Память диалога в enterprise-чате: как хранить факты отдельно
Память диалога в enterprise-чате помогает хранить факты о пользователе отдельно, сокращать токены и держать ответы точными без длинного контекста.
Почему длинная история ломает чат
Когда ассистент отправляет в модель весь прошлый диалог, каждый следующий ответ обходится дороже предыдущего. Сначала рост почти незаметен. Потом один короткий вопрос начинает тащить за собой десятки старых реплик, которые уже не помогают.
Страдает не только счет. Модель заново читает старые уточнения, отмененные решения и случайные детали, а потом пытается понять, что важно именно сейчас. Если в истории много шума, ответ начинает плыть. Пользователь спрашивает про новый лимит, а модель цепляется за черновик из позавчера.
Повторы делают ситуацию еще хуже. Имя клиента, роль сотрудника, язык общения, уровень доступа, правила тона и внутренние ограничения часто едут вместе с историей снова и снова. Новой информации мало, токенов тратится много.
Обычно проблема видна по четырем признакам:
- короткие вопросы стоят почти как длинные;
- ответы приходят медленнее;
- старые детали спорят с новыми;
- повторы раздувают запрос без пользы.
Есть и менее заметный эффект. Чем длиннее контекст, тем труднее предсказать поведение модели. Сегодня она опирается на свежую реплику, завтра на случайную фразу из начала беседы. Для рабочего чата это плохой режим. Люди ждут ровный и понятный ответ, а не лотерею.
Простой пример. Сотрудник поддержки пять дней переписывается с внутренним ассистентом. В первый день он сказал, что работает в розничном блоке, пишет на русском и видит заявки только по своему региону. Если система каждый раз тянет весь разговор, к пятому дню модель читает сотни лишних строк ради трех постоянных фактов и одного нового вопроса. В такой схеме память превращается в груз.
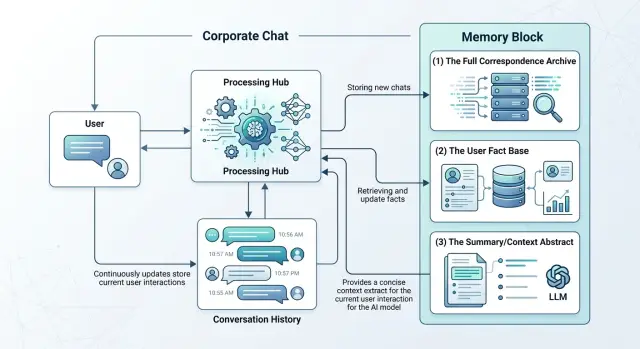
Где проходит граница между памятью и контекстом
Память и контекст часто смешивают, а потом чат путает старые факты с текущей задачей. Разделение простое. Память хранит то, что остается верным дольше одного разговора. Контекст нужен только для ответа здесь и сейчас.
В память обычно попадают устойчивые факты о человеке и его работе: роль, команда, рабочий язык, доступные системы, повторяющиеся ограничения и привычный формат ответа. Если сотрудник почти всегда просит короткую сводку для руководителя, это похоже на память.
Контекст - это свежий слой. Сюда входят текущий вопрос, последние реплики, активный документ, номер заявки, временная цель и детали, которые важны только в этой сессии. Если пользователь пишет, что сегодня подменяет коллегу и смотрит чужой портфель, такую деталь не стоит сохранять надолго.
Полезный тест звучит так: этот факт поможет через неделю без дополнительных объяснений или только запутает модель? Если поможет, его можно хранить как память. Если факт привязан к одному дню, одному файлу или одной задаче, оставьте его в контексте.
На практике удобно держать два отдельных блока. В первом лежит профиль пользователя: например, риск-команда, русский язык, краткий вывод в начале. Во втором - все, что относится к текущему кейсу: заявка N, приложен PDF, ответ нужен до 500 символов. Когда эти слои разделены, запросы становятся короче, а ответы стабильнее.
Это особенно заметно в регулируемой среде. Если компания использует единый LLM-шлюз, лучше передавать в модель короткий профиль отдельно от свежих сообщений и материалов по задаче. Тогда ассистент не тащит весь хвост переписки в каждый запрос.
Какие факты хранить отдельно
В памяти не нужен весь разговор. Нужны только данные, которые заметно улучшают следующий ответ.
Начните с базового профиля: имя, роль, отдел и предпочитаемый язык общения. Для внутреннего чата этого часто уже достаточно, чтобы убрать лишние уточнения. Модель не будет каждый раз спрашивать, кто перед ней и в каком стиле писать.
Следом идут рабочие факты, которые прямо влияют на результат. Это набор доступных систем, регион, проект, очередь поддержки, статус клиента или сотрудника. Если менеджер видит CRM и биллинг, а стажер нет, чат должен знать это заранее, а не угадывать по косвенным фразам.
Отдельно храните ограничения. Сюда входят правила по персональным данным, запрет на некоторые темы, внутренние пометки вроде не показывать суммы без маскирования. В банке, телекоме или госсистеме такие вещи лучше задавать явными фактами. Старый кусок диалога для этого не подходит.
Есть и простые настройки ответа. Один человек любит три коротких пункта, другой просит таблицу, третий всегда хочет поля риск, срок и следующий шаг. Это мелочь только на вид. На практике такие настройки сильно уменьшают число уточнений.
Что не стоит хранить долго
Разовые просьбы, настроение в конкретном чате и временные детали лучше не переносить в долгую память. Фраза сегодня я спешу не должна жить месяц. А вот отвечать кратко по-русски уже может.
Еще одна частая ошибка - сохранять догадки. Если человек один раз написал на русском, это еще не значит, что русский стал его постоянным языком. Если модель решила по контексту, что пользователь работает в комплаенсе, это не факт. Хранилище памяти должно принимать только подтвержденные данные.
У каждой записи должны быть как минимум две подписи: источник и дата обновления. Запись отдел: риск из HR-системы надежнее, чем тот же факт со слов пользователя полгода назад. Источник помогает понять, чему доверять, а дата не дает тащить в ответ давно устаревшую информацию.
Как хранить факты, чтобы их можно было обновить
Надежнее хранить не куски старой переписки, а отдельные записи. Не пользователь однажды написал про ипотеку, а product_interest = ипотека. Так запись проще проверить, обновить и удалить без разбора всего диалога.
У каждой записи обычно есть тип, значение, источник, дата обновления и уровень уверенности. Для временных вещей добавляют срок жизни. Простой пример: type = preferred_language, value = ru, source = user_explicit, updated_at = 2026-04-27, confidence = high.
Обновлять факт стоит только после явного сигнала. Если человек прямо сказал писать по-русски, запись можно сохранить. Если он один раз задал вопрос на русском, лучше подождать повторения или подтверждения. То же правило работает для должности, региона, продуктового интереса и рабочих задач. Модель любит достраивать картину. Слой памяти не должен принимать ее догадки за истину.
Для временных данных задавайте TTL. Предпочтение по формату ответа может жить 30 дней. Просьба не присылать уведомления до пятницы должна исчезнуть после даты. Без срока жизни память быстро обрастает мусором и начинает мешать: старые привычки выглядят как актуальные, хотя пользователь давно работает иначе.
С персональными данными лучше договориться заранее. Если запись содержит ФИО, телефон, табельный номер, паспортные или платежные данные, система должна понимать, где это хранится, кто имеет доступ и когда запись удаляется. Для российского корпоративного контура это обычно связано с 152-ФЗ, журналом доступа и понятной политикой хранения. Если вы строите чат через RU LLM, тот же подход логично применить и к памяти: держать данные в российском контуре, маскировать PII в логах и оставлять аудит-трейл на изменение записи.
Есть простое правило, которое редко подводит: память обновляет не сама модель, а отдельный слой с понятными условиями записи. Тогда чат помнит нужное и не выдумывает лишнего.
Простая схема внедрения
Хорошая схема начинается не с векторного поиска и не с большой базы, а со списка фактов, которые реально меняют ответ модели. Для большинства рабочих чат-сценариев хватает 10-20 полей: роль сотрудника, отдел, продукт, язык общения, регион, уровень доступа, текущая задача, согласованные термины, запрещенные темы и подтвержденные предпочтения.
Если факт не влияет на ответ, не храните его. Запись любит короткие ответы может быть полезной. Запись во вторник спрашивал про отпуск почти всегда лишняя.
Дальше достаточно пяти шагов:
- Опишите схему памяти. У каждого поля должны быть имя, тип и срок жизни.
- Задайте правила записи. Явные данные сохраняйте сразу, догадки не сохраняйте без подтверждения.
- Перед генерацией ответа поднимайте только те записи, которые связаны с текущим запросом.
- Передавайте в промпт короткую выжимку, а не весь старый диалог. Часто хватает нескольких строк.
- После ответа проверяйте, появился ли новый устойчивый факт. Если нет, ничего не записывайте.
На практике удобно разделить память на два слоя. В оперативном лежит то, что нужно только внутри текущей задачи. В постоянном - факты, которые пригодятся через неделю или месяц. Такое разделение заметно снижает шум.
Если у команды уже есть OpenAI-совместимый шлюз, этот подход внедрять проще. Например, RU LLM позволяет отправлять короткую структурированную выжимку через тот же эндпоинт и не менять SDK, код и промпты. Это убирает часть лишней работы на пилоте.
Пример для внутреннего чата банка
В банке такой подход особенно хорошо виден на повторяющихся задачах. Допустим, сотрудник службы ИБ каждое утро просит чат собрать сводку по одному и тому же инциденту: что изменилось за ночь, сколько клиентов затронуто, есть ли новые блокировки и что нужно отправить руководителю до 10:00.
Если память хранится отдельно, чат не тащит в запрос всю вчерашнюю переписку. Он берет только профиль сотрудника и свежие данные по инциденту. Это дешевле, быстрее и обычно точнее, потому что модель не тонет в старых сообщениях.
В профиле такого пользователя можно хранить всего несколько фактов: роль - руководитель смены ИБ, подразделение - антифрод, формат ответа - пять пунктов и короткий вывод, уровень деталей - без технических логов. Это не история диалога, а рабочие настройки, которые редко меняются.
Ежедневный запрос после этого выглядит намного проще. В модель уходят только новые цифры: сколько событий подтвердили, сколько заявок закрыли, какой статус у расследования и к какому времени нужен отчет. Вчерашние просьбы вроде сделай короче или не добавляй IP-адреса уже не надо повторять, если система однажды сохранила их как устойчивое правило.
На практике это выглядит так. Сотрудник пишет короткую команду вроде сводка по инциденту 2481 к 9:30. Оркестратор достает профиль, добавляет свежую выборку из внутренних систем и отправляет в модель компактный пакет данных. Ответ приходит в привычном формате, без длинной преамбулы и без пересказа старого чата.
Если на следующий день сотрудник говорит, что теперь ему нужна таблица, система не переписывает всю историю. Она меняет один факт в профиле. Этого достаточно, чтобы следующий ответ сразу вышел в новом виде.
Где команды ошибаются чаще всего
Самая частая ошибка проста: в память начинают писать почти весь диалог. Пользователь поздоровался, передумал, пошутил, уточнил формулировку, и все это летит в хранилище как будто пригодится потом. Через пару недель памяти много, пользы мало.
Вторая ошибка - путать факт и вывод. Чат увидел фразу я, кажется, из комплаенса и сохранил пользователь работает в комплаенсе. Потом этот вывод попадает в каждый новый запрос и искажает ответ. Лучше хранить не только значение, но и статус записи: подтверждено, предположено, устарело или удалено.
Третья ошибка - смешивать личные данные и рабочие настройки в одной куче. Имя пользователя, номер телефона и предпочтение по формату ответа не должны лежать в одном слое и с одинаковыми правами доступа. Для корпоративного чата это не только вопрос удобства, но и вопрос риска.
Четвертая ошибка всплывает не сразу. Записи никто не чистит. Пользователь сменил отдел, проект закрыли, правило больше не действует, а память ведет себя так, будто ничего не изменилось. Если у записи нет срока жизни, источника и времени последнего подтверждения, она почти наверняка начнет мешать.
Есть и еще одна проблема: память вставляют в промпт сплошным куском текста. В таком виде модели трудно понять, что важнее - постоянная роль пользователя, временная задача или старая заметка двухнедельной давности. Гораздо лучше передавать память по слоям и по приоритету: сначала постоянные факты, потом активный контекст, потом короткий хвост свежей истории.
Даже если инфраструктура держит логи и обработку в России, качество памяти все равно решает само приложение. Если факт нельзя проверить, обновить и удалить, ему не место в памяти.
Что проверить перед запуском
Перед пилотом полезно пройтись по памяти так, будто ее завтра будут разбирать поддержка, ИБ и продуктовая команда. Если вы не можете простыми словами объяснить, зачем хранится каждый тип факта, память уже стала слишком большой.
Хороший вопрос звучит так: для какого ответа нужен этот факт? Предпочтительный язык нужен. Часовой пояс тоже нужен. Случайная шутка пользователя или старый спор из переписки почти никогда не нужны.
Потом стоит провести жесткий тест. Уберите старую историю чата и оставьте только последние 5-10 сообщений, системные инструкции и сохраненные факты. Если бот после этого теряет смысл, у вас не память, а зависимость от длинного лога. Нормальная архитектура выдерживает такой тест: ассистент помнит устойчивые данные о человеке и опирается на свежий контекст, а не на всю историю целиком.
Отдельно проверьте происхождение каждого факта. У записи должен быть источник: из какого сообщения она появилась, когда обновилась, кто ее подтвердил и насколько ей можно доверять. Иначе начнутся разборы в духе почему чат решил, что клиент работает в Казани.
Срок жизни тоже нужен почти всегда. Предпочтительный язык можно хранить долго. Текущий проект, роль в конкретной заявке или временный лимит лучше удалять по TTL или сразу после завершения сценария. Без этого память быстро набирает мусор и начинает спорить с пользователем на основе старых данных.
И еще один практический момент: не редактируйте память через сырые логи. Логи должны оставаться журналом событий, а память должна жить в отдельном слое редактирования. Тогда оператор или менеджер сможет исправить неверный факт вручную, не ломая историю запросов. Если ваша инфраструктура уже хранит аудит-трейлы на уровне запросов, такой контроль встроить проще.
С чего начать
Не пытайтесь перестроить весь чат сразу. Возьмите один сценарий, где история разрастается уже в первые минуты: поддержка сотрудников, помощник для CRM или чат по регламентам. На таком кейсе быстрее видно, где память дает реальную пользу, а где только усложняет систему.
Сначала зафиксируйте текущую картину. Посчитайте, сколько токенов уходит на один ответ, какая средняя задержка и как часто модель ошибается из-за длинной истории: путает продукт, забывает уже известные факты, повторно задает те же вопросы. Без этих цифр после пилота будет только общее впечатление.
Потом соберите короткий список полей, которые стоит хранить отдельно от истории. Обычно хватает роли пользователя, языка, продукта, номера заявки и пары подтвержденных предпочтений. Этого уже достаточно, чтобы увидеть эффект.
Дальше сверьте схему с безопасностью, юристами, владельцем продукта и инженерами. Первые проверят состав данных, сроки хранения и доступы. Юристы посмотрят, не спорит ли схема с 152-ФЗ и внутренними правилами. Владелец продукта вычеркнет поля на всякий случай. Инженеры опишут, кто и когда обновляет каждый факт.
После этого запускайте маленький пилот. Без сложной архитектуры и без желания решить все сразу. Достаточно простого контура: извлечение фактов после ответа, запись в отдельное хранилище, добавление только нужных полей в следующий запрос и журнал изменений. Через неделю такой пилот обычно говорит больше, чем месяц обсуждений.
Если чат должен работать в российском контуре, инфраструктуру лучше проверить заранее. Для многих команд удобен единый OpenAI-совместимый эндпоинт, чтобы не переписывать интеграции. В этом месте может пригодиться RU LLM: сервис работает как API-шлюз для российского рынка, помогает держать логи и бэкапы в РФ, поддерживает маскирование PII и аудит-трейлы внутри одного контура. Это удобно проверять на пилоте вместе с ИБ и архитектурной командой, а не после запуска.
Скучный следующий шаг обычно самый правильный: один сценарий, несколько полей памяти, метрики до и после и короткий пилот на реальном потоке. Если задержка падает, расход токенов снижается, а ответов с промахами становится меньше, такую схему уже можно масштабировать.
Часто задаваемые вопросы
Зачем отделять память от истории чата?
Потому что длинная история быстро раздувает каждый запрос. Память хранит устойчивые факты один раз, а контекст несет только то, что нужно для текущей задачи. Так чат тратит меньше токенов и реже цепляется за старые детали.
Какие факты стоит хранить в памяти?
Держите там только то, что меняет следующий ответ. Обычно это роль, отдел, язык, доступы, регион, формат ответа и постоянные ограничения вроде маскирования данных.
Что не стоит сохранять надолго?
Разовые просьбы и детали на один день лучше не тащить дальше. Фразы вроде сегодня я спешу, временная подмена коллеги или случайная шутка только засоряют память и потом мешают ответу.
Когда можно записывать новый факт о пользователе?
Записывайте факт после явного сигнала. Если человек прямо попросил отвечать по-русски или сказал, что ему нужна таблица, это можно сохранить. Если модель сама догадалась по одному сообщению, лучше подождать подтверждения.
В каком виде лучше хранить память?
Удобнее хранить отдельные записи, а не куски переписки. Простая схема такая: type, value, source, updated_at, confidence, а для временных вещей еще и ttl. Такой формат легко обновлять и удалять.
Нужен ли TTL для записей памяти?
Да, без срока жизни память быстро зарастает мусором. Предпочтение по стилю ответа может жить неделями, а временный лимит или роль в конкретной заявке стоит удалить после завершения сценария.
Как передавать память в промпт, чтобы модель не путалась?
Не вставляйте весь архив одним блоком. Сначала добавьте короткий профиль пользователя, потом свежий контекст задачи и только потом несколько последних сообщений, если они правда нужны модели.
Что делать, если память хранит неверный или устаревший факт?
Исправляйте запись в отдельном слое памяти, а не через логи. У записи должны быть источник и дата обновления, чтобы оператор быстро понял, откуда взялся факт, и спокойно заменил его на актуальный.
Как работать с персональными данными в памяти чата?
Если в памяти есть ФИО, телефон, табельный номер или другие персональные данные, сразу задайте правила хранения и доступа. В российском контуре обычно держат такие данные в РФ, маскируют PII в логах и сохраняют аудит изменений под требования 152-ФЗ.
С чего начать пилот с памятью в enterprise-чате?
Начните с одного сценария, где история уже мешает: поддержка сотрудников, CRM-помощник или чат по регламентам. Замерьте токены, задержку и число промахов до пилота, потом вынесите 10–20 устойчивых полей в память и сравните результат через неделю.