Оркестрация LLM-задач через очередь без хаотичных вызовов
Оркестрация LLM-задач через очередь снижает хаос в продакшене: разберем ретраи, дедлайны, компенсации и простой шаблон пайплайна.
Почему прямые вызовы быстро превращаются в хаос
Прямой HTTP-вызов к модели кажется удобным, пока нагрузка ровная, а ответ нужен сразу. Проблемы начинаются в день, когда один и тот же сценарий должен пережить пик трафика, медленного провайдера и пару сбоев подряд.
Чаще всего команда делает одну и ту же ошибку: оставляет всю логику внутри одного запроса. Пользователь отправляет документ, сервис сразу идет в LLM, потом в проверку правил, потом в базу, потом в еще один вызов модели. Пока все шаги не завершатся, HTTP-соединение висит. Один долгий ответ на любом этапе держит занятыми воркеры, соединения и память.
При всплеске нагрузки это ломается быстро. Если в систему одновременно прилетает не 20, а 2000 задач, прямые вызовы начинают мешать друг другу. Очередь входящих запросов растет, таймауты срабатывают чаще, клиенты нажимают "повторить", и система сама усиливает перегрузку дубликатами.
Один таймаут редко остается одиночной проблемой. Если сервис ждал ответ от модели 40 секунд и не дождался, следующий шаг уже не стартует, а внешний клиент часто не понимает, завершилась задача или нет. В итоге одна и та же операция уходит повторно. Для LLM-пайплайна это особенно неприятно: вы получаете двойные расходы, разные ответы для одной заявки и спорные записи в статусах.
Обычно это выглядит так:
- задача "зависла", но никто не понимает, на каком шаге;
- один сервис считает ее неуспешной, а другой уже сохранил результат;
- повтор со стороны клиента создает дубль вместо продолжения;
- поддержка не может быстро объяснить, что произошло;
- нагрузка растет не из-за новых задач, а из-за повторов и ожидания.
Статус теряется потому, что прямой вызов почти не хранит историю выполнения. Он живет ровно столько, сколько живет запрос. Если в цепочке три сервиса и один из них упал после частичного успеха, у команды часто нет нормальной картины: что уже сделано, что можно повторить, а что трогать нельзя.
Поэтому оркестрация LLM-задач почти всегда выигрывает, когда выполнение выносят из HTTP в очередь. HTTP принимает задачу, проверяет входные данные, выдает task_id и отпускает клиента. Дальше воркер берет шаги по очереди, пишет статус, соблюдает дедлайны и переживает временные сбои без паники. На старте это выглядит скучнее. Зато в рабочей системе такой подход экономит и нервы, и деньги.
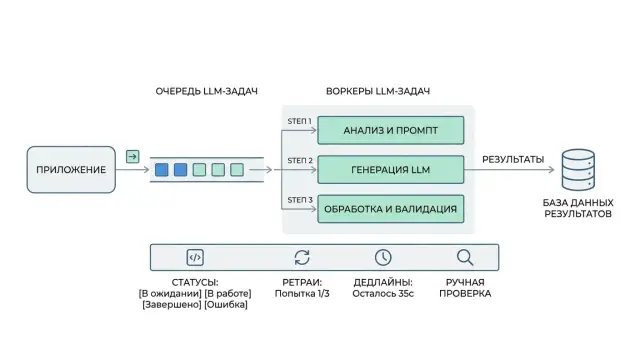
Из чего состоит рабочий LLM-пайплайн
Рабочий LLM-пайплайн чаще ломается не на модели, а на обвязке вокруг нее. Все начинается с простой идеи: каждый шаг должен жить отдельно, иметь свой статус и оставлять след в журнале.
Если собрать все в один вызов, контроль быстро теряется. Непонятно, какой шаг уже прошел, где случился таймаут и что нужно перезапустить, а что лучше не трогать.
Обычно хватает четырех частей. Очередь хранит задания и выдает их в понятном порядке. Воркеры забирают один шаг, выполняют его и сразу сохраняют результат. Хранилище статусов держит текущее состояние задачи: ждет ли она запуска, идет ли сейчас, уперлась ли в ошибку, нужна ли ручная проверка. Журнал событий хранит историю: кто взял задачу, какой был вход, какой промпт и какая модель использовались, чем закончилась попытка.
Эта схема не выглядит сложной, пока не начинаешь чинить сбои. Но именно она спасает в плохие дни. Если один воркер упал, другой может продолжить с понятной точки. Если провайдер модели отвечает медленно, очередь не дает всей системе рухнуть вместе с ним.
Как разложить одну задачу на шаги
Такой подход работает лучше, когда одна бизнес-задача не прячется внутри одного большого запроса. Если смешать подготовку данных, вызов модели, проверку ответа и отправку результата в один шаг, любой сбой ломает все сразу. Потом трудно понять, что именно пошло не так и что можно безопасно повторить.
Сначала отделите подготовку данных от самого вызова модели. Подготовка включает очистку входа, сбор контекста, маскирование персональных данных и приведение данных к нужному формату. Вызов модели - это уже отдельная операция со своим таймаутом, стоимостью и правилами повтора.
Для каждого шага стоит сохранять минимум, без которого нельзя разобраться в результате: исходный вход, версию промпта, параметры вызова и ожидаемый формат ответа. Даже если команда работает через единый OpenAI-совместимый эндпоинт, такой журнал все равно нужен. Иначе через неделю никто не вспомнит, почему один и тот же текст дал другой ответ после смены модели или промпта.
У хорошего шага обычно есть четыре свойства. Он получает один понятный вход. Выдает один явный результат. Записывает статус в хранилище. И его можно повторить без порчи всей цепочки.
Результат лучше задавать явно, а не словами вроде "ну, почти сработало". Подойдут простые состояния: prepared, generated, validated, needs_review, failed. Тогда очередь задач для LLM двигает задачу дальше по правилам, а не по догадкам.
Полезно заранее решить, где нужен человек. Не везде, а в точках риска. Например, если модель готовит ответ клиенту банка, ручную проверку можно включать только для спорных случаев: низкая уверенность, конфликт с внутренними правилами, пустой или слишком длинный ответ. Это дешевле, чем отправлять на ручной разбор весь поток.
Простой пример - входящее письмо клиента. Сначала система чистит текст и убирает лишние данные. Потом модель определяет тему обращения. После этого отдельный шаг проверяет, попал ли ответ в нужную схему. Если проверка не прошла, задача не "падает в никуда", а уходит в needs_review. Такой пайплайн чинить заметно проще, чем один хаотичный вызов с десятью скрытыми действиями внутри.
Как собрать выполнение по шагам
Хороший пайплайн не делает всю работу одним длинным вызовом. Он двигает задачу по этапам и после каждого этапа оставляет запись в хранилище. Если воркер упадет на середине, система не гадает, что уже сделано, а что нет.
В начале создайте отдельную сущность задачи. У нее должны быть свой task_id, приоритет, общий дедлайн и ссылка на исходные данные. Полезно сразу хранить current_step, число попыток по каждому шагу и идентификатор воркера, который взял задачу в работу.
Дальше помогает простое правило: следующий шаг нельзя запускать, пока предыдущий не записал итог. Сначала воркер обновляет статус, сохраняет артефакты шага и только потом ставит в очередь следующий этап или публикует событие. Это убирает гонки, дубли и странные ситуации, когда постобработка уже пошла, а ответ модели еще не сохранился.
Для статусов обычно хватает короткого набора:
queued- задача ждет выполнения;running- шаг выполняется сейчас;done- цепочка завершилась успешно;failed- система остановила задачу;manual_review- нужен человек.
Ответ модели лучше сохранять в сыром виде до любой очистки, парсинга и нормализации. Это спасает чаще, чем кажется. Например, модель вернула почти правильный JSON, но парсер сломался на одном поле. Если сырой ответ лежит отдельно, вы сможете перепарсить его новым кодом и не дергать модель второй раз.
На практике цепочка часто выглядит так: подготовка контекста, вызов модели, проверка формата, бизнес-валидация, запись результата. Если команда использует единый OpenAI-совместимый шлюз вроде RU LLM, логика не меняется. Очередь управляет шагами, а не самим провайдером.
Финал тоже должен быть однозначным. У задачи не должно быть состояния "где-то зависла". Закрывайте цепочку одним из трех итогов: успех, отказ с понятной причиной или ручная проверка.
И ручная проверка должна быть отдельным маршрутом, а не мусорным статусом на всякий случай. Оператору нужно сразу видеть, на каком шаге задача остановилась, какой был сырой ответ модели и что именно система не смогла решить сама.
Как ставить ретраи и дедлайны
Ретраи помогают не всегда. Если модель вернула 429, провайдер ответил 503 или сеть оборвалась на середине запроса, повтор обычно нужен. Если промпт сломан, JSON не проходит валидацию или входные данные пустые, повтор только тратит время и деньги.
В очереди задач для LLM полезно сразу делить ошибки на временные и постоянные. Это простое правило убирает половину шума. Проблема обычно не в самих сбоях, а в бессмысленных повторах там, где задача уже не сможет пройти.
Рабочая схема обычно такая:
- повторяйте 429, 500, 502, 503, сетевые таймауты и краткие обрывы соединения;
- не повторяйте ошибки схемы ответа, битый вход, отказ бизнес-валидации и превышение бюджета задачи;
- после каждого повтора увеличивайте паузу, например 5, 15 и 45 секунд;
- после нескольких одинаковых сбоев подряд переводите задачу в
failedилиneeds_review.
Пауза между повторами должна расти. Иначе очередь начинает душить саму себя: сотни задач падают, тут же летят снова и добивают провайдера второй волной. Даже простой backoff с небольшим случайным разбросом уже заметно сглаживает пики.
Отдельный таймаут на шаг нужен, но его мало. Нужен еще общий дедлайн на всю цепочку. Допустим, пайплайн должен обработать заявку за 2 минуты. Тогда шаг с извлечением данных может получить 25 секунд, шаг с проверкой - 20 секунд, но вся цепочка все равно остановится по общему сроку. Иначе отдельные шаги будут "успешно" ретраиться, а пользователь уже давно ушел.
Полезно хранить в статусе не просто failed, а причину последней ошибки: provider_503, json_validation_error, deadline_exceeded, budget_exceeded. Когда команда утром открывает очередь, ей нужно сразу видеть, что именно сломалось и требуется ли вмешательство человека.
Если вы маршрутизируете запросы через RU LLM к разным провайдерам через один OpenAI-совместимый эндпоинт, причина последней ошибки особенно полезна. Она помогает быстро понять, это общий сбой пайплайна, временная проблема у конкретного провайдера или ошибка в самом шаге.
Где нужны ручные компенсации
Ручная компенсация нужна там, где ошибка уже успела что-то изменить: запись в CRM, письмо клиенту, статус заявки, тег в очереди. Если следующий шаг падает, простой ретрай часто только добавляет путаницу. Очередь должна уметь не только повторять шаги, но и останавливать задачу в точке, где нужен человек.
Спорные ответы модели лучше отправлять на ручную проверку сразу. Это особенно полезно, когда модель извлекает данные из документов, ставит риск-метку или решает, можно ли передавать текст дальше по цепочке. Если уверенность низкая, ответы двух моделей расходятся или сработало правило комплаенса, лучше не продолжать пайплайн автоматически.
В российской среде это особенно заметно на задачах с персональными данными. Если пайплайн через RU LLM маскирует PII, классифицирует обращение и потом пишет результат во внутреннюю систему, сомнительный ответ разумнее остановить до записи, чем потом исправлять последствия.
Частичный результат тоже требует компенсации. Допустим, один шаг разобрал договор, второй заполнил карточку клиента, а третий не прошел проверку. Не оставляйте систему в состоянии "наполовину готово". Либо откатите созданную карточку, либо пометьте ее как черновик и отправьте кейс оператору с понятным статусом.
Промежуточные данные лучше не удалять до финального решения. Сохраняйте вход, ответ модели, распарсенные поля, ID запроса и номер шага. Иначе оператор увидит только "ошибка на этапе 4" и начнет гадать. С контекстом он может исправить одно поле и перезапустить только провалившийся шаг, а не всю цепочку заново.
Оператору при этом не нужен сложный экран с десятком кнопок. Обычно хватает трех действий:
- повторить шаг с теми же данными;
- исправить конкретное поле и продолжить пайплайн;
- закрыть кейс и отменить частичный результат.
К каждой задаче добавьте короткое объяснение: что уже изменилось, что еще не изменилось и какой шаг ждет решения. Если оператору приходится читать сырые логи, процесс устроен плохо.
Хороший признак простой схемы такой: человек открывает карточку, за 30-60 секунд понимает проблему и делает одно действие. Если на разбор уходит пять минут, значит вы слишком рано удаляете данные, слишком поздно ставите ручную проверку или смешали бизнес-ошибку с техническим сбоем.
Пример на реальном сценарии
Представьте поддержку банка или крупного ритейла. Клиент пишет: "У меня списали деньги дважды, номер заказа 54821, мой телефон 9XX..." Если такое сообщение сразу отправить в модель одним вызовом, путаница начнется очень быстро. Непонятно, кто отвечает за маскирование данных, что делать при таймауте и куда отправлять сомнительный ответ.
Через очередь это выглядит спокойнее. Входящее обращение получает job_id и попадает в обработку. С этого момента каждый шаг живет отдельно, а система видит статус задачи, число попыток и дедлайн.
Сначала работает шаг подготовки. Он находит телефон, номер карты, почту, адрес и другие персональные данные, сохраняет исходный текст в защищенном контуре, а в копии для модели заменяет чувствительные фрагменты масками. Для компаний с требованиями 152-ФЗ это не формальность, а обычная часть маршрута.
Потом второй воркер берет уже очищенный текст и решает три вещи: о чем обращение, насколько оно срочное и насколько модель уверена в своем выводе. Если уверенность низкая, ответ противоречивый или тема чувствительная, задачу не гоняют по кругу. Очередь сразу передает ее оператору. Он видит исходное сообщение, вывод модели, причину эскалации и может либо подтвердить черновик ответа, либо исправить маршрут.
Дальше система делает одно из двух. Если все чисто, она формирует ответ по шаблону и отправляет его клиенту. Если нужен разбор в другой команде, она создает тикет с нужным приоритетом и прикладывает краткое резюме обращения.
Ретраи и дедлайны здесь тоже прозрачны. Если шаг классификации не ответил за 10 секунд, система делает еще одну попытку. Если вторая попытка тоже сорвалась, задача не висит бесконечно, а уходит человеку. Подход не самый эффектный на бумаге, но именно он делает LLM-пайплайн в продакшене предсказуемым.
Ошибки, которые ломают очередь
Обычно очередь падает не из-за редких аварий, а из-за пары плохих привычек в дизайне. Сбои начинаются в тот момент, когда команда пытается решить все одним вызовом и надеется, что ретрай потом все исправит.
Первая частая ошибка - один длинный промпт вместо цепочки коротких шагов. Такой запрос трудно отлаживать: вы не видите, где именно сломался процесс, почему выросла цена и какой кусок можно безопасно повторить. Если разбить задачу на этапы, очередь живет дольше и чинится быстрее.
Не меньше проблем дает общий ретрай для всех ошибок. Очередь не должна одинаково реагировать на 429, таймаут модели и плохой входной JSON. В первом случае полезно подождать и повторить. Во втором иногда лучше переключиться на другую модель или сократить контекст. В третьем повтор бесполезен, задачу нужно отправлять на разбор.
Нормальная схема обычно выглядит так:
- rate limit - пауза и повтор с backoff;
- временный сбой провайдера - 1-2 повтора, потом переключение на запасной маршрут;
- ошибка в данных - остановка и ручная проверка;
- нарушение бизнес-правила - компенсация, а не ретрай.
Еще одна ловушка - повторный запуск без защиты от дублей. Если воркер перезапустился после таймаута, он может второй раз отправить письмо, создать второй тикет или повторно списать лимит токенов. У каждой задачи нужен idempotency key и понятный статус шага: pending, running, done, failed, compensated.
Дедлайн только на HTTP-запросе тоже не спасает. Один вызов модели может завершиться за 20 секунд, но вся задача зависнет на 40 минут из-за очереди, ретраев и ожидания соседних шагов. Ставьте срок жизни на всю работу целиком. Когда дедлайн истек, система должна прекратить новые попытки и перевести задачу в финальное состояние.
Ручная обработка без журнала действий тоже быстро ломает доверие. Если оператор поменял промпт, выбрал другую модель или вручную закрыл задачу, это нужно записать вместе с причиной. Иначе через неделю никто не поймет, почему результат отличается от обычного маршрута. Если запросы идут через RU LLM, аудит-трейлы по вызовам уже помогают, но действия людей и бизнес-компенсации все равно стоит хранить отдельно.
Простой пример: заявка на кредит прошла через классификацию, потом зависла на проверке полей. Если просто нажать "запустить заново", система может создать второй набор выводов и смешать версии. Если у вас есть короткие шаги, дедлайн задачи и журнал ручных решений, оператор исправит один этап, а не сломает всю цепочку.
Быстрый чек-лист перед запуском
Перед первым запуском проверяйте не только качество промпта, но и управляемость процесса. Очередь ломается не там, где модель ответила чуть хуже, а там, где вы не можете понять, что именно произошло и что делать дальше.
Короткий список проверки:
- у каждой задачи есть постоянный ID, понятный статус и один общий дедлайн на весь путь;
- каждый шаг можно безопасно повторить без дублей в CRM, тикетах и уведомлениях;
- оператор видит не просто
failed, а точную причину остановки и следующее действие; - логи сохраняют вход, ответ модели, версию промпта и параметры вызова;
- чувствительные данные маскируются до записи в лог;
- система ограничивает число повторов, длину очереди и скорость постановки новых задач.
Есть еще одна полезная проверка: можно ли за две минуты разобрать любой зависший job вручную. Если для ответа нужно открыть пять сервисов и читать сырые логи, процесс еще сырой.
Для LLM-пайплайна в продакшене этого минимума уже хватает, чтобы не тонуть в случайных ошибках. Если вы используете OpenAI-совместимый шлюз вроде RU LLM, полезно писать в журнал не только ответ модели, но и конкретного провайдера, модель и версию промпта. Тогда спорный результат проще воспроизвести.
Что делать дальше
Не пытайтесь сразу переводить на очередь весь LLM-контур. Лучше взять один короткий сценарий, где результат виден за день или два. Подойдет цепочка вроде такой: классификация обращения, извлечение полей, черновик ответа и передача человеку.
Для первого запуска обычно хватает простого каркаса:
- вынесите каждый шаг в отдельную задачу с понятным статусом;
- задайте дедлайн для шага и лимит на число ретраев;
- сохраняйте вход, выход, длительность и расход токенов;
- поставьте ручную проверку там, где ошибка стоит дороже всего.
Этого уже достаточно, чтобы увидеть, где пайплайн тормозит. Очень часто время уходит не в саму модель, а между шагами: очередь растет, один воркер забирает слишком тяжелые задачи, повторные вызовы съедают бюджет. Если не мерить это с первого дня, команда начинает спорить по ощущениям.
Смотрите хотя бы на четыре числа по каждому шагу: среднее время, p95, долю ретраев и токены на успешный результат. Такая таблица быстро показывает слабые места. Иногда один промпт отвечает чуть лучше, но ест в два раза больше токенов и чаще уходит в повтор. Для реальной эксплуатации это сомнительный обмен.
Ручную проверку не стоит ставить везде. Лучше добавить ее в дорогие или рискованные точки: перед отправкой клиенту, перед записью в CRM, перед запуском следующего дорогого шага. Если шаг уже создал побочный эффект, держите и простой ручной откат, чтобы оператор не искал обходной путь в чате или таблицах.
Если вам нужен единый OpenAI-совместимый эндпоинт и хранение данных в РФ, такой пайплайн можно связать с RU LLM без смены SDK, кода и промптов - достаточно переключить base_url на api.rullm.com. Это удобно, когда оркестрация и очередь остаются у вас, а маршрутизацию по моделям, биллинг в рублях и требования 152-ФЗ к хранению логов и бэкапов в РФ вы не хотите собирать отдельно.
Следующий шаг простой: выберите один сценарий, соберите его за неделю, снимите метрики и только потом расширяйте схему. После этого решения о ретраях, дедлайнах и ручных проверках будут опираться на цифры, а не на догадки.
Часто задаваемые вопросы
Зачем вообще выносить LLM-задачи в очередь?
Очередь снимает длинную работу с HTTP-запроса. Клиент быстро получает task_id, а воркеры спокойно проходят шаги, пишут статусы и переживают временные сбои без лавины таймаутов и повторов.
Когда прямой HTTP-вызов уже не подходит?
Как только одна задача живет дольше пары секунд, дергает несколько сервисов или начинает ловить повторы от клиентов, прямой вызов уже мешает. Если при пике трафика у вас растут таймауты, дубли и непонятные статусы, пора переводить сценарий в очередь.
Как правильно разбить одну задачу на шаги?
Разделите бизнес-задачу на короткие этапы с явным входом и явным результатом. Обычно хватает подготовки данных, вызова модели, проверки формата, бизнес-валидации и записи результата. Если шаг нельзя безопасно повторить отдельно, он слишком большой.
Какие статусы задачи стоит хранить?
На старте хватит queued, running, done, failed и manual_review. Этого набора достаточно, чтобы понять, ждет ли задача запуска, идет ли работа сейчас, завершилась ли она или требует человека.
Какие ошибки стоит ретраить, а какие нет?
Повторяйте только временные сбои: 429, 500, 502, 503, сетевые обрывы и таймауты. Если вход битый, схема ответа не сошлась или задача вышла за бюджет, не тратьте повторы — останавливайте шаг и отправляйте его в failed или на разбор.
Как выбрать таймауты и общий дедлайн?
Ставьте два срока: отдельный таймаут на шаг и общий дедлайн на всю цепочку. Например, шаг классификации может ждать 10–20 секунд, а вся задача — не дольше двух минут. Так система не будет бесконечно "успешно" повторять шаги, пока пользователь уже ушел.
Как защититься от дублей и повторной отправки?
Дайте каждой операции свой idempotency key и не запускайте следующий шаг, пока прошлый не записал итог. Тогда воркер не отправит письмо второй раз и не создаст дубль тикета после перезапуска или таймаута.
В каких местах нужна ручная проверка?
Подключайте человека там, где ошибка уже дорого стоит. Это обычно отправка ответа клиенту, запись в CRM, работа с PII, спорные выводы модели и случаи с низкой уверенностью. Не гоняйте такие задачи по кругу — лучше остановить их в понятной точке.
Что обязательно писать в логи и статусы?
Сохраняйте вход, сырой ответ модели, версию промпта, параметры вызова, номер шага и причину последней ошибки. Если работаете через RU LLM, полезно писать еще провайдера и модель, чтобы потом быстро понять, где сломался маршрут.
С чего начать внедрение без большого проекта?
Возьмите один короткий сценарий, где результат видно за день-два. Подойдет классификация обращения или извлечение полей из текста. Сначала соберите очередь, статусы, ретраи и ручную проверку, а уже потом расширяйте схему на другие процессы.