто теряет время или деньги при остановке, сколько минут бизнес готов терпеть простой, можно ли на это время перейти на ручной режим и что ломается сразу, а что может подождать.
После этого нужен один владелец инцидента. Не группа, не комитет и не общий чат. Один человек принимает решение: ждать, переключать трафик, урезать функции или откатывать изменение. Если такого человека нет, команда тратит первые 20 минут на обсуждения вместо восстановления.
Следующий шаг - карта зависимостей. У LLM-сервиса почти никогда не падает только модель. Чаще ломается связка из API-шлюза, маршрутизации, очередей, хранилища истории диалогов, авторизации, логирования и внешних вебхуков. Если у вас есть единый шлюз вроде RU LLM, полезно заранее отметить, что идет через прокси к внешним провайдерам, а что работает на собственных моделях в российском контуре. Во время аварии это сильно экономит время: команда быстрее понимает, какой слой отказал и что можно обойти.
Еще на старте стоит зафиксировать, что можно временно отключить без потери процесса. Например, поиск по базе знаний, вложения, длинный контекст, автосуммаризацию или вторичную аналитику. А вот создание тикета, аутентификацию, запись действий оператора и обязательные проверки отключать нельзя, если на них держится сам процесс.
И сразу разделите клиентский чат и внутренние рабочие места. Внешний канал обычно требует более быстрого переключения, потому что клиент видит сбой сразу. Внутренние интерфейсы иногда могут 30-60 минут жить в урезанном режиме: без подсказок модели, но с доступом к карточке клиента, очереди и шаблонам ответов. Это упрощает план. Вы не пытаетесь спасти все одновременно, а сначала удерживаете самые чувствительные операции.
Как посчитать RTO и RPO без формальностей
RTO часто считают слишком оптимистично. На схеме сервис поднимается за 3 минуты, а в реальной аварии дежурный сначала ловит алерт, потом проверяет, что именно упало, и только после этого решает, в чем проблема: в модели, сети, хранилище истории или маршрутизации. Поэтому RTO лучше считать не "для LLM вообще", а для конкретных типов отказа.
Полное падение площадки, отказ одного провайдера моделей, потеря доступа к истории диалогов и зависшая очередь запросов дают разный ущерб. Если чат помогает оператору поддержки, пауза в 5 минут уже бьет по SLA. Если это внутренний помощник для подготовки писем, команда может пережить и 20 минут.
Честный RTO нужно мерить от первого алерта до первого нормального ответа пользователю. Не до момента, когда кто-то написал в чат "подняли", а до живого запроса, который прошел через резервный контур и вернул ожидаемый результат. В это время входят все действия дежурного: открыть инструкцию, сменить маршрут, проверить авторизацию, прогнать тестовый диалог и убедиться, что история подтягивается.
RPO тоже не стоит сводить к одной цифре на весь сервис. В LLM-системах обычно есть как минимум два разных объекта потери: история диалога и очередь запросов.
С историей все просто: сколько последних сообщений можно потерять без вреда для процесса. Если бот уточняет данные клиента, потеря даже двух реплик уже ломает разговор. С очередью вопрос другой: можно ли потерять запрос, нужно ли отправить его заново и что хуже - пропуск или дубль. Для службы поддержки, где чат создает обращения, это два разных риска.
Хорошая проверка - разобрать реальный инцидент по минутам. Допустим, в 10:02 пришел алерт, в 10:04 дежурный понял, что основная площадка недоступна, в 10:07 перевел трафик, а в 10:10 оператор получил ответ. Значит, честный RTO для этого сценария - 8 минут, а не 2.
Пороги для переключения тоже нужны конкретные. Например, если 5xx держится выше 10% три минуты подряд, если очередь старше 60 секунд или если медианная задержка выросла в четыре раза. Тогда команда не обсуждает, а переключает контур.
Если у вас один OpenAI-совместимый вход и резерв уже подключен заранее, RTO обычно меньше. Если при аварии нужно менять SDK, править код и вручную переносить контекст сессии, время почти всегда оказывается больше, чем кажется.
Что нужно подготовить заранее
Падение площадки редко выглядит как полная тишина. Чаще ломается один кусок: маршрут к провайдеру, конкретная модель, хранилище сессий или очередь ответов. Поэтому план восстановления стоит строить вокруг нескольких типов отказа, а не вокруг одной абстрактной аварии.
Первое, что нужно держать наготове, - резервный маршрут к моделям. Если основной трафик идет через одного провайдера, у вас должен быть второй путь, который можно включить без правки приложения. Для команд, которые уже работают через OpenAI-совместимый слой, это проще: меняется base_url, а SDK и промпты остаются прежними. В российском контексте резервом может быть другой провайдер или контур через RU LLM, где запросы можно переключить на другой источник модели или на размещенную в РФ open-weight модель. Такой вариант особенно полезен там, где важны низкая задержка, работа внутри российского периметра и соблюдение требований по хранению данных.
Состояние диалога и незавершенные запросы
Историю диалога лучше хранить вне падающей площадки. Если сессия живет только в памяти чат-сервиса, после сбоя оператор увидит пустой экран, а клиенту придется повторять все сначала. Надежнее держать состояние в отдельном хранилище и записывать туда не только сообщения, но и служебные поля: id сессии, выбранную модель, версию промпта и время последнего ответа.
Незавершенные запросы стоит отправлять в очередь на повтор. Иначе часть обращений просто исчезнет между фронтом и моделью. У такой очереди должны быть idempotency key, число попыток и причина повтора. Тогда сервис не создаст два разных ответа на один и тот же запрос и не потеряет разговор, который завис на полпути.
Что часто забывают
Перед аварией никто не хочет выяснять, что у резерва закончился лимит или токен не дает доступ к нужной модели. Поэтому заранее проверьте срок действия токенов, лимиты по провайдерам и моделям, права сервисных аккаунтов, доступ к журналам и очередям, а также отдельные алерты для основного и резервного контура.
Еще одна частая ошибка - считать отказ одной модели отказом всего сервиса. Это разные события. Если одна модель отвечает с ошибками или резко замедлилась, роутер должен снять ее с трафика, а чат должен продолжить работу на другой модели с понятным снижением качества. Полный отказ сервиса стоит объявлять только тогда, когда не работает сам слой маршрутизации, сессии или другие критичные зависимости.
Если эти вещи готовы заранее, переключение занимает минуты, а не полдня с ручным поиском потерянных диалогов и недоступного резерва.
Порядок переключения по шагам
Когда чат влияет на возвраты, смену тарифа или ответы оператору, переключение нельзя делать на ходу. Нужен короткий и жесткий порядок действий, чтобы команда не спорила во время сбоя.
Первые минуты
Сначала дежурный фиксирует инцидент: точное время начала, что сломалось, какой контур затронут и кто принял решение о переключении. Это нужно не для отчета, а чтобы потом правильно посчитать RTO и не гадать, когда сервис реально перестал работать.
Сразу после этого команда отключает рискованные сценарии. Чат можно временно оставить в режиме справки, но лучше закрыть все действия, которые меняют состояние систем: создание заявок, списания, возвраты, смену статуса заказа, отправку команд во внутренние сервисы. Если бот ошибется дважды, последствия придется разбирать часами.
Дальше инженер переводит трафик на резервный контур. У кого-то это запасной провайдер, у кого-то свой кластер, у кого-то OpenAI-совместимый шлюз с заранее настроенной маршрутизацией. Если резерв построен через RU LLM, переключение часто сводится к смене маршрута или base_url без правок SDK и промптов. Но это работает только тогда, когда правила маршрутизации и доступы проверили заранее.
Перед возвратом нагрузки
После переключения нельзя сразу открывать весь поток. Сначала нужно проверить три вещи:
- история диалогов читается и не потерялась;
- очереди не содержат старые задания, которые уйдут повторно;
- идемпотентность работает для всех операций с внешним эффектом.
Простой пример: клиент попросил отменить доставку, первый контур упал после отправки команды, а резервный получил тот же запрос еще раз. Если система не умеет распознавать дубликаты по request_id или operation_id, получится двойное действие.
Возвращать нагрузку лучше поэтапно. Сначала внутренние пользователи, потом небольшой процент реальных сессий, потом весь трафик. На каждом шаге команда смотрит на задержку, долю ошибок, длину очередей, число повторов и отклонение по бизнес-метрикам. Для поддержки это могут быть неверные ответы, пустые резюме диалога или рост ручных эскалаций.
Все ручные действия стоит записывать прямо по ходу инцидента: кто отключил операции, кто сменил маршрут, какие флаги включили и какие очереди чистили. В такие моменты память подводит быстро. Без этого журнала следующий отказ снова превратится в импровизацию.
Пример для службы поддержки
Представим чат поддержки интернет-магазина. Клиент пишет: "Не прошла оплата, заказ завис". Бот уточняет номер заказа, проверяет статус и сразу создает заявку в CRM. В такой схеме сбой LLM бьет не только по ответам в чате. Он ломает весь операционный поток: заявка может не создаться, диалог может потеряться, а клиент уйдет без номера обращения.
В 11:07 основной провайдер начинает отвечать с ошибками и тайм-аутами. Виджет чата еще открыт, сообщения от клиента приходят, но бот уже не может нормально продолжить разговор. Если система хранит переписку только по пути к модели, часть истории потеряется. Поэтому каждое сообщение лучше записывать в свою базу до отправки в LLM. Туда же стоит писать ID клиента, канал, время, статус диалога и номер обращения, если он уже создан.
Рабочий порядок здесь простой. Клиент отправляет сообщение, backend сразу сохраняет его в журнале диалога. После первого понятного запроса система создает тикет в CRM и возвращает номер обращения. Только потом сервис вызывает модель, чтобы сгенерировать ответ. Если модель не ответила, чат все равно знает, что клиент писал и какой тикет уже открыт.
Дальше срабатывает правило переключения. Например, если за 30 секунд прошло три ошибки подряд или задержка ответа выросла выше 8 секунд, новые реплики идут в резервный контур. Если компания использует OpenAI-совместимый шлюз, такой переход часто проходит без смены SDK и клиентского кода. Меняется только маршрут к другому провайдеру, а приложение продолжает работать через тот же API.
Оператор берет разговор вручную не на всякий случай, а по понятному правилу. Обычно это нужно в двух случаях: резерв тоже отвечает плохо или запрос относится к деньгам, доставке, блокировке аккаунта и другим чувствительным темам. Оператор открывает карточку и видит всю переписку, последний статус, номер обращения и шаг, на котором бот остановился. Клиенту не приходится повторять все заново.
После стабилизации не стоит сразу возвращать весь трафик на основной маршрут. Команда сначала проверяет 5-10% новых чатов, смотрит на ошибки и дубли в CRM, а потом поднимает долю выше. Активные разговоры лучше не дергать: если чат уже ушел в резерв или к оператору, пусть там и завершится. Так меньше путаницы и меньше лишних тикетов.
Ошибки, из-за которых план не сработает
План восстановления часто выглядит аккуратно на бумаге и разваливается в первый же сбой. Обычно проблема не в модели и не в сервере. Ломается сам рабочий процесс вокруг чата.
Самая частая ошибка - команда проверяет только ответ модели. Тест считается успешным, если резервный контур выдает осмысленный текст, но этого мало. Нужно прогонять весь путь запроса: авторизацию, историю диалога, вызовы внутренних систем, запись логов, лимиты, тайм-ауты и возврат ответа в интерфейс.
Для операционного чата это особенно опасно. Если бот в поддержке умеет не только отвечать, но и создавать заявку, менять статус заказа или передавать данные в CRM, один удачный ответ ничего не гарантирует.
Вторая проблема - резерв не видит прошлые сообщения. Формально сервис поднялся в пределах RTO, но по факту он слепой: не знает, что уже обещал клиенту, какие данные запросил и на каком шаге остановился. В такой ситуации оператор получает раздраженного пользователя, а не восстановленный процесс.
Отдельно стоит проверять очередь. Во время сбоя она часто начинает дублировать запросы: клиент повторно нажал кнопку, фронт повторил отправку, воркер после тайм-аута взял задачу заново. В чате это быстро превращается в лишние действия - две заявки вместо одной, два списания, два одинаковых уведомления.
Слабое место часто и в управлении инцидентом. Когда площадка уже упала, дежурные не должны спорить, кто дает команду на переключение чата. Если нет одного ответственного, люди легко теряют 10 минут на согласования, хотя сам перенос трафика занял бы 2 минуты.
Даже единый шлюз и привычный OpenAI-совместимый эндпоинт не спасают, если роли не расписаны заранее. Техническая простота не заменяет порядок действий.
И еще один типичный промах: план живет в документе, но учений нет. Без тренировок команда не замечает мелкие, но неприятные вещи - устаревший секрет, пустой DNS cache, недоступный журнал аудита или сломанный доступ у дежурного. Один короткий прогон раз в квартал обычно полезнее десяти страниц регламента.
Короткая проверка перед запуском
Перед тем как считать план рабочим, проверьте пять вещей.
- У инцидента есть один владелец на смене и человек на подхвате. Имена, телефоны и право принимать решение известны заранее.
- Бизнес подтвердил допустимое время простоя и допустимую потерю данных в понятном виде, без общих формулировок.
- Резервный контур проходит живой тест каждый месяц, а не только проверку на бумаге.
- История диалога переживает переключение, и пользователь не теряет контекст.
- Команда знает, кто и по какому правилу возвращает трафик назад.
Обычно слабое место здесь одно и то же: все уверены, что история чата "где-то сохраняется", но никто не проверял, как она ведет себя после смены провайдера или региона. Если вы используете OpenAI-совместимый шлюз, например RU LLM, смена base_url сама по себе упрощает переход на резерв. Но состояние диалога это не решает. Его все равно нужно хранить отдельно от точки отказа.
Хороший признак готовности очень простой: дежурная команда может за 15 минут назвать владельца инцидента, целевые RTO и RPO, дату последнего теста, место хранения истории и правило возврата трафика. Если хотя бы на один пункт ответ расплывчатый, план еще сырой.
Что сделать дальше
План восстановления полезен только после живой проверки. На бумаге RTO почти всегда выглядит лучше, чем в реальной аварии, особенно если чат влияет на поддержку, внутренние заявки или антифрод.
Хотя бы один раз проведите учебный отказ в рабочем контуре без предупреждения сервисной команды. Владельца процесса и ответственных за риск лучше предупредить заранее, но дежурная смена должна пройти сценарий как обычный сбой. Так быстро видно, кто ищет доступы, кто не помнит порядок действий и где теряются лишние 10-15 минут.
После теста фиксируйте не впечатления, а метки времени: когда площадка перестала отвечать, когда дежурный заметил сбой, когда команда начала переключение, когда пользователи снова получили ответы и сколько контекста диалогов потеряли. По этим данным вы получите фактический RTO и реальный RPO. Если в плане стоит 10 минут, а по журналу вышло 27, нужно менять схему доступа, алерты, роли и набор ручных действий.
Параллельно подготовьте второй совместимый эндпоинт и проверьте простую замену base_url без правок SDK, промптов и клиентского кода. Это скучная проверка, но именно она часто спасает во время отказа площадки. Чем меньше ручной работы в момент сбоя, тем меньше шанс сломать что-то еще.
Если нужен резерв внутри РФ, такой вариант лучше оценивать заранее, а не в день инцидента. Например, RU LLM дает OpenAI-совместимый эндпоинт, маршрутизацию между провайдерами, хранение логов и бэкапов внутри РФ и поддержку российского контура. Для части команд этого достаточно, чтобы собрать резервный путь без отдельной переделки приложения.
Отдельно проверьте логи, бэкапы и журнал запросов. Если в системе есть персональные данные, хранение и восстановление должны совпадать с требованиями 152-ФЗ не в описании, а в реальных настройках и процедурах. Ошибка здесь часто очень простая: резервный контур есть, но логи уходят не туда или бэкап нельзя быстро поднять.
И последнее. Обновляйте план раз в квартал. За три месяца у команды легко меняются модели, провайдеры, доступы и ответственные. Короткая проверка на полчаса обычно находит больше слабых мест, чем длинная встреча по статусам.
Часто задаваемые вопросы
Что обычно ломается первым при падении LLM-площадки?
Чаще всего первым ломается не окно чата, а цепочка вокруг него. Новые обращения не доходят до нужной очереди, CRM не получает поля, а оператор видит сырой текст без резюме и меток.
Как считать RTO для LLM-сервиса?
Берите не среднее по сервису, а отдельные сценарии отказа. Считайте время от первого алерта до первого нормального ответа пользователю через резервный контур, включая проверку авторизации, истории и тестовый запрос.
Что учитывать в RPO, кроме истории чата?
Не ставьте одну цифру на весь сервис. Отдельно оцените потерю истории диалога и потерю запросов в очереди, потому что пропуск и дубль дают разный ущерб для поддержки, CRM и денег.
Кто должен принимать решение о переключении на резерв?
Назначьте одного владельца на смене. Он решает, ждать ли, резать ли функции, переводить ли трафик и когда возвращать нагрузку назад.
Что лучше отключить первым во время инцидента?
Сначала закройте действия с внешним эффектом: создание заявок, списания, возвраты, смену статуса заказа и команды во внутренние системы. Справочный режим можно оставить, если он не меняет данные.
Как не потерять контекст диалога при переключении?
Храните состояние диалога вне падающей площадки. Записывайте сообщения, id сессии, модель, версию промпта и время последнего ответа в отдельное хранилище до вызова модели.
Как защититься от дублей после тайм-аутов и повторных отправок?
Используйте очередь с idempotency key, числом попыток и причиной повтора. Тогда сервис распознает повторный запрос и не создаст две заявки, два списания или два одинаковых ответа.
Когда нужно переключать трафик, а не ждать?
Не ждите полного отказа. Заранее задайте пороги: например, доля 5xx выше выбранного уровня несколько минут подряд, очередь старше заданного времени или резкий рост задержки.
Как правильно вернуть нагрузку после аварии?
Возвращайте поток поэтапно. Сначала проверьте внутренние рабочие места, потом пустите малую долю новых сессий и только после этого открывайте весь трафик, если ошибки и дубли не растут.
Как часто нужно проверять план восстановления?
Делайте живой прогон хотя бы раз в квартал и снимайте метки времени. После теста смотрите не на ощущения, а на фактический RTO, потери контекста, дубли в очередях и готовность резервного маршрута.